Amazon Web Services ブログ
Amazon SageMaker で分散強化学習を使用して AI 搭載の Battlesnake をスケーリングする
Battlesnake は AI を搭載したヘビを構築する AI コンテストです。Battlesnake のルールは、従来のスネークゲームと類似しています。目標は、他のヘビと競争して、最後まで生き残るヘビになることです。あらゆるレベルの開発者が、独自のヒューリスティックベースの戦略から、最先端の深層強化学習 (RL) アルゴリズムまで、さまざまな技術を駆使してヘビを構築します。
SageMaker Battlesnake Starter Pack を使用して独自のヘビを構築し、Battlesnake アリーナで競うことができます。詳細については、Amazon SageMaker の強化学習を使用して AI で駆動する Battlesnake を構築するを参照してください。Starter Pack には、Amazon SageMaker で複数の戦略を開発するための開発環境が含まれています。戦略には、RL ベースのポリシートレーニングと決定木ベースのヒューリスティックが含まれます。以前の SageMaker Battlesnake Starter Pack では、Deep Q-Network (DQN) [1] ベースのスネークポリシーを開発するための Apache MXNet ベースのトレーニングスクリプトを提供しました。このアルゴリズムの実装は実践および変更が簡単で、初心者の開発者に教育体験を提供します。
この投稿では、フルマネージド型の RL に Amazon SageMaker を使用し、同じトレーニング時間で 10 倍の成果を提供する Starter Pack の更新について説明します。Starter Pack は、分散 RL トレーニングに Amazon SageMaker の組み込み機能を使用します。これにより、インスタンスで使用可能な複数のノードでシミュレーションステップが同時に収集されている間、エージェントのポリシーが更新されます。この投稿では、分散 RL の基本と、Amazon SageMaker で分散 RL を使用してヘビをトレーニングする方法についても説明します。
Amazon SageMaker はフルマネージド型のサービスであり、モデルの構築とデプロイをより速く、より手間をかけずに行うことを可能にします。Amazon SageMaker には、データのラベル付けと準備、モデルのトレーニング、調整、およびデバッグ、そして、本番環境におけるモデルのデプロイとモニタリングを支援する機能が組み込まれています。さらに、Amazon SageMaker には、データへのラベル付けのコストを最大 70% 削減する Amazon SageMaker Ground Truth、トレーニングコストを最大 90% 削減する Managed Spot Training などのコスト節約メカニズムが組み込まれているほか、Amazon SageMaker は Amazon Elastic Inference をサポートし、機械学習の推論コストを最大 75% 削減します。
