Amazon Web Services ブログ
AWS Parallel Computing Service (PCS) と RELION によるスケーラブルなクライオ電子顕微鏡データ解析環境
1. はじめに
クライオ電子顕微鏡(Cryo-EM)技術は、2017年のノーベル化学賞を受賞し、構造生物学と創薬研究に革命をもたらしました。特に構造ベース創薬(Structure-Based Drug Design: SBDD)において、Cryo-EMは標的タンパク質の三次元構造を原子レベルで解明し、その構造情報を基に効果的な化合物をデザインする上で不可欠な技術となっています。
近年、製薬業界ではCryo-EMの導入が急速に進んでいます。従来の手法では困難だった膜タンパク質や柔軟な構造を持つ標的に対しても、Cryo-EMを活用した創薬研究が世界中で推進されています。この技術により、これまで「創薬困難」とされていた標的タンパク質に対する新薬開発の可能性が大きく広がっています。
しかし、Cryo-EMによって毎日生成される数テラバイトのデータを効率的に処理することは、科学者やITシステム管理者にとって大きな課題です。これらの処理パイプラインには、スケーラブルで多様なワークロードに対応できるコンピューティング環境と、高速かつコスト効率に優れたストレージが必要です。
以前のブログ記事では、AWS Parallel Computing Service (PCS) 上で商用ソフトウェアであるCryoSPARCを使用したCryo-EM解析環境を紹介しました。本ブログでは、オープンソースの解析ソフトウェアであるRELIONに焦点を当てます。RELIONは世界中の研究者が自由にダウンロードして利用できるため、大学や研究機関はもちろん、解析環境を新たに立ち上げたい組織にとっても導入しやすいソフトウェアです。PCS上でRELIONを動かすことで、Slurmベースの既存ワークフローをそのままクラウドに持ち込み、オンデマンドでスケールする解析環境を実現できます。
本ブログでは、セットアップ手順からジョブ実行例、コスト最適化のポイントまでを解説します。
2. Cryo-EM解析ソフトウェア RELIONの紹介
2.1 RELIONとは何か
RELION(REgularised LIkelihood OptimisatioN)は、Medical Research Council (MRC)で開発されたオープンソースのクライオ電子顕微鏡画像解析ソフトウェアです。世界中の研究機関で採用されており、以下の特徴があります:
- 完全オープンソース: 学術的透明性と細かいパラメータ制御が可能
- GUI/CLI両対応: 対話的な処理とバッチ処理の両方をサポート
- RELION 5.0の主要機能: 最新の画像処理アルゴリズムと高速化機能
2.2 解析ワークフロー概要
RELIONの解析ワークフローは、以下の主要なステップで構成されます:
- Motion Correction(動き補正): 電子顕微鏡で撮像された動画の動きを補正
- CTF Estimation(コントラスト伝達関数推定): 撮像結果のデフォーカス値と非点収差を測定
- Particle Picking(粒子選択): 解析対象となる粒子を選択
- 2D/3D Classification(分類): 選択した粒子を分類
- 3D Refinement(精密化): 三次元構造の精密化
2.3 RELIONの処理ステップごとのCPU/GPUリソース要求の傾向
RELIONの各処理ステップは、計算特性が異なります。適切なインスタンスタイプを選択するために、処理ステップごとの違いを理解しておくことが重要になります。
CPU中心の処理は主に以下のとおりです。
- Motion Correction: RELIONの自前実装(relion_run_motioncorr)はCPUベースで動作します。マルチスレッドで並列化されており、各スレッドが独立した動画フレームを処理します。ただし、外部ツールであるMotionCor2やMotionCor3等を呼び出す場合はGPU処理も可能になります。
- CTF Estimation: CTFFIND-4.1を使用したCPU処理です。MPIによる並列化で複数のマイクログラフを同時に処理できます。
- Particle Picking: LoGフィルタベースの自動ピッキングはCPU処理で実行されます。テンプレートベースのピッキングはGPUによる高速化が可能です。
- Bayesian Polishing: 粒子ごとの動き補正
GPU中心の処理は主に以下のとおりです。
RELION-2以降、最も計算負荷の高いステップにGPUによる高速化が導入されています(Kimanius et al., eLife, 2016)。GPUによる高速化対象は以下の通りです:
- 2D Classification: 画像分類のExpectation-Maximization(EM)アルゴリズムのE-stepをGPU上で実行。CPUのみと比較して10倍以上の高速化を実現
- 3D Classification: 複数の3Dクラスを同時に精密化する処理。クラス数が増えるほどGPU加速の効果が大きくなります
- 3D Auto-refine: 高解像度精密化。フーリエ空間での参照マップの投影、差分計算、逆投影をGPU上で並列実行
GPU加速により2D/3D Classificationと高解像度Refinementが高速化されました。これにより、従来は大規模クラスターが必要だった計算が、GPUを搭載したインスタンスで短時間に完了できるようになりました。
3. アーキテクチャ概要
3.1 全体構成
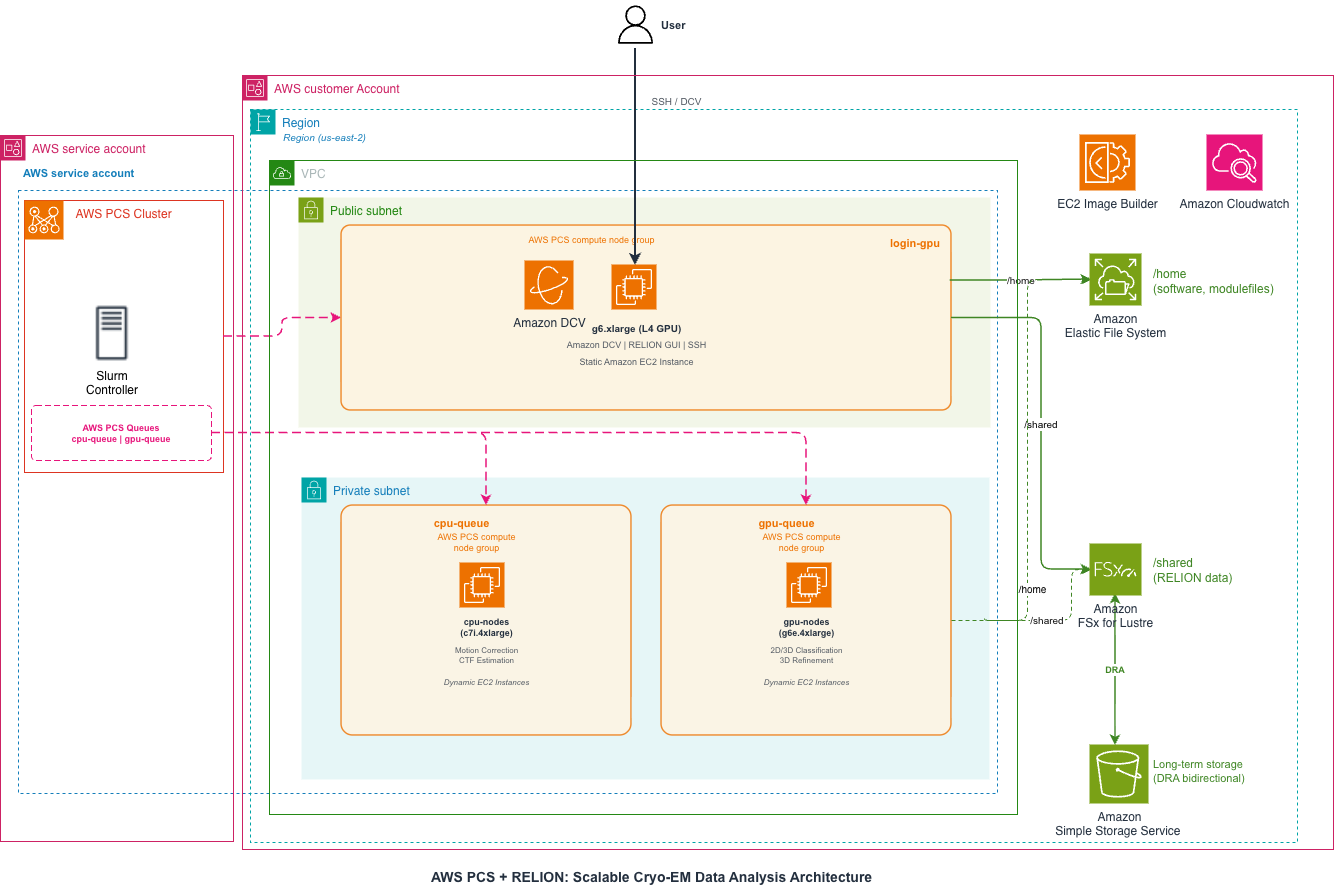
図1 – AWS上のRELION解析用PCSのアーキテクチャ概要。SlurmコントローラはAWSサービスアカウントに配置され、コンピュートとストレージリソースはユーザーAWSアカウントに配置されます。クラスタにはFSx for LustreとAmazon Elastic File Store (EFS)がマウントされています。
ユーザーアクセス経路としては以下の経路でアクセスします。
ユーザー → Amazon DCV(ブラウザ/クライアント)→ Login Node → RELION GUI操作・ジョブ投入(CUIでも投入可)
今回紹介するAWS PCS + RELIONのアーキテクチャは、以下のコンポーネントで構成されています。
- Amazon DCV: Login Node上のリモートデスクトップ接続
- PCS Cluster: マネージドSlurmコントローラー
- Login Node: ユーザーアクセスポイント、DCV接続先
- Compute Nodes: CPU/GPUインスタンス、自動スケーリング
- Amazon FSx for Lustre: 高速共有ストレージ(/shared)
- Amazon EFS: ホームディレクトリ(/home)
- Amazon S3: 長期保存、Data Repository Association(DRA)連携
3.2 Amazon DCV
Amazon DCVは、高性能リモートディスプレイプロトコルです。クラウド上のLinuxデスクトップにブラウザやネイティブクライアントから低遅延で接続できます:
- 低遅延接続: H.264ベースのエンコーディングとロスレス品質ビデオ圧縮
- RELIONのGUI操作に最適: リモート環境でもローカルと同等の操作感
- 追加料金なし: Amazon EC2上での使用は追加ライセンス費用不要
3.3 AWS Parallel Computing Service (PCS)
AWS PCSは、クラウドでハイパフォーマンスコンピューティング(HPC)クラスタを展開・管理するためのマネージドサービスです。主な利点は以下の通りです:
- 運用負荷の削減: Slurmコントローラー(slurmctld)の管理が不要
- 自動スケーリング: ジョブに応じた計算ノードの自動起動・停止
- 既存ワークフローの活用: 既存のSlurmスクリプトをそのまま利用可能
- 迅速な環境構築: 約30分で計算環境の準備が完了(株式会社 豊田中央研究所のAWS re:Invent 2025での発表事例)
3.4 RELIONワークロードにPCSが適している理由
RELIONのようなCryo-EM解析ワークロードには、以下の理由からPCSが適していると考えます。
- Slurmとの親和性: RELIONはGUIからSlurmのsbatchコマンドでジョブを投入する設計です。PCSはネイティブにSlurmをサポートしており、既存のSlurmスクリプトやワークフローをそのまま利用できます
- 運用負荷の最小化: 研究者はインフラ管理ではなく解析に集中すべきです。PCSはSlurmコントローラーの管理をAWSに委任でき、ParallelClusterと比較して運用負荷を大幅に削減できます
- コンテナ化不要: AWS Batchはコンテナベースのため、RELIONや依存ライブラリ(wxWidgets、CTFFIND等)のコンテナ化が必要です。PCSではAMIにソフトウェアを事前インストールするだけで済みます
- GUI操作との相性: Amazon DCVと組み合わせたGUI操作は、PCSのログインノードから直接行えます
AWS ParallelClusterとPCSの比較は、AWSブログ記事「What’s the difference between AWS ParallelCluster and AWS Parallel Computing Service?」も参考になります。
3.5 ストレージ戦略
効率的なデータ管理のため、以下のストレージ構成としています。
- FSx for Lustre: RELION作業ディレクトリ、S3 DRA連携による高速アクセス
- Amazon EFS: ホームディレクトリ、ソフトウェアインストール
- Amazon S3: 生データ保存、処理結果の長期保存、ライフサイクル管理
3.6 S3とFSx LustreのData Repository Association (DRA)
Data Repository Association (DRA)は、Amazon S3とFSx for Lustreを連携させる強力な機能です。RELIONワークロードにおいて、コスト効率と性能を両立させる鍵となります。
DRAの仕組み:
DRAは、S3バケットとFSx Lustreファイルシステム間に双方向のデータ同期を確立します。1つのFSx Lustreファイルシステムに最大8つのDRAを作成でき、それぞれ異なるS3バケットまたはプレフィックスにリンクできます。
自動インポート機能: 自動インポートは、S3バケット内のオブジェクトの変更を自動的にFSx Lustreに反映します:
- New: S3に新しいオブジェクトが追加されたときにメタデータをインポート
- Changed: 既存のS3オブジェクトが変更されたときにメタデータを更新
- Deleted: S3オブジェクトが削除されたときにファイルシステムから削除
推奨設定は、New + Changed + Deletedの組み合わせです。これにより、S3とFSx Lustre間で完全な同期が維持されます。
自動エクスポート機能: 自動エクスポートは、FSx Lustre上のファイル変更を自動的にS3にエクスポートします:
- ファイルが作成、変更、削除されると自動的にS3に反映
- ファイルコンテンツの変更は、ファイルを閉じた後にエクスポート
- Amazon CloudWatch Logsでエクスポート失敗を監視可能
DRAについてはこちらのユーザガイドをご確認ください。
4. セットアップと構築手順
本手順では、DLAMI + EC2 ImageBuilder方式でPCS用カスタムAMIを作成し、RELION環境を構築します。この手順はAWS HPC Recipesで紹介されている手順です。この方法により以下の効率化が図れます。
- NVIDIAドライバー/CUDAがAMIに事前インストール済み
- DCVがLogin NodeのUserDataに含まれるため、再起動時にもDCV構成が維持される
