(Physical AI を) やらないか〜デバイス作成 & LLM 動作編
2026-04-02 | Author : 呉 和仁
はじめに
この記事があなたの手に落ちる頃には、私はもういないでしょう。とくに去っているでしょう
どうも、夏目漱石のこゝろかぶれの呉です。この記事が出ることろにはすでに私は AWS を去っていることかと思います。
AI で読書感想文を書いたり、献立のパーソナライズを行ったり、AWS のサービスの表記警察を行ったり、お菓子の分別装置を作ったり、マインクラフトの MCP サーバーを作ったり、色々書いてきました。
今までご愛読ありがとうございました。
前置きはさておき、私は子供が 3 人おり、洗濯機を回すと大量の靴下が発生することで有名です。靴下のペアを見つけるのが大変苦痛です。靴下のペアを AI が勝手に見つけて、なんなら畳んでくれたら嬉しいですね。まずはその前段として、ロボットに頑張って靴下を掴ませようとして失敗した奮闘記です。先に結果から申し上げると惜しいところまでいきましたが失敗しました。
ご注意
本記事で紹介する AWS サービスを起動する際には、料金がかかります。builders.flash メールメンバー特典の、クラウドレシピ向けクレジットコードプレゼントの入手をお勧めします。
builders.flash メールメンバー登録
builders.flash メールメンバー登録で、毎月の最新アップデート情報とともに、AWS を無料でお試しいただけるクレジットコードを受け取ることができます。
Physical AI やってますか?
昨今 Physical AI という言葉をよく聞くようになりました。簡単に言うと AI を物理世界に適用するということですが、Physical AI は様々な人が様々な文脈で語るので混乱しがちです。AWS の定義 では、
(原文)
At AWS, we define Physical AI as a system of hardware and software that integrates perceiving, understanding, reasoning, and learning to interact with the physical world. Physical AI is a subset of artificial intelligence that focuses on understanding spatiotemporal relationships and the physical nature of the world and then interacts with their surroundings through sensors and actuators. It processes multimodal inputs including images, videos, text, speech, depth/lidar, and real-world sensor data, to derive insights and enable real-time decision-making in autonomous systems capable of operating independently in complex, dynamic environments. For example, an AI model can use reasoning to describe how to pour a cup of coffee, whereas a Physical AI model first reasons where the coffee is located and that it needs to be poured in the cup, and then extends additional capabilities into the physical world to identify, grasp, lift, and pour a cup of coffee in real world conditions.
(日本語訳)
AWS では、Physical AI を、物理世界と相互作用するために知覚、理解、推論、学習を統合するハードウェアとソフトウェアのシステムとして定義しています。Physical AI は、時空間的関係と世界の物理的性質を理解し、センサーとアクチュエーターを通じて周囲と相互作用することに焦点を当てた人工知能のサブセットです。画像、ビデオ、テキスト、音声、深度/LiDAR 、実世界のセンサーデータを含むマルチモーダル入力を処理し、洞察を導き出し、複雑で動的な環境で独立して動作できる自律システムにおけるリアルタイムの意思決定を可能にします。例えば、AI モデルは推論を使用してコーヒーを注ぐ方法を説明できますが、Physical AI モデルは最初にコーヒーがどこにあり、カップに注ぐ必要があることを推論し、その後、実世界の条件下でコーヒーカップを識別、把持、持ち上げ、注ぐために物理世界への追加能力を拡張します。
とあり、環境情報を取り込んで物理世界を操作することと解釈することができます。もちろん LLM もコンピューターのメモリの各 bit の ON/OFF 等はできるので、そういう意味だと物理的になにかを動かしている、とも言えなくはなさそうですがそうではなく、現在の状況から何をすべきかを理解し、物理的な行動を起こすことが Physical AI と言えそうです。最近 Physical AI という言葉を聞かない日はありません。
世界的ですもんね。乗るしかない。このビッグウェーブに。
というわけで Physical AI の波にどう乗ればいいかわからない方のために、まず私が乗ってみましたというメモ書きです。
SO-101 の組み立て
Physical AI をやるにしてもなにか動かすものが必要です。いきなり物理デバイスを作るのは難易度が高いので、キットを用います。SO-101 というロボットアームをご存知でしょうか?SO-101 は、RobotStudio と Hugging Face が共同で開発したロボットアーム ですが、その実態はロボットアームそのものが売られているわけではなく、こうすればロボットアームができるよ、という説明 (BOM や組み立てガイド) があるだけですので、今回それに沿ってロボットアームを制作してみました。
いくつかの部品は購入して、いくつかの部品は 3D プリンターで印刷して、調達する必要があります。
購入部品は こちら を参照ください。日本だと秋月電子からサーボモーターやケーブル、ネジなどの一式を購入することができます。
購入したもの


注意事項
ただし、このキットにアームの肉体(?)部分は含まれないので、アームは 3D プリンターで印刷するか、秋月電子などで印刷済みのものを購入する必要があります。
逸般の誤家庭には 3D プリンターの 1 台や 2 台は家にあるかと思いますので、私は印刷しました。
パーツを一気に全て印刷することもできる (Follower Arm, Leader Arm) のですが、私が使っている Bambu Lab A1 mini という 3D プリンターだと、ベッド (印刷する場所) のサイズが小さくて一度に印刷できなかったので、以下のように3回に分けて印刷しました。
印刷の様子
1 回目だけ残っていた印刷完了の様子
こんな形で印刷できました。

3 回目
- Follower Arm の場合
Wrist_Roll_Follower_SO101.stl
Moving_Jaw_SO101.stl
- Leader Arm の場合
Wrist_Roll_SO101.stl
Trigger_SO101.stl
Handle_SO101.stl

組み立て完了 !