この投稿では、Amazon SageMaker のフルマネージド型の RL 機能について説明します。これには、事前にパッケージ化された RL ツールキットとフルマネージドモデルのトレーニングとデプロイが含まれます。MXNet や TensorFlow などの組み込み深層学習フレームワークを使用したり、Intel Coach のさまざまな組み込み RL アルゴリズムや RLlib ライブラリを使用して RL ポリシーをトレーニングしたり、Amazon SageMaker Experiments で簡単に RL の実験を開始したりできます。詳細については、Amazon SageMaker Experiments – 機械学習トレーニングを整理、追跡、比較するを参照してください。レコメンデーションシステム、ロボティクス、財務管理などの領域への RL の適用の詳細については、GitHub リポジトリをご覧ください。
分散強化学習
RL エージェントは通常、試行錯誤しながら環境とのインタラクションを通じてポリシーを開発します。トレーニングプロセスの間、エージェントはシミュレーションのステップを収集して学習し、ポリシーを調整します。シミュレーション手順は、エクスペリエンスまたはロールアウトとも呼ばれます。この投稿では、DQN を例として使用しています。DQN は、ターゲットおよびローカルの Q-Network での勾配ベースの最適化のために、リプレイバッファとポリシー間の通信に依存しています。詳細については、Amazon SageMaker の強化学習を使用して AI で駆動する Battlesnake を構築するを参照してください。
次の図は、DQN のさまざまなコンポーネントとデータフローを示しています。
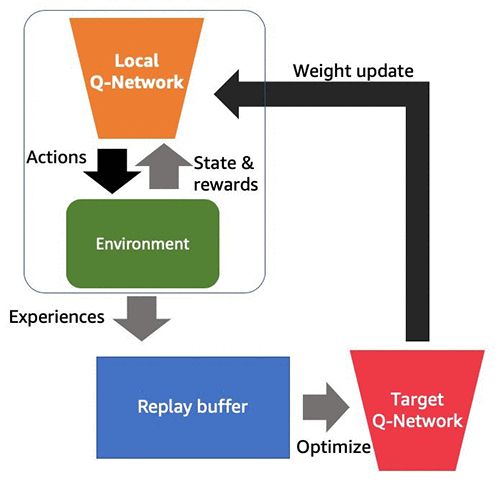
DQN アルゴリズムは複数のコンポーネントで構成され、分散 RL はこれらのコンポーネントの分離可能な性質を利用してトレーニングをスケールアップします。具体的には、分散 RL が複数のロールアウトワーカーを使用してシミュレーターのコピーを作成し、エージェントポリシーのエクスペリエンスを収集します。そして、これらのエクスペリエンスをポリシーの更新に使用します。DQN では、ポリシーオプティマイザーはロールアウトワーカーからサンプルを同期的にプルし、それらを連結します。ネットワークの重みが更新された後、重みはすべてのロールアウトワーカーにブロードキャストされます。アルゴリズムのタイプによっては、このプロセスを非同期にすることができます。たとえば、APEX-DQN [2] のオプティマイザーは、ロールアウトワーカーから勾配を非同期的にプルして適用し、必要に応じて更新された重みを送り返します。次の図は、4 つの CPU を備えた単一の Amazon SageMaker インスタンスに複数のワーカーを持つ分散 RL モデルを示しています。1 つの CPU がドライバーに割り当てられ、残りは環境シミュレーションに使用されます。
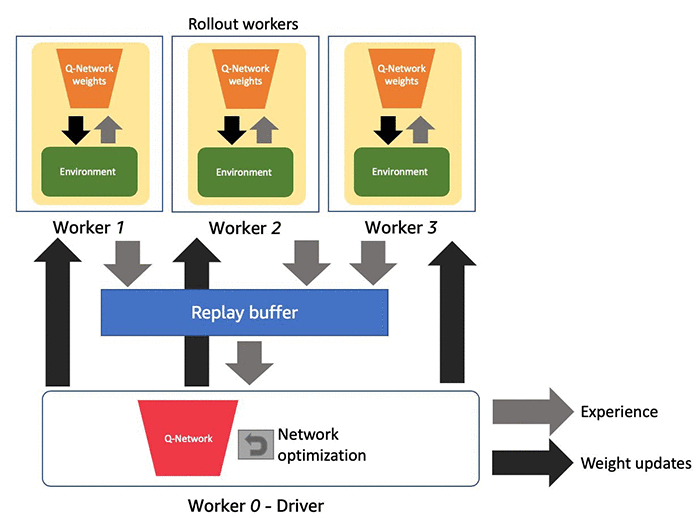
Amazon SageMaker は、Ray RLlib [3] ライブラリを使用して、ほんの数行の構成で単一の Amazon SageMaker ML インスタンスで分散 RL をサポートします。デフォルトでは、Amazon SageMaker は 1 つの CPU をドライバーに割り当てます。ドライバーはトレーニングプロセスを実行し、ワーカー間の調整を管理し、グローバルポリシーパラメータの更新を処理します。残りのリソースは、並列のエクスペリエンスの収集に専念するワーカーとして使用できます。