- FFTWがLaunchTemplateでインスタンス起動時にインストールされる
- OS: Amazon Linux 2023(Amazon Linux2023は2029年6月30日までサポートされます)
- 全ノード(GPU Login、GPU Compute、CPU Compute)で同一AMIを使用できる
手順の実行に当たっては以下の前提条件を踏まえて実行してください。
- PCSをデプロイできるAWSアカウントを持っていること(使うリージョンはus-east-2リージョンとする)
- EC2のSSHキーペアを作成済みであること(デプロイ対象となるリージョンのus-east-2に作成済みとする)
- ローカルのPCにAWS CLI v2 がインストール済みであること
4.1 DLAMI ImageBuilderでカスタムAMI作成
4.1.1 ImageBuilderスタックのデプロイ
HPC Recipes for AWSの DLAMI for PCS レシピを使用して、ImageBuilderパイプラインをデプロイします。ここではAWS CloudFormationを使ってデプロイします。
aws cloudformation create-stack \
--region us-east-2 \
--capabilities CAPABILITY_IAM \
--stack-name dlami-for-pcs \
--template-url https://aws-hpc-recipes.s3.us-east-1.amazonaws.com/main/recipes/pcs/dlami_for_pcs_imagebuilder/assets/dlami-for-pcs.yaml \
--parameters \
ParameterKey=BuildSchedule,ParameterValue=Manual \
ParameterKey=PublishToSsm,ParameterValue=true \
ParameterKey=SsmParameterPrefix,ParameterValue=/dlami-for-pcs
# 完了待機(約5-10分)
aws cloudformation wait stack-create-complete --stack-name dlami-for-pcs --region us-east-24.1.2 AMIビルドの実行
AmazonLinux2023のイメージを作成可能なAL2023 x86_64パイプラインを実行します。
# パイプラインARNを取得
PIPELINE_ARN=$(aws cloudformation describe-stacks \
--region us-east-2 \
--stack-name dlami-for-pcs \
--query "Stacks[0].Outputs[?OutputKey=='PipelineAl2023X8664Arn'].OutputValue" \
--output text)
# ビルド開始(約25分程度時間がかかります)
aws imagebuilder start-image-pipeline-execution \
--image-pipeline-arn ${PIPELINE_ARN} \
--region us-east-24.1.3 ビルド済みAMI IDの取得
# ビルド完了後、AMI IDを取得
DLAMI_AMI_ID=$(aws ec2 describe-images \
--owners self \
--filters "Name=name,Values=dlami-for-pcs-base-al2023-x86_64*" \
--query 'reverse(sort_by(Images, &CreationDate))[0].ImageId' \
--output text --region us-east-2)
echo "DLAMI AMI ID: ${DLAMI_AMI_ID}"このAMIには以下が事前インストールされています:
- NVIDIAドライバー + CUDA(DLAMIベース)
- AWS PCS Agent
- Slurm 24.11 + 25.05(PATHはSlurm 25.05を優先するようLaunchTemplateの設定箇所で指定)
- EFS Utils
- CloudWatch Agent
- AWS System Manager Agent(SSM Agent)
4.2 PCSクラスターの作成
HPC Recipes for AWSの Getting Started テンプレートを使用して、PCSクラスターの基盤をデプロイします。上記テンプレートは、VPC、サブネット、EFS、FSx for Lustre、PCS Cluster、IAM、Security Groupsなどの基盤リソースを一括作成します。デフォルト設定ではデモ用のLogin Node(c6i.xlarge)とCompute Node(c6i.xlarge、demoキュー)が作成されますが、今回作成するRELION環境ではGPU付きのLogin NodeとGPU/CPUコンピュートノードも作成します。次のステップで、RELION向けにノードグループとキューを追加で作成します。
AWS PCSはマネージドコンソールで「パラレルコンピューティングサービス」というサービス名で画面にアクセスできます。
4.2.1 コンソールからのデプロイする場合(ワンクリック)
パラメータ設定:
- SlurmVersion:
25.05(最新のサポートバージョンを推奨。24.11は2026年5月31日にEOL。サポートバージョン一覧を参照) - ManagedAccounting:
enabled(Slurm Accountingを有効化。sacctコマンドでジョブ履歴・リソース使用量を確認でき、トラブルシューティングやコスト分析に有用です) - NodeArchitecture:
x86 - KeyName: 事前に作成したSSHキーペア名(
my-keypair) - ClientIpCidr: ご利用されている環境下でのクライアント側のパブリックIP(
aa.bb.cc.dd/32)
機能と変換箇所で、チェックを入れて、「スタックの作成」をクリックするとCloudFormationがデプロイされます。

4.2.2 AWS CLIからデプロイする場合
YOUR_KEY_NAMEに事前に作成したSSHキーペア名を代入してください。YOUR_IPにはClientIpCidrと同じクライアント側のパブリックIPを指定してください。
export YOUR_KEY_NAME="my-keypair"
export YOUR_IP="aa.bb.cc.dd"aws cloudformation create-stack \
--stack-name pcs-relion \
--template-url https://aws-hpc-recipes.s3.us-east-1.amazonaws.com/main/recipes/pcs/getting_started/assets/cluster.yaml \
--parameters \
ParameterKey=SlurmVersion,ParameterValue=25.05 \
ParameterKey=ManagedAccounting,ParameterValue=enabled \
ParameterKey=NodeArchitecture,ParameterValue=x86 \
ParameterKey=KeyName,ParameterValue=${YOUR_KEY_NAME} \
ParameterKey=ClientIpCidr,ParameterValue=${YOUR_IP}/32 \
--capabilities CAPABILITY_IAM CAPABILITY_NAMED_IAM CAPABILITY_AUTO_EXPAND \
--region us-east-2
# 完了待機(約25分)
aws cloudformation wait stack-create-complete --stack-name pcs-relion --region us-east-24.2.3 CloudFormation出力値の取得(AWS CLIを使用)
デプロイされたCloudFormationのスタックが作成完了した後、以降の手順で使用するリソースIDを取得します。CloudFormationコンソールの「出力」タブでも確認できますが、以下のAWS CLIで確認ができます。あとのコマンド実行のパラメータとしてもここで設定した変数を利用します。以降の処理を行う場合はAWS CLIでコマンドを実行してください。
# PCSクラスターID
CLUSTER_ID=$(aws cloudformation describe-stacks --stack-name pcs-relion \
--query "Stacks[0].Outputs[?OutputKey=='ClusterId'].OutputValue" \
--output text --region us-east-2)
# ネストスタックからリソースIDを取得するヘルパー関数
get_nested_output() {
local nested_id=$(aws cloudformation describe-stack-resource \
--stack-name pcs-relion --logical-resource-id "$1" \
--query "StackResourceDetail.PhysicalResourceId" \
--output text --region us-east-2)
aws cloudformation describe-stacks --stack-name "$nested_id" \
--query "Stacks[0].Outputs[?OutputKey=='$2'].OutputValue" \
--output text --region us-east-2
}
# 各リソースID
VPC_ID=$(get_nested_output "Networking" "VPC")
PUBLIC_SUBNET_ID=$(get_nested_output "Networking" "DefaultPublicSubnet")
PRIVATE_SUBNET_ID=$(get_nested_output "Networking" "DefaultPrivateSubnet")
EFS_ID=$(get_nested_output "EfsStorage" "EFSFilesystemId")
FSX_ID=$(get_nested_output "FSxLStorage" "FSxLustreFilesystemId")
FSX_MOUNT_NAME=$(get_nested_output "FSxLStorage" "FSxLustreMountName")
CLUSTER_SG_ID=$(get_nested_output "PCSSecurityGroup" "ClusterSecurityGroupId")
SSH_SG_ID=$(get_nested_output "PCSSecurityGroup" "InboundSshSecurityGroupId")
INSTANCE_PROFILE_ARN=$(get_nested_output "PCSInstanceProfile" "InstanceProfileArn")
COMPUTE_LT_ID=$(get_nested_output "PCSLaunchTemplate" "ComputeLaunchTemplateId")
LOGIN_LT_ID=$(get_nested_output "PCSLaunchTemplate" "LoginLaunchTemplateId")
# VPCデフォルトSG
VPC_DEFAULT_SG=$(aws ec2 describe-security-groups \
