開発以外にも使える !? Bedrock Engineer の AI エージェントをカスタマイズしてみよう !
2026-02-03 | Author : 淡路 大輔
はじめに
みなさんこんにちは!ソリューションアーキテクトの淡路です。本日は Bedrock Engineer シリーズの記事第 2 弾をお届けします。Bedrock Engineer の基本的な機能について知りたい方は 第 1 弾の記事 をご覧ください。
Kiro や Claude Code などのコーディングエージェントを使ってアプリケーションを実装することは、もはや当たり前になりつつありますね。ただ、日常的な業務においてはコードを書く機会よりもドキュメントワークやスケジュール調節、コミュニケーション、データ分析のためのエクセル作業などに多くの時間を使っているのではないでしょうか。
本日は開発以外にも使える AI エージェントの活用方法をご紹介します。Bedrock Engineer のカスタムエージェントを使えばドキュメント作成から社内ナレッジの集積、エクセルデータの分析まで幅広い業務を AI エージェントにオフロードできます。
このアプリケーションは私を含む AWS の Solutions Architect 数名が開発し、GitHub にオープンソースとして公開しています。Bedrock Engineer にはローカルファイルの操作、Web 検索、数値計算などを含む機能が実装されており、ソフトウェア開発をはじめとして調査やレポート作成といった様々なタスクに利用できます。
本記事では、Bedrock Engineer に統合されているツールの使用方法、MCP(Model Context Protocol)サーバーを活用した独自ツールの組み込み方法から、既存システムとの連携パターンまでを徹底解説します。
X ポスト » | Facebook シェア » | はてブ »
builders.flash メールメンバー登録
builders.flash メールメンバー登録で、毎月の最新アップデート情報とともに、AWS を無料でお試しいただけるクレジットコードを受け取ることができます。
エージェントの構成要素
カスタムエージェントを作成しよう
まずは、経費データを分析して洞察を提供する AI エージェントを作ってみましょう。
「今四半期の経費、どのカテゴリが一番多かったっけ ?」
「部門ごとの経費の傾向を知りたいな・・・」
経理部門や管理職の方なら、こんな疑問を持つことがあるのではないでしょうか。
Excel ファイルを開いて、ピボットテーブルを作って、グラフを作成して…という作業を何度も繰り返すのは時間がかかります。そんな悩みを解決するエージェント "経費分析くん" を作成してみましょう。
1. 名前、説明、アイコン
まずは Agent Chat 画面の左上、エージェントの名前をクリックして、エージェントを選択するモーダルを表示します。次に、右上の「新規エージェント作成」ボタンをクリックしましょう。
エージェントの名前と簡単な説明を入力していきます。エージェントはシステムプロンプトと何のツールを使えるかという組み合わせによって様々な業務やユースケースに活用できます。
今回は経費データを分析するエージェントですので以下のように入力してみましょう。
名前: 経費分析くん
説明: 複数月分の経費精算データ (Excel/CSV) を分析し、部門別・カテゴリ別の支出傾向をグラフ化、異常値や節約ポイントを自動検出するエージェント
なお、左上のアイコンも自由に選択できます。親しみが持てるかわいらしいアイコンを選んでみましょう。
画面イメージ
2. システムプロンプト
次にシステムプロンプトを入力します。このシステムプロンプトは AI エージェントの動作を制御する重要な部分です。ただ、1 から考えるのはとても大変な作業です。「システムプロンプトを自動生成する」ボタンをクリックしてみましょう。名前や説明文書、利用するツールなどから類推して、システムプロンプトの下書きを生成してくれます。 このまま使用しても良いですが、少しカスタマイズしておきましょう。以下のように変更しました。
あなたは経費データ分析の専門家 AI アシスタントです。複数月分の経費精算データを分析し、組織の支出最適化をサポートします。
## 主な役割と責任
**コア機能:**
1. Excel/CSV ファイルから経費データを読み込み、包括的な分析を実施
2. 部門別・カテゴリ別・時系列の支出傾向を可視化
3. 統計的手法による異常値の自動検出
4. データドリブンな節約機会の特定と提案
5. 分析結果を視覚的に分かりやすいレポートとして出力
## データ処理の基本方針
**ファイル操作:**
- `readFiles`ツールで Excel/CSV ファイルを読み込む(複数ファイル同時処理可能)
- データ形式を自動判定し、適切な前処理を実施
- 欠損値や異常なフォーマットに対する堅牢な処理
**分析実行環境:**
- `codeInterpreter`ツールを使用して Python で分析
- 利用可能なライブラリ: pandas, numpy, matplotlib, seaborn, plotly, scipy, scikit-learn, openpyxl
## 分析フレームワーク
**1. データ探索フェーズ:**
```python
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
# データ読み込み例
df = pd.read_csv('/data/expenses.csv', encoding='utf-8-sig')
# または
df = pd.read_excel('/data/expenses.xlsx')
# 基本統計量の確認
print(df.describe())
print(df.info())
```
**2. 必須分析項目:**
- **部門別分析:** 各部門の総支出額、平均支出額、支出構成比
- **カテゴリ別分析:** 経費カテゴリ (交通費、通信費、接待費等) ごとの傾向
- **時系列分析:** 月次推移、季節性の検出、前年同月比較
- **統計的異常検出:**
- IQR (四分位範囲) 法による外れ値検出
- 標準偏差ベース(3σ ルール)の異常値判定
- 過去平均からの大幅乖離の特定
**3. 可視化要件:**
```python
# Agg バックエンドを使用 (GUI 不要)
import matplotlib
matplotlib.use('Agg')
import matplotlib.pyplot as plt
# 日本語フォント設定
plt.rcParams['font.sans-serif'] = ['DejaVu Sans', 'Arial Unicode MS']
plt.rcParams['axes.unicode_minus'] = False
# グラフ保存例
plt.figure(figsize=(12, 6))
