AI エージェントで分析効率を飛躍的に向上させる実装ガイド
2026-02-03 | Author : 日野原 弘幸 (あいおいニッセイ同和損害保険株式会社)
はじめに
あいおいニッセイ同和損保のデジタルビジネスデザイン部では、社内で蓄積される多様なデータを安全かつ効率的に分析できるよう、AWS 上に社内分析環境 (以下、分析基盤) を構築しています。当社のデータサイエンティストは、この基盤上で分析および DX 事業化に向けた開発を日々進めています。
本分析基盤では、Amazon Bedrock を活用した生成 AI エージェントを含んだチャットツールを実装しており、分析効率やデータ利活用推進に役立っております。本記事では、データサイエンティストが直面するデータ発見・理解の課題を AWS DataZone と Amazon Athena を連携させた AI エージェント機能でどのように解決したのか、そのエージェント実装内容をご説明します。
X ポスト » | Facebook シェア » | はてブ »
builders.flash メールメンバー登録
builders.flash メールメンバー登録で、毎月の最新アップデート情報とともに、AWS を無料でお試しいただけるクレジットコードを受け取ることができます。
データ分析上の課題
分析基盤では、保険・自動車走行データなどのビッグデータを活用できますが、データ項目の定義やメタデータがデータソースごとにサイロ化されていたため、データ発見や理解の妨げとなっていました。例えば、一部のプロジェクトで使用するデータ定義が Excel で属人的に管理されており、対象ファイルの探索に時間がかかる状況がありました。また、データカタログの存在する社内ネットワークと、データが格納されている AWS 分析基盤のネットワークを行き来しながら作業する必要があり、効率性の面でも課題がありました。
これらの課題に対し、対象データのメタデータを AWS DataZone に登録することで、データ内容をデータアセットとして集約管理できる仕組みを導入しました。分析基盤がAWS上に構築されているため、同一 AWS ネットワーク内で完結できる DataZone はガバナンス統制がしやすくセキュリティ・運用の観点から適切であると判断しました。
さらに、生成 AI チャットアプリ側に DataZone や Athena の API を実行可能なエージェント機能を追加し、データ発見・理解・問い合わせまでを 1 つの Web インターフェースで完結できる体験を実現しました。例えば、「あるデータのテーブル定義とカラム情報が知りたい」とチャットで質問すると、エージェントが自動で DataZone API を呼び出し、すぐにその定義を返します。さらに「ランダムに数件サンプルを見せて」と質問すれば、Athena API を使って安全な範囲でサンプルデータを抽出し、チャット画面から一切離れることなくデータの内容を確認できます。
生成 AI アプリのアーキテクチャ全体概要
生成 AI チャットアプリは、Amazon ECS を Web サーバーとして利用し、Amazon Bedrock のモデルと対話できるよう構築しています。アプリ内のエージェントモードでは、Bedrock エージェントを使用して以下のような アクショングループ (AWS Lambda 関数) にアクセス可能となります:
- AWS DataZone のアセット検索、アセット詳細の取得
- Amazon Athena を利用した対象テーブルのサンプルクエリ実行