Amazon SageMaker では、RL ジョブを複数の Amazon SageMaker ML インスタンスにスケーリングすることにより、さらに一歩踏み込むことができます。これにより、トレーニングに使用できるリソースが増加します。トレーニングジョブは、同種スケーリングと異種スケーリングの 2 つの方法で分散できます。
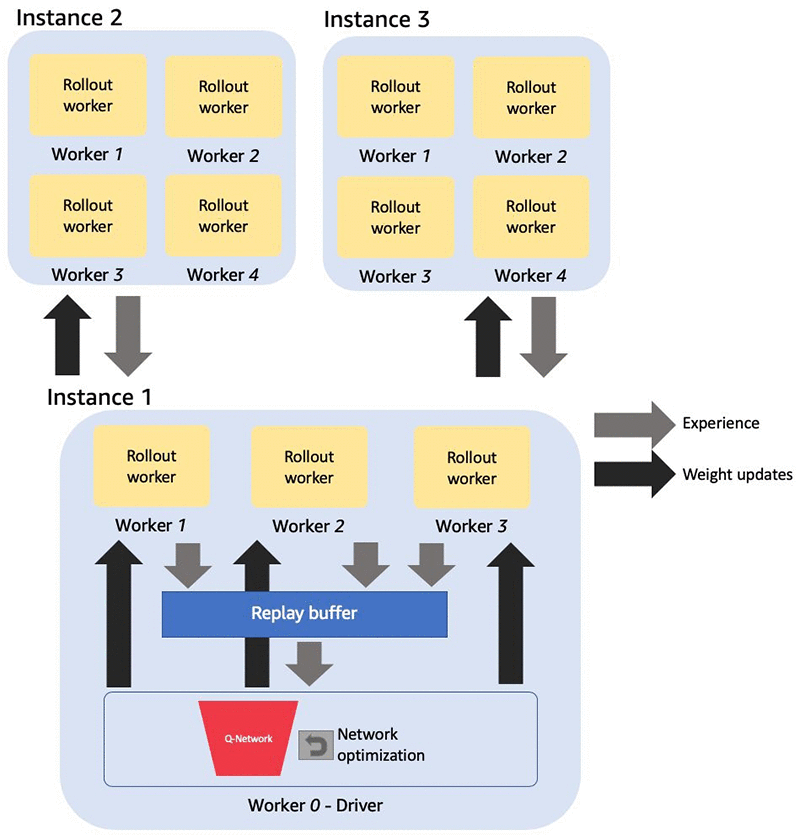
同種スケーリングでは、単一の Amazon SageMaker ジョブに対して同じタイプの複数のインスタンス (通常は CPU インスタンス) を使用します。前に示した構成と同様に、単一の CPU コアがドライバー用に予約されており、残りのすべてをロールアウトワーカーとして使用して、環境シミュレーションを通じてエクスペリエンスを生成できます。使用可能な CPU コアの数は、インスタンスが複数になると増加します。同種スケーリングは、エクスペリエンスの収集がトレーニングワークフローのボトルネックである場合に役立ちます。たとえば、環境が計算上重い場合などです。
次の図は、それぞれ 4 つの CPU を備えた複数のインスタンスを使用した同種スケーリングのアーキテクチャを示しています。プライマリインスタンスの CPU の 1 つはドライバーとして使用され、プライマリインスタンスとセカンダリインスタンスの残りの CPU は環境シミュレーションに使用されます。
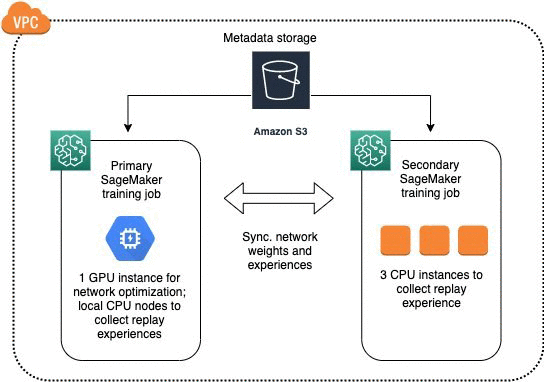
ロールアウトワーカーが増えると、ニューラルネットワークの更新がボトルネックになることがよくあります。この場合、異なるインスタンスタイプを一緒に使用する異種スケーリングを使用できます。一般的には、GPU インスタンスを使用してネットワーク最適化を実行するとともに、CPU インスタンスを使用してエクスペリエンスを収集して、最適化されたコストでより高速なトレーニングを行います。Amazon SageMaker では、同じ Amazon VPC 内で 2 つのジョブをスピンアップすることでこれを実現でき、インスタンス間の通信は自動的に処理されます。
次の図は、プライマリジョブが 1 つの GPU インスタンスを使用し、セカンダリジョブが 3 つの CPU インスタンスを使用するアーキテクチャを示しています。
ユースケースに合うように、特定の数のインスタンスとタイプを設定できます。複数のノードに分散した RL トレーニングの詳細については、GitHub リポジトリの次のノートブックを参照してください。
単一のインスタンスでヘビをトレーニングする
RL トレーニングジョブを実行するには、他の Amazon SageMaker のトレーニングジョブを実行するのと同様のワークフローに従います。すなわち、推定子を使用してトレーニングスクリプトを実行します。次の例では、エントリポイントは、環境とポリシーの間のインターフェイスとなるトレーニングスクリプト (train-mabs.py) です。単一インスタンスの RL トレーニングジョブを立ち上げるには、最初に目的のパラメータを使用して RLEstimator() を作成し、推定子オブジェクトで fit() を呼び出します。次のコードを参照してください。
RL トレーニングを複数のワーカーに自動的にスケーリングするため、rl.training.config.num_cpus および rl.training.config.num_gpus パラメータを調整できます。ドライバーとして機能する 1 つの CPU (num_cpus - 1 の 1) を予約する必要があります。たとえば、単一の Amazon SageMaker インスタンスで複数のワーカーを使用してトレーニングジョブを設定するには、'rl.training.config.num_cpus' = 3 および 'num_gpus' = 0 に設定し、少なくとも 4 つの CPU を持つトレーニングインスタンスタイプを選択します (たとえば ml.c5.xlarge)。