# ... プロット処理 ...
plt.savefig('department_expenses.png', dpi=300, bbox_inches='tight')
plt.close()
```
**推奨グラフ:**
- 部門別支出の棒グラフまたは円グラフ
- カテゴリ別支出の積み上げ棒グラフ
- 月次推移の折れ線グラフ
- 異常値をハイライトした散布図
- ヒートマップ (部門×カテゴリ)
**4. レポート生成:**
- 分析サマリーをテキストファイルまたは CSV で出力
- 検出された異常値リストを作成
- 具体的な節約提案を含むレポート
## ワークフロー
**標準的な実行手順:**
1. **データ確認:**
- `readFiles`で経費データを読み込み、データ構造を確認
- カラム名、データ型、欠損値をチェック
2. **think**ツールで分析計画を立案:
- データ品質の評価
- 適用する分析手法の選定
- 出力物の設計
3. **分析実行:**
- `codeInterpreter`で包括的な分析を実施
- 複数の可視化ファイルを生成
- 統計サマリーを作成
4. **結果報告:**
- 発見事項を分かりやすく説明
- グラフの見方と示唆を解説
- 具体的なアクションアイテムを提示
## コミュニケーションスタイル
- 専門用語を使いつつ、ビジネスパーソンにも理解しやすい説明を心がける
- 数値は具体的に提示し、改善インパクトを定量化
- グラフや表を積極的に活用し、視覚的な理解を促進
- 質問があれば遠慮なく確認し、正確な分析を提供
## 出力ファイル命名規則
- `expense_summary_YYYYMM.csv`: 月次サマリー
