- AWS Builder Center›
- builders.flash
コンテナ Lambda でサイドカーパターンは実現可能なの ? ~コンテナ利用者に捧げる AWS Lambda の新しい開発方式 ! ~ 第 7 回
2022-02-02 | Author : 下川 賢介
はじめに
こんにちは、サーバーレス スペシャリストソリューションアーキテクトの下川 (@_kensh) です。
今回はコンテナイメージサポート Lambda 関数のサイドカーパターンについて、その実現可能性や、Amazon ECS や Amazon EKS のような コンテナサービスでのサイドカーパターンと異なる点を整理して、その利用方法について確認していきたいと思います。
X ポスト » | Facebook シェア | はてブ »
ご注意
本記事で紹介する AWS サービスを起動する際には、料金がかかります。builders.flash メールメンバー特典の、クラウドレシピ向けクレジットコードプレゼントの入手をお勧めします。
builders.flash メールメンバー登録
サイドカーパターンについて
Google のコンテナによる分散システムのデザインパターンに関する論文、Design patterns for container-based distributed systems によると、サイドカーパターンの利点を以下のように説明しています。ここで言及されているすべての利点が コンテナ Lambda で実現できるわけではないので整理しておきたいと思います。
※ 論文中では Kubernetes と podsを中心に説明していますが、ここでは Kubernetes に特化しないように、より抽象的に図示しています。
figure: sidecar
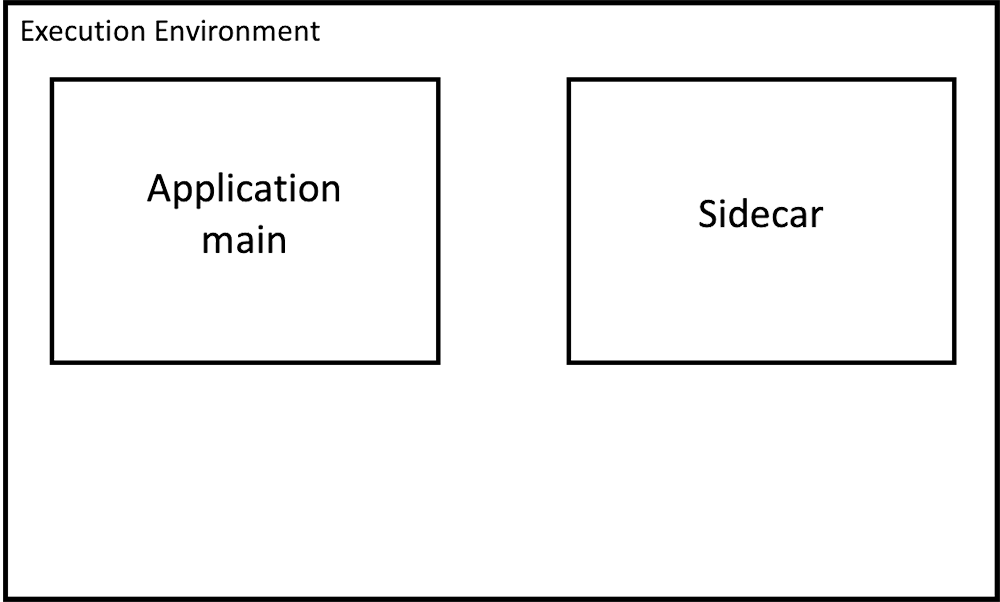
論文で言及されているコンテナベースでのサイドカーパターンの利点
-
各コンテナは独立したリソースの設定や適用ができるため、メインコンテナに優先的に CPU を割り当てて、サイドカーにはメインアプリケーションがビジーでない時に CPU を利用させることができる。
-
コンテナはパッケージの単位になっているため、非機能要件を独立に開発してサイドカーとして利用することができる。これにより、独立した開発チームに非機能要件の開発を委譲しやすい。
-
同様の非機能要件を要求するメインコンテナに同一のサイドカーを適用することも簡単になる。
-
コンテナは障害の境界として働くため、仮にサイドカーコンテナが障害を起こしても、グレースフルデグラデーションするように実装することができる。(サイドカーを無視してメインコンテナが稼働し続けるように実装するなど)
