- AWS Builder Center
- builders.flash
Amazon DynamoDB のエクスポートデータを、別アカウントの既存テーブルに復元する
2024-07-02 | Author : 三浦 一樹 (AWS Community Hero)
はじめに
札幌在住の AWS Community Hero の三浦です。
現在、弊社では適切な分割がされていなかった AWS アカウントの分割を行っていました。この際、開発環境で使っていた複数の Amazon DynamoDB (以降、DynamoDB) のテーブルのデータを別アカウントにお引越しする必要が出てきました。
DynamoDB のデータのエクポートは「S3 からのインポート」という DynamoDB の機能で、簡単に行うことができます。そのエクスポートしたデータから DynamoDB の標準機能を用いてのインポートを行うことができる「S3 からインポート」機能では、新しい DynamoDB テーブルを作成する必要があります。既存のテーブルへのインポートは現在この機能ではサポートされていません。(DynamoDB のロードマップには、既存のテーブルへのインポートが明記されているため、リリースが待ち遠しいです。)
そのため、既存の DynamoDB テーブルに対して、復元を行いたい場合は、自分で実装する必要があります。その手順をお伝えしたいと思います。
ご注意
本記事で紹介する AWS サービスを起動する際には、料金がかかります。builders.flash メールメンバー特典の、クラウドレシピ向けクレジットコードプレゼントの入手をお勧めします。
builders.flash メールメンバー登録
1. 全体構成
手順は以下の通りです。
-
DynamoDB から別アカウントの Amazon Simple Storage Service (以降、S3) にデータをエクスポートする
-
実際にエクスポートされたデータの中身を見て確認する
-
実際にエクスポートされたデータの中身を見て確認する
-
-
AWS Step Functions を用いて、S3 にエクスポートされた複数のファイルを元に DynamoDB に 書き込む
全体構成図
2. DynamoDB から S3 に対して、データをエクスポートする
2-1. エクスポートを保存する S3 の設定
エクスポートしたデータを受け取る方のアカウント B に S3 バケットを作成します。(以下、エクスポートされるバケット名の部分を EXPORT-BUCKET としています)
対象のバケットには、以下のように、アカウントAからのアクセスを許諾するためのポリシーを設定する必要があります。DynamoDB のエクスポートは内部的に S3 のマルチパートアップロードの機能を使っています。そのため、必要最低限の Action は s3:AbortMultipartUpload , s3:PutObject , s3:PutObjectAcl の 3 つです。
ただし、コンソール上での確認が簡単になるため s3:ListBucket も追加しておきます。
今回は AWS コンソールからの操作で DynamoDB のエクスポートを実施するため Principal には、アカウント A で操作する IAM ユーザーの ARN を使用しています。AWS SDK など、他の方法で実施する場合は適宜変更してください。