--filters "Name=vpc-id,Values=${VPC_ID}" "Name=group-name,Values=default" \
--query "SecurityGroups[0].GroupId" --output text --region us-east-2)
# EFS/FSx SG(ネストスタックから取得)
EFS_SG=$(get_nested_output "EfsStorage" "SecurityGroupId")
FSX_SG=$(get_nested_output "FSxLStorage" "FSxLustreSecurityGroupId")
echo "CLUSTER_ID=${CLUSTER_ID}"
echo "PUBLIC_SUBNET_ID=${PUBLIC_SUBNET_ID}"
echo "PRIVATE_SUBNET_ID=${PRIVATE_SUBNET_ID}"
echo "EFS_ID=${EFS_ID}"
echo "FSX_ID=${FSX_ID}"
echo "FSX_MOUNT_NAME=${FSX_MOUNT_NAME}"4.3 GPU Login Node + GPU/CPUコンピュートノードグループの追加
Getting Started テンプレートで作成されたデフォルトのLogin Node(c6i.xlarge)とCompute Node(c6i.xlarge、demoキュー)とは別にRELIONの実行環境に適したGPUを搭載したLoginNodeやCPUとGPUのComputeNodeを作成します。
- Login Node(GPU): g6.xlarge(L4 GPU搭載。DCVをGPU対応で稼働 + RELION GPUビルドで用いる)
- GPU Compute Node: g6e.4xlarge(L40S GPU、
gpu-queue。2D/3D Classification等のGPU処理用) - CPU Compute Node: c7i.4xlarge(
cpu-queue。Motion Correction、CTF Estimation等のCPU処理用) - デフォルトの
login、compute-1ノードグループとdemoキューは削除
Launch Templateの作成
Compute用UserData(GPU/CPU共通)
DLAMIにはNVIDIAドライバー/CUDAが事前インストール済みのため、UserDataで設定するものはEFS/FSxのマウントとFFTWやlustre-clientのパッケージのインストールになります。
cat > compute-userdata.txt <<EOF
MIME-Version: 1.0
Content-Type: multipart/mixed; boundary="==MYBOUNDARY=="
--==MYBOUNDARY==
Content-Type: text/cloud-config; charset="us-ascii"
MIME-Version: 1.0
packages:
- amazon-efs-utils
- lustre-client
- fftw
- fftw-libs
- fftw-devel
- ghostscript
runcmd:
- mkdir -p /tmp/home
- rsync -aA /home/ /tmp/home
- echo "${EFS_ID}:/ /home efs tls,_netdev" >> /etc/fstab
- mount -a -t efs defaults
- rsync -aA --ignore-existing /tmp/home/ /home
- rm -rf /tmp/home/
- mkdir -p /shared
- chmod a+rwx /shared
- mount -t lustre ${FSX_ID}.fsx.us-east-2.amazonaws.com@tcp:/${FSX_MOUNT_NAME} /shared
- chmod 777 /shared
- echo 'export PATH=/opt/aws/pcs/scheduler/slurm-25.05/bin:$PATH' > /etc/profile.d/slurm-version.sh
--==MYBOUNDARY==
EOFLogin GPU用UserData(DCV含む)
Login NodeのUserDataにはDCVインストールも含めます。これによりログインノード再起動時にもDCVが維持されます。
cat > login-gpu-userdata.txt <<EOF
MIME-Version: 1.0
Content-Type: multipart/mixed; boundary="==MYBOUNDARY=="
--==MYBOUNDARY==
Content-Type: text/cloud-config; charset="us-ascii"
MIME-Version: 1.0
packages:
- amazon-efs-utils
- lustre-client
- fftw
- fftw-libs
- fftw-devel
- cmake
- git
- wget
- environment-modules
- libtiff-devel
- libpng-devel
- gtk3-devel
- mesa-libGL-devel
- mesa-libGLU-devel
- libXft-devel
- libX11-devel
- ghostscript
runcmd:
# Development Tools group install
- dnf groupinstall -y "Development Tools"
# EFS/FSx mount
- mkdir -p /tmp/home
- rsync -aA /home/ /tmp/home
- echo "${EFS_ID}:/ /home efs tls,_netdev" >> /etc/fstab
- mount -a -t efs defaults
- rsync -aA --ignore-existing /tmp/home/ /home
- rm -rf /tmp/home/
- mkdir -p /shared
- chmod a+rwx /shared
- mount -t lustre ${FSX_ID}.fsx.us-east-2.amazonaws.com@tcp:/${FSX_MOUNT_NAME} /shared
- chmod 777 /shared
# Slurm 25.05 PATH priority
- echo 'export PATH=/opt/amazon/openmpi/bin:/opt/aws/pcs/scheduler/slurm-25.05/bin:$PATH' > /etc/profile.d/slurm-version.sh
- echo 'export LD_LIBRARY_PATH=/opt/amazon/openmpi/lib64:${LD_LIBRARY_PATH:-}' >> /etc/profile.d/slurm-version.sh
# Software directory setup
- mkdir -p /home/software/apps /home/software/src /home/software/modulefiles
- chown -R ec2-user:ec2-user /home/software
# DCV installation (AL2023)
- dnf groupinstall -y "Desktop"
- dnf install -y glx-utils
- systemctl set-default graphical.target
# Wayland無効化(X11モードに強制)
- sed -i '/\[daemon\]/a WaylandEnable=false' /etc/gdm/custom.conf
# NVIDIA Xorg設定(GPUレンダリング有効化)
- nvidia-xconfig --preserve-busid --enable-all-gpus
# DCV パッケージインストール
- rpm --import https://d1uj6qtbmh3dt5.cloudfront.net/NICE-GPG-KEY
- cd /tmp && wget -q https://d1uj6qtbmh3dt5.cloudfront.net/nice-dcv-el9-x86_64.tgz && tar -xzf nice-dcv-el9-x86_64.tgz && cd nice-dcv-*-el9-x86_64 && dnf install -y nice-dcv-server-*.rpm nice-dcv-web-viewer-*.rpm nice-xdcv-*.rpm
- |
cat > /etc/dcv/dcv.conf << 'DCVCONF'
[session-management]
create-session = true
[session-management/automatic-console-session]
owner = "ec2-user"
[display]
target-fps = 30
[connectivity]
enable-quic-frontend = true
idle-timeout = 0
[security]
authentication = "system"
DCVCONF
- echo "ec2-user:dcvpassword" | chpasswd
# Skip Initial GNOME setup
- mkdir -p /home/ec2-user/.config
- echo 'yes' > /home/ec2-user/.config/gnome-initial-setup-done
- chown -R ec2-user:ec2-user /home/ec2-user/.config
- systemctl enable gdm && systemctl start gdm
- systemctl enable dcvserver && systemctl restart dcvserver
--==MYBOUNDARY==
EOFec2-userのパスワードは検証用に簡単なものを付けています。お使いになる環境条件を考慮頂き、必要に応じて強固なパスワードに変更してください。
Launch Template作成
# Compute用UserDataをファイルに保存してBase64エンコード
COMPUTE_USERDATA_B64=$(cat compute-userdata.txt | base64)
# Login GPU用UserDataをファイルに保存してBase64エンコード
LOGIN_USERDATA_B64=$(cat login-gpu-userdata.txt | base64)
# Compute Launch Template(GPU/CPU共通、Private Subnet用)
COMPUTE_LT_ID=$(aws ec2 create-launch-template \
--launch-template-name "compute-dlami-pcs-relion" \
--launch-template-data "{
\"TagSpecifications\": [{\"ResourceType\": \"instance\", \"Tags\": [{\"Key\": \"HPCRecipes\", \"Value\": \"true\"}]}],
\"MetadataOptions\": {\"HttpEndpoint\": \"enabled\", \"HttpPutResponseHopLimit\": 4, \"HttpTokens\": \"required\"},