SO-101 を動かしてみる
このデバイスはキットに同梱されている USB ケーブルとドライバーを通じて操作することができます。操作はモータの制御と同義です。モーターはサーボモーターのため、回転位置制御 (モーターをどの位置に回転させるか、という操作) を行うことができます。
モーター制御に必要な情報を取得して、設定ファイルとして保存しました。
あらかじめ キャリブレーション しておき、フォロワーアームの各モーターがどの位置まで動かせるのかを、メモしたファイルです。最後の port キーは USB ドライバーの Mac 側で認識した ID を指しています。
.env.yaml ファイル
follower:
calibration:
elbow_flex:
homing_offset: 2026
id: 3
range_max: 3067
range_min: 838
gripper:
homing_offset: 1587
id: 6
range_max: 3324
range_min: 1773
shoulder_lift:
homing_offset: 1568
id: 2
range_max: 3183
range_min: 746
shoulder_pan:
homing_offset: 1978
id: 1
range_max: 3502
range_min: 897
wrist_flex:
homing_offset: -1348
id: 4
range_max: 3217
range_min: 813
wrist_roll:
homing_offset: 2035
id: 5
range_max: 4093
range_min: 26
port: /dev/tty.usbmodem5AB90678311Follower Arm を動かす
Follower Arm を動かすにあたって、Leader Arm と同じ動作をさせるコマンド (lerobot-teleoperate) がありますが、今回は動作理解も含めて、以下のようなコードを用意しました。
全て同じディレクトリに保存し uv run simple_controller.py で実行します。
すると、このような GUI が表示され、スライダーを動かすことで各モーターを操作することができます。
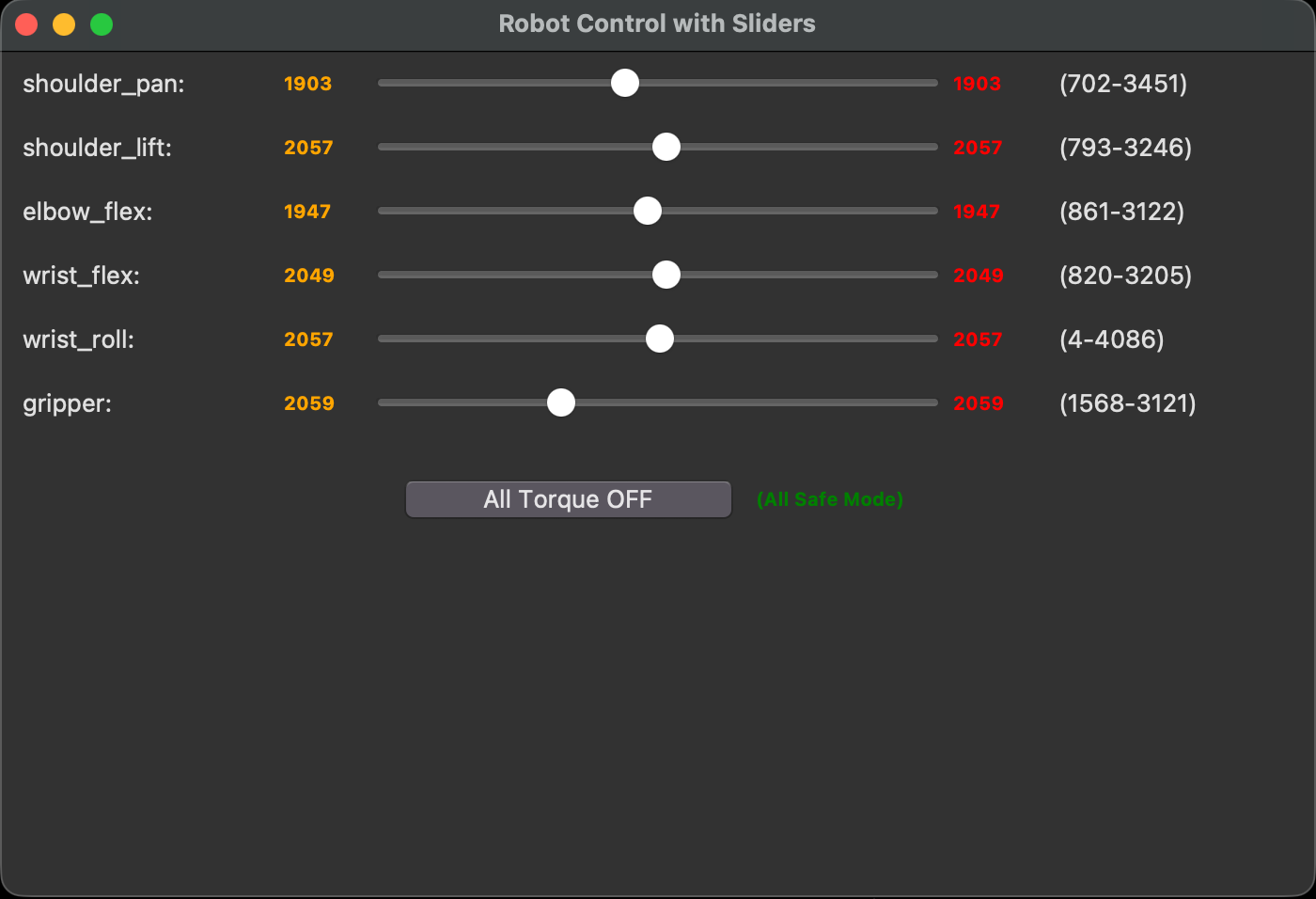
実際に動かしてみる
実際に動かして Kiro のキャラクターのぬいぐるみを掴んで喜んだらぬいぐるみがどっかに飛んでしまったって PC を危うく破壊しかねなかった様子です。これで物理デバイスデビュー完了ですね !
AI でモノを認識して掴ませる
さて、人が目で確認しながらアームでモノを掴めることはわかりましたがこれは AI を使ってないのでただの Physical です(形容詞もおかしいので Physics というツッコミはさておき)。
Physical AI においてロボットを操作するのは VLA (Vision Language Action Model) モデルを使うのが一般的です。VLA モデルとは Vision-Language-Action Models: Concepts, Progress, Applications and Challenges に依ると
原文
Vision-Language-Action (VLA) models mark a transformative advancement in artificial intelligence, aiming to unify perception, natural language understanding, and embodied action within a single computational framework.