アクセスを許諾するためのポリシー
記述例
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "AllowDynamoDBExportAnotherAccount",
"Effect": "Allow",
"Principal": {
"AWS": "arn:aws:iam::111122223333:user/A-USER-NAME"
},
"Action": [
"s3:AbortMultipartUpload",
"s3:PutObject",
"s3:PutObjectAcl",
"s3:ListBucket"
],
"Resource": "arn:aws:s3:::EXPORT-BUCKET/*"
}
]
}2-2. AWS コンソールから DynamoDB のエクスポートを行う
このエクスポート機能を使うためには、対象のテーブルのポイントインタイムリカバリ (PITR) が有効になっている必要があります。
AWS コンソールでは、DynamoDB > テーブル から、「バックアップ」タブにて有効化することができます。
S3 へのエクスポート
PITR の状態が「オン」になっていることが確認できたら、DynamoDB > S3 へのエクスポート を選択し、「S3へのエクスポート」ボタンを押します。
エクスポート設定
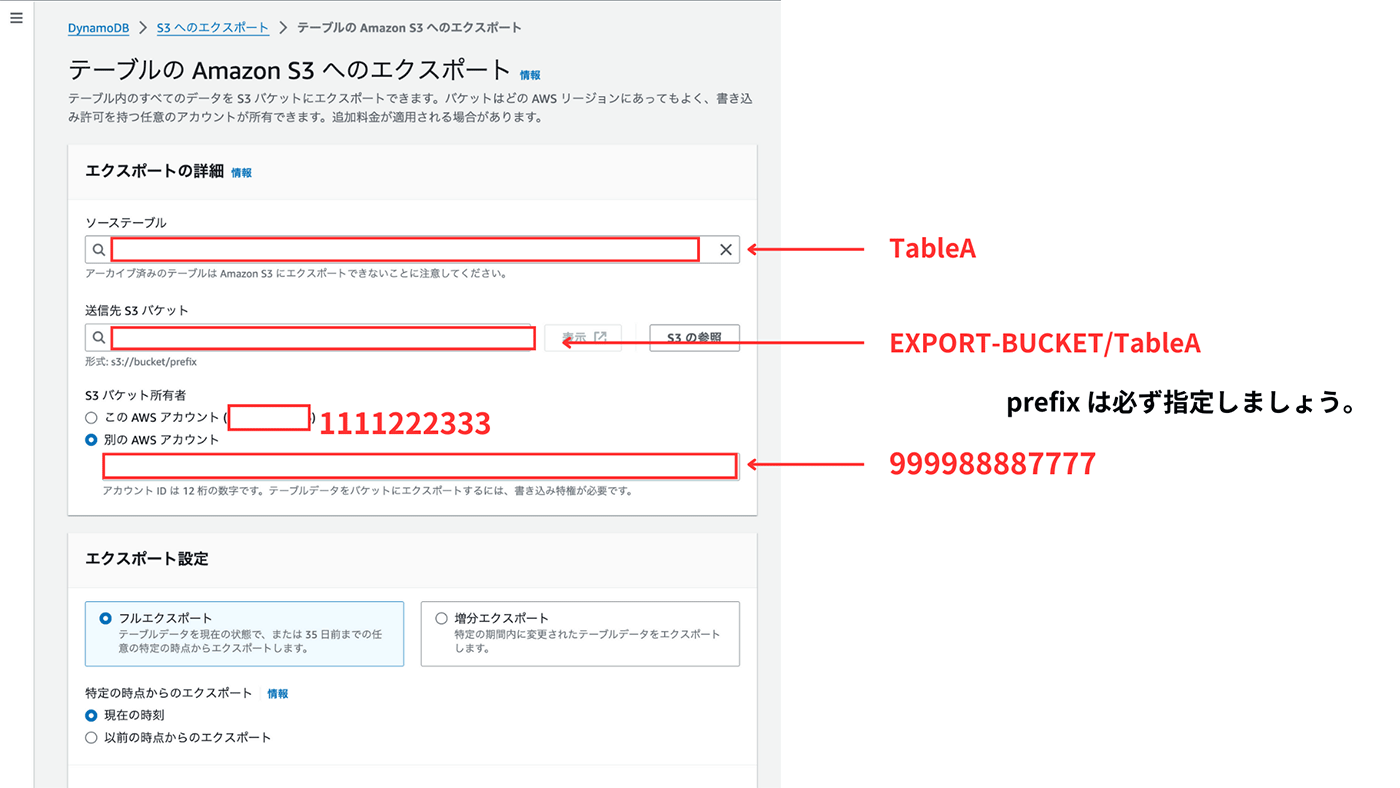
ここでは、以下のように設定をします
-
バックアップを取りたい DynamoDB のテーブルを選択
-
AWS アカウント B のバケットを指定
-
s3://EXPORT-BUCKET/TableA のように、直接指定します
-
S3 を見た時にどのテーブルのデータなのかを分かりやすくするため、prefix にテーブル名を入れてください
-
別アカウントのものを指定するため「S3 の参照」ボタンは使えません
-
-
エクスポート先のアカウントを指定
-
S3 バケットの所有者で、「別の AWS アカウント」を選択
-
12 桁の AWS アカウント ID を記入
-
-
図の「エクスポート設定」はデフォルトのままで
-
今回はフルエクスポートを実施しますが、時間を指定しての増分エクスポートも行うことができます
-
ここまで、設定できたら、画面右下の「エクスポート」ボタンを押します。
すると、画面が遷移します。この画面では履歴を見ることができます。
先ほど実施したエクスポートの履歴を確認すると、状態が「エクスポート中」になっていることが確認できます。しばらくすると、状態が「完了」になり、エクスポートが終了したことが分かります。
この時、DynamoDB への負荷についてですが、この機能を使った場合、DynamoDB のキャパシティユニットを消費せずにエクスポートを行うことができるため、DynamoDB への負荷を考えなくてもよいです
3. エクスポートされたファイルを確認する
エクスポートされたファイルは以下のようになっています。 このファイル構造は「フルエクスポート」を実施した時のもので、「増分エクスポート」を実施した際には違う構造になることを注意してください。
EXPORT-BUCKET/TableA
.
