- AWS Builder Center›
- builders.flash
たけのこの里が好きな G くんのために、きのこの山を分別する装置を作ってあげた。 ~ 分別装置作成編 ~
2021-05-02 | Author : 市川 純, 呉 和仁
はじめに
こんにちは、プロトタイピングソリューションアーキテクトの市川です。
前回の記事 で呉さんに召喚されて、"きのこの山" は山に、"たけのこの里" は里に返す装置を作って欲しいと相談されたのがきっかけで、エッジで推論をするモノを作ることになりました。
前回の話では、夏休みの工作レベルの予算感で作ることが決まっていたので、家にあるものを漁りながら作ってみました。完成した装置を動画で撮影しましたので、まずはこちらを見ていただけると雰囲気が伝わるかと思います。
builders.flash メールメンバー登録
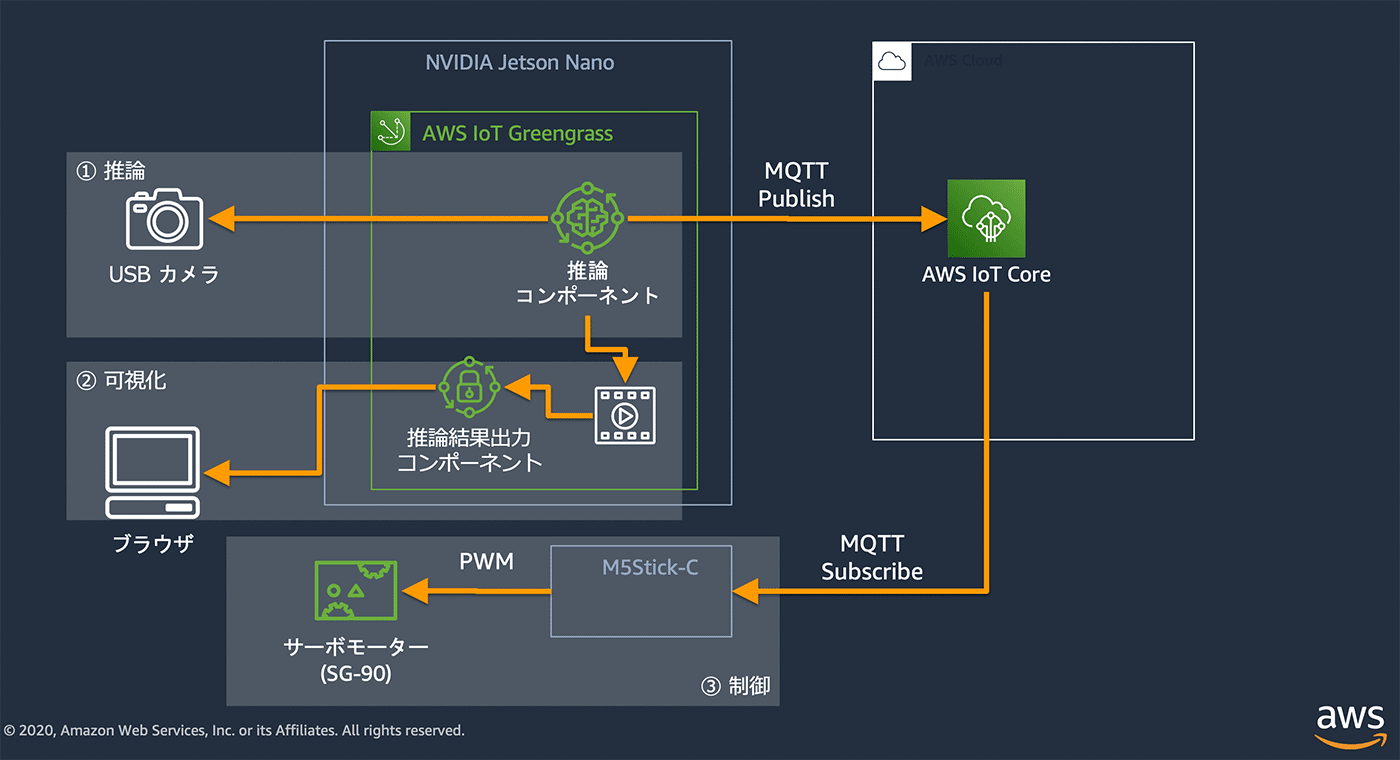
1. 全体アーキテクチャの紹介
この記事で作成した環境は、以下のようなアーキテクチャとなっています。NVIDIA Jetson Nano から直接サーボを制御することも、AWS IoT Greengrass を利用すれば ローカルだけで IoT デバイス同士のメッセージング もできるので、もっとシンプルなアーキテクチャにすることもできるのですが、今回は AWS IoT Core の MQTT ブローカーを介してサーボを制御する方法をとっています。
このようなアーキテクチャだとクラウド側からの指示でサーボを動かすこともできる為、作る時に AWS IoT Core の テストコンソール から簡単に試すことが出来ます。また、クラウド側からの指示で動かすことができるため、他のシステムとの連携が可能となってきます。さらにクラウド側に常に推論結果が届くため、稼働状況の可視化といったアーキテクチャへの拡張が簡単にできるようになりますので、今回はそのようなユースケースの参考になればと AWS IoT Core を経由するアーキテクチャにしました。
一方で、クラウド側からの操作は必要なかったり、推論結果はその都度必要ないといったユースケースでは、ローカルだけでメッセージングするアーキテクチャの方が向いているかもしれません。
アーキテクチャの中身を分けると、大きく 3 つの機能があります。
① 推論
AWS IoT Greengrass に前回の記事で作成した 機械学習のモデル と推論用のプログラムで推論コンポーネントを作成し、NVIDIA Jetson Nano に繋がっている USB カメラから画像を取り出して推論します。推論結果はバウンディングボックスを画像に描画してローカルストレージ上に保存しています。
② 可視化
推論結果出力コンポーネントでは、簡易的な Web サーバーを起動して、ローカルストレージに保存された画像を返すというエンドポイントを用意し、ブラウザからアクセスすることで、推論結果をブラウザから動画のように見られるようにしています。
③ 制御
推論結果を AWS IoT Core 経由でサーボ制御用のデバイスへ送り、受信したメッセージによって、サーボを制御します。
2. 利用する AWS のサービス
3. 分別装置を作る際に利用したもの
動画にある環境を構築する際に用意したものは、以下となります。今回利用したデバイスを揃えるとなった場合、予算としては 3 万ぐらいです。(ミーボード、マウス、モニターを除く)
- マウス、キーボード、モニターも必要
4. 開発の進め方
実際に動画でお見せした分別機を開発する際には、以下のような進め方を行いました。
4-1-1. ベルトコンベアの作成