\"SecurityGroupIds\": [\"${VPC_DEFAULT_SG}\", \"${CLUSTER_SG_ID}\", \"${EFS_SG}\", \"${FSX_SG}\"],
\"UserData\": \"${COMPUTE_USERDATA_B64}\"
}" \
--query "LaunchTemplate.LaunchTemplateId" \
--output text --region us-east-2)
# Login GPU Launch Template(Public Subnet用、SSH SG + KeyName + DCV付き)
LOGIN_LT_ID=$(aws ec2 create-launch-template \
--launch-template-name "login-gpu-dlami-pcs-relion" \
--launch-template-data "{
\"TagSpecifications\": [{\"ResourceType\": \"instance\", \"Tags\": [{\"Key\": \"HPCRecipes\", \"Value\": \"true\"}]}],
\"MetadataOptions\": {\"HttpEndpoint\": \"enabled\", \"HttpPutResponseHopLimit\": 4, \"HttpTokens\": \"required\"},
\"KeyName\": \"${YOUR_KEY_NAME}\",
\"SecurityGroupIds\": [\"${VPC_DEFAULT_SG}\", \"${CLUSTER_SG_ID}\", \"${SSH_SG_ID}\", \"${EFS_SG}\", \"${FSX_SG}\"],
\"UserData\": \"${LOGIN_USERDATA_B64}\"
}" \
--query "LaunchTemplate.LaunchTemplateId" \
--output text --region us-east-2)${YOUR_KEY_NAME}は登録済みのキーペア名を指定してください。
NodeGroup + キュー作成
全ノードでDLAMI AMI(${DLAMI_AMI_ID})を使用します。
# GPU Login NodeGroup (g6.xlarge)
aws pcs create-compute-node-group \
--cluster-identifier ${CLUSTER_ID} \
--compute-node-group-name login-gpu \
--ami-id ${DLAMI_AMI_ID} \
--subnet-ids ${PUBLIC_SUBNET_ID} \
--iam-instance-profile-arn ${INSTANCE_PROFILE_ARN} \
--scaling-configuration "minInstanceCount=1,maxInstanceCount=1" \
--instance-configs '[{"instanceType":"g6.xlarge"}]' \
--custom-launch-template "id=${LOGIN_LT_ID},version=1" \
--region us-east-2
# login-gpuのNodeGroupがACTIVEになるまで待機
# GPU Compute NodeGroup (g6e.4xlarge)
aws pcs create-compute-node-group \
--cluster-identifier ${CLUSTER_ID} \
--compute-node-group-name gpu-nodes \
--ami-id ${DLAMI_AMI_ID} \
--subnet-ids ${PRIVATE_SUBNET_ID} \
--iam-instance-profile-arn ${INSTANCE_PROFILE_ARN} \
--scaling-configuration "minInstanceCount=0,maxInstanceCount=4" \
--instance-configs '[{"instanceType":"g6e.4xlarge"}]' \
--custom-launch-template "id=${COMPUTE_LT_ID},version=1" \
--region us-east-2
# CPU Compute NodeGroup (c7i.4xlarge) - 同じDLAMI AMI + 同じCompute LT
aws pcs create-compute-node-group \
--cluster-identifier ${CLUSTER_ID} \
--compute-node-group-name cpu-nodes \
--ami-id ${DLAMI_AMI_ID} \
--subnet-ids ${PRIVATE_SUBNET_ID} \
--iam-instance-profile-arn ${INSTANCE_PROFILE_ARN} \
--scaling-configuration "minInstanceCount=0,maxInstanceCount=4" \
--instance-configs '[{"instanceType":"c7i.4xlarge"}]' \
--custom-launch-template "id=${COMPUTE_LT_ID},version=1" \
--region us-east-2
# gpu-nodesとcpu-nodesのNodeGroupがACTIVEになるまで待機
# 作成したNodeGroupのIDを取得
GPU_NG_ID=$(aws pcs list-compute-node-groups --cluster-identifier ${CLUSTER_ID} \
--query "computeNodeGroups[?name=='gpu-nodes'].id" --output text --region us-east-2)
CPU_NG_ID=$(aws pcs list-compute-node-groups --cluster-identifier ${CLUSTER_ID} \
--query "computeNodeGroups[?name=='cpu-nodes'].id" --output text --region us-east-2)
# キュー作成
aws pcs create-queue --cluster-identifier ${CLUSTER_ID} --queue-name gpu-queue \
--compute-node-group-configurations "[{\"computeNodeGroupId\":\"${GPU_NG_ID}\"}]" --region us-east-2
aws pcs create-queue --cluster-identifier ${CLUSTER_ID} --queue-name cpu-queue \
--compute-node-group-configurations "[{\"computeNodeGroupId\":\"${CPU_NG_ID}\"}]" --region us-east-2gpu-queueとcpu-queueキューがアクティブになるまで少し待ちます。
(オプション)デフォルトリソースの削除
RELION実行用に新しいNodeGroupとキューが作成できたのちに、Getting Started Templateで作成されたデフォルトリソースは今回不要となるのでリソースを削除します。本手順の実行はオプションです。
# デフォルトリソースのID取得
DEMO_QUEUE_ID=$(aws pcs list-queues --cluster-identifier ${CLUSTER_ID} \
--query "queues[?name=='demo'].id" --output text --region us-east-2)
COMPUTE1_NG_ID=$(aws pcs list-compute-node-groups --cluster-identifier ${CLUSTER_ID} \
--query "computeNodeGroups[?name=='compute-1'].id" --output text --region us-east-2)
OLD_LOGIN_NG_ID=$(aws pcs list-compute-node-groups --cluster-identifier ${CLUSTER_ID} \
--query "computeNodeGroups[?name=='login'].id" --output text --region us-east-2)
# demoキュー削除(キューを先に削除してからNodeGroupを削除します)
aws pcs delete-queue --cluster-identifier ${CLUSTER_ID} \
--queue-identifier ${DEMO_QUEUE_ID} --region us-east-2
# demoキューが削除されるまで少し待ってから以下を実行してください。
# compute-1コンピュートノードグループ削除
aws pcs delete-compute-node-group --cluster-identifier ${CLUSTER_ID} \
--compute-node-group-identifier ${COMPUTE1_NG_ID} --region us-east-2
# loginコンピュートノードグループ削除
aws pcs delete-compute-node-group --cluster-identifier ${CLUSTER_ID} \
--compute-node-group-identifier ${OLD_LOGIN_NG_ID} --region us-east-2
# 削除確認(login-gpu, cpu-nodes, gpu-nodes の3つだけ残っていればOK)
aws pcs list-compute-node-groups --cluster-identifier ${CLUSTER_ID} \
--query "computeNodeGroups[].name" --output text --region us-east-24.4 Amazon DCVのセキュリティグループ設定
セキュリティグループにDCVポートを追加します(TCP + UDP。UDPはQUICプロトコルによる低遅延ストリーミングに使用します)。${YOUR_IP}/32はクラスター作成時に指定したClientIpCidrと同じパブリックIPを使用してください:
aws ec2 authorize-security-group-ingress --group-id ${SSH_SG_ID} \
--protocol tcp --port 8443 --cidr ${YOUR_IP}/32 --region us-east-2
aws ec2 authorize-security-group-ingress --group-id ${SSH_SG_ID} \
--protocol udp --port 8443 --cidr ${YOUR_IP}/32 --region us-east-2DCVへのアクセス確認
ブラウザで https://<LOGIN_GPU_NODE_IP>(login-gpuで作成したインスタンスに付与されているグローバルアドレス):8443 にアクセスし、ec2-user / dcvpassword でDCVにログインができるか確認をしてください。ブラウザ上証明書の警告が表示されますが、確認をしながらアクセスを進めてください。
4.5 RELIONと依存ライブラリのインストール