日本語訳
Vision-Language-Action(VLA)モデルは、人工知能における変革的な進歩を示しており、知覚、自然言語理解、および具現化された行動を単一の計算フレームワーク内で統合することを目指しています。
とあり、この文脈で意訳すると、見て(Vision)、何をすべきか理解し(Language)、行動する(Action) ことを End to End で行うモデルのことを指します。
VLA は OpenVLA といった MIT-0 ライセンスで公開されているモデルもありますし、今回利用している SO-101 をサポートしている SmolVLA といった比較的軽量 (450M パラメータ) のモデルもありますが、動作環境をいきなり用意するのはクラウドがあっても少し手間です。そこで、まず導入は楽をするために VLA ではなく、LLM を用いて動かすこととしました。ロボットはすでに回転位置制御ができるため、MCP サーバーを作ってしまえば LLM から動かすことが可能なはずです。というわけで、まずは MCP サーバーを実装しました。
capture.py は USB カメラで撮影してファイル名を返す MCP サーバー、so101.py は各モーターの回転位置を与えるとその回転位置にロボットアームが移動する MCP サーバーです(+ モーターの現在の回転位置も取得できる)。
mcp.json
これらを Kiro CLI (LLM を用いた AI エージェント) の MCP サーバーに設定しました。使用した mcp.json は以下の通りです。
{
"mcpServers": {
"WebCam": {
"command": "uv",
"args": [
"--directory",
"/path/to/directory",
"run",
"capture.py"
]
},
"so101": {
"command": "uv",
"args": [
"--directory",
"/path/to/directory",
"run",
"so101.py"
]
}
}
}Kiro CLI で実行
そして、Kiro CLI に以下のようなプロンプトを打ち込んで実行してみました。
まず Capture を使って画像に映る靴下を認識してください。
それをロボットアームで掴んでください。
モータを動かしたら都度 capture を使って状況を確認してください。
各モータの説明は以下のとおりです。
### 1. shoulder_pan(ベース回転)
- **範囲**: 702-3451
- **動作**: アーム全体を水平面で左右に回転
### 2. shoulder_lift(肩の上下)
- **範囲**: 793-3246
- **動作**: アーム全体を上下に傾ける
### 3. elbow_flex(肘の曲げ伸ばし)
- **範囲**: 861-3122
- **動作**: 前腕部分の角度を調整
### 4. wrist_flex(手首の曲げ伸ばし)
- **範囲**: 820-3205
- **動作**: グリッパー部分の上下角度を調整
### 5. wrist_roll(手首の回転)
- **範囲**: 4-4086
- **動作**: グリッパーを軸方向に回転
### 6. gripper(グリッパーの開閉)
- **範囲**: 1568-3121
- **動作**: グリッパーの開閉。数字が大きくなればグリッパーが開く
例として、物が各場所においてある場合のパラメータの例です。グリッパーは閉じたり開いたりしてください。
左上
shoulder_pan: 1687
shoulder_lift: 2802
elbow_flex: 1227
wrist_flex: 2985
wrist_roll: 2081
右上
shoulder_pan: 2313
shoulder_lift: 2802
elbow_flex: 1227
wrist_flex: 2985
wrist_roll: 2081
右下
shoulder_pan: 2600
shoulder_lift: 2013
elbow_flex: 2470
wrist_flex: 2681
wrist_roll: 2081
左下
shoulder_pan: 1246
shoulder_lift: 2013
elbow_flex: 2470
wrist_flex: 2681
wrist_roll: 2081実行結果の様子
すると、、、なかなか掴めない。。。(冒頭の動画です)
うまくいかなかった理由を考える
理由として、モーターの回転位置と物理的な位置がリンクしていないことが上げられます(モーターをこの位置に動かすと掴む装置 (グリッパー) が x, y, z, ロール, ピッチ, ヨーの値がいくつになるのかがわからない)。
画像を用いて探索的にいけばいけるかと思い、左上や右下にグリッパーを持っていったときに各モーターがどの値になるのか、みたいなヒントも与えてみましたが、触れただけで掴むことまではうまく行きませんでした (最後グリッパーが開いちゃっているのが問題で、グリッパーが開いていなければ掴めた可能性がありますが)。
なかなかムズカシイぜ Physical AI …!
次回予告
さて、Kiro CLI ( AI エージェント) にナイーブに MCP サーバーを渡すだけではモノを掴むことができませんでした。つまり、VLA が必要だということですね !
SO-101 では模倣学習をサポートしており、Leader Arm (私の場合は青いアーム) を使って Follower Arm (私の場合は黒いアーム) で全く同じ行動を起こさせることで、与えた画像から正解の行動のデータセットを作って VLA モデルを学習させることができます。そして、VLA モデルの学習には AWS の Amazon SageMaker AI を使える…はずです。
次回の記事ではこの物理デバイスを使って VLA 及び模倣学習を用いてモノを掴むチャレンジをしてみます。
最後に人間とロボットの協調を
さて、最後に人間とロボットの協調として、ロボットにお辞儀させて私の builders.flash での筆を置くこことしましょう。トルクが足りず (?) にリーダーアームが上がりきらなかったあたりも含めいろいろ考えさせられますね !
それではまたどこかでお会いしましょう〜 !
筆者プロフィール
呉 和仁 (Go Kazuhito / @kazuneet)
アマゾン ウェブ サービス ジャパン合同会社
自動車・製造ソリューションアーキテクト
IoT の DWH 開発、データサイエンティスト兼業務コンサルタントを経て現職。
プログラマの三大美徳である怠惰だけを極めてしまい、モデル構築を怠けられる AWS の AI サービスをこよなく愛す。