ユーザーのリクエスト内容に応じ、この アクショングループ内の関数を自動的に呼び出せるよう設計しています。次のセクションではアーキテクチャ図の赤枠部分のエージェントの実装に焦点を当て、エージェントビルダーでの設定内容について説明します。
全体アーキテクチャ図
Amazon Bedrock エージェントの実装手順とアクショングループ関数の使用例
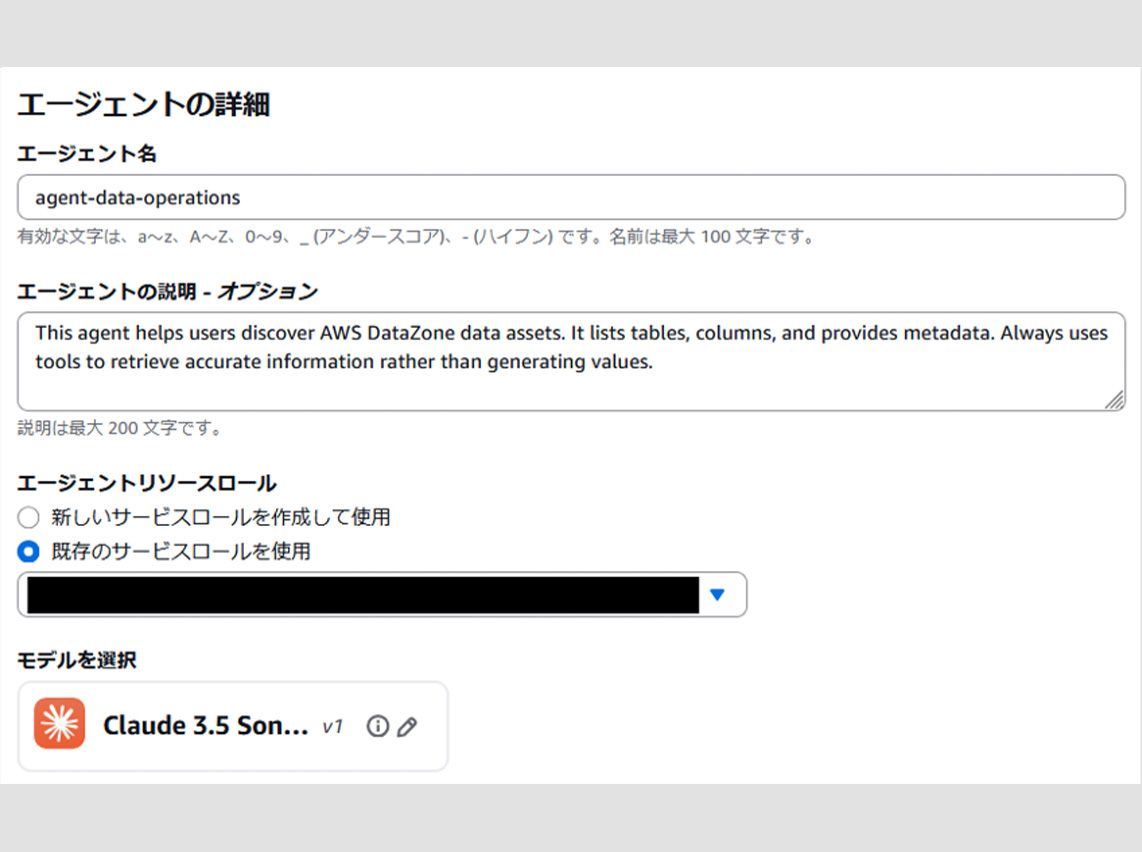
1. エージェントの詳細
エージェントビルダー内では下記のように設定します。セキュリティの問題でデータの国外持出しが発生しないように、東京リージョンのみで推論を実施する Claude3.5 Sonnet を使用しています。

2. アクショングループの設定
本システムではエージェント が実行可能な アクショングループを下記のように設定しています。
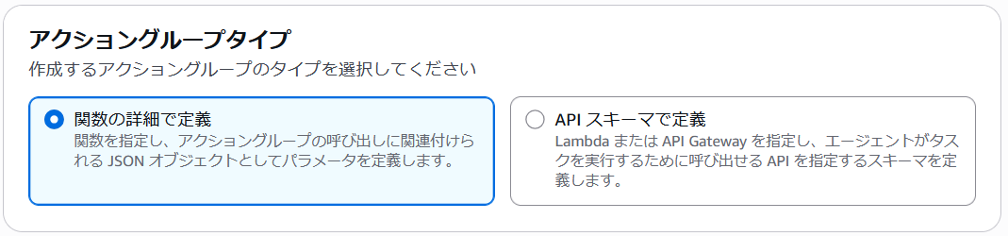
アクショングループタイプの選択
”アクショングループタイプ” には、”関数の詳細で定義” を選択
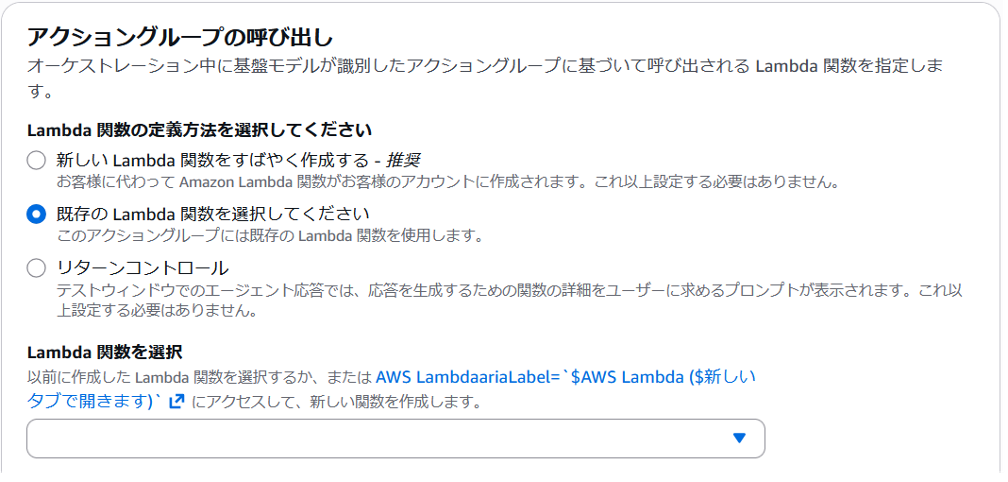
アクショングループの呼び出し
”アクショングループの呼び出し” には、既存の Lambda 関数を選択
Lambda 関数の定義
Lambda 関数において下記のように Python コードで定義するlist-assets、show-asset-details、sample-athena-query の 3 種類の関数を、それぞれエージェントのアクショングループ関数として定義しています。各関数の詳細コードは省略します。
def lambda_handler(event, context):
# Bedrockエージェント向けにイベントデータをパースする
action_group = event.get('actionGroup', '')
function = event.get('function', '')
parameters = event.get('parameters', [])
# 適切な関数へのルーティング
## アクショングループ関数1
if function == 'list-assets':
result = list_assets()
## アクショングループ関数2
### asset_identifier, domain_identifierはデータゾーンのAPI呼出しに必要な引数
elif function == 'show-asset-details':
param_dict = {param['name']: param['value'] for param in parameters}
asset_identifier = param_dict.get('asset_identifier')
domain_identifier = param_dict.get('domain_identifier')
result = show_asset_details (asset_identifier, domain_identifier)
## アクショングループ関数3
### glue_database, glue_tableはAthenaのクエリで必要なテーブル名とデータベース名
elif function == 'sample-athena-query':
param_dict = {param['name']: param['value'] for param in parameters}