RELIONのビルドにはPCS AMIにプリインストールされたOpenMPI(/opt/amazon/openmpi/)を使用します。
# LOGIN NODEにSSHでログインします。
ssh -i "${YOUR_KEY_NAME}が置かれている絶対パス" ec2-user@${LOGIN_NODE_IP}
# wxWidgets 3.2.5(CTFFIND用。ビルドに9分弱時間が掛かる)
cd /home/software/src
wget https://github.com/wxWidgets/wxWidgets/releases/download/v3.2.5/wxWidgets-3.2.5.tar.bz2
tar -xjf wxWidgets-3.2.5.tar.bz2 && cd wxWidgets-3.2.5
cd build
../configure --prefix=/home/software/apps/wxWidgets-3.2.5 --with-gtk=3 --enable-unicode --disable-shared
make -j$(nproc) && make install
# CTFFIND 4.1.14
cd /home/software/src
wget https://grigoriefflab.umassmed.edu/sites/default/files/ctffind-4.1.14.tar.gz -O ctffind-4.1.14.tar.gz
tar -xzf ctffind-4.1.14.tar.gz && cd ctffind-4.1.14
# CTFFIND 4.1.14ではソースの一部でbool型で宣言されているにもかかわらずreturn文がなく、
# C++の未定義動作によりSegmentation Faultが発生します。
# この問題はCTFFIND開発者フォーラムで報告され、開発版では修正済みであることが確認されています。
# 参照: https://grigoriefflab.umassmed.edu/forum/software/ctffind_ctftilt/ctffind_4114_segfault
sed -i 's/^bool ComputeRotationalAverageOfPowerSpectrum/void ComputeRotationalAverageOfPowerSpectrum/' src/programs/ctffind/ctffind.cpp
sed -i 's/^bool RescaleSpectrumAndRotationalAverage/void RescaleSpectrumAndRotationalAverage/' src/programs/ctffind/ctffind.cpp
# ビルド(OpenMP有効化を指定、ビルドに1分弱時間が掛かる)
mkdir build && cd build
../configure --prefix=/home/software/apps/ctffind-4.1.14 \
--with-wx-config=/home/software/apps/wxWidgets-3.2.5/bin/wx-config \
--enable-openmp --disable-debugmode \
CXXFLAGS="-O2 -fopenmp -Wall -pipe" \
LDFLAGS="-L/home/software/apps/wxWidgets-3.2.5/lib -lgomp"
make -j$(nproc) && make install
# RELION 5.0 GPUビルド(ビルドに9分弱時間が掛かる)
cd /home/software/src && git clone https://github.com/3dem/relion.git
cd relion && git checkout ver5.0
mkdir build-gpu && cd build-gpu
cmake .. -DCMAKE_INSTALL_PREFIX=/home/software/apps/relion-gpu-5.0 \
-DCUDA_TOOLKIT_ROOT_DIR=/usr/local/cuda -DGUI=ON -DCUDA=ON \
-DCUDA_ARCH=89 \
-DFETCH_WEIGHTS=OFF \
-DMPI_C_COMPILER=/opt/amazon/openmpi/bin/mpicc \
-DMPI_CXX_COMPILER=/opt/amazon/openmpi/bin/mpicxx
make -j$(nproc) && make install
# RELION 5.0 CPUビルド(ビルドに6分弱時間が掛かる)
cd /home/software/src/relion
mkdir build-cpu && cd build-cpu
cmake .. -DCMAKE_INSTALL_PREFIX=/home/software/apps/relion-cpu-5.0 \
-DGUI=ON -DCUDA=OFF \
-DFETCH_WEIGHTS=OFF \
-DMPI_C_COMPILER=/opt/amazon/openmpi/bin/mpicc \
-DMPI_CXX_COMPILER=/opt/amazon/openmpi/bin/mpicxx
make -j$(nproc) && make install4.5.1 Environment Modulesの設定
RELIONのGPU/CPUビルド版をEnvironment Modulesで切り替えるためのmodulefileを作成します。
# relion/gpu modulefile
mkdir -p /home/software/modulefiles/relion
cat > /home/software/modulefiles/relion/gpu <<'MODEOF'
#%Module1.0
proc ModulesHelp { } { puts stderr "RELION 5.0 GPU build (CUDA enabled)" }
module-whatis "RELION 5.0 GPU build"
conflict relion
set basedir /home/software/apps/relion-gpu-5.0
prepend-path PATH $basedir/bin
prepend-path LD_LIBRARY_PATH $basedir/lib
prepend-path PATH /home/software/apps/ctffind-4.1.14/bin
prepend-path PATH /opt/amazon/openmpi/bin
prepend-path LD_LIBRARY_PATH /opt/amazon/openmpi/lib64
prepend-path PATH /usr/local/cuda/bin
prepend-path LD_LIBRARY_PATH /usr/local/cuda/lib64
setenv RELION_CTFFIND_EXECUTABLE /home/software/apps/ctffind-4.1.14/bin/ctffind
MODEOF
# relion/cpu modulefile
cat > /home/software/modulefiles/relion/cpu <<'MODEOF'
#%Module1.0
proc ModulesHelp { } { puts stderr "RELION 5.0 CPU build (no CUDA)" }
module-whatis "RELION 5.0 CPU build"
conflict relion
set basedir /home/software/apps/relion-cpu-5.0
prepend-path PATH $basedir/bin
prepend-path LD_LIBRARY_PATH $basedir/lib
prepend-path PATH /home/software/apps/ctffind-4.1.14/bin
prepend-path PATH /opt/amazon/openmpi/bin
prepend-path LD_LIBRARY_PATH /opt/amazon/openmpi/lib64
setenv RELION_CTFFIND_EXECUTABLE /home/software/apps/ctffind-4.1.14/bin/ctffind
MODEOF
# MODULEPATHを~/.bashrcに追加
echo 'export MODULEPATH=/home/software/modulefiles:${MODULEPATH:-}' >> ~/.bashrc
source ~/.bashrcこれで以下のコマンドでGPU/CPUビルドを切り替えられます:
module load relion/gpu # GPU処理(2D/3D Classification, Refinement)
module load relion/cpu # CPU処理(Motion Correction, CTF Estimation)
# EC2からログアウト
exit4.6 FSx for Lustreスループット調整とDRA作成(オプション)
このセクションはオプションです。FSx for Lustreのスループット調整とS3 Data Repository Association(DRA)は、RELIONの実行自体には必須ではありません。Getting Started Templateで作成されたFSx for Lustre(デフォルト125 MB/s/TiB)のままでもRELIONジョブは正常に動作します。大規模データセットの処理やS3との双方向同期が必要な場合に設定が必要となるので、参考の手順として示します。
# スループット更新(125 → 250 MB/s/TiB、変更完了まで時間が掛かる)
aws fsx update-file-system --file-system-id ${FSX_ID} \
--lustre-configuration PerUnitStorageThroughput=250 --region us-east-2
# FSxのコンソール画面で、Lustreの該当ファイルシステムのライフサイクルの状態が「更新中」になります。それが完了するまで待つこと。
# S3バケット作成
AWS_ACCOUNT_ID=$(aws sts get-caller-identity --query Account --output text)
aws s3 mb s3://pcs-relion-data-${AWS_ACCOUNT_ID} --region us-east-2
# DRA作成(双方向同期)
aws fsx create-data-repository-association \
--file-system-id ${FSX_ID} \
--file-system-path /shared/data \
--data-repository-path s3://pcs-relion-data-${AWS_ACCOUNT_ID}/datasets/ \
--s3 '{"AutoImportPolicy":{"Events":["NEW","CHANGED","DELETED"]},"AutoExportPolicy":{"Events":["NEW","CHANGED","DELETED"]}}' \
--batch-import-meta-data-on-create --region us-east-24.7 CloudWatch監視設定(オプション)
このセクションもオプションです。CloudWatch監視はRELIONの実行には必須ではありませんが、Slurmスケジューラーのログ確認やDRA同期状態の監視に有用です。
PCS Scheduler / Job Completion ログ