ベルトコンベアはギアボックスに付属しているモーターを利用して動かしています。当初はフォトトランジスタを使って、物体を検出したらコンベアを止めてから推論する方法を考えていましたが、工作が複雑になってしまうことから、ベルトコンベアを動かしたまま推論を行う方法にしました。
この方式の場合は、ベルトコンベアが速すぎると推論に必要な時間が確保できなくなる可能性があります。ギア比を低速に設定してみたものの 1.5v でモーターを動かしても速く感じたので安定化電源を使って電圧を 0.9v まで下げています。
4-1-2. サーボモーターの配線

サーボモーターを利用する時は、外部電源を利用するのが良いですが、今回は手抜きをして M5StickC から給電して動かしています (動画の最後の1つで検出したのにサーボのアームがすぐに動かなかったのは、こういう手抜きが原因です)。
サーボから直接コネクタで M5StickC に接続するため、以下のように配線しています。
|
サーボ側 |
コネクタ側 |
|
PWM (オレンジ色) |
白 (G32) |
|
Vcc (赤色) |
赤 (Vout) |
|
Ground (茶色) |
黒 (G) |
|
|
黄 (未使用) |
4-1-3. プログラムの開発
サーボモーターと推論アプリの開発は、ある程度ベルトコンベアの環境ができてから進めました。理由としては推論アプリを作っても実際に推論を実行する環境が揃っていないと、手戻りが発生するかと思ったからです。そして、出来上がった環境で推論アプリを動かしてみたら、やはり期待通りに動かなかったため、ML スペシャリスト SA の呉さんを召喚しました。
セットアップの詳細は、後半の「6. 環境のセットアップとプログラミング」で必要な情報を公開していますので、実際に作りたいと思われた方は、是非そちらも見てみてください。
5. ML スペシャリストを再召喚 (推論用のモデルの再学習)
※以下フィクションです。
市川「呉さん、ちょっとツラをかしてもらえます ?」
呉「ヒィッ !」
市川「推論がうまくいかないんですがどういうことでしょう ? (圧)」
呉「ちょ、ちょっと状況確認させてください・・・」
市川「これを見てください」

きのこの山の検出範囲も検出数もおかしい

たけのこの里なのにきのこの山だし検出範囲がおかしい
呉「おおー、市川さんの作ったきのこの山とたけのこの里 on ベルトコンベア !! カッコイイ !」
市川「そこじゃないです。推論結果がめちゃくちゃじゃないですか」
呉「ソッスネ・・・」
市川「どういうことですか ?」
呉「コッカラッス」
市川「・・・じゃなくて、どうすれば直るんですか ?」
呉「機械学習で精度 100% は出ないですから・・・。」
市川「そういうレベルの話はしていません。」
呉「まず、もともとのテストの画像で再現してみるのはどうでしょうか ? 前回の記事では Amazon SageMaker Studio のPython 3 (MXNet 1.8 Python 3.7 CPU Optimized) カーネルで実行していたので、Jetson との環境差異が原因か確認させてください。」
市川「この通り問題ないんですよ」

呉「ということは、モデルの問題ということですね・・・(呉が手を動かさないと解決しないと思った時の顔をしている)。となると、撮影環境の差異が大きそうですね。学習とテストしたときの撮影状況に少し近づけてどうなるか確認してみたいです。撮影時は明るい状況で、黒机の上やティッシュを下に敷いて撮ったりしたので、ティッシュを下に敷いて撮ってみてどうなるか教えてください。」