└── AWSDynamoDB
├── 01693685827463-2d8752fd // 同じS3バケットへの複数のエクスポートを保証するID
│ ├── manifest-files.json // 「data」フォルダの中身について
│ ├── manifest-files.checksum
│ ├── manifest-summary.json // エクスポートジョブについての詳細なメタデータ
│ ├── manifest-summary.md5
│ ├── data // 4つの json.gz が格納されている
│ │ ├── asdl123dasas.json.gz
│ │ ├── bvcx987vcxza.json.gz
│ │ ├── qwer456tyuib.json.gz
│ │ └── hjkl234zxcvs.json.gz
│ └── _started // 権限チェック時に生成された空ファイルmanifest-summary.json
manifest-summary.json ファイルは以下のようなデータが入っています。(一部項目抜粋) エクスポートした結果のレスポンスの一部にこの`manifest-summary.json`が入っています。自動化する時のことを考えると、このファイルに含まれる情報から manifest-files.json を見ると良さそうです。
{
"version": "2020-06-30",
"exportArn": "arn:aws:dynamodb:ap-northeast-1:111122223333:table/TableA/export/01693685827463-2d8752fd",
"startTime": "2024-06-10T08:50:00.000Z",
"endTime": "2024-06-10T09:00:00.000Z",
"tableArn": "arn:aws:dynamodb:ap-northeast-1:111122223333:table/TableA",
...
"s3Bucket": "EXPORT-BUCKET",
"s3Prefix": "TableA",
"s3SseAlgorithm": "AES256",
"s3SseKmsKeyId": null,
"manifestFilesS3Key": "TableA/AWSDynamoDB/01693685827463-2d8752fd/manifest-files.json",
...
"outputFormat": "DYNAMODB_JSON"
}manifest-files.json
manifest-files.json には data 配下に置かれた gzip ファイルの数だけ以下のような JSON Line が格納されています。
{
"itemCount":10,
"md5Checksum":"sQMSpEILNgoQmarvDFonGQ==",
"etag":"af83d6f217c19b8b0fff8023d8ca4716-1",
"dataFileS3Key":"TableA/AWSDynamoDB/01693685827463-2d8752fd/data/asdl123dasas.json.gz"
}エクスポートされるファイルについて
エクスポートされる対象のデータが少ない場合でも、少なくとも 4 つの gzip ファイルが作られるので、manifest-files.json は 4 行分の上記のようなデータが含まれています。manifest-files.json にアクセスできれば、dataFileS3Key の値からエクスポートされたすべてのファイルの場所を知ることができます。
また、エクスポートされた対象のデータが少ない場合、manifest-files.json 内部で "itemCount": 0 となり、0 KB の gzip ファイルが作られます。この状態でも ファイル数は 4 になります。これらの分割されたファイルを元に DynamoDB にデータを戻し入れてあげます。
ここで登場する manifest-files.json や data 配下のデータは JSON Lines 形式です。これは改行が区切り文字として使用されているデータで、Amazon Athena など多くの AWS サービスで自動的に解析されます。
このため、DynamoDB のデータを分析するためにも、エクスポートは便利に使える機能です。