-
コンテナはデプロイメントの単位になっているため、メインコンテナとサイドカーコンテナは独立したタイミングでデプロイすることができる。そのため独立したアップグレードやロールバックが容易になっている。
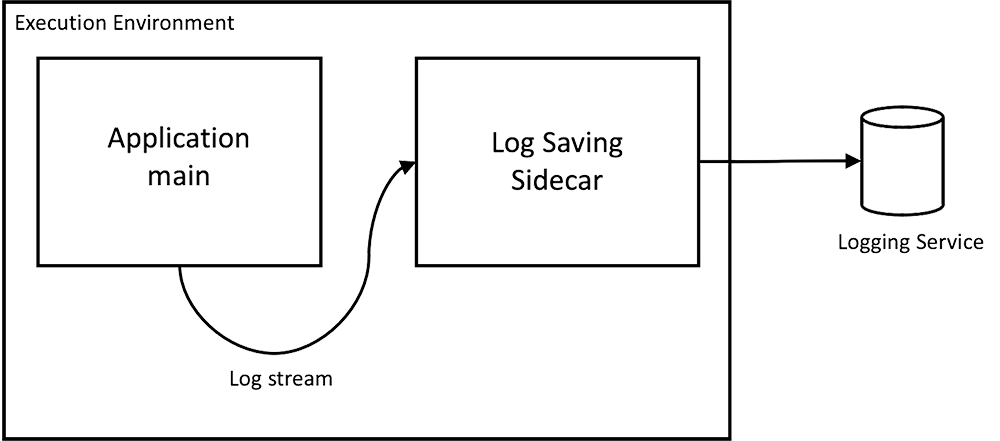
サイドカーは非機能要件を扱うのに適しているという説明によく登場するのが、アプリケーションログ用のサイドカーの利用です。
このように、どんなアプリケーションでも非機能要件としてログの扱いが必要になるはずなので、再利用性が高くライフサイクルの違う機能に扱いやすいサイドカーパターンを適用することは理にかなっています。
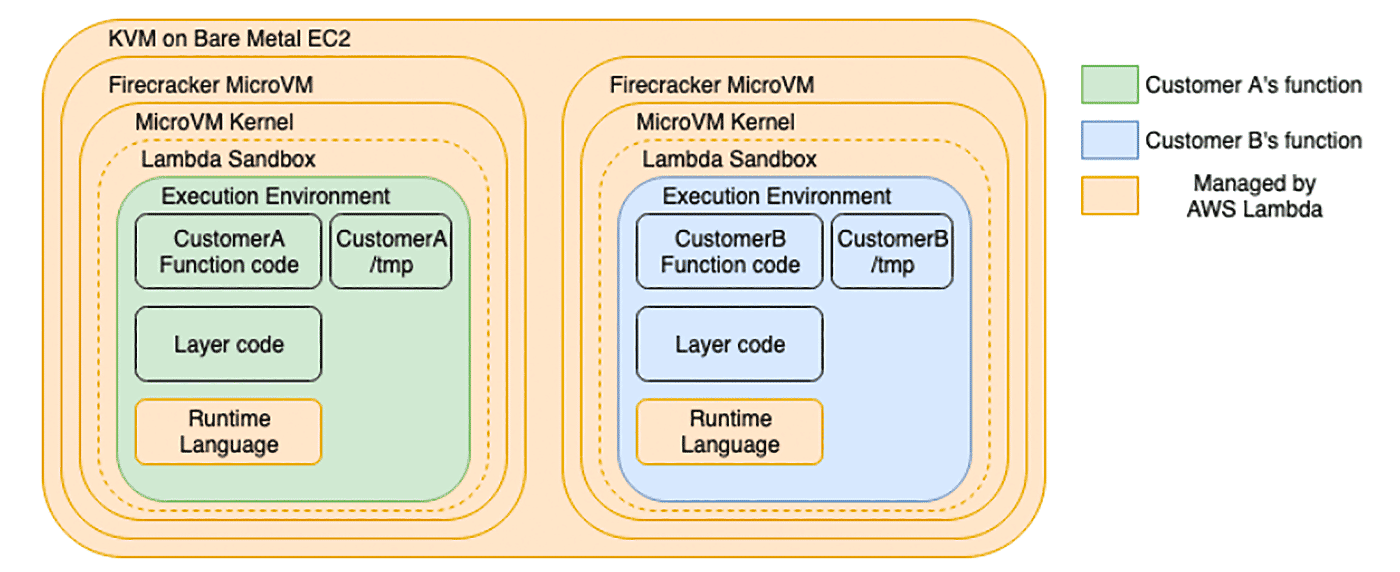
AWS Lambda の環境分離方法のおさらい
コンテナ Lambdaのサイドカーパターンに入る前に、そもそも AWS Lambda はどのように実行環境を分離していたかを振り返ってみましょう。
Lambda の実行環境 はこのようになっています。
この図でいうと、 Customer A’s function (緑色) と、Customer B’s function (青色) の実行環境 (Lambda Execution Environment) は独立分離した環境が提供されています。さらに、同じ Customer A が別の関数インスタンスを起動したとしても、実行環境は独立分離されます。そのため、異なるコンテナ Lambda 用のイメージを同じ実行環境で独立して起動することは不可能です。
ここまでの説明でお分かりの通り、Amazon ECS や Amazon EKS のような コンテナサービスでのコンテナ単位のサイドカーをそのまま コンテナ Lambda で実現することはできません。
AWS Lambda での非機能要件の扱いはどのようになっているか
ここまで読むと、AWS Lambda では Zip 形式の Lambda でもコンテナ Lambda でも、コンテナサービスのようなコンテナ単位のサイドカーは作れないので、独立して管理できる再利用可能な非機能要件をどう実現するのか? と頭を抱えてしまった読者もいるかもしれません。