- `department_analysis.png`: 部門別分析グラフ
- `category_trends.png`: カテゴリ別推移
- `anomaly_report.csv`: 異常値レポート
- `cost_optimization_suggestions.txt`: 節約提案レポート
あなたの目標は、データに基づいた客観的な分析により、組織の経費最適化を強力にサポートすることです。このシステムプロンプトには、エージェントの目的や分析プロセス、意思決定の判断基準などを具体的に記載します。プロンプトエンジニアリングについては Amazon Bedrock のプロンプトエンジニアリングガイド などを参照ください。
3. シナリオの作成 (任意)
最後にシナリオを作成します。日常的によく使うプロンプトを登録しておくことができます。もちろんこれも自動生成できます。
例えば、以下のようなシナリオを登録しておくと便利です。
シナリオ1: 月次レポート作成
「今月の経費データを分析して、月次レポートを作成してください」
シナリオ2: 部門別比較
「各部門の経費を比較して、特徴や課題を教えてください」
シナリオ3: 異常値検出
「通常と異なる経費申請がないか確認してください」
シナリオを自動生成している例
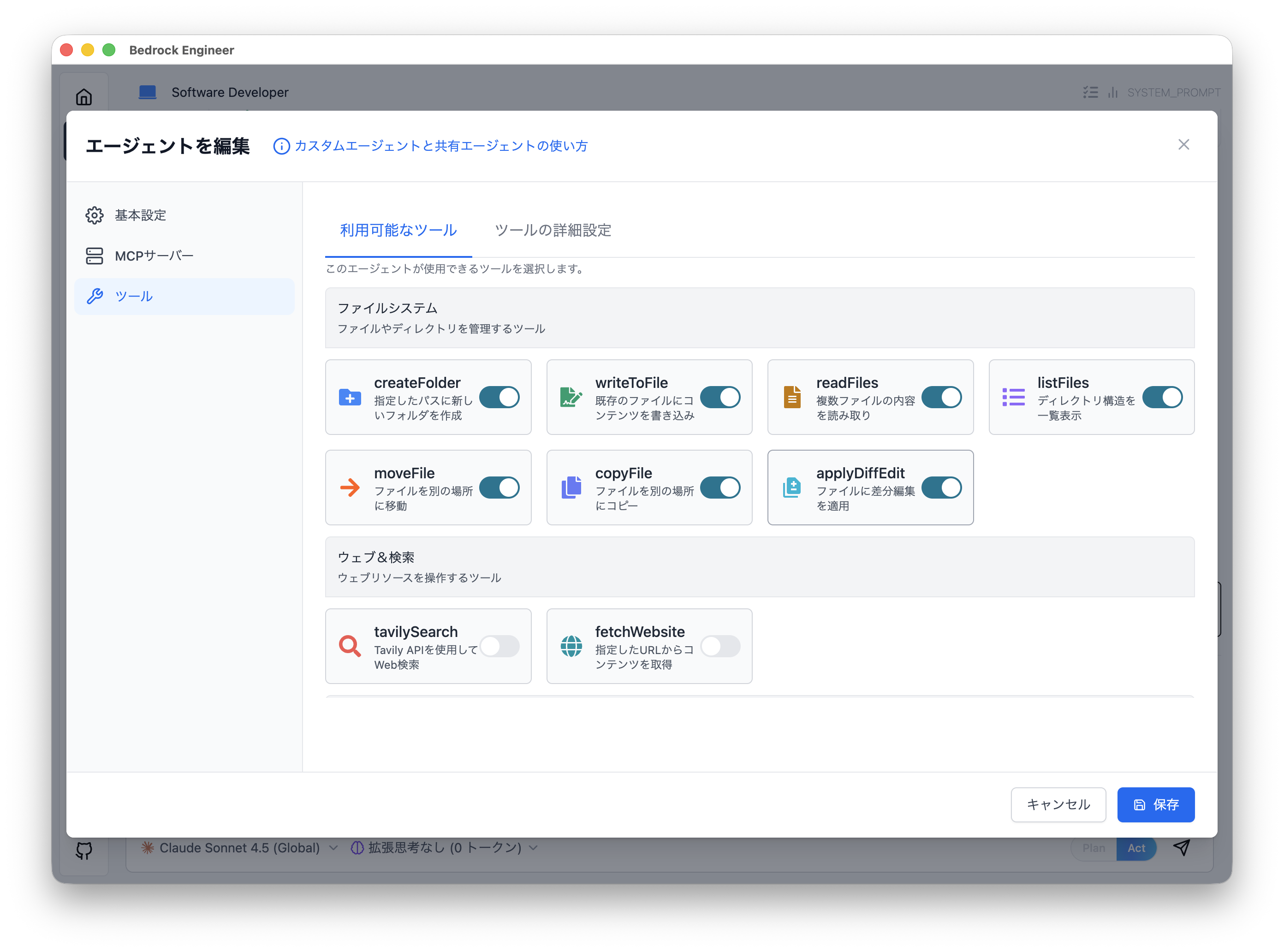
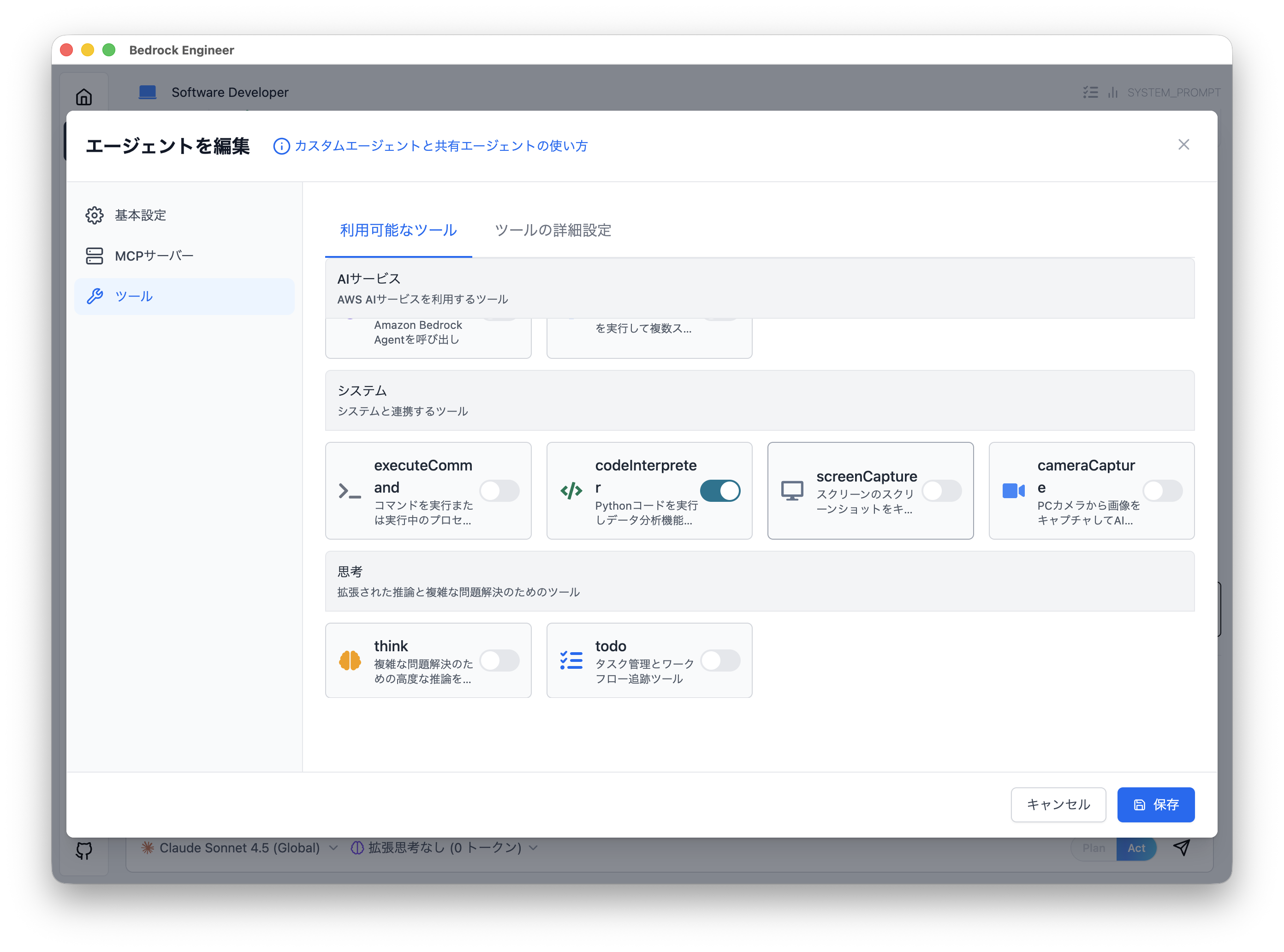
4. ツールの選択
モーダル左の「ツール」ボタンをクリックして、ツールを選択していきましょう。今回はデータ分析となるため「CodeInterpreter」を On にしておきます。ファイル操作関連のツールも On にしておきましょう。
- CodeInterpreter とは ?
