Amazon Web Services ブログ
ボンネットの下で: Kinesis データストリームのスケーリング
データとそれに伴う所見がリアルタイムに提供されるなら、ビジネスは軸足を素早く定めて、様々な要素、中でも必要性の変化、ユーザーの関与、そしてインフラストラクチャのイベントに対応できるしょう。Amazon Kinesis はマネージド型サービスを提供しているため、ユーザーはインフラストラクチャの管理に煩わされることなく、アプリケーションの構築に専念することができます。スケーラビリティは特別な労力なしで実現でき、毎秒ギガバイト単位のストリーミングを取り込んで処理できます。データは 3 か所のアベイラビリティーゾーンに複製され、高い可用性と耐久性を提供します。料金は従量制で、初期費用が必要ないので、Kinesis はコスト効率のよいソリューションとなっています。
Amazon Kinesis Data Streams は、プロビジョニング済みキャパシティーモデルを採用しています。それぞれのデータストリームは 1 つ以上のシャードから構成されており、これがキャパシティーのユニットとしての役割を果たします。シャードが定義済みの読み書き書きキャパシティーを提供するため、ストリーミングパイプラインの設計とスケーリングは容易になります。ワークロードが増えて、アプリケーションの読み書き率がシャードのキャパシティーを越えるとホットシャードの原因となり、キャパシティーをすぐに追加することが必要になります。また、シャードの使用により、大規模なデータセットの処理を並列化することもできるので、計算結果を高速に出力できます。
この記事では、データストリームをスケーリングし、ホットシャードを避ける方法について説明します。まず、ストリームパイプラインを設計する時点でデータストリームが必要とするシャード数を評価する方法を示します。それから、ホットシャードが発生する原因と、Kinesis Data Streams のスケーリングを使用してそれを避ける方法について考慮し、監視するべき重要なメトリクスを確認します。
ストリームのキャパシティーを見積もる
次の図は、1 本のストリーミングデータパイプラインがマルチプレイヤービデオゲームに接続されている様子を示しています。Kinesis Data Streams はプレイヤーのスコアや他の統計情報を取り込みます。ingest player scores and other stats.データはフィルタリングすること、および情報を追加することができ、それから DynamoDB に書き込まれて、ゲームの様々な順位表の元データとなります。

ストリーミングパイプラインの設計を始めるときには、データレコードのプロデューサーが作成するデータを取り込むことによってプロデューサーをハンドルし、同じレコードを消費するユーザーもハンドルするのに十分なキャパシティーを持つデータストリームをセットアップすることが重要です。シャードごとに、毎秒 1 MB のデータを取り込むこと、または同じくシャードごとに毎秒 1,000 のデータレコードを書き込むことができます。読み取りキャパシティーは最大でシャードごとに毎秒 2 MB、または毎秒 5 つの読み取りトランザクションに達します。あるストリームから読み取るすべてのアプリケーションは、読み取りのキャパシティーを共有します。強化されたファンアウト機能により、消費側アプリケーションの数をスケーリングすることができ、そのそれぞれが毎秒 2 MB の専用接続を持てるようにできます。
この記事では、前述のアプリケーションを例として用いることにします。プロデューサー側では毎秒 20,000 KB の割合でデータレコードを作成すると見積もられたとすると、ストリームの反対側ではそれと同じ量のデータを消費者ノードが処理する必要があります。この割合を処理できるようにすることに加え、ストリームの増大のためのヘッドルームとして追加のキャパシティーを追加しておくのは良いアイディアです。
このヘッドルームは、データの取り込みや処理で遅延や中断が発生したというシナリオにおいても、アプリケーションがすぐに回復できるようにする点でも役立ちます。そのようなシナリオとしては、次のものがあり得ます。
- 消費者側アプリケーションの新しいバージョンがデプロイされる
- 一過的なネットワークの問題