市川「少々お待ちを」


市川「ちゃんと取れますね」
呉「ということはカメラなどのデバイスの問題ではなく、背景がベルトコンベアだと検出できない、という説が濃厚ですね。機械学習ではトレーニングしたデータと推論するデータに乖離していると機能しないことが多く環境の差異 (背景) がモロに効いてしまった感じですね。工場とかだと静止したベルトコンベアだとできるけど動作中のベルトコンベアだと推論できない、あるいはその逆も、みたいなケースもあります。そもそも今回のケースだとベルトコンベア上に配置した画像は学習していないですし、黒机やティッシュなどの一様な背景でしかトレーニングしていなかったので検出できなかったようです。」
市川「つまり ?」
呉「ベルトコンベアを実際に動かして撮影した画像でラベリングしてトレーニングし直す必要があるということです。画像処理やオーグメンテーションでなんとかなる可能性もありますが、今回はベルトコンベアで動かすのが前提で本番環境が市川さんの手元にあるので、そこで撮影した画像でトレーニングし直すのが間違いないかと。」
市川「ということは ?」
呉「・・・ラベリング頑張ります。」
市川「まぁまぁ、画像の準備は私がやりますよ。どれくらいの枚数が必要ですか ?」
呉「20 枚ちょっとあればランダムクロップで増幅して使い物になるかと」
市川「現状 640x480 の解像度しか出せないんですが、そこからランダムクロップできます ?」
呉「・・・画像サイズが小さすぎますね・・・。以前は 512x512 だったので縦がそれ以下だとランダムクロップ難しそうです。」
市川「じゃあ枚数を多く撮って多くラベリング ?」
呉「ということです。」
市川「はい、か Yes で答えてほしいのですが、ラベリングやってくれるんですよね ?」
呉「・・は、はい・・・」
市川「撮影はデバイスが自動でやるのでご安心ください (ニッコリ)。何枚くらい必要ですか ?」
呉「とりあえず 200 枚くらい・・・」
市川「お待ちを」
5-1. ラベリング職人、再び
かくして、きのこの山が 230 枚、たけのこの里が 216 枚の画像が送られてきました。
きのこの山の画像群
たけのこの里の画像群
ここからさらにもう一度 Amazon SageMaker Ground Truth でラベリングしていきます。
まずは前回の記事同様、S3 に画像をアップロードします。
import sagemaker
input_s3_uri = sagemaker.session.Session().upload_data(path='./conveyor_image/', bucket=sagemaker.session.Session().default_bucket(), key_prefix='conveyor_image')あとは前回同様画像のファイルパスの指定だけ変えてジョブを作成しました。(詳細はこちら)
前回は 23 枚のラベリングですみましたが、今回は 400 枚以上の画像に対して一人でやるのは大変です。ここは一つ、市川さんにもやってもらおうと呉はたくらみました。
Amazon SageMaker Ground Truth は複数人でのラベリング作業も対応しているので、その機能を使ってみましょう。
5-1-1. 複数人でのラベリング
こちらの URLにアクセスし (オハイオリージョンで行っております。皆様のリージョンをご利用ください)、「プライベート」→「新しいワーカーを招待」をクリックします。

招待したい人のメールアドレスを入力し、「新しいワーカーを招待」をクリックします。

このようなメールが市川さんに送信されますので、市川さんが以下の作業をしてくれることに期待します。
{ID}.{REGION}.sagemaker.aws のリンクに飛びます。

あとは、サインインしてパスワードを変更してもらいます。
市川さんがログインしてメールアドレスの確認ができたら呉の作業でワークフォース (ラベリングのチーム) に市川さんを追加します。

これで市川さんにもラベリングジョブを割り振られます。(ゲス顔)
さて、市川さんがやってくれるかどうかはさておき、自分でもやらないと進まないのでラベリングします。結局大量にラベリングするオチでした。
(16 倍再生で作業抜粋です)
5-1-2. ワーカーのラベリング状況を見守る
さて、アノテーションしたものの、市川さんが本当にやってくれたのか気になるところです。Amazon SageMaker Ground Truth はワーカーがどんな行動をしたのかをトラッキングすることもできます。市川さんの良心を少し覗いてみましょう。
Amazon SageMaker Ground Truth では誰がどのデータに対してラベリングしたか、時間はどれくらいかかったのか ? ラベリングの内容は ? などは全て Amazon S3 に残っていますので、それを集計してもいいのですが、Amazon CloudWatch Metrics で、/AWS/SageMaker/Workteam の CognitoUserPool,WorkerId を見に行くことで、各ユーザーがどの時間に何件処理したのか、をみることができます。
ふむふむ、4/4 4:00-6:00 (UTCなので JST 換算だと +9 で 13:00-15:00) に作業していることがわかります。