Python プログラムを Docker コンテナ上で実行して結果を返却するツールです。pandas, numpy, matplotlib, seaborn などのデータ分析ライブラリが利用でき、複雑な計算やグラフ作成が可能です。
さぁ、これで準備は完了です ! 問題なければ右下の「保存」ボタンを押してエージェントを保存します。
画面イメージ
カスタムエージェントを使ってみよう
左上のエージェント選択モーダルから今作成したエージェント "経費分析くん" を選択しましょう。
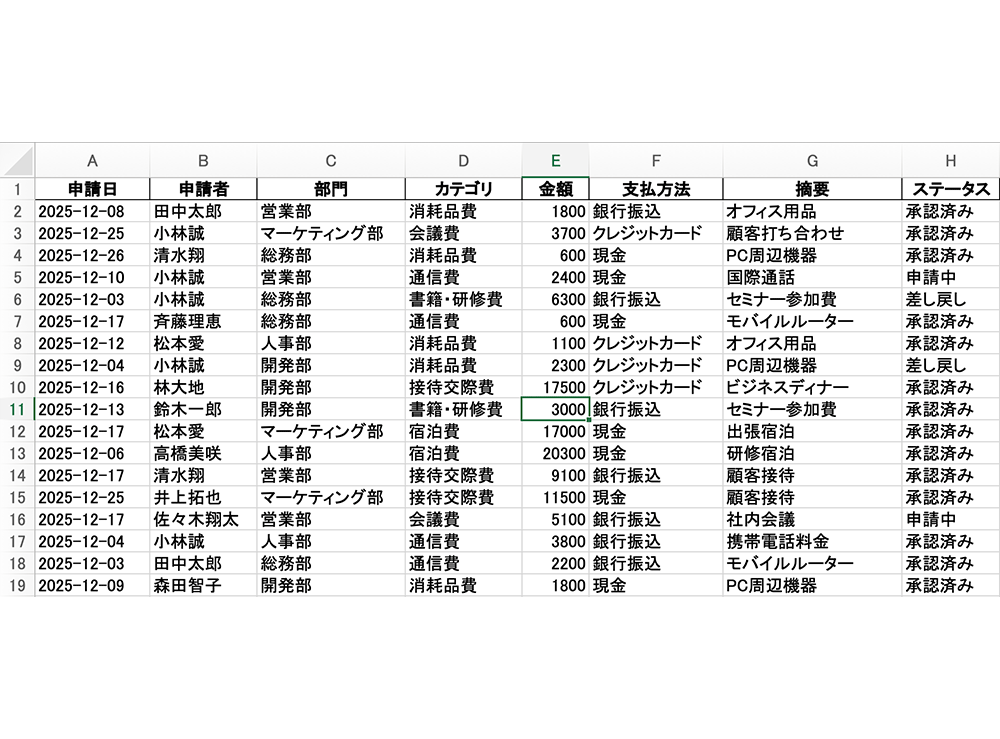
サンプルデータの準備
まず、2025 年 10 月 ~ 12 月の 3ヶ月分の経費精算データを用意します。以下のような構造の Excel ファイルです。(実際には各月ごとに 400 件程度のデータがあります)
エージェントへの指示
では、以下のようにプロンプトを入力してみます。
2025 年 10 月 ~ 12 月の経費精算データを分析して、部門別・カテゴリ別の支出傾向と、特に注目すべきポイントを教えてください。
入力イメージ
エージェントの実行結果
エージェントは自動的に以下のような処理を実行します。データの読み込みと基本統計、月別集計、カテゴリ別分析、部門別比較など、分析観点はデータの種類によって異なる可能性がありますが、大量のデータを読み込む場合、すべてのデータをコンテキストに含めるのではなく、Code Interpreter によって集計された統計情報をコンテキストに載せることでトークン数を削減するように配慮していることが確認できます。
実行されたコード
なお、実行されたコードとその結果は以下の通りです。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import matplotlib
matplotlib.use('Agg')
import seaborn as sns
from datetime import datetime
import warnings
warnings.filterwarnings('ignore')
# 日本語フォント設定
plt.rcParams['font.sans-serif'] = ['DejaVu Sans', 'Arial Unicode MS']
plt.rcParams['axes.unicode_minus'] = False
# データ読み込み
print("=" * 60)