glue_database = param_dict.get('glue_database')
glue_table = param_dict.get('glue_table')
account_id = param_dict.get('account_id')
result = sample_athena_query (glue_database, glue_table, account_id)
else:
result = {"error" : f"Unknown function requested: {function}"}
return create_bedrock_response(action_group, function, result)
def create_bedrock_response(action_group, function, result):
"""
エージェントへのリスポンスとして正しくフォーマット化する
"""
response = {
"messageVersion": "1.0",
"response": {
"actionGroup": action_group,
"function": function,
"functionResponse": {
"responseBody": {
"TEXT": {
"body": json.dumps(result, indent=2, ensure_ascii=False)
}
}
}
}
}
return response3. アクショングループ関数の詳細とその使用例
下では、3 つのアクショングループ関数 (以下、関数) の設定内容、指示プロンプトでこだわった点、アプリケーション上の簡単な使用例について整理します。
- 各指示プロンプト設計における共通の指針
- 英語での指示文定義
翻訳のプロセスを省き、推論の精度と返答速度を向上するためです - Lambda 関数のコード上の引数名とエージェント指示文の引数名を完全一致させる
曖昧性を排除しエージェント上の引数の不一致リスクを削減します - 関数の目的とユースケース、引数に関する詳細を記述する
Lambda 関数の引数の定義とその効率的な検索方法も明確にします
- 英語での指示文定義
アクショングループ関数 1 : 管理対象テーブル名のリスト作成 (list-assets)
関数 1 の定義を JSON エディタ形式で示します。関数 1 では DataZone API を利用して、登録されている各ドメインのアセットを抽出し一覧化します。JSON 内の ”description” はエージェントへの本関数に関する指示文になりますが、後続の他の関数 (show-asset-details, sample-athena-query) での再利用を考慮し、例えば domain_identifier などの引数についても抽出・保持できるように設計しています。
{
"name": "list-assets",
"description":
"
Function Purpose: Retrieves all available tables from the AWS DataZone domain. Function returns structured asset, including parameters required for other group functions:\"show-asset\" and \"sample-athena-query\".