これらのノードが回復後に追いつくときには、レコードを標準の速度よりも速い速度で生成または消費することになるので、より大きなキャパシティーが必要になります。この例では、ヘッドルームとして 25% または 5 シャードを加えることにします。シャードはコスト効率のよいものですが、それはいくつ追加するかにもかかっています。
スケーリングのシナリオ
ゲームのリリースの時点では、キャパシティーはアプリケーションに十分なように思われるものです。データの取り込みと処理はどちらもスムーズに進み、ゲームの順位表には最新のデータが反映されます。さて、リリースから数週間経ち、ゲームは着実に人気を得て、同時に参加するプレイヤーの数も増加していきます。このようなシナリオでは、負荷の増大が見られたときにはストリームのスケーリングを行ってスループットを上げられるよう、増大を検出するために十分な頻度でモニタリングを行うことが重要です。
次の図は、CloudWatch を使用してデータストリームをモニタリングし、スケーリング処理をトリガーする場合の略図です。
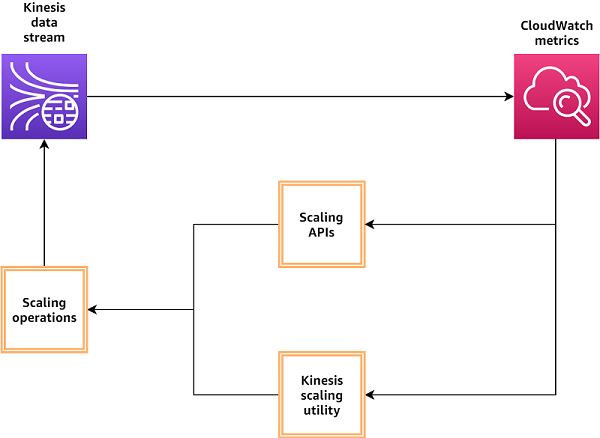
この例では、スケーリングの問題が、順位表の更新レポートの遅れという形で現れる可能性があります。シャードがデータストリームのキャパシティーの単位となっているため、シャードのキャパシティーは他のシャードとは独立しています。プロデューサー側が 1 つのシャードに毎秒 1 MB を越える割合で書き込んだ、または 1,000 レコードを越えて書き込んだ場合には、シャードはホットシャードとなり、キャパシティーを越えたリクエストにはスロットルがかかって、順位表の更新に遅れが生じます。このような状況は、ストリームの他のシャードがあまり使用されていない場合に発生することがあります。そのため、メトリクスをストリームレベルで監視しているだけでは問題の原因が見つからないことになり得ます。全体としてのストリームは、毎秒 25 MB という総キャパシティーよりも低い割合でしかデータを取り込んでいないからです。Amazon Kinesis を使えば、ストリーミングパイプラインを中断せずにストリームスケーリングをシームレスに行うことができます。
スケーリングを可能にする中心的な概念
レコードをデータストリームに書き込むには、Put API を使用します。1 つのレコードを書き込む際には PutRecord を、複数のレコードの場合には PutRecords を使用します。このどちらかを実行する場合、Kinesis の API へのリクエストには以下の 3 つのコンポーネントを含める必要があります。
- ストリームの名前。
- ストリームに書き込むデータレコード。この記事では、ゲームの特定のラウンドでの得点結果です。
- パーティションキー (例えば fame セッション)。
次の図は、複数のプロデューサーが Kinesis のデータストリームに書き込みを行っている状況を描いています。パーティションキーはハッシュ関数と組み合わせることにより、特定のレコードがどのシャードに書き込まれるかを決定します。
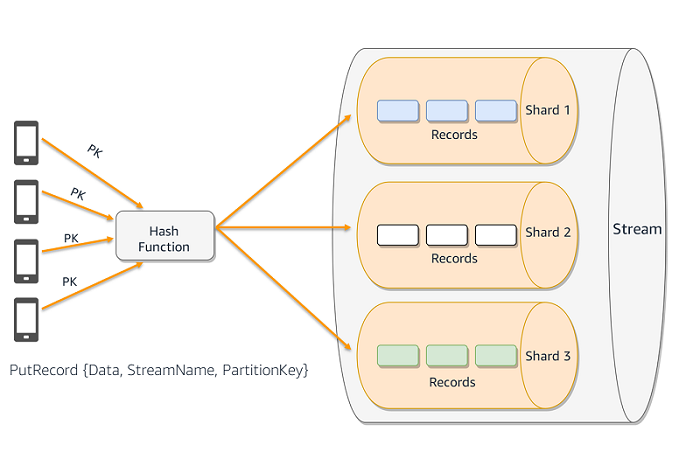
パーティションキーは、レコードがどのシャードに書き込まれるかを決定します。パーティションキーは、最長で 256 バイトの Unicode 文字列です。Kinesis は、リクエストに含められたパーティションキーを MD5 ハッシュ関数に与えます。得られた結果により、レコードはストリーム内の特定のシャードにマップされ、Kinesis はレコードをそのシャードに書き込みます。パーティションキーは、ストリーム全体へのデータの分散と、シャードの使用方法を決定します。
特定のユースケースでは、消費側アプリケーションで効率的な処理が行われるように、特定の基準に基づいてデータを区分することが必要になります。例えば、プレイヤーの ID pk1234 をハッシュキーとし、そのプレイヤーに関連するすべてのスコアが shard1にルーティングされるようにしたいという場合が考えられます。消費側アプリケーションでは、shard1 にはこのプレイヤーの ID に関連したデータが保存されているという事実を基に、得点表への結果を効率的に算出できます。この場合、shard1 にマップされているプレイヤーに関連したトラフィックが増大すると、ホットシャードが発生することがあります。Kinesis Data Streams では、ストリーミングパイプラインを混乱させずにシャードを分割したり、合併したりすることにより、そのようなシナリオに対応できます。