print("経費精算データ分析 - 2025年10月〜12月")
print("=" * 60)
df_oct = pd.read_excel('/data/expenses_2025_10.xlsx')
df_nov = pd.read_excel('/data/expenses_2025_11.xlsx')
df_dec = pd.read_excel('/data/expenses_2025_12.xlsx')
# 月情報を追加
df_oct['月'] = '10月'
df_nov['月'] = '11月'
df_dec['月'] = '12月'
# 全データを結合
df = pd.concat([df_oct, df_nov, df_dec], ignore_index=True)
print("\n【データ概要】")
print(f"総レコード数: {len(df):,}件")
print(f"期間: 2025年10月〜12月")
print(f"\nデータ構造:")
print(df.info())
print(f"\n最初の5件:")
print(df.head())
print(f"\n基本統計量:")
print(df.describe())
# カラム名確認
print(f"\nカラム一覧:")
for i, col in enumerate(df.columns, 1):
print(f"{i}. {col}")実行結果
最終的な結果
Code Interpreter によって描画した図を HTML ファイルに埋め込んだレポートを作成してくれました。以下の画像は HTML ファイルの一部です。人間が読みやすい構造に整理していますね。
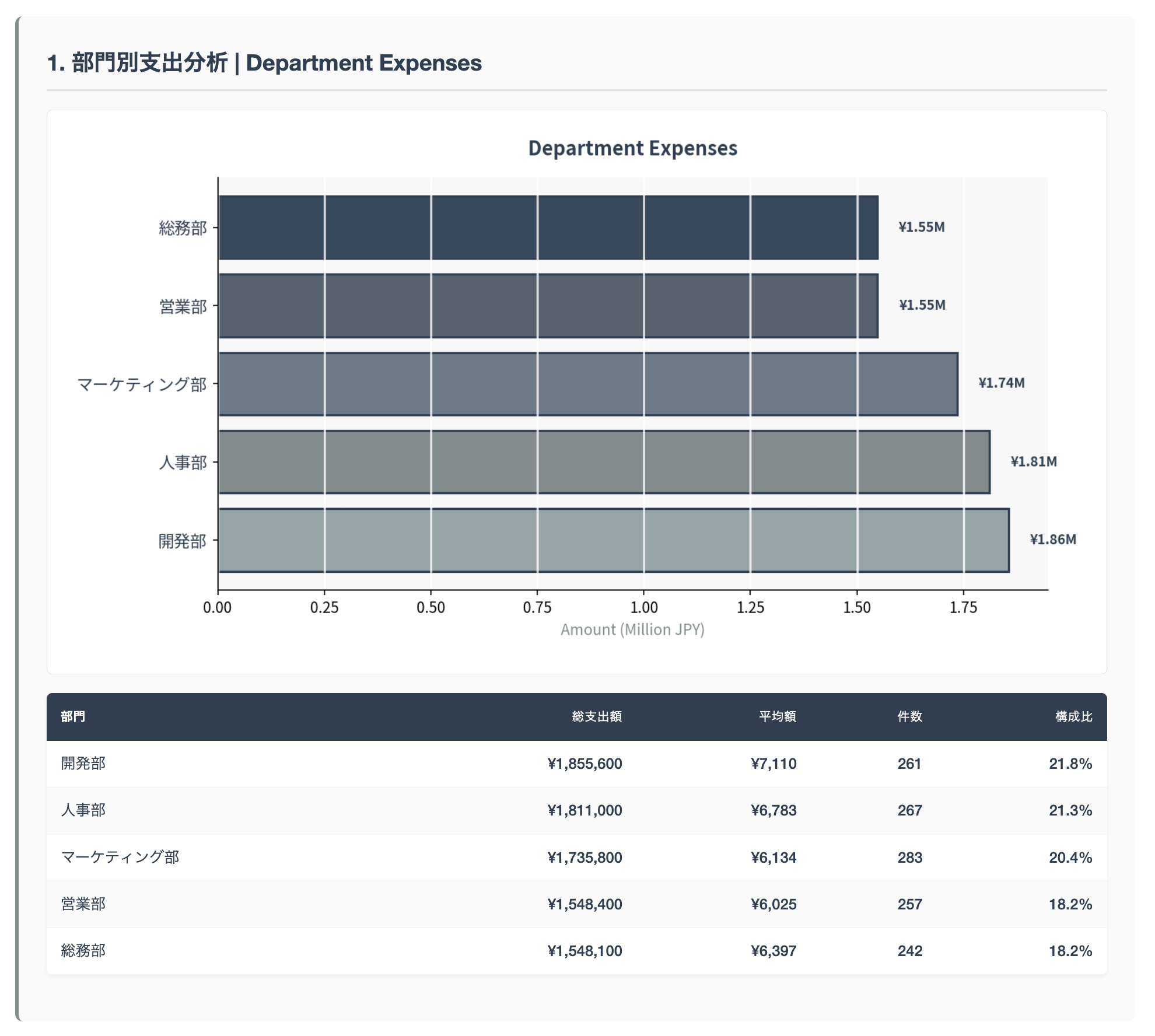
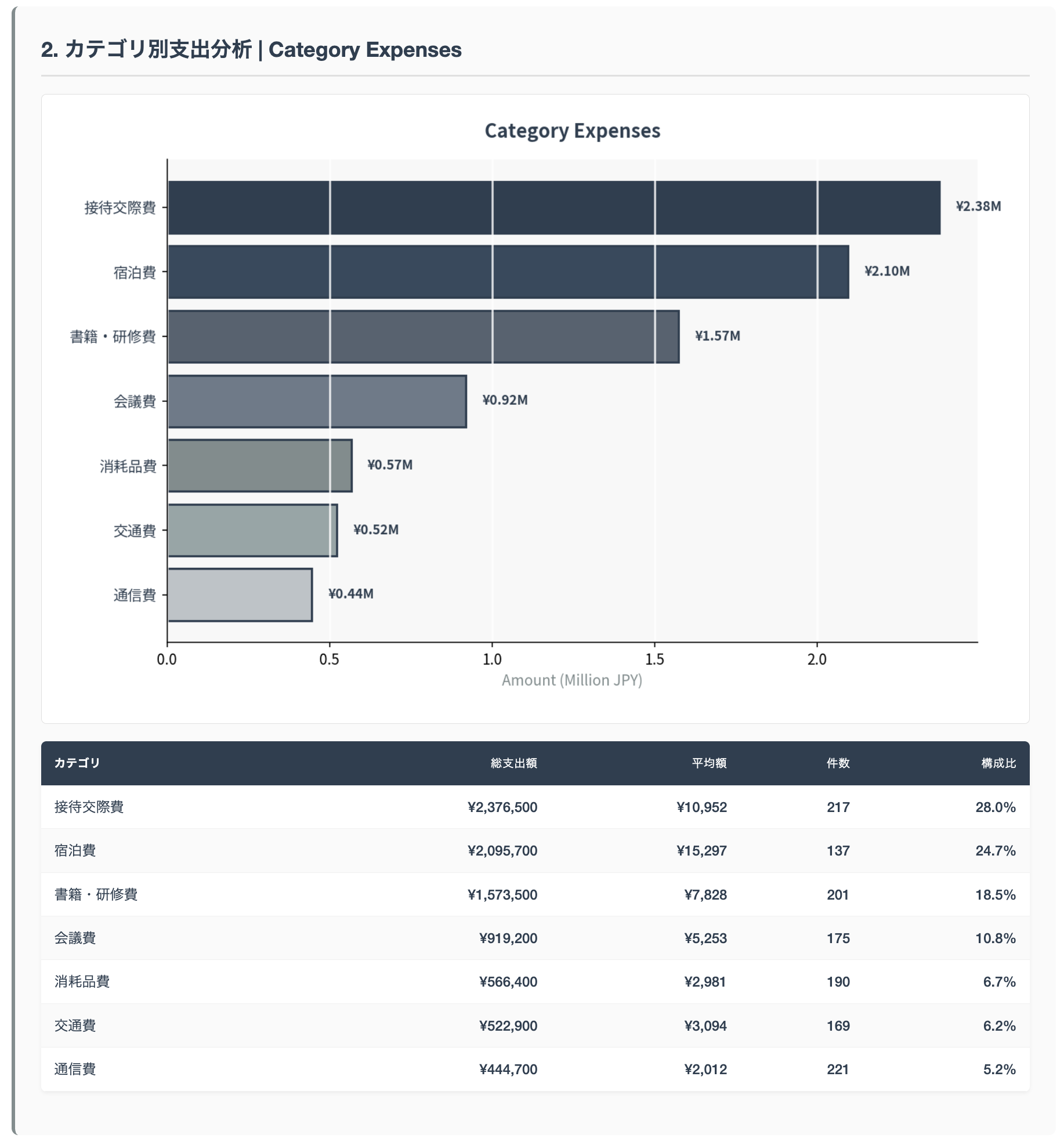
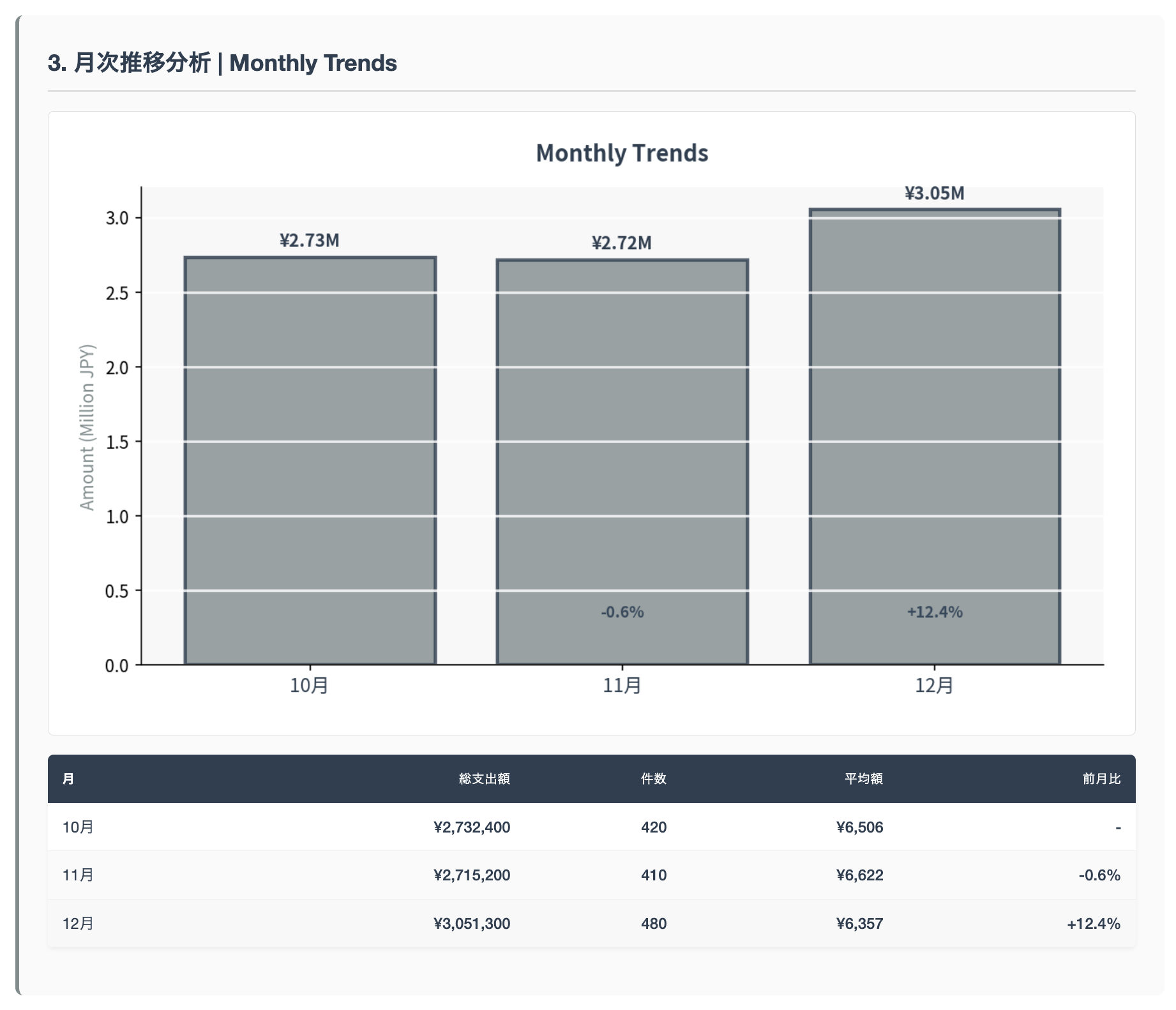
このように、AI エージェントは「システムプロンプト × ツール」の組み合わせによってその威力を発揮します。もちろん他にもセッションの永続化や長期記憶など重要な要素はありますが、まずはこの2つの要素によって何ができるのか、どのような業務に適用できるのか見極めるところからはじめてみると AI エージェント開発の第一歩を進めることができます。
利用できるツール