しかし、思い出してください。 AWS Lambda はサーバーレスサービスです。アプリケーション開発・運用に必要な多くの非機能要件がサービス自体にネイティブに実装されています。例えば 実行ログ は Lambda 関数内で標準出力または標準エラー出力することで、自動的に Amazon CloudWatch Logs に送信されます。同様に同時実行数などの運用に必要な メトリック も Amazon CloudWatch metrics に送られます。トレース についても、ユーザーがサイドカーコンテナとして トレース用の Agent を立てる必要はなく、Lambda サービス側で AWS X-Ray と統合されています。つまり、サイドカーパターンが Lambda サービスネイティブに実装されています。
また、多くの AWS サービスやオープンソースミドルウエアと 統合する機能を Lambda サービスでは提供 しているので、例えば Amazon SQS と Lambdaを統合 する際にも、同一実行環境に SQS 用のポーラーを立てる必要はありません。Lambda サービスで各種サービスとの接続を自動的に適合させて、Lambda 関数のハンドラーインターフェース (event データとして受け取れる) 形式に変換してくれます。つまり Lambda サービスがサービス側で SQS をポーリングする仕組みを持っているため開発者は、Lambda 関数にデプロイするアプリケーションコード上のビジネスロジックに集中できます。こちらはアダプターパターンと呼ばれ、多くのサービスとの統合が、Lambda サービスネイティブに実装されています。
他にも、非同期に呼び出しされた Lambda 関数 や、Amazon Kinesis Data Streams などストリームデータを処理する Lambda 関数 については関数エラー時に、エラーイベントの 送信先 を設定しておくことができます (非同期呼び出しの場合は成功時にも送信可)。現在、送信先として対応しているサービスは、Amazon SQS、Amazon SNS (非同期呼び出しの場合は加えて AWS Lambda、Amazon EventBridge) になっています。これにより、アプリケーションの障害を管理者に伝えたり、送信先で自動回復の処理を予め実装しておくことができます。つまり、アンバサダーパターンが Lambda サービスネイティブに実装されています。
これまで紹介してきた Lambda での非機能要件の取り扱いですが、AWS Lambda 関数ハンドラーの実装言語によらず利用することができます。また、Lambda サービス自体がこれらのパターンの可用性やセキュリティ、ネットワーク接続性を担保してくれているため、ユーザーが独自にサイドカーコンテナを実装、管理する必要はありません。独立して管理できる再利用可能な非機能要件は多くの場合、Lambda サービス側が担っています。
なぜ Lambda にユーザー定義のサイドカーが必要か ?