複数のインスタンスを使用したヘビの分散トレーニング
同じタイプの複数のインスタンスを使用して、分散 RL 実験を実行できます (同種スケーリング)。train_instance_count をトレーニングを行うインスタンスの数に設定する必要があります。単一インスタンスのユースケースと同様に、利用可能なリソースの合計に基づいてワーカー数を設定する必要があります。これは、train_instance_count にインスタンスあたりのコア数から 1 を減じたものを乗じることで算出できます。繰り返しになりますが、1 を減じているのはドライバーのためです。次のコードを参照してください。
ロールアウトワーカーの数を増やすと、ポリシーの更新がボトルネックになることがよくあります。これに対処するため、ポリシーの更新に 1 つ以上の GPU を備えたインスタンスを使用し、ロールアウトに複数の CPU インスタンスを使用できます (異種スケーリング)。
具体的には、2 つの Amazon SageMaker ジョブをスピンアップでき、SageMaker RL が 2 つのジョブ間の通信を処理します。この投稿では、プライマリインスタンスを使用して 1 つ以上の GPU インスタンスを参照し、セカンダリインスタンスを使用して CPU インスタンスのクラスターを参照しています。推定子を定義する前に、いくつかのパラメータを定義する必要があります。次のコードを参照してください。
次のコードを使用して、プライマリおよびセカンダリの RLEstimator を定義できます。
実験
このセクションでは、前述の RL 実装と、Amazon SageMaker の組み込み RL アルゴリズムを使用した新しい実装の両方で、ヘビをトレーニングします。以前の RL 実装は MXNet に基づいており、単一コアの単一インスタンスで実行されます。Amazon SageMaker の RL 実験は、以下で構成されています。
- 単一コアの単一インスタンス
- 複数のコアを持つ単一インスタンス
- 複数のコアを持つ複数の同一インスタンス
- 複数のコアを持つ複数の異種インスタンス
DQN が単一インスタンスの実験に使用されたのは、2 つの実装間の実験条件を同様に保つためでした。マルチインスタンスでの実験では、トレーニングバッチのサイズを同じに保ち、収集されたエクスペリエンスをより有効に活用するために非同期ポリシーの更新を有効にしました。分散され、優先順位が付けられたエクスペリエンスのリプレイを使用することにより、データ効率をさらに改善しました。変更されたアルゴリズムは APEX [2] として知られています。この投稿では、すべての実験を 210 分間実行し、同一の報酬関数、環境表現、およびハイパーパラメータを使用します。
トレーニングに関しては、MXNet、単一インスタンス、および同種スケーリングジョブが、同一インスタンスタイプ (ml.m5.xlarge) を使用して実行されます。異種スケーリングジョブのプライマリインスタンスタイプは GPU インスタンス (ml.p2.xlarge) で、セカンダリインスタンスは ml.m5.xlarge です。次のグラフは、平均エピソード報酬で評価されたパフォーマンスを示しています。