When Agent Should Use This Function:
• User asks to \"list tables\", \"show tables available\"
• As initial step before exploring specific table details
Function Behavior:
• Returns asset table list with 'domain_name','domain_identifier','asset_name','asset_identifier','glue_database','glue_table','account'
Agent Instructions:
• For list requests: Show detailed table names in list format from function output
• Excludes domains with no assets and invalid/error states
• Uses \"Table\" terminology in responses (function handles technical \"asset\" conversion)
• Provides clean, accessible results only
• 'domain_identifier','asset_identifier','glue_database','glue_table','account_id' are supposed to be used for internal use to call other functions but optionally return them depending on the request
",
"parameters": {},
"requireConfirmation": "DISABLED"
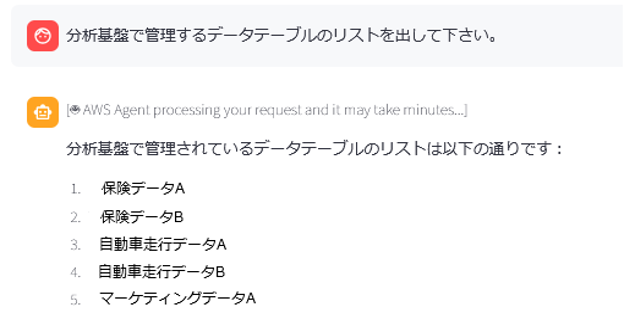
}WEB UI の例
こちらの例では仮データを使って、WEBUI 上の見え方を示しています。アカウント内の全ドメインに渡るデータテーブルがリストされます。
アクショングループ関数 2 : 対象アセットのメタデータ取得 (show-asset-details)
関数 2 の定義を JSON エディタ形式で示します。関数 2 は、ユーザーからのリクエストに基づいて DataZone API を利用し、指定されたアセットのメタデータを取得します。Lambda 関数としては、引数に DataZone のドメイン ID (domain_identifier) とアセットID (asset_identifier) を受け取ります。この Agent の指示文では、関数2に必要な引数がチャット履歴にない場合のみ、list-assets (関数 1) を自動的に実行して引数を補完するように指示しています。これにより処理の効率と速度の向上を実現しています。
{
"name": "show-asset-details",
"description":
"
Function Purpose: Retrieves detailed information for a specific asset table, including overview summary with columns definitions and schema, and metadata.
When to Use:
• User requests column details, table structure, or schema
• User asks for table overview or purpose
Required Parameters:
• domain_identifier: Domain ID where asset exists
• asset_identifier: Unique asset ID
Parameter Resolution:
• When user provides only table name: Always check conversation history, agent trace, and memory for identifiers from previous \"list-assets\" calls
• If identifiers not found: Use \"list-assets\" function to locate correct information
• If table name is ambiguous: Ask user to specify exact name
",
"parameters": {
"asset_identifier": {
"description": "asset_identifier",
"required": "True",
"type": "string"
},
"domain_identifier": {
"description": "domain_identifier",
"required": "True",
"type": "string"
}
},
"requireConfirmation": "DISABLED"
}WEB UI の例
WEB UI上ではこのような形で利用され、対象テーブルのカラムの正式名称や型の理解に役立ちます。

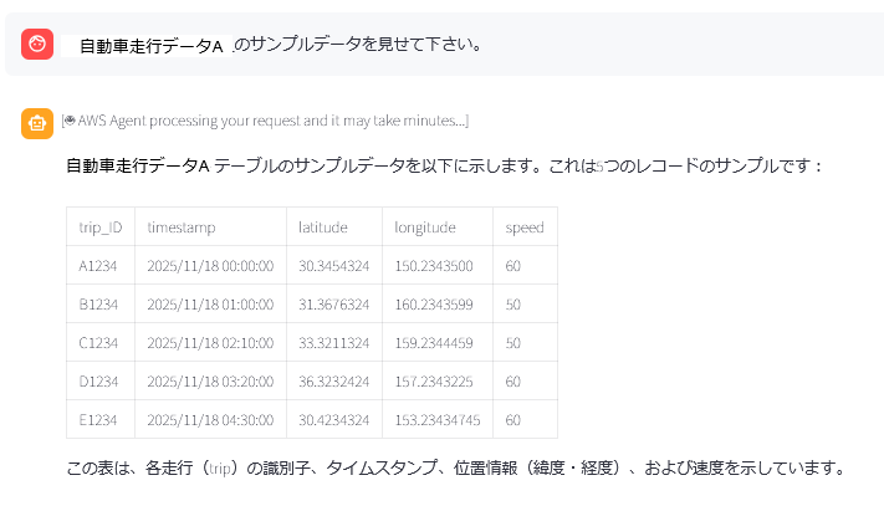
アクショングループ関数 3 : サンプルデータの抽出機能 (sample-athena-query)
関数 3 の定義を JSON エディタ形式で示します。この機能は、個人情報を含まないデータについて、Athena API を使用して指定されたテーブルからランダムに数件を抽出します。Lambda 関数への引数として、Glue のデータベース名 (glue_database)、テーブル名 (glue_table) とアカウント ID (account_id) を指定します。Agent の指示文では、show-asset-details (関数 2) の場合と同様に、必要な引数がチャット履歴に存在しない場合に list-assets (関数 1) を実行して引数を取得するロジックになっています。
{
"name": "sample-athena-query",
"description":
"
Function Purpose: Retrieves sample data from a specified table, returning the first 5 rows with all columns and actual data values to help users preview table contents.