自分のユースケースで、類似性の高いデータをあるシャードに保存する必要がないのであれば、データを分散させるためにランダムなパーティションキーを使用して、全体として高いスループットを達成することができます。ランダムなパーティションキーを使えば、入力されるデータレコードを、ストリーム内のすべてのシャードに均一に分散することができ、あるシャードだけに不均等に多数のレコードが集まる可能性を抑えることができます。汎用一意識別子 (universally unique identifier、UUID) をパーティションキーとすれば、レコードがすべてのシャード間に均等に分散されるようになります。この戦略では、消費者側アプリケーションが複数のシャードからデータを集積しなければならない場合、レコード処理のレイテンシーが増大する可能性があります。
Kinesis Data Streams のスケーリングメカニズム
このようなアクションを実施している間も、ストリームは引き続き完全に機能し続けます。生産者側と消費者側では、スケーリングの処理が行われている間も、ストリームへの読み書きを行えます。
スケーリングのリクエストを受け取ると、Kinesis はストリームのステータスを 更新中に変更します。ストリームのステータスは、DescribeStreamsAPI を使用してチェックできます。操作が完了すると、ストリームのステータスはアクティブになります。
SplitShard アクションは 1 つのアクティブなシャードを 2 つのシャードに分割し、ストリームの読み書きキャパシティーを向上させます。これは、ストリームが取り込むレコード数が増加することが予期される場合、またはリアルタイムの処理を行うため、複数の Kinesis Data Streams アプリケーションが、あるストリームから同時にデータの読み取りを行えるようにしたい場合に役立ちます。
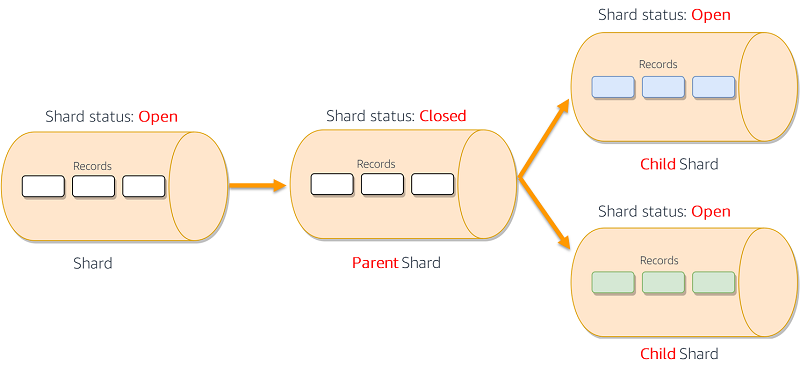
SplitShard はこのプロセスを促進します。親シャードのハッシュキー空間も分割されます。2 つの新しいシャードは新しいデータレコードを受け付け、親シャードは新しいレコードの受け付けを中止します。親シャード内の既存のレコードは、ストリーム保持期間 (デフォルトでは 24 時間、最大 7 日に設定可能) の間保持されます。このコマンドを発行する場合には、new-starting-hash-key 値を指定する必要があります。この値は、親シャードのハッシュキー空間をどこで分割するかを決定します。ほとんどの場合には、均等な分割が求められるでしょう。しかし、例えばすでに不均等なシャードがあり、それらの間でバランスを取り直したい場合には、不均等異な分割が必要になるでしょう。次の図は、実施中の SplitShard プロセスを示しています。
多くのストリーミングワークロードではデータフロー率は一定ではなく、時間とともに、つまり日単位、週単位、または季節単位のパターンで変化します。データフロー率を監視している間には、あまり使用されていないシャードが見つかり、他のものと合併すれば、データフロー率をシャードの限界満に下げて、ストリームのコストを抑えられると思われる場合もあり得ます。
MergeShards アクションは隣接した 2 つのシャードを合併して、1 つのシャードにします。2 つのシャードは、それら 2 つのシャードのハッシュキー空間がギャップなしで連続している場合、隣接していると見なされます。2 つのシャードを合併すると、ハッシュキー空間も合併されます。新しいシャードは、新しいデータレコードを受け付けるようになります。2 つの親シャードは新しいレコードの受け付けを中止し、既存のレコードをストリームで設定された保持期間の間、保持します。次の図は、実施中の MergeShards プロセスを示しています。