AWS Lambda の場合には、サービス側でかなりの部分、非機能要件があらかじめ実装されていることを説明してきました。それでもあえてサイドカーパターンを利用したいユースケースを考えてみます。
ユースケース
このように、Lambda サービスが統合のネイティブ実装を用意していなかったり、サードパーティサービスとの連携では、サイドカーを用意しておいて、再利用したいということはあるでしょう。
AWS Lambda でのサイドカーの実現方法
これまで説明したとおり、コンテナサービスで実現していたようなコンテナベースのサイドカーパターンは AWS Lambda では実現できません。ここでは、上で挙げたサイドカーパターンの利点を思い出して、AWS Lambda での実現方法を探ってみまたいと思うのですが、結論から言うと AWS Lambda Extensions を利用することで、独自のサイドカーを Lambda 実行環境に持ち込む事ができます。
Lambda Extensions を理解するために、この Extensions 機能が登場前にはどういったサイドカー実現方法があったかの歴史を振り返ってみます。AWS Lambdaでは推奨はしませんが、Lambda 関数ハンドラー内で サブプロセスを起こすことができます。例えば Python で実装されたハンドラーなら subprocess.py を利用することで簡単に実現できます。そして、そのサブプロセスを起こし利用するためのコード群を Lambda Layer にしておくことで、他の Lambda 関数実装内で再利用することが出来ます。
先程、この独自サブプロセスのパターンは推奨しないと言いましたが、これには理由があります。開発者がサブプロセスの管理をする際にサブプロセスのエラーハンドリングや適切な終了をさせることは比較的難易度が高いのでプロセス間の依存がどうしても強くなるのと、Lambda 関数のライフサイクルフックが、独自に立ち上げたサブプロセスでは得られないことが理由です。
そこで、この課題を解決するため登場したのが AWS Lambda Extensions になります。Extensions は大まかに説明すると、Lambda 関数のデプロイメントを所定のパスにエントリーポイントを配置する形式で用意しておくと、AWS Lambda サービス側で、Extensions プロセスを起動してくれる仕組みになります。それだけでなく、Lambda 関数の ライフサイクルイベントを Extensions プロセス側にも通知してくれる機能になります。この Extensions プロセスは、メイン関数プロセスから見るとサブプロセスではなく、親子関係のないサイドカープロセスとなっています。また、サイドカーコンテナではなく、サイドカープロセスとなっていることにも注意が必要です。このサイドカープロセスはメイン関数のプロセスと実行環境を共有し、Lambda 関数に設定した実行ロールや、メモリ設定を共有します。(プロセスで分離されているため共有メモリとなっているわけではなく、利用可能な最大メモリ量を共有している)
Lambda 関数のライフサイクル を Extensions 側では、この図のように Init/Invoke/Shutdown について把握することが出来ます。

Lambda 関数インスタンスでは、初回呼び出しの際にインスタンス立ち上げの Init フェーズに入ります。一度立ち上がったインスタンスは次回以降の呼び出しに再利用されます。この呼出単位で入るフェーズが Invoke フェーズになります。
これらのフェーズを Lambda Extensions でも同時に Lambda サービスから受け取ることが出来るのです。そのため Extensions として実装された非機能要件の初期化も Init フェーズで完了させたり、Invoke 毎に実施したい処理なども実装することが出来ます。特に、しばらく Lambda 関数インスタンスへの Lambda サービスからのルーティングがない場合、Lambda Extensions は Shutdownイベントを Lambda サービスから通知され、クリーニングなど定形の処理をグレースフルに行うことが出来ます。これが Shutdown フェーズになります。
コンテナ Lambda での Lambda Extensions の利用方法
コンテナ Lambdaで Lambda Extensions (Lambda の拡張機能) を利用する方法が、こちらのブログ (コンテナイメージ内で Lambda レイヤーと拡張機能を動作させる) に詳しく紹介されています。ぜひ一度手を動かして試してみてください。