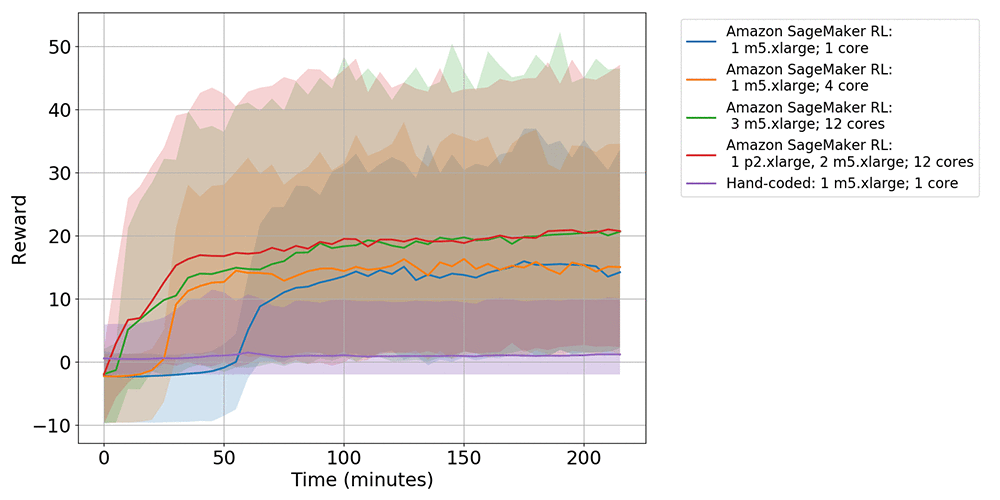
次のグラフは、平均エピソードの長さ (ヘビの生存期間) で評価したパフォーマンスを示しています。

以前のポリシーは 20 時間を超えてトレーニングされました。これは両方のグラフに反映されています。3 時間のトレーニング後に報酬とエピソードの長さがわずかに増加しただけです (ハンドコード: 1 つの m5.xlarge; 1 つのコア)。グラフは、以前のポリシーと現在のポリシーの間で、獲得した報酬が少なくとも 7.5 倍、エピソードの長さが 2 倍長くなっていることを示しています。単一インスタンスジョブを比較すると (Amazon SageMaker RL: 1 つの m5.xlarge、1 つのコアと、Amazon SageMaker RL: 1 つの m5.xlarge、4 つのコア)、複数のコアを持つ単一インスタンスは、単一コアのジョブよりもパフォーマンスが優れています。これは、複数のインスタンスを使用する場合にさらに顕著になります。すなわち、異種スケーリング (Amazon SageMaker RL: 1 つの p2.xlarge、2 つの m5.xlarge、12 個のコア) は、単一インスタンスと同種スケーリングのジョブ (Amazon SageMaker RL: 3 つの m5.xlarge、12 個のコア) よりも優れています。異種スケーリングのジョブでは、以前の実装と比較して、報酬が少なくとも 10 倍、エピソードの長さが 3 倍長くなりました。
まとめ
この投稿では、SageMaker Battlesnake Starter Pack を使用して、分散 RL でヘビをトレーニングする方法を示しています。Amazon SageMaker を使用して構築されたヘビは、このオプションなしで構築されたヘビに比べて、Amazon SageMaker の RL の分散トレーニング機能を使用して同じ時間にわたってトレーニングされた場合に 10 倍の報酬を達成しました。
Amazon SageMaker RL で分散トレーニングを試して、Battlesnake グローバルアリーナでランクを上げることができるかどうかを確認してください。詳細については、Food Banks Canada の資金集めのための Battlesnake: Stay Home and Code イベントの一部である AWS の Xavier Raffin 氏による Amazon SageMaker Battlesnake ワークショップ (4 月 20 日) の動画を Twitch でご覧ください。
参考文献
[1] Mnih, V., Kavukcuoglu, K., Silver, D., Graves, A., Antonoglou, I., Wierstra, D., & Riedmiller, M.(2013).Playing atari with deep reinforcement learning. arXiv preprint arXiv:1312.5602.
[2] Horgan, D., Quan, J., Budden, D., Barth-Maron, G., Hessel, M., Van Hasselt, H., & Silver, D.(2018).Distributed prioritized experience replay. arXiv preprint arXiv:1803.00933.