4/4 4:00-6:00 の市川の作業
なんか瞬間最大で 5 分で 40 件程度やってくれている・・・?
合計も見てみましょう。

9d4xxx が市川さんで、591xxx が呉の作業
あれ、387 件もやってくれている…。呉は 59 件しかやっていない・・・。カメラで撮影だけじゃなくて、6 倍以上ラベリングしてくれている・・・。ラベリング菩薩が降臨したようです。あ~り~が~た~や~。
さて、ラベリングの中身もちょっと確認してみましょう。ラベリングに一番時間がかかった画像と、そのかかった時間、そのラベリングを担当した人間を特定してみます。
import sagemaker
import os, json
TARGET_DIR = 'annotation_result'
!mkdir -p {TARGET_DIR}
sagemaker.session.Session().download_data(TARGET_DIR,bucket=sagemaker.session.Session().default_bucket(),key_prefix='conveyor_image/conveyor-image/')
ITE1_WORKER_RESPONSE = './annotation_result/annotations/worker-response/iteration-1/'
max_time = 0
userid = ""
for directory in sorted(os.listdir(ITE1_WORKER_RESPONSE)):
tmp_dir = os.path.join(ITE1_WORKER_RESPONSE,directory)
tmp_json_file = os.path.join(tmp_dir,os.listdir(tmp_dir)[0])
with open(tmp_json_file) as f:
tmp_json = json.loads(f.read())['answers'][0]
if max_time < float(tmp_json['timeSpentInSeconds']):
max_time = float(tmp_json['timeSpentInSeconds'])
userid = tmp_json['workerMetadata']['identityData']['sub']
print(max_time,userid)
出力結果
525.306 9d41bf13-2f4b-4563-9f36-326e0445fc66
9d4xxx なので市川さんが 525 秒 (9 分弱) かけた画像があるようですね。おそらく画像を眺めながらたけのこの里を頬張っていた時間でしょう。このように Amazon SageMaker Ground Truth ではラベリングジョブでどれくらい時間がかかったかや、他にも誰がどの画像を担当したのかを追えたりもします。
さて、ここからは 前回同様 Amazon SageMaker JumpStart で Fine-Tune します。まずはラベリング結果を取得します。
sagemaker.session.Session().download_data('./manifest/',key_prefix=f'conveyor_image/conveyor-image/manifests/output/output.manifest',bucket=bucket)5-2. Amazon SageMaker JumpStart で Fine-Tune 再び。せっかくなので今回は API で。
さて、ここから Fine-Tune するために annotation.json を加工していく必要があります。
5-2-1. ランダムクロップ処理をパスする
前回は annotation.json を作ると同時にランダムクロップを行っていました が、今回は画像サイズが小さいのでランダムクロップは適していません。
コードを書き直すのは大変なので既存のコードを修正して annotation.json を作成していきましょう。
# 追記 : ベルトコンベアの画像を格納したディレクトリに定数を変更
TRAIN_RAWIMAGE_DIR = 'conveyor_image'
# ラベリング結果をテキストとして読み込む
with open('./manifest/output.manifest','r') as f:
manifest_line_list = f.readlines()
# クロップした結果のきのこの山やたけのこの里の位置情報を格納する辞書
annotation_dict = {
'images':[],
'annotations':[]
}
# クロップサイズの定数
IMAGE_SIZE_TUPLE=(640,480) # 変更 : 画像サイズ変更
# クロップした画像のファイル名に使う一意なシーケンス番号
IMAGE_ID = 0
# クロップした画像の保存先
OUTPUT_DIR = './train_random_crop_images/'
# (re-run用の削除コマンド)
!rm -rf {OUTPUT_DIR}*.png
# ラベリング結果の行数分ループする
# ラベリング結果は 1 行につき 1 画像格納される
for manifest_line in manifest_line_list:
# 画像のラベリング結果の読み込み
manifest_dict = json.loads(manifest_line)
# 画像のファイル名取得(ラベリング結果に格納されている)
filename = manifest_dict['source-ref'].split('/')[-1]
# 元画像のサイズを取得(ラベリング結果に格納されている)
image_size_tuple=(manifest_dict['conveyor-image']['image_size'][0]['width'],manifest_dict['conveyor-image']['image_size'][0]['height'])
# PIL で画像を開く
raw_img = Image.open(os.path.join(TRAIN_RAWIMAGE_DIR,filename))
# 変更 : クロップ回数は1回(=ランダムクロップしない)
for i in range(1):
# ループさせる必要がないので無視
# # ループするかどうかのフラグ(画像にきのこの山やたけのこの里が 2 枚未満だったらクロップをやりなおし)
# loop = True
# while loop:
# クロップを行う左上の座標を設定
rand_x = 0
rand_y = 0
# クロップする
crop_img = raw_img.crop((
rand_x,
rand_y,
rand_x + IMAGE_SIZE_TUPLE[0],
rand_y + IMAGE_SIZE_TUPLE[1]
))
# クロップ後のきのこの山やたけのこの里の位置を格納するリスト
annotation_list = []
# 元画像のラベリング結果をループ
for annotation in manifest_dict['conveyor-image']['annotations']:
# クロップした後のきのこの山やたけのこの里の座標に補正
left = annotation['left'] - rand_x
top = annotation['top'] - rand_y
right = annotation['left'] + annotation['width'] - rand_x
bottom = annotation['top'] + annotation['height'] - rand_y
# 変更 : きのこの山やたけのこの里があるかどうかを判定する必要がないのでコメントアウト
# judge,(left,top,right,bottom) = fix_bbox(left,top,right,bottom,IMAGE_SIZE_TUPLE[0],IMAGE_SIZE_TUPLE[1])
# if judge:
# # きのこの山やたけのこの里があったら位置とラベルを追加
# 変更 : 判定がなくなったのでインデントを前へ
annotation_list.append(
{
'bbox':[left,top,right,bottom],
'category_id':annotation['class_id']
}
)
# 変更 : クロップやり直しは不要なのでコメントアウト
# # きのこの山やたけのこの里と数が2未満だったらクロップやり直し
# if len(annotation_list):
# loop = False
# クロップしたら画像を保存する
save_file_name = f'{str(IMAGE_ID).zfill(5)}_{str(i).zfill(5)}_{filename}'.replace('jpg','png')
crop_img.save(os.path.join(OUTPUT_DIR,save_file_name))
# 補正済ラベリング結果を出力用辞書に格納
annotation_dict['images'].append(
{
'file_name' : save_file_name,
'height' : IMAGE_SIZE_TUPLE[1],
'width' : IMAGE_SIZE_TUPLE[0],
'id' : IMAGE_ID
}
)
for annotation in annotation_list:
annotation_dict['annotations'].append(
{
'image_id': IMAGE_ID,
'bbox':annotation['bbox'],
'category_id':annotation['category_id']
}
)
IMAGE_ID += 1
# ランダムクロップ補正後のラベリング結果を出力
with open('annotations.json','wt') as f:
f.write(json.dumps(annotation_dict))
# 出力したディレクトリを prefix として使う
prefix = OUTPUT_DIR[2:-1]
# re-run 用の削除コマンド
!aws s3 rm s3://{sagemaker.session.Session().default_bucket()}/{prefix} --recursive
# ランダムクロップした画像をアップロード
image_s3_uri = sagemaker.session.Session().upload_data(OUTPUT_DIR,key_prefix=f'{prefix}/images')
# ラベリング結果をアップロード
annotatione_s3_uri = sagemaker.session.Session().upload_data('./annotations.json',key_prefix=prefix,bucket=sagemaker.session.Session().default_bucket())
# Fine-Tune で使う URI を出力
paste_str = image_s3_uri.replace('/images','')
print(f"paste string to S3 bucket address:{paste_str}")
コメントアウトするだけで済むところが多かったです。差分はコメントで書きましたが、ぜひ前回の記事との diff を取ってみてください。
最後にトレーニングしてモデルを市川さんに引き渡します。
5-2-2. Amazon SageMaker JumpStart の Fine-Tune を API でキックする
トレーニングについては、当然 Amazon SageMaker JumpStart を使うのですが、Amazon SageMaker JumpStart が API を公開しました。これにより SageMaker Studio からマウスポチポチでモデルをデプロイしたり Fine-Tune するだけでなく、コードでデプロイや Fine-Tune できるようになりました。早速ですがこの機能を使って見ましょう。
流れとしては、学習に使う pre-trained model と、Fine-Tune するためのトレーニングスクリプト、トレーニングで使用するコンテナイメージの URI をそれぞれ API で取得し、ハイパーパラメータを設定して実行します。詳細は SageMaker SDK の JumpStart ドキュメント を参照ください。ほぼドキュメントにあるコードをコピペしています。
from sagemaker import image_uris, model_uris, script_uris
model_id, model_version = "mxnet-od-ssd-512-mobilenet1-0-coco", "1.1.0"
training_instance_type = "ml.g4dn.xlarge"
instance_count = 1
# Retrieve the JumpStart base model S3 URI
base_model_uri = model_uris.retrieve(
model_id=model_id, model_version=model_version, model_scope="training"
)
# Retrieve the training script and Docker image
training_script_uri = script_uris.retrieve(
model_id=model_id, model_version=model_version, script_scope="training"
)
training_image_uri = image_uris.retrieve(
region=None,
framework=None,
image_scope="training",
model_id=model_id,
model_version=model_version,
instance_type=training_instance_type,
)
from sagemaker.estimator import Estimator
from sagemaker.session import Session
from sagemaker import hyperparameters
# URI of your training dataset
training_dataset_s3_path = paste_str
# Get the default JumpStart hyperparameters
hps = hyperparameters.retrieve_default(
model_id=model_id,
model_version=model_version,
)
# [Optional] Override default hyperparameters with custom values
hps['epochs'] = '40'
hps['adam-learning-rate'] = '0.0001'
# Create your SageMaker Estimator instance
estimator = Estimator(
image_uri=training_image_uri,
source_dir=training_script_uri,
model_uri=base_model_uri,
entry_point="transfer_learning.py",
role=Session().get_caller_identity_arn(),
hyperparameters=hps,
instance_count=instance_count,
instance_type=training_instance_type,
enable_network_isolation=True,
)
# Specify the S3 location of training data for the training channel
estimator.fit({"training": training_dataset_s3_path})
最後に以下のように表示されれば無事トレーニング完了です。
YYYY-MM-DD HH:MI:SS Completed - Training job completed
Training seconds: {かかった秒数}
Billable seconds: {かかった秒数}
5-2-3. モデルの取得
さて、トレーニングが終わったので出来上がったモデルを市川さんに送りつけましょう。使ったモデルは latest_training_job.describe メソッドで出力されるトレーニングジョブ詳細の中の ModelArtifacts というキーの中に S3 の URI があり、そこにモデルがありますのでダウンロードした上で解凍します。
import tarfile
prefix = estimator.latest_training_job.describe()['ModelArtifacts']['S3ModelArtifacts'].replace(f's3://{sagemaker.session.Session().default_bucket()}/','')
sagemaker.session.Session().download_data('./', sagemaker.session.Session().default_bucket(), key_prefix=prefix)
with tarfile.open('./model.tar.gz', 'r') as f:
f.extractall()
解凍するといろいろファイルが出てきますが、再学習したモデル (重みとバイアス) は finetuned_model.params ですので、こちらを市川さんに転送します。
6. 環境のセットアップとプログラミング
6-1. SageMaker Studio で必要なクラウドのリソース作り
前回の記事を試されている場合は、すでに Amazon SageMaker Studio の環境があると思いますので、その環境を利用します。前回の記事 を試されていない場合は、先にそちらを進めてから、こちらの手順を進めてください。
ダウンロードしたサンプルソースの zip ファイル を Amazon SageMaker Studio にアップロードして zip ファイルを展開します。展開すると BuildersFlashSample というフォルダが作られます。
BuildersFlashSample フォルダの中に 前回記事で取得した model.tar.gz を置きます。 BuildersFlashSample/inference_updates の中には、先の手順で作成した finetuned_model.params を置きます。
-
component: AWS IoT Greengrass の推論と推論結果確認用のコンポーネント作成に必要なソースコードが含まれています
-
infernece_updates: この記事で紹介しているエッジ推論のコンポーネントを作成する際に、置き換えが必要なファイルが含まれています。このフォルダの中に先の手順で作成したfinetuned_model.paramsを置いてください
-
m5stickc: M5StickC のプログラムに必要なファイルが含まれています
-
iot-edge.ipynb: AWS IoT Core に対して必要な設定や、コンポーネントの作成を行う手順が書かれています。
-
model.tar.gz: 前回の記事で推論エンドポイントから取得したmodel.tar.gzを置きます
iot-edge.ipynbをダブルクリックしてノートブックを開き、ノートブックに書かれている手順に沿って進めます。