HPC Recipesの CloudWatch Log Delivery テンプレートを使用して、PCSのScheduler LogsとJob Completion LogsをCloudWatchに送信します。これにより、Slurmスケジューラーの動作ログとジョブ完了ログをCloudWatchコンソールから確認できます。
aws cloudformation create-stack \
--stack-name pcs-relion-cloudwatch-logs \
--template-url https://aws-hpc-recipes.s3.us-east-1.amazonaws.com/main/recipes/pcs/cloudwatch/assets/cloudwatch_log_delivery.cfn.yaml \
--parameters ParameterKey=PCSClusterId,ParameterValue=${CLUSTER_ID} \
--capabilities CAPABILITY_NAMED_IAM CAPABILITY_AUTO_EXPAND \
--region us-east-2作成されるCloudWatch LogGroup:
/aws/vendedlogs/pcs/cluster/PCS_SCHEDULER_LOGS/<CLUSTER_ID>/aws/vendedlogs/pcs/cluster/PCS_JOBCOMP_LOGS/<CLUSTER_ID>
5. ジョブ実行例
5.1 テストデータセットの準備
RELION 5.0公式チュートリアルのテストデータ(beta-galactosidase、EMPIAR-10204)を使用します。
# LOGIN NODEにSSHでログインします。
ssh -i "${YOUR_KEY_NAME}が置かれている絶対パス" ec2-user@${LOGIN_NODE_IP}
mkdir -p /shared/relion-test && cd /shared/relion-test
wget ftp://ftp.mrc-lmb.cam.ac.uk/pub/scheres/relion30_tutorial_data.tar
tar -xf relion30_tutorial_data.tar
rm -f relion30_tutorial_data.tar展開後、/shared/relion-test/relion30_tutorial/Movies/にテストデータ(.tiffファイル)が配置されます。
5.2 Importジョブの実行
RELIONでは最初にImportジョブを実行して、動画ファイルのパスとoptics情報をSTARファイルに登録する必要があります。RELION 5.0ではopticsグループ(電圧、球面収差、ピクセルサイズ等)がSTARファイルに必須です。
module load relion/cpu
cd /shared/relion-test
mkdir -p Import/job001
relion_import --do_movies --optics_group_name opticsGroup1 \
--angpix 0.885 --kV 200 --Cs 1.4 --Q0 0.1 \
--beamtilt_x 0 --beamtilt_y 0 \
--i "relion30_tutorial/Movies/*.tiff" \
--odir Import/job001/ --ofile movies.starパラメータはRELION公式チュートリアルデータ(EMPIAR-10204、beta-galactosidase)の撮像条件に基づいています:
--angpix 0.885: ピクセルサイズ(Å/pixel)--kV 200: 加速電圧(kV)--Cs 1.4: 球面収差(mm)--Q0 0.1: 振幅コントラスト比
Import/job001 以下にmovies.starファイルが作成されていれば処理は成功しています。
5.3 Motion Correctionの実行
5.3.1 RELION GUIからのジョブ投入
Amazon DCV経由でLoginNodeにログイン後、以下のコマンドでRELIONのGUI画面が表示されます。
# DCV経由でLogin Nodeに接続後
source ~/.bashrc
module load relion/cpu
cd /shared/relion-test
relion &GUIでジョブを投入する場合、あらかじめSubmission.shを作成しておく必要があります。以下のコマンドでTemplateのシェルスクリプトを作成しておきます(CPU queueに投げる場合のsubmission.shです)。
cat > /home/software/apps/relion-submission.sh << 'EOF'
#!/bin/bash
#SBATCH --ntasks=XXXmpinodesXXX
#SBATCH --cpus-per-task=XXXthreadsXXX
#SBATCH --time=24:00:00
#SBATCH --partition=XXXqueueXXX
#SBATCH --job-name=XXXnameXXX
#SBATCH --output=XXXoutfileXXX
#SBATCH --error=XXXerrfileXXX
source /etc/profile.d/modules.sh
export MODULEPATH=/home/software/modulefiles:${MODULEPATH:-}
module purge
module load relion/cpu
export OMP_NUM_THREADS=${SLURM_CPUS_PER_TASK}
export OMPI_MCA_rmaps_base_mapping_policy=slot:PE=${SLURM_CPUS_PER_TASK}
export OMPI_MCA_hwloc_base_binding_policy=core
if [ ${SLURM_NTASKS} -gt 1 ]; then
mpirun -np ${SLURM_NTASKS} XXXcommandXXX
else
XXXcommandXXX
fi
EOFchmod +x /home/software/apps/relion-submission.shRELION GUI経由でPCSにジョブを投入する場合は、各処理プロセスのRunningタブで以下を設定する必要があります。
- Queue name:
gpu-queue(GPU処理)またはcpu-queue(CPU処理) - Submit to queue?: Yesに変更する
参考例としてGUIによる実行例を示します。Motion correctionの処理をGUIから行う場合です。
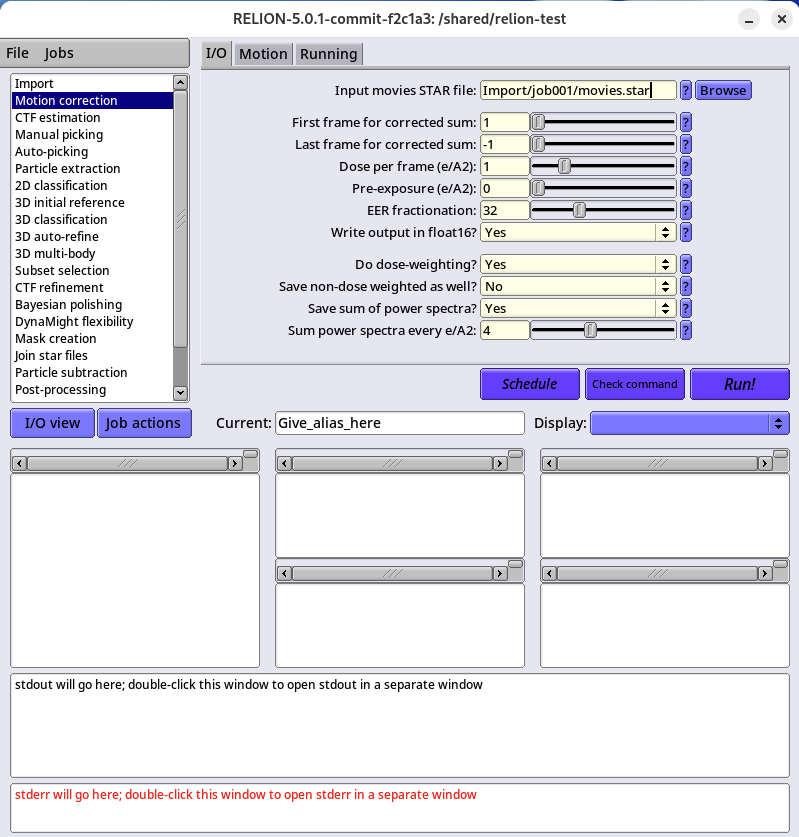
Input movies STAR file:に「Import/job001/movies.star」を指定する
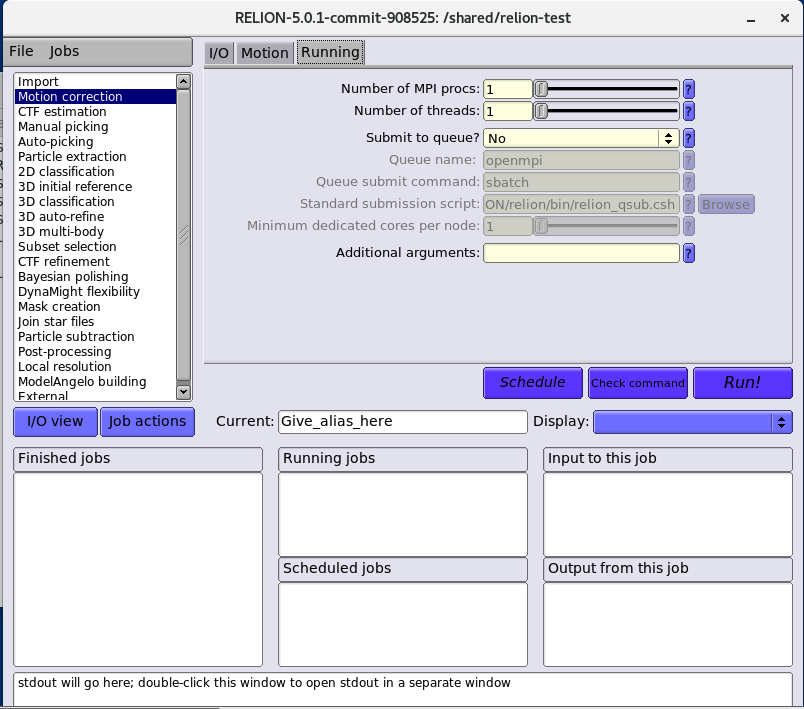
Runningタブを選択し、以下の項目を変更します。
| 項目 | 設定値 |
|---|---|
| Number of MPI procs | 2 |
| Number of threads | 4 |
| Submit to queue? | Yes |
| Queue name | cpu-queue |
| Queue submit command | sbatch |
| Standard submission script | /home/software/apps/relion-submission.sh |
変更後「Run!」でPCSにジョブが投入されます。
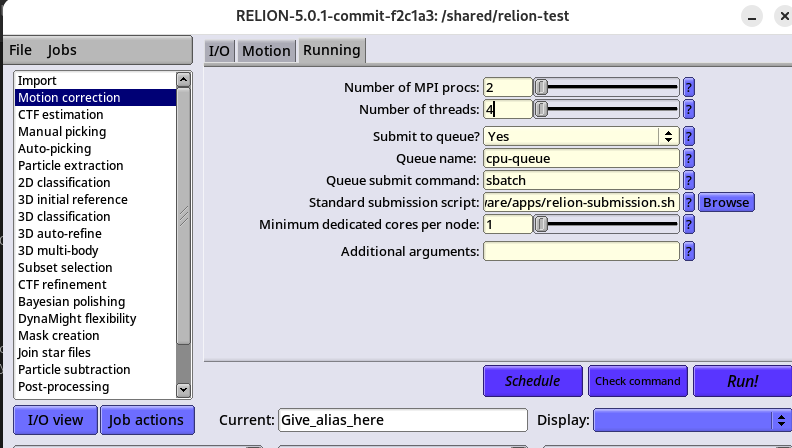
他の解析処理も同様のGUI操作でPCSにジョブが投入可能です。以降のRELIONのサンプル実行はCUIベースで説明しますが、同じ処理をGUIでも行うことができます。使いやすい方を選び処理を実行してください。
5.3.2 CUIによるMotion Correctionの実行例(CPUキューでの実行)
Motion Correctionはデフォルトの状態ではCPUで行われる処理になっています。今回の場合はcpu-queueに投入してください。
sbatch --partition=cpu-queue --nodes=1 --ntasks=2 --cpus-per-task=4 \
--time=02:00:00 --job-name=relion_motioncorr \
--wrap="
source /etc/profile.d/modules.sh
export MODULEPATH=/home/software/modulefiles:\${MODULEPATH:-}
module load relion/cpu
cd /shared/relion-test
mkdir -p MotionCorr/job002
export OMP_NUM_THREADS=\$SLURM_CPUS_PER_TASK
BIND_OPTS='--map-by slot:PE='\$SLURM_CPUS_PER_TASK' --bind-to core'
mpirun \$BIND_OPTS -np \$SLURM_NTASKS \
relion_run_motioncorr_mpi \
--i Import/job001/movies.star \
--o MotionCorr/job002/ \
--use_own --j \$SLURM_CPUS_PER_TASK \
--patch_x 1 --patch_y 1 --bin_factor 1 \
--dose_per_frame 1.0 --angpix 0.885
"MotionCorr/job002以下にstarファイルなどが作成されていれば処理は成功しています。24 micrographs処理は約2分程度かかります。
5.4 CTF Estimationの実行例(CPUキューでの実行)
sbatch --partition=cpu-queue --nodes=1 --ntasks=8 --cpus-per-task=1 \
--time=02:00:00 --job-name=relion_ctf \
--wrap="
source /etc/profile.d/modules.sh
export MODULEPATH=/home/software/modulefiles:\${MODULEPATH:-}
module load relion/cpu
cd /shared/relion-test
mkdir -p CtfFind/job003
export OMP_NUM_THREADS=\$SLURM_CPUS_PER_TASK
BIND_OPTS='--map-by slot:PE='\$SLURM_CPUS_PER_TASK' --bind-to core'
mpirun \$BIND_OPTS -np \$SLURM_NTASKS \
relion_run_ctffind_mpi \
--i MotionCorr/job002/corrected_micrographs.star \
--o CtfFind/job003/ \
--ctffind_exe /home/software/apps/ctffind-4.1.14/bin/ctffind \
--is_ctffind4 --ctfWin 512 --Box 512 \
--ResMin 30 --ResMax 5 --dFMin 1000 --dFMax 50000 --FStep 500 --dAst 100 \
--j \$SLURM_CPUS_PER_TASK
"CtfFind/job003以下にepsやstarファイルが生成されていれば処理は成功しています。CTF推定の完了には約1分程度かかります。
5.5 Auto-picking と Particle Extraction(CPU処理)