[3] Liang, E., Liaw, R., Moritz, P., Nishihara, R., Fox, R., Goldberg, K., … & Stoica, I.(2017).RLlib: Abstractions for distributed reinforcement learning. arXiv preprint arXiv:1712.09381.
著者について
 Jonathan Chung は AWS のアプライドサイエンティストです。彼は、ゲームや文書分析などのさまざまなアプリケーションにディープラーニングを適用することに取り組んでいます。彼の趣味は料理と世界中の歴史的な都市を訪れることです。
Jonathan Chung は AWS のアプライドサイエンティストです。彼は、ゲームや文書分析などのさまざまなアプリケーションにディープラーニングを適用することに取り組んでいます。彼の趣味は料理と世界中の歴史的な都市を訪れることです。
 Anna Luo は AWS のアプライドサイエンティストです。彼女は、サプライチェーンやレコメンダーシステムなど、さまざまな分野で強化学習テクニックを活用しています。彼女の現在の個人的な目標は、スノーボードをマスターすることです。
Anna Luo は AWS のアプライドサイエンティストです。彼女は、サプライチェーンやレコメンダーシステムなど、さまざまな分野で強化学習テクニックを活用しています。彼女の現在の個人的な目標は、スノーボードをマスターすることです。
 Scott Perry は、AWS のスペシャリストソリューションアーキテクトです。アルバータ州カルガリーを拠点とし、お客様が AI/ML ベースのソリューションを重要なビジネス上の問題に適用するのを支援します。彼は、深層強化学習とゲノミクスに興味を抱いています。仕事以外では、エレキギターを弾いたり、山で過ごしたりしています。
Scott Perry は、AWS のスペシャリストソリューションアーキテクトです。アルバータ州カルガリーを拠点とし、お客様が AI/ML ベースのソリューションを重要なビジネス上の問題に適用するのを支援します。彼は、深層強化学習とゲノミクスに興味を抱いています。仕事以外では、エレキギターを弾いたり、山で過ごしたりしています。
 Bharathan Balaji は AWS のアプライドサイエンティストで、彼の研究対象は強化学習システムとアプリケーションにあります。彼は Amazon SageMaker RL と AWS DeepRacer の立ち上げに貢献しました。余暇には、バドミントン、クリケット、ボードゲームを楽しんでいます。
Bharathan Balaji は AWS のアプライドサイエンティストで、彼の研究対象は強化学習システムとアプリケーションにあります。彼は Amazon SageMaker RL と AWS DeepRacer の立ち上げに貢献しました。余暇には、バドミントン、クリケット、ボードゲームを楽しんでいます。
 Xavier Raffin は AWS のソリューションアーキテクトで、お客様がビジネスを変革し、業界をリードするクラウドソリューションを構築するのを支援しています。彼は好奇心に駆られ、公共交通機関、ウェブマッピング、IoT、航空、宇宙といった多くの分野にテクノロジーを応用しています。彼は、OpenStreetMap、Navitia、トランスポート API といった、いくつかの OpenSource プロジェクトと Opendata プロジェクトに貢献しました。
Xavier Raffin は AWS のソリューションアーキテクトで、お客様がビジネスを変革し、業界をリードするクラウドソリューションを構築するのを支援しています。彼は好奇心に駆られ、公共交通機関、ウェブマッピング、IoT、航空、宇宙といった多くの分野にテクノロジーを応用しています。彼は、OpenStreetMap、Navitia、トランスポート API といった、いくつかの OpenSource プロジェクトと Opendata プロジェクトに貢献しました。
 Vishaal Kapoor は、AWS AI のシニアソフトウェア開発マネージャーです。彼は AI のすべてを愛し、SageMaker を使ってディープラーニングソリューションを構築することに取り組んでいます。余暇には、マウンテンバイク、スノーボードを楽しみ、家族との時間を大切にしています。
Vishaal Kapoor は、AWS AI のシニアソフトウェア開発マネージャーです。彼は AI のすべてを愛し、SageMaker を使ってディープラーニングソリューションを構築することに取り組んでいます。余暇には、マウンテンバイク、スノーボードを楽しみ、家族との時間を大切にしています。