UpdateShardCount アクションは、ストリーミングが使用しているシャードの数を増減させて、ストリーミングのスケーリングを調整したい場合に役に立ちます。この API 呼び出しには多数のパラメータがあります。現在のキャパシティーを基に、その 25% 単位でスケーリングを行えば (25%、50%、75%、100%) 、操作は短時間で済みますが、必要なわけではありません。このコマンドは、指定されたシャード数を達成するのに必要なだけ、一連の SplitShard と MergeShards アクションを実施します。このコマンドはシャードのハッシュキー空間を均等に分割して、等しいサイズのシャードを作成します。このサイズを変えるためのオプションはありませ。
加えて、GitHub から入手できる Kinesis Scaling Utility を使えば、ストリームの Amazon CloudWatch メトリクスを監視させて、自動的に Kinesis Data Streams のスケーリングアップやスケーリングダウンを行わせることができます。ストリームのスケーリングは、シャード数を明示すること、または全体の使用率を指定することによって、行えます。この API を使用する場合には、キー空間の割り当てを管理する必要はありません。自動的に行われるからです。
シャードのバランス調整
スケーリングの操作が完了したら、ストリーム内のハッシュキー空間の分布を確認してください。ほとんどのユースケースでは、ハッシュキー空間は、ストリーム内のシャード全体にわたり、均等に分布しているはずです。シャードのハッシュキー空間の開始値の計算または入力を間違えると、ハッシュキー空間が異常に大きい、または小さいシャードができることがあります。異常に大きい場合のシャードは、多数の読み書きリクエストを受け取ることになり、スロットリングが生じます。小さい方のシャードは使用率が低くなります。
ListShards API の出力には、ストリーム内のシャードごとに、ハッシュキーの開始値と終了値がリストとして示されます。これらの値を基に、アンバランスなシャードがないか確認し、分割や合併によってバランスを取り直してください。Kinesis Scaling Utility は、シャードのキー空間のレポートも生成します。これを参照しても、同じ結果が得られます。次のコードを参照してください。
ホットシャード防止のためにストリームを監視する
ホットシャードのシナリオを示したように、データストリームをストリームレベルで監視しただけでは、シャードレベルの問題に備えることができません。Kinesis には、ストリームレベルとシャードレベルのメトリクスが多数用意されています。シャードレベルでは、IncomingBytes と IncomingRecords により、シャードでの取り込み率が示されます。WriteProvisionedThroughputExceeded と ReadProvisionedThroughputExceeded はそれぞれ、スロットリングが発生した Put と Get リクエストを示します。ストリームレベルでは、PutRecord.Success に注目してください。これは、時間経過とともに PutRecord の成功の割合を反映する平均値です。適切なアラームしきい値と組み合わせれば、ストリームの流入と流出の変化に応じて前もってスケーリングアクションを実施し、ホットシャードが出現する可能性を抑えることができるはずです。
次の画像は、Kinesis データストリームのいくつかを表示させた、CloudWatch のダッシュボードを示しています。

結論
この記事では、Kinesis Streams のスケーリングと監視をシンプルに行う方法について説明しました。適切なキャパシティーを判断できるようになるまでは、ストリームで予期されるデータフローをしばらくの間、考慮することが重要です。良好なパーティションキー戦略を選択すれば、プロビジョニングしたキャパシティーを十分に活用し、ホットシャードを避けることができます。ストリームのメトリクスを監視し、アラームのしきい値を設定すれば、スケーリングに関する判断をよりよく下すのに必要な可視性が得られます。
詳細については、Amazon Kinesis Data Streams とは? を参照してください。 Kinesis API アクションについての詳細は、Actions を参照してください。
著者について
 Ahmed Gaafar は、AWS のシニアテクニカルアカウントマネージャーです。
Ahmed Gaafar は、AWS のシニアテクニカルアカウントマネージャーです。