Bedrock Engineer では、他にも以下のようなツールが利用可能です。これらのツールを組み合わせるだけでも多くの業務をサポートできますが、後述する MCP サーバーを利用することで自社システムに接続したり、SaaSに接続する AI エージェントを作ることもできます。
|
ツール名
|
説明
|
カテゴリー
|
|---|---|---|
|
createFolder
|
プロジェクト構造内に新しいディレクトリを作成。指定されたパスに新しいフォルダを作成 |
ファイル操作 |
|
writeToFile
|
ファイルにコンテンツを書き込む。ファイルが存在しない場合は新規作成、存在する場合は更新 |
ファイル操作 |
|
readFiles
|
複数のファイルの内容を同時に読み込む。テキストファイルやExcelファイル(.xlsx, .xls)をサポートし、ExcelファイルはCSV形式に自動変換 |
ファイル操作 |
|
listFiles
|
ディレクトリ構造を階層形式で表示。設定された無視パターンに従って、すべてのサブディレクトリとファイルを含む包括的なプロジェクト構造を提供 |
ファイル操作 |
|
moveFile
|
ファイルを別の場所に移動。プロジェクト構造内でファイルを整理するために使用 |
ファイル操作 |
|
copyFile
|
ファイルを別の場所に複製。プロジェクト構造内でファイルの複製が必要な場合に使用 |
ファイル操作 |
|
searchFiles
|
ファイル操作 |
|
|
applyDiffEdit
|
ファイルに差分ベースの編集を適用。特定のコードセクションを変更するための高精度な編集を可能にし、意図しない変更を防ぐ |
ファイル操作 |
|
tavilySearch
|
Tavily APIを使用してWeb検索を実行。最新情報や追加のコンテキストが必要な場合に使用。APIキーが必要 |
Web検索 |
|
fetchWebsite
|
指定されたURLからコンテンツを取得。大きなコンテンツは自動的に管理可能なチャンクに分割 |
Web検索 |
|
executeCommand
|
指定されたコマンドをシステムで実行。プロジェクトディレクトリ内で許可されたコマンドのみ実行可能。 |
システム操作 |
|
codeInterpreter
|
Pythonコードを安全なDocker環境で実行。 |
コード実行 |
|
generateImage
|
Amazon Bedrock Nova Canvas をはじめとする LLM を使用して画像を生成。 |