6-1-1. Amazon SageMaker Studio の IAM Role を更新
ノートブックでは、様々なリソースを編集します。以下の IAM 権限が必要になりますので Amazon SageMaker Studio の Role に以下のマネージドポリシーを追加します。(今回はサンプルを作るために強めの権限を付与していますが、本番の環境などで作成する場合は、最低限必要な権限に留めるようにしてください)
-
IAMFullAccess
-
AmazonS3FullAccess
-
AWSIoTFullAccess
-
AWSGreengrassFullAccess
6-1-2. サーボを動かす M5StickC 用の AWS IoT Core 設定
M5StickC のアプリケーションでは AWS IoT Core の MQTT ブローカーに届くメッセージをサブスクライブし、サーボを制御します。 AWS IoT Core へ接続するには、 Thing 、証明書、 IoT Policy が必要となるため作成します。ノートブックの「サーボを動かす M5StickC 用の AWS IoT Core 設定」の手順を進めると、 Thing 、証明書、 IoT Policy が作成され、認証情報で利用する証明書と秘密鍵が Amazon SageMaker Studio 上に保存されています。この 2 つのファイル (cert.pem, key.pem) とM5StickC に必要なプログラム (m5stickc.m5f) をダウンロードします。
-
BuildersFlashSample/m5stickc/m5stickc.m5f
-
BuildersFlashSample/m5stickc/certs/cert.pem
-
BuildersFlashSample/m5stickc/certs/key.pem
6-2. サーボ制御用 M5StickC のプログラミング
一度 Amazon SageMaker Studio 上の作業は終了し、自分の PC で以降の作業を進めます。
M5StickC のプログラミングでは、以前に書いた記事「夏休みの課題にプログラミングの学習をしながらラジコンを作ろう !」で紹介している UIFlow を利用しています。これらのツールは、頻繁にアップデートされるため、公式のサイト を参照しながらセットアップしてください。この記事では、以下のバージョンを利用しています。
-
UIFlow IED v1.7.4
-
M5StickCのファームウエア v1.9.4
サンプルに含まれている m5stickc.m5f を UIFlow に読み込むと、こちらのようなブロックが確認できます。