CTF Estimation後、2D Classificationに進むにはParticle Picking(粒子選択)とExtraction(粒子抽出)が必要です。ここではRELIONのLoG(Laplacian-of-Gaussian)フィルタによるテンプレートフリーのAuto-pickingを使用します。チュートリアルデータ(24 micrographs)であればLogin Node上で数十秒で完了するため、sbatchではなく直接実行します。
# Login NodeにSSH接続した状態で実行
module load relion/cpu
cd /shared/relion-test
# LoG Auto-picking(テンプレートフリー、CPU処理)
mkdir -p AutoPick/job004
relion_autopick \
--i CtfFind/job003/micrographs_ctf.star \
--odir AutoPick/job004/ \
--LoG \
--LoG_diam_min 150 --LoG_diam_max 180 \
--shrink 0 --lowpass 20 \
--LoG_adjust_threshold 0 --LoG_upper_threshold 5上記処理は30秒弱で終了します。AutoPick/job004の下にファイルが作成されていれば処理は成功しています。
今回指定しているパラメータの例を以下に示します。
LoG Auto-pickingのパラメータ:
--LoG_diam_min 150 --LoG_diam_max 180: 粒子の直径範囲(Å)。beta-galactosidaseの場合150-180Å--LoG_adjust_threshold 0: ピッキング閾値の調整(正の値で少なく、負の値で多くピックします)--LoG_upper_threshold 5: 高コントラスト汚染(氷滴等)を除外する上限閾値
# Particle Extraction(256px → 64pxにダウンスケール)
mkdir -p Extract/job005
relion_preprocess \
--i CtfFind/job003/micrographs_ctf.star \
--coord_dir AutoPick/job004/ \
--coord_suffix _autopick.star \
--part_star Extract/job005/particles.star \
--part_dir Extract/job005/ \
--extract --extract_size 256 --scale 64 \
--norm --bg_radius 25 --white_dust -1 --black_dust -1 \
--invert_contrast --float16上記処理は15秒程度で終了します。Extract/job005の下にparticles.starファイルが生成されていれば処理は成功しています。
Particle Extractionのパラメータ:
--extract_size 256: 抽出ボックスサイズ(ピクセル)--scale 64: 64pxにダウンスケール(初期分類の高速化のため)--bg_radius 25: 背景領域の半径(ピクセル、スケール後のサイズに対して指定します。64pxの約75%÷2で25)--invert_contrast: 黒い粒子を白に反転(RELION内部処理用)
5.6 2D Classification の実行例(GPUキューでの実行)
2D ClassificationはGPUによって処理が高速化される処理工程です。今回作成したgpu-queueにジョブを投入します。
5.5のAuto-picking + Particle Extractionで生成されたExtract/job005/particles.starを入力として使用します。
GPU Compute Node(g6e.4xlarge、NVIDIA L40S)でRELIONのGPUビルドを使用します。初回のgpu-queueへのジョブ投入時は、ノード起動待機時間として5分程度インスタンス起動の待ち時間がかかります。
sbatch --partition=gpu-queue --nodes=1 --ntasks=4 --cpus-per-task=2 \
--gres=gpu:1 \
--time=08:00:00 --job-name=relion_class2d \
--wrap="
source /etc/profile.d/modules.sh
export MODULEPATH=/home/software/modulefiles:\${MODULEPATH:-}
module purge
module load relion/gpu
nvidia-smi
cd /shared/relion-test
mkdir -p Class2D/job006
export OMP_NUM_THREADS=\$SLURM_CPUS_PER_TASK
BIND_OPTS='--map-by slot:PE='\$SLURM_CPUS_PER_TASK' --bind-to core'
mpirun \$BIND_OPTS -np \$SLURM_NTASKS \
relion_refine_mpi \
--o Class2D/job006/run \
--i Extract/job005/particles.star \
--dont_combine_weights_via_disc \
--pool 30 --pad 2 \
--ctf --iter 25 \
--tau2_fudge 2 \
--particle_diameter 200 \
--K 50 \
--flatten_solvent \
--zero_mask \
--oversampling 1 \
--psi_step 12 --offset_range 5 --offset_step 2 \
--norm --scale \
--j \$SLURM_CPUS_PER_TASK \
--gpu 0
"Class2D/job006以下に各種starファイルが生成されていれば処理は成功しています。GPU Compute Node(g6e.4xlarge)でNVIDIA L40S のGPUが検出されていることも確認しながら、relion_refine (GPU) 動作を確認する流れになっています。
なお、今回のRELIONの処理例はあくまでもサンプル実行例として示したものです。各処理工程のパラメータ等の設定は扱うデータにより異なります。RELIONのパラメータ設定はRELIONのマニュアルなどを参考し、正確に処理を行う際は適した設定を行う必要がありますので、その点はご承知おきください。
sacctによるジョブ履歴確認
ManagedAccounting=enabledでクラスターを作成しているので、sacctコマンドでジョブの実行履歴を確認できます:
# 全ジョブ履歴
sacct --format=JobID,JobName,Partition,State,ExitCode,Elapsed,Start,End
# 特定ジョブの詳細(メモリ使用量含む)
sacct -j <JOB_ID> --format=JobID,State,ExitCode,NodeList,Elapsed,MaxRSS
# SSHからのログアウト
exit6. クリーンアップ
検証が完了したら、以下の手順でリソースを削除します。PCSリソースは依存関係があるため、削除順序が重要です。
6.1 PCSキューの削除
# CLUSTER_IDの取得
CLUSTER_ID=$(aws cloudformation describe-stacks --stack-name pcs-relion \
--query "Stacks[0].Outputs[?OutputKey=='ClusterId'].OutputValue" \
--output text --region us-east-2)
# キュー一覧を確認
aws pcs list-queues --cluster-identifier ${CLUSTER_ID} --region us-east-2
# 各キューのIDを取得
GPU_QUEUE_ID=$(aws pcs list-queues --cluster-identifier ${CLUSTER_ID} \
--query "queues[?name=='gpu-queue'].id" --output text --region us-east-2)
CPU_QUEUE_ID=$(aws pcs list-queues --cluster-identifier ${CLUSTER_ID} \
--query "queues[?name=='cpu-queue'].id" --output text --region us-east-2)
# 各キューを削除
aws pcs delete-queue --cluster-identifier ${CLUSTER_ID} --queue-identifier ${GPU_QUEUE_ID} --region us-east-2
aws pcs delete-queue --cluster-identifier ${CLUSTER_ID} --queue-identifier ${CPU_QUEUE_ID} --region us-east-26.2 PCS NodeGroupの削除
キュー削除後にNodeGroupを削除します。
# NodeGroup一覧を確認
aws pcs list-compute-node-groups --cluster-identifier ${CLUSTER_ID} \
--query "computeNodeGroups[].[name,id]" --output table --region us-east-2
# 各NodeGroupを削除
for NG_NAME in login-gpu gpu-nodes cpu-nodes; do
NG_ID=$(aws pcs list-compute-node-groups --cluster-identifier ${CLUSTER_ID} \
--query "computeNodeGroups[?name=='${NG_NAME}'].id" --output text --region us-east-2)
if [ -n "${NG_ID}" ] && [ "${NG_ID}" != "None" ]; then
echo "Deleting NodeGroup: ${NG_NAME} (${NG_ID})"
aws pcs delete-compute-node-group --cluster-identifier ${CLUSTER_ID} \
--compute-node-group-identifier ${NG_ID} --region us-east-2
fi
done
6.3 Launch Templateの削除
aws ec2 delete-launch-template --launch-template-name compute-dlami-pcs-relion --region us-east-2
aws ec2 delete-launch-template --launch-template-name login-gpu-dlami-pcs-relion --region us-east-26.4 PCSクラスター + 関連リソースの削除(CloudFormationスタック)
# PCSクラスタースタックの削除(VPC、EFS、FSx Lustre、セキュリティグループ等すべて含む)
aws cloudformation delete-stack --stack-name pcs-relion --region us-east-2
echo "Waiting for pcs-relion stack deletion (this may take 10-20 minutes)..."