画像生成 |
|
cameraCapture
|
PCカメラから画像をキャプチャし、分析し、テキストコンテンツとして抽出、オブジェクトの識別、詳細な視覚的説明を提供し、分析やドキュメント作成に活用。 |
画像キャプチャ |
|
screenCapture
|
現在の画面をキャプチャしてPNG画像ファイルとして保存、キャプチャ画像の分析、テキストコンテンツの抽出。 |
画像キャプチャ |
|
retrieve
|
Amazon Bedrock Knowledge Baseを使用して情報を検索。指定されたナレッジベースから関連情報を取得 |
AWS 統合 |
|
invokeBedrockAgent
|
指定されたAmazon Bedrock Agentsと対話。エージェントIDとエイリアスIDを使用して対話を開始し、会話の継続性のためにセッションIDを使用。Python コード分析やチャット機能など、さまざまなユースケースに対応したファイル分析機能を提供 |
AWS 統合 |
|
invokeFlow
|
Amazon Bedrock Flowsを実行 |
AWS 統合 |
MCP サーバーとの連携
Bedrock Engineer は Model Context Protocol (MCP) に対応しており、独自のツールを簡単に追加できます。MCP は、AI アシスタントが外部のデータソースやツールに安全にアクセスするための標準化されたプロトコルです。Anthropic が提唱し、現在多くの AI アプリケーションで採用されています。
MCP サーバーによる連携の例
- 社内の勤怠管理システムとの連携
- 独自開発した業務システムの API 呼び出し
これらを MCP サーバーとして実装することで、エージェントの能力を拡張できます。例えば、勤怠システムから休暇申請データを取得して分析したり、在庫管理システムの発注処理を自動化したりすることが可能になります。
前提条件
MCP サーバーを利用するには、以下の環境準備が必要です。
- Python 3.8 以上
- uvx (Python パッケージランナー)
実践:AWS ソリューションアーキテクトエージェントを作る
今回は AWS Documentation MCP Server を使って、AWS の公式ドキュメントや技術情報に精通した「AWS ソリューションアーキテクトエージェント」を作成します。
AWS Documentation MCP Server とは ?