それぞれのパートの役割と必要な作業ですが、
① AWS IoT Core に接続し、表示やサーボの初期設定をおこなっています。自分の環境に合わせて修正が必要です。
-
接続する自分のAWS IoT Coreエンドポイントに修正します
-
M5StickC を USB で PC へ繋いだ状態で、6-1-2. サーボを動かす M5StickC 用の AWS IoT Core 設定で作成したcert.pemとkey.pemをアップロードして、keyFile と certFile に指定します。
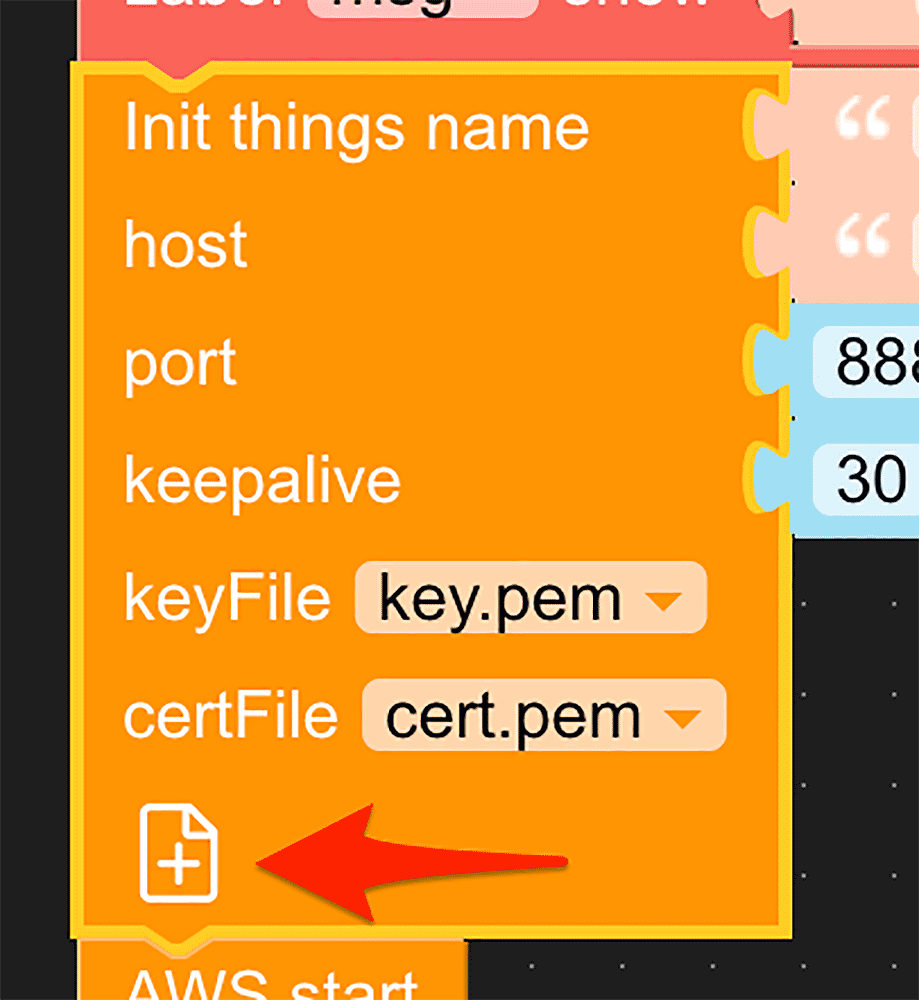
②bf202205/actionという Topic に Subscribe しています。メッセージが届くと JSON データの内容によって、サーボを制御します。
③ ボタン A を押した時の動き : 手動で動作確認をしたい場合は、このボタンを押すことでサーボが動きます
④ ボタン B を押した時の動き : 手動で動作確認をしたい場合は、このボタンを押すことでサーボが動きます
⑤ このプログラムがデバイス起動時も自動で実行させたい時は、このアイコンをクリックして書き込みます。
プログラミング中は、右上の再生ボタンで書き込むことが出来ます。この場合はデバイスを再起動すると、書き込んだアプリは実行されずに USB 接続モードで起動します
正常に書き込めたら、ボタンを押してサーボが動くことを確認してください。確認ができたら M5StickC の動作確認は完了です。
6-3. NVIDIA Jetson Nano のセットアップ
NVIDIA Jetson Nano (JetPack 4.4) では、推論に必要な機械学習のライブラリのインストールが必要です。今回はモデルを作る際の環境が MXNet 1.8、Python3.7 という環境でしたので、必要なものをインストールしています。ソースコードからのビルドはメモリを多く必要としますので Swap 領域を増やしておきます (ビルドには数時間かかります)。
6-3-1. SWAP 領域を増やす
git clone https://github.com/JetsonHacksNano/installSwapfile
cd installSwapfile
./installSwapfile.shインストールが終わった環境の情報は以下のとおりです。
$ uname -a
Linux nvidia 4.9.140-tegra #1 SMP PREEMPT Fri Oct 16 12:32:46 PDT 2020 aarch64 aarch64 aarch64 GNU/Linux $ python3 --version
Python 3.7.5 $ python3
>>> import mxnet, gluoncv, cv2
>>> mxnet.__version__
'1.8.0'
>>> gluoncv.__version__
'0.11.0'
>>> cv2.__version__
'4.5.5'6-4. AWS IoT Greengrass のセットアップ
このサンプルでは AWS IoT Greengrass を利用してエッジ推論のアプリを実行します。手順は開発者ガイドで紹介されている手順のとおりですが、以下にも手順を掲載します。
セットアップの際に様々なリソースの登録を行いますので Administrator 権限を持つアクセスキーとシークレットキーを以下の環境変数で指定してください。最低限の権限のみを付与したい場合は、こちらのページ を参考にしてください。
$ export AWS_ACCESS_KEY_ID=
$ export AWS_SECRET_ACCESS_KEY=
$ export AWS_DEFAULT_REGION=ap-northeast-1AWS IoT Greengrass は Java ランタイムを必要としますので、インストールします。
$ sudo apt install -y curl default-jdkAWS IoT Greengrass のセットアップに必要なファイルをダウンロードし、インストールします。
$ sudo -E java -Droot="/greengrass/v2" -Dlog.store=FILE \ -jar ./GreengrassInstaller/lib/Greengrass.jar \ --aws-region $AWS_DEFAULT_REGION \ --thing-name bf202205_Nano \ --thing-group-name bf202205_Nano_Group \ --thing-policy-name bf202205_Nano_IoTPolicy \ --tes-role-name bf202205_Nano_TESRole \ --tes-role-alias-name bf202205_Nano_TESRoleAlias \ --component-default-user ggc_user:ggc_group \ --provision true \ --setup-system-service true以上で AWS IoT Greengrass のセットアップが完了しました。
6-5. AWS IoT Greengrass のコンポーネント作成
Amazon SageMaker Studio のノートブックに戻り、「AWS IoT Greengrass のコンポーネントを作成」の手順を進めます。この手順では、以下の作業を行っています。
6-5-1. コンポーネントをホストする Amazon S3 のバケットを作成