When to Use: User requests \"show sample data from [table_name]\"
Required Parameters:
glue_database: Database name containing the table
glue_table: Table name (not asset name)
account_id: AWS account identifier
Parameter Resolution Steps:
When user provides only table/asset name:
First check conversation history or trace for glue_database, glue_table, and account_id
If not found: Use \"list-assets\" function to locate correct parameters
If table name is ambiguous: Ask user to specify exact table
Always confirm correct table before proceeding
Display actual data in table format (don't summarize unless requested)
Note: If the target table contains PII data, the function will not return sample data. In this case, inform the user that sample data is unavailable due to PII restrictions.
",
"parameters": {
"glue_table": {
"description": "table name defined in glue",
"required": "False",
"type": "string"
},
"glue_database": {
"description": "database name defined in glue catalog",
"required": "False",
"type": "string"
},
" account_id ": {
"description": "account ID where the table and db belong to",
"required": "False",
"type": "string"
}
},
"requireConfirmation": "DISABLED"
} WEB UI の例
WEB UI 上ではこのように、サンプルデータが閲覧可能です。(表示はダミーデータです)
セキュリティ対策
本アプリケーションでは、以下のような多層的なセキュリティ対策を実施しています。
- ユーザーは Amazon WorkSpaces 上のブラウザからのみアクセス可能とし、データの持ち出し・持ち込みを制限
- Web サーバーからの外部接続は AWS PrivateLink を徹底し、AWS ネットワーク外の通信を排除
- Amazon Bedrock では日本リージョンのみで利用可能な Claude 4.5 Sonnet を使用し、国外データ移転リスクに配慮
- エージェントは Claude 3.5 Sonnet (現在東京リージョンのみで利用可能な最新エージェントモデル) を使用し、Action Group の Lambda 関数には最小権限の IAM ロールを付与
- 個人情報が含まれるデータについては Athena からのサンプル抽出を制限し、安全なデータのみプロンプトに含まれるように設計
- Athena のサンプルデータはランダム抽出とし、個人の再識別を防止
- モデルへのリクエストやエージェントの操作ログは Amazon DynamoDB に保存し、監査ログを一元管理
- AWS CloudTrail と連携し、追跡性を確保
まとめ
本取り組みを通じて、AWS DataZone はメタデータを体系的に整理し、組織内の知見として蓄積する用途に適しており、テキスト情報を扱う生成AIとの親和性が高いことを学びました。これらの特性を踏まえ、DataZone に保存されたアセット情報へ AI エージェントが直接アクセスできる仕組みを導入したことで、データの発見・理解に必要なプロセスを一つの対話インターフェースに統合することが可能になりました。
その結果、データの所在や内容を一元的に把握できるようになり、「どのようなデータがどこにあるのか」を即座に確認できる環境が実現しました。これは本取り組みにおける特筆すべき成果の一つです。
業務効率化の観点では、データサイエンティストが所属するグループの 11 名のアプリアクティブユーザーを対象にヒアリングを行った結果、AI チャットアプリ全体で月間約 473 時間 (1 人あたり約 43 時間) の業務効率化効果が確認されました。
また、データの種類や構造を理解しやすくなったことで、新入社員や中途社員の学習支援にも活用されており、組織全体としてのデータ民主化の推進にも寄与しています。
今後は、新サービスである Amazon Bedrock AgentCore への移行を行い、他の AWS サービスとの連携を拡充してより高機能な AI チャットツールの開発を目指していきます。
筆者プロフィール
日野原 弘幸
あいおいニッセイ同和損害保険株式会社
デジタルビジネスデザイン部 データソリューショングループ 上席スペシャリスト
あいおいニッセイ同和損保に入社後シンガポール現地法人 AIS Asia に出向し、AWS を活用した、自動車走行データを用いた安全性評価システムの開発等を担当。
現在所属するグループでは、DX 事業化 PJ の推進の文脈で AWS 分析基盤の改善や生成 AI 活用の取り組みを推進している。自ら手を動かしながら課題解決に取り組むことを大切にしている。