Lambda サービス は /opt/extensions ディレクトリを検索し、見つかった全ての Extensions の初期化を開始します。Extensions は、バイナリまたはスクリプトとして実行可能である必要があります。Lambda メイン関数コードディレクトリは読み取り専用であるため、拡張機能は関数コードを変更できません。
以下の Dockerfile のように、extensions のソースを /opt/extensions に展開して利用します。
FROM python:3.8-alpine AS installer # Extensions Code COPY extensionssrc /opt/ COPY extensionssrc/requirements.txt /opt/ RUN pip install -r /opt/requirements.txt -t /opt/extensions/lib FROM scratch AS base WORKDIR /opt/extensions COPY --from=installer /opt/extensions .(snip)# Function code WORKDIR /var/task COPY app.py . CMD ["app.lambda_handler"]単一の Dockerfile
この Dockerfile を見てお分かりのとおり、サイドカー用の Extensions の記述と、メインハンドラー記述が混在した単一の Dockerfile になっています。 コンテナサービスでのサイドカーでは個々の分離した Dockerfile を利用していたのと大きく違います。
もう一つ注意点として、コンテナサービスでのサイドカーは、一つのサイドカーを複数のメインアプリケーションコンテナから共通に利用することが出来ますが、Lambda Extensions によるプロセスサイドカーでは、同じ実行環境に一つのメイン関数しか配置できないためランタイムにおけるサイドカーの共有はできません (もちろん同じサイドカーの artifact を他の Lambda 関数デプロイメントに梱包して利用することは可能です)。一方で、Lambda 関数には最大 10 個の Extensions を配置できるため、複数の異なる非機能要件用サイドカーを入れ込むことは可能となっています。
コンテナ Lambda サイドカーパターンで実現出来ること、出来ないこと
AWS Lambda でのサイドカーパターンはコンテナ単位のサイドカーではなく、プロセス単位のサイドカーでした。そのためサイドカーパターンの利点で実現できること、出来ないことを整理しておきたいと思います。
- (Lambda Extensions) 実行環境をメイン関数と共有するため パフォーマンスの影響と拡張機能のオーバーヘッド があります。コンテナ単位ではないため、厳格なリソース利用の境界を引くことが出来ません。
- (Lambda Extensions) Lambda Layer やランタイム言語が対応する artifact repository (例えば AWS CodeArtifact など) を利用して、独立チームや独立リポジトリのある程度の分離管理はできるが、コンテナサイドカーほど独立分離はしていない。
- (Lambda Extensions) 可能
- (Lambda Extensions) 実行環境を共有しているため困難。特に、CPU とメモリを互いの境界なく最大利用可能量を共有しているため、Extensions プロセスが暴走した場合に、本体のメイン関数にも影響が出る。
- (Lambda Extensions) Extensions プロセスが、デプロイメントの単位であることを保証していないので、Artifact は分離できたとしてもデプロイメントの単位は分離できない。
結局のところ、論文で出てきていたサイドカーパターンは Lambda Extensions で実装すると、本当に効力を発揮しているのは上記 3. の独自非機能要件の再利用性向上のみということが言えるでしょう。この独自非機能要件向けサイドカーパターンを実現するために Lambda Extensions が登場したという歴史を振り返りましたが、つまり、他の多くの非機能要件に関しては Lambda サービス側で ネイティブに持っている機能であるため、Lambda Extensions のサイドカーで実現すべき項目が少なくて済んでいるとも言えます。
それでは、AWS Lambda を含むアーキテクチャをどのように設計すべきなのか ?