4. S3 のエクスポートデータを AWS Lambda を使って DynamoDB に書き込む
エクスポートしたデータを元に アカウント B にすでに存在している DynamoDB テーブルにデータを入れてみましょう。
AWS Lambda (以降、Lambda) で ランタイムは node.js を指定して、AWS SDK の BatchWrite を用いでデータを put してきます。
DynamoDB にデータを書き入れるために AWS Step Functions を使っています。ここでは、2つのステートマシーンについて説明します。
-
データの場所と、書き込むデータを確認するステートマシン
-
manifest-summary.json のデータから manifest-files.json の中身を確認して、gzip ファイルの場所を特定する
-
データが入っている gzip の数だけ 後続の ステートマシンを起動する
-
1 つのテーブルを対象に行う場合は心配ないですが、複数のテーブルを対象に並列でこの処理をする際には Map の同時起動数 1000 (ハードクォータ) という制限があるので注意が必要です。
-
-
-
DynamoDBへのデータの書き込むを行うステートマシン
-
AWS SDK を使って S3 からのデータの取得
-
AWS SDK を使って、BatchWrite での DynamoDB の書き込み。
-
全体構成図
ここでは、2つのステートマシーンについて説明します。
ステートマシンについて
Lambdaで書き込む部分のコードは割愛しますが、gzip ファイルの解凍、JSON のパース、DynamoDB への書き込みを行なっていきます。
ステートマシンの分割はもちろんしなくてもいいのですが、コンソールでの失敗成功の見やすさ、再実行の手軽さからこのような構成をとっています。
また、ここでは詳しく触れませんが、これらの Lambda から DynamoDB への書き込みはとても高速に終わるため、データが多い場合は DynamoDB 側の制限に達してしまう可能性があります。これを回避するためには、書き込みをゆっくり行うか、失敗したデータを再度後から書き込むようにするなど、工夫が必要になってきます。
5. まとめ
手動でエクスポートした DynamoDB のファイルを元に、別テーブルへのデータのインポートを行ってみました。
おかげで Infrastructure as code (IaC) で定義していた開発環境のテーブルを別アカウントに展開し、上記の方法でデータを引っ越すことができました。
同一リージョンでのバックアップ/リストアだけであれば、ポイントインタイムリカバリだけでも、十分賄うことができると思いますが、お引越し案件以外にも、いざという時に、別リージョンに IaC 経由でまるっと再構築されたシステムにデータだけ入れたいときやデータ分析目的などで定期的にデータをエクスポートしたい。というときには使えるかもしれません。
一方でデータ分析目的の利用を想定すると、エクスポートの部分の定期実行やフルエクスポートではなく、増分エクスポートを使いたいなど、まだまだ派生が出てきそうなところが出てきそうです。
こちらも AWS Step Functions を使ってエクスポート部分の自動化も取り組んでいるところですので、次の機会があれば、そちらも紹介したいと思います。
著者プロフィール
三浦 一樹 (@miu_crescent / AWS Community Hero)
北海道テレビ放送株式会社 コンテンツビジネス局 ネットデジタル事業部
1986 年生まれ。2012 年東京工業大学卒業後、北海道テレビ放送に入社。放送の期間システムや電源設備の保守管理を行う 技術部門に配属される。2015 年からデータ放送コンテンツの開発、アクセスログ解析などに従事。 2017 年 5 月、AWS Summit 2017 のメディア業界シンポジウムに参加したことをきっかけに、放送×クラウドの 可能性に開眼。各地のコミュニティに参加するようになる。2020 年 3 月、コミュニティ活動への貢献が認 められ、「AWS Samurai 2019」に認定。2023 年 9 月、「AWS Community Hero」に選出。

Did you find what you were looking for today?
Let us know so we can improve the quality of the content on our pages