aws cloudformation wait stack-delete-complete --stack-name pcs-relion --region us-east-2
echo "pcs-relion stack deleted."
# オプションで作成した場合のスタックの削除(CloudwatchのLogsを追加した場合に削除が必要)
aws cloudformation delete-stack --stack-name pcs-relion-cloudwatch-logs --region us-east-2
# (オプション) LustreとDRA設定をしたS3バケットの削除(格納されているファイルも含めて削除)
AWS_ACCOUNT_ID=$(aws sts get-caller-identity --query Account --output text)
aws s3 rb s3://pcs-relion-data-${AWS_ACCOUNT_ID} --force --region us-east-2
6.5 ImageBuilderスタックの削除
aws cloudformation delete-stack --stack-name dlami-for-pcs --region us-east-2
aws cloudformation wait stack-delete-complete --stack-name dlami-for-pcs --region us-east-2
echo "dlami-for-pcs stack deleted."6.6 カスタムAMIの登録解除(オプション)
ImageBuilderで作成したAMIが不要な場合は登録解除します。
# AMI IDを取得
DLAMI_AMI_ID=$(aws ec2 describe-images \
--owners self \
--filters "Name=name,Values=dlami-for-pcs-base-al2023-x86_64*" \
--query 'Images[*].[ImageId,Name]' \
--output table --region us-east-2)
echo "${DLAMI_AMI_ID}"
# 各AMIを登録解除(複数ビルドした場合は複数存在する可能性あり)
for AMI_ID in $(aws ec2 describe-images \
--owners self \
--filters "Name=name,Values=dlami-for-pcs-base-al2023-x86_64*" \
--query 'Images[*].ImageId' \
--output text --region us-east-2); do
echo "Deregistering AMI: ${AMI_ID}"
# 関連するスナップショットを取得
SNAP_IDS=$(aws ec2 describe-images --image-ids ${AMI_ID} \
--query 'Images[0].BlockDeviceMappings[*].Ebs.SnapshotId' \
--output text --region us-east-2)
# AMI登録解除
aws ec2 deregister-image --image-id ${AMI_ID} --region us-east-2
# 関連スナップショットの削除
for SNAP_ID in ${SNAP_IDS}; do
echo " Deleting snapshot: ${SNAP_ID}"
aws ec2 delete-snapshot --snapshot-id ${SNAP_ID} --region us-east-2
done
done6.7 削除確認
# CloudFormationスタックが残っていないか確認
aws cloudformation list-stacks \
--stack-status-filter CREATE_COMPLETE UPDATE_COMPLETE \
--query "StackSummaries[?contains(StackName,'pcs-relion') || contains(StackName,'dlami-for-pcs')].StackName" \
--output text --region us-east-2
# カスタムAMIが残っていないか確認
aws ec2 describe-images --owners self \
--filters "Name=name,Values=dlami-for-pcs*" \
--query 'Images[*].[ImageId,Name]' \
--output table --region us-east-27. コスト最適化のポイント
7.1 処理ステップに応じたインスタンスタイプの選択
RELIONの解析工程ごとにCPU/GPU要求が異なるため、適切なインスタンスタイプを選択することでコスト最適化が可能です。
- CPU中心の処理: Motion Correction、CTF Estimation、Particle Picking → c7iインスタンスなどのCPUインスタンス
- GPU中心の処理: 2D/3D Classification、3D Refinement → g6eインスタンスなどのGPUインスタンスを用いる
大学共同利用機関法人 高エネルギー加速器研究機構(KEK)による研究論文「GoToCloud optimization of cloud computing environment for accelerating cryo-EM structure-based drug design(Moriya et al., Communications Biology, 2024)」では、AWS ParallelCluster上でEC2インスタンスタイプの使い分けによるコストパフォーマンス最適化が実証され、報告されています。PCSにおいても同様のインスタンス選択の考え方が適用可能と考えます。
今回紹介したアーキテクチャや手順を参考にRELIONの処理ステップに応じてPCSで作成するcpu-queueとgpu-queueを使い分けることで、処理時間の短時間化とコスト最適化を図ることができます。
7.2 自動スケーリングの活用
本ブログの構成では、GPU/CPUコンピュートノードグループのminInstanceCountを0に設定しています。これにより、ジョブが投入されるとPCSが自動的にインスタンスを起動し、ジョブ完了後はアイドルタイムアウト(デフォルト10分)経過後に自動的にインスタンスを終了します。解析を行っていない時間帯のコンピュートノードのコストはゼロになります。
PCSの自動スケーリング機能を活用することで、アイドルコストを削減できます。
- ジョブ完了後の自動停止
- 推奨設定: アイドルタイムアウト5〜10分(デフォルトは600秒で10分の設定です)
7.3 効率的なストレージコスト管理とS3ライフサイクル管理
効率的なストレージコスト管理のため、以下の戦略を採用することをおすすめします。
- S3 + FSx Lustre DRA連携: 必要なデータのみをFSx Lustreにキャッシュ
- S3ライフサイクルポリシー: Intelligent-Tiering、Glacierへの自動移行
- FSx Lustreの使用後削除・再作成: 長期間使用しない場合は削除してコスト削減
Cryo-EMデータは長期保存が必要ですが、すべてのデータを高速ストレージに保持し続ける必要はないものと考えます。S3のライフサイクル管理を活用して、コストを最適化できます。以下にストレージクラスの選択指針の例を示します。
ストレージクラスの選択指針:
- S3 Standard: アクティブな処理中のデータ(0-30日)
- S3 Intelligent-Tiering: アクセスパターンが不明なデータ(自動最適化)
- S3 Glacier Flexible Retrieval: 年に数回アクセスするデータ(90日以降)
- S3 Glacier Deep Archive: ほとんどアクセスしないアーカイブデータ(1年以降)
考え方の参考にしていただければ幸いです。
8. 結論
AWS Parallel Computing Serviceは、Cryo-EMをクラウドで実行するためのスケーラブルなソリューションを提供し、研究者が新しい科学的発見に集中できる環境を実現します。
本ブログでは、オープンソースのCryo-EM解析ソフトウェアであるRELIONをPCS上で動かす方法を紹介しました。RELIONは世界中の研究者が自由に利用できるソフトウェアです。PCSのマネージドSlurm環境と組み合わせることで、既存のSlurmベースのワークフローをそのままクラウドに持ち込み、オンデマンドでスケールする解析環境を構築できます。
Amazon DCVを使用することで、クラウド上のRELION GUIをローカル環境と同等の操作感で利用でき、粒子の選択や分類結果の確認といったインタラクティブな作業もリモートから快適に行えます。
AWS上のスケーラブルでオンデマンドなコンピューティングにより、科学者のアイデアや意欲の成長に合わせて要求に応えることができます。処理ステップに応じてCPUインスタンスとGPUインスタンスを使い分け、ジョブ完了後はインスタンスが自動的に停止するため、コスト効率の高い運用が可能です。Amazon S3とAmazon FSx for LustreのData Repository Association(DRA)を活用することで、高速な処理性能と低コストな長期保存を両立できます。
本ブログで紹介した手順に沿って、PCS上でのRELIONのサンプル解析環境を構築し、サンプルの処理実行が可能です。ぜひお手元のAWS環境でお試しいただき、PCSの有用性とRELIONの解析の流れをご確認ください。
詳細については、AWSアカウントチームにお問い合わせいただくか、ask-hpc@amazon.com までご連絡ください。