すでに、Lambda の実行環境分離方法については紹介しましたが、サイドカーの分離状況に頼らずに、本来の AWS Lambda が提供している 関数実行単位の分離によって、アーキテクチャ設計するのがAWS サーバーレスのプラクティスになります。
また、コンテナのサイドカーが提供する機能がロードバランサーやルーティング、フィルタ、サーキットブレーカーなどの他種多様な機能を提供しているという点もありますが、これは Lambda サービスが単体で提供するだけでなく、AWS の複数サービスと組み合わせることによるビルディングブロックとして機能を提供する設計思想となっているからです。たとえば Lambda 関数を Amazon API Gateway、Application Load Balancer、非同期呼び出しや Stream サービスと連携する ことによって、ロードバランス、ルーティング、フィルタ、スロットリングをきめ細やかに設定することが出来ます。
論文で登場したサイドカーパターンの利点をすべて サイドカーだけで実現できなくとも、Lambda サービスが持つ機能を理解しアーキテクチャを組むことで実現できます。
- 各 Lambda 関数は独立したリソースの設定や適用ができるため、関数ごとに適切な関数メモリの設定をすることができます (vCPU の設定はメモリの設定 で自動適用)。このメモリ/vCPU リソースは関数の実行単位で厳格に分離されます。
- AWS Lambda はアカウント/リージョンごとに、東京リージョンではデフォルトで 1,000 の同時実行数が割り当てられています (上限緩和可能) 。こちらは関数全体で共有する Quota になるため、以下のいずれか、または組み合わせた分離戦略を取ることができます。
- メインアプリケーションに優先して同時実行数を割り当てるために、優先度の低い関数に少量の 予約された同時実行数 を割り当て、超過分はスロットリングさせる。
- 優先度の高いアプリケーションに、十分な同時実行数を予約しておき、スロットリングの懸念を緩和しておく。
- 優先度の低い Lambda 関数については、Lambda 関数の実行イベントをいったん Amazon SQS に入れておき、低いスループットで実行するようにコントロールしておくなど、同期型のアーキテクチャだけでなく、要件を確認して非同期型のイベント・ドリブンアーキテクチャに移行する。
- Lambda 関数を分離することで開発フローも分離を図ることができます。ドメイン駆動中心の設計 にすることで、チームの分離とアーキテクチャの分離がしやすくなります。
- 障害の影響範囲の最小化 を図るために、マイクロサービス間を疎結合に保ちます。例えば Amazon SQS をマイクロサービス間に入れることによりアーキテクチャ全体が非同期で疎結合になり、メッセージのパブリッシャーとサブスクライバーの障害影響が分離されます。
- 同期的な API 実装の場合、AWS SDK を利用し SDK に組み込みの Exponential backoff retry を適切に実施することで、間欠的な不通からの復旧時に処理が再開されます。
- AWS StepFunctions を利用してサーバーレスワークフローにリトライやエラーハンドリングを委譲して Lambda 関数をシンプルに保ちます。
- Lambda 関数自体がデプロイメントの単位となり、分離を担っています。機能/非機能に関わらず、Lambda 関数を小さく最小権限を維持できるように設計しましょう。また、Lambda サービスには Lambda 関数の artifact バージョンエイリアスを使ったトラフィックルーティング機能 があります。こちらを使うことにより、新旧 artifact バージョンに対しての Canary デプロイも可能になります。
まとめ
筆者プロフィール
下川 賢介 (@_kensh)
アマゾン ウェブ サービス ジャパン合同会社
シニア サーバーレススペシャリスト ソリューションアーキテクト
Serverless Specialist Solutions Architect として AWS Japan に勤務。
Serverless の大好きな特徴は、ビジネスロジックに集中できるところ。
ビジネスオーナーにとってインフラの管理やサービスの冗長化などは、ビジネスのタイプに関わらず必ず必要になってくる事柄です。
でもどのサービス、どのビジネスにでも必要ということは、逆にビジネスの色はそこには乗って来ないということ。
フルマネージドなサービスを使って関数までそぎ落とされたロジックレベルの管理だけでオリジナルのサービスを構築できるという Serverless の特徴は技術者だけでなく、ビジネスに多大な影響を与えています。
このような Serverless の嬉しい特徴をデベロッパーやビジネスオーナーと一緒に体験し、面白いビジネスの実現を支えるために日々活動しています。

Did you find what you were looking for today?
Let us know so we can improve the quality of the content on our pages