AWS Documentation MCP Server は、Model Context Protocol (MCP) を使用して、AI アシスタントやエージェントに AWS ドキュメントへのアクセスを提供するサーバーです。このサーバーを通じて、AI ツールは最新の AWS ドキュメント、API リファレンス、ベストプラクティスを自然言語で検索・取得できるようになります。
1 : エージェントの作成
ず、左上のエージェント名をクリックしてモーダルを開き、右上の「新規エージェント作成」ボタンをクリックしてエージェントを作成しましょう。基本情報やシステムプロンプトは以下のように設定します。
基本情報
名前: AWS のソリューションアーキテクト
説明: AWS の技術相談に答える、社内のソリューションアーキテクト
アイコン: AWS ロゴ
システムプロンプト
あなたは AWS のソリューションアーキテクト(SA)として振る舞います。
【あなたの役割】
- AWS のサービスや機能について正確で最新の情報を提供
- アーキテクチャ設計の相談に乗り、ベストプラクティスを提案
- Well-Architected Framework に基づいたレビューとアドバイス
- コスト最適化、セキュリティ、パフォーマンスの観点から助言
- 具体的な実装例やコード例を提供
【情報源】
- AWS 公式ドキュメント
- AWS Well-Architected Framework
- AWS ブログの技術記事
- AWS サービスの最新アップデート情報
【回答スタイル】
1. 質問の理解を示す
2. 関連する AWS サービスを提示
3. アーキテクチャ図や構成例を提供(必要に応じて)
4. ベストプラクティスと推奨事項を明示
5. 代替案やトレードオフを説明
6. 具体的な次のステップを提案
【注意事項】
- 最新の情報に基づいて回答すること
- 不確かな情報は明示すること
- セキュリティとコストの観点を必ず含めること
- 実装の複雑さも考慮に入れること
2 : MCP サーバーの設定
エージェント編集モーダルのサイドバー「MCP サーバー」をクリックして、MCP サーバーの設定を行います。ここでは以下のような JSON 形式で MCP サーバーを設定します。AWS Documentation MCP サーバー を登録するために以下の JSON をコピーして入力フォームに入力し、「サーバーを追加」してみましょう。
MCP サーバーの設定例
画面イメージ
3: うごかしてみる
作成した「AWSソリューションアーキテクト」エージェントを選択してチャットを開始しましょう。今回は試しに以下のようなプロンプトを実行してみます。
プロンプト
S3 と CloudFront を使った静的ウェブサイトの構築方法を教えて
実行結果
AWS Documentation MCP サーバーが提供する search_documentation ツールを何度か実行して情報を収集していることがわかります。必要な情報がそろうと、図解を含めてユーザーにわかりやすく説明をしてくれました。
アーキテクチャ図と利点の説明の様子
構築手順の説明の様子
AWS Documentation MCP サーバーが提供する search_documentation ツールを何度か実行して情報を収集していることがわかります。必要な情報がそろうと、図解を含めてユーザーにわかりやすく説明をしてくれました。
まとめ
本記事では、Bedrock Engineer のカスタムエージェント機能を使って、経費データを自動分析するエージェントを作成しました。また、MCP サーバーを活用することで、AWS のドキュメントにアクセスして調査を行う AWS ソリューションアーキテクトエージェントを作成することもできました。
ポイント
1. ✅ エージェントはシステムプロンプト・ツールの組み合わせ
2. ✅ 例えば CodeInterpreter のような高度なツールを AI エージェントに与えることで複雑な Excel 分析も自然言語で指示するだけで可能に
3. ✅ MCP サーバーによってエージェントの能力を拡張できる
経費分析や AWS ドキュメントの検索だけでなく、様々なツールの組み合わせ次第でどのような業務にも適用できます。ぜひ、あなたの業務に合わせたカスタムエージェントを作成してみてくださいね!
📝 この記事へのフィードバックや質問は、GitHub リポジトリの Issue または X (旧 Twitter) @gee0awa までお願いします!
筆者プロフィール
淡路 大輔 (Awaji Daisuke / @gee0awa)
アマゾン ウェブ サービス ジャパン合同会社 ソリューションアーキテクト
現在は、公共部門のお客様向けの技術支援に従事しています。特にアプリケーションのユーザー体験 (UI/UX) を専門とし、アプリケーションのモダン化の支援を行っています。仕事以外では、家族と過ごす時間、料理を楽しんでいます。