バケット名を変えたい場合は、この部分を修正してください。
# AWS IoT Greengrass のコンポーネントを保存するバケットを作成
component_bucket_name = f"bf202205-ggcomponent-{account_id}"
component_bucket_name6-5-2. 推論コンポーネントの作成 (com.example.takenoko)
このコンポーネントはカメラから画像を取得し推論を行います。推論結果は検出した物体のクラス名と物体の位置情報が取得できます。クラス名は AWS IoT Core の特定の Topic に送信しています。また、物体の位置情報を使って画像に枠を描画しストレージ上に保存します。
- 機械学習のモデルと推論用のソースコードで zip ファイルを作成
- S3 にアップロード
- コンポーネントの Recipe を作成
- コンポーネントを AWS IoT Greengrass に登録
6-5-3. 推論結果表示用のコンポーネントの作成 (com.example.streamer)
簡易的な Web サーバーを起動し特定のパスに保存された画像を返す動きをします。NVIDIA Jetson Nano の場合はストレージが SD カードのため、SD カードに対して随時画像が書き込まれます。利用状況によっては SD カードの寿命に影響が出ますので、長期的に利用が考えられる場合は、推論コンポーネントと統合してメモリ渡しにするといった方法を取るのが良いかもしれません。
- ブラウザで推論結果を見られるソースコードで zip ファイルを作成
- S3 にアップロード
- コンポーネントの Recipe を作成
- コンポーネントを AWS IoT Greengrass に登録
6-5-4. コンポーネントのデプロイ
AWS IoT Greengrass のインストールで名称など変更した場合は、以下の部分を修正して正しい AWS IoT Greengrass Core にデプロイされるようにしてください。
# AWS IoT Greengrass を Jetson Nano 上にインストールした時の、
# Thing 名(--thing-name)、グループ名( --thing-group-name)、 Role 名(--tes-role-name)を変数に指定します
GG_THING_NAME="bf202205_Nano"
GG_GROUP_NAME="bf202205_Nano_Group"
GG_TES_ROLE="bf202205_Nano_TESRole"デプロイが終わると、コンポーネントが自動で動き出しますので、 Jetson Nano のブラウザからhttp://127.0.0.1/live.mjpgにアクセスしてみてください。最初の推論が実行される際に、モデルのロードや最適化の処理が内部で実行されるため、1〜2 分ほど画面に変化が出ません。しばらく待っても画像が表示されない場合は、AWS IoT Greengrass のログを確認してください。
7. まとめ
市川の脳に描かれたマーベラスでファビュラスなデバイスの正体とは一体・・・ ?
AWS IoT Greengrass でアプリを配信 ! デプロイがこんなに簡単にできるの・・・?
果たして適当に撮影した 23 枚の画像で学習したモデルは本物のベルトコンベアで流れてくるきのこの山とたけのこの里に太刀打ちできるのか !? ラベリング職人再び現る !?
2 つの記事に渡って AWS の機械学習向けサービスと IoT 向けサービスを利用した、モノの自動分別を紹介してきましたがいかがでしたでしょうか ?
今回は "きのこの山" と "たけのこの里" を分けるのに、機械学習で作成したモデルを使い、エッジデバイス上で推論処理を行って制御をするサンプルを作りました。このような仕組みは様々な分野でも取り組まれており、製品の外観検査、商品の在庫管理など、多くのユースケースで利用されています。サンプルを作る過程で、色々と試行錯誤を行ないましたが、本番の環境でも同じような課題に遭遇すると思います。
以下は試行錯誤した内容のまとめです。
-
機械学習のデータはなるべく本番環境で得られるデータを利用したほうが精度を上げることが出来ます
-
画像を取る際はなるべく同じ光源がある状態で取ることで、環境の差異を減らすことが出来ます
-
タクトタイム内で推論対象の動きを止めることができるのであれば、止めることも検討しましょう
動画撮影の裏側です。手前にあるデバイスは、左から安定化電源、ライト、デモ動画撮影用の三脚です。

筆者プロフィール

市川 純
アマゾン ウェブ サービス ジャパン合同会社
技術統括本部 プロトタイピング ソリューションアーキテクト
2018年 に AWS へ入社した、Web サービスから家のデッキ作りまで、モノを作るという事であれば何でも好きな DIY おじさんです。最近は週末にバイクをイジるのにハマっています。

呉 和仁 (Go Kazuhito / @kazuneet)
アマゾン ウェブ サービス ジャパン合同会社
機械学習ソリューションアーキテクト。
IoT の DWH 開発、データサイエンティスト兼業務コンサルタントを経て現職。
プログラマの三大美徳である怠惰だけを極めてしまい、モデル構築を怠けられる AWS の AI サービスをこよなく愛す。
Did you find what you were looking for today?
Let us know so we can improve the quality of the content on our pages