Kiro にハーネスを付ける ~ 制御された全力疾走のすすめ
2026-05-07 | Author : 稲田 大陸 (いなりく)

はじめに
こんにちは、AWS Japan でソリューションアーキテクトをしているいなりくです。
2026 年 3 月に Anthropic が公開した「Harness design for long-running application development」は、AI エージェントに長時間の自律的なソフトウェア開発をさせるためのハーネス (制御構造) 設計について書かれた記事です。
この記事では、Prompt → Context → Harness というパラダイムの進化を整理した上で、Anthropic の知見から汎用的に使えるポイントを抽出し、Kiro のカスタムエージェント機能でどう実装できるかを解説します。
builders.flash メールメンバー登録
builders.flash メールメンバー登録で、毎月の最新アップデート情報とともに、AWS を無料でお試しいただけるクレジットコードを受け取ることができます。
Prompt → Context → Harness : 3 つのパラダイム
AI との協働手法は、3 年間で 3 つのパラダイムを経て進化してきました。
Prompt Engineering (2022〜)
ChatGPT の登場とともに「どう指示すれば良い回答が得られるか」に焦点が当たりました。Chain of Thought、Few-shot、Tree of Thought などの技法が研究され、1 回の API 呼び出しの品質を最大化することが目標でした。
Context Engineering (2025〜)
2025 年 6 月、Shopify CEO の Tobi Lütke が「prompt engineering ではなく context engineering と呼ぶべきだ」と提唱し、Andrej Karpathy が支持したことで広まりました。Karpathy はこう述べています、
Context engineering is the delicate art and science of filling the context window with just the right information for the next step.
プロンプトの書き方ではなく、モデルが推論時に何を見ているか (RAG、ツール定義、Few-shot 例、会話履歴、状態管理) を体系的に設計する技術です。この流れは LangChain のブログや MIT Technology Review の記事でも詳しく解説されています。
Harness Engineering (2025 後半〜)
Claude Code、Kiro CLI、OpenAI Codex などの AI コーディングエージェントが本格普及する中で、1 つのコンテキストウィンドウ内の最適化だけでは不十分であることが明らかになりました。
2025 年 11 月、Anthropic が「Effective harnesses for long-running agents」を公開。エージェントが何時間、何日にもわたって作業を続ける場合に必要な、セッション間の引き継ぎ、進捗追跡、品質維持の仕組みを体系化しました。
3 つのパラダイムは排他的ではなく、入れ子構造です。
Prompt Engineering → 1 回の API 呼び出しを最適化
└ Context Engineering → 1 つのコンテキストウィンドウを最適化
└ Harness Engineering → 複数セッションにまたがる環境全体を最適化
なぜナイーブな実装では不十分か
ハーネスなしでエージェントを長時間稼働させると、3 つの典型的な失敗が起きます。
自己評価の甘さ
AI に自分の成果物を評価させると、ほぼ確実に甘い評価になります。Anthropic の記事では「明らかに品質が低い成果物に対しても、自信を持って褒める」と指摘しています。検証可能なテストがある場合でさえ、エージェントは問題を見つけた後に「大した問題ではない」と自分を説得して承認してしまいます。
早期完了宣言
プロジェクトの後半、いくつかの機能が動いている状態で、エージェントが周囲を見回し「ジョブ完了」と宣言してしまいます。残りのタスクは放置されます。
技術的負債の増幅
人間のエンジニアはコード中の「地雷」を見つけたとき迂回しますが、エージェントはそのパターンを「正当なアプローチ」として学習し、次に同様の機能を生成するとき体系的に再利用します。一時的な回避策がコードベース全体に拡散するのです。
Anthropic の記事の核心的知見
2026 年 3 月の記事「Harness design for long-running application development」は、2025 年 11 月の初回記事から進化し、GAN (敵対的生成ネットワーク) に着想を得たマルチエージェント構造を提案しています。 (私の修士論文で GAN を使った研究をしていたので、懐かしい気持ちになりました。)
GAN とは何か
GAN (Generative Adversarial Network) は 2014 年に Ian Goodfellow が提案した機械学習のアーキテクチャです。2 つのニューラルネットワークを競わせることで、高品質な出力を生成します。
- Generator (生成器) : データを生成する。最初はランダムなノイズから始まり、徐々にリアルな出力を学習する
- Discriminator (識別器) : 生成されたデータが本物か偽物かを判定する
Generator は Discriminator を騙そうとし、Discriminator は見破ろうとする。この敵対的な関係が互いを改善し続け、最終的に Generator は非常にリアルな出力を生成できるようになります。画像生成の分野で大きな成功を収めた手法です。
Anthropic の記事は、この構造をソフトウェア開発に応用しています。Generator がコードを書き、Evaluator がその品質を判定する。Evaluator のフィードバックが Generator を改善し、Generator の出力が Evaluator の判定精度を鍛える。GAN と同じ「競争による品質向上」の原理です。
1. Generator と Evaluator の分離
ソフトウェア開発の文脈では、Generator と Evaluator はそれぞれ以下の役割を担います、
Generator (生成者) は、仕様に基づいてコードを書くエージェントです。人間のソフトウェアエンジニアに相当します。ファイルの作成・編集、git 操作、シェルコマンドの実行など、全ての権限を持ちます。
Evaluator (評価者) は、Generator の成果物を検証するエージェントです。人間のコードレビュアーや QA エンジニアに相当します。コードを読み、テストを実行し、ライブアプリを操作して品質を採点しますが、コードの修正権限は持ちません。
この分離が重要な理由は、AI の自己評価が構造的に甘くなるためです。記事では「明らかに品質が低い成果物に対しても、自信を持って褒める」と指摘しています (これは実体験にもよく当てはまり、クビがモゲルほど頷きました笑)。独立した Evaluator を懐疑的にチューニングする方が、Generator に自己批判させるよりはるかに容易です。
❌ 1 つのエージェントが実装 → 自己評価 → 「よくできました」
✅ generator が実装 → 独立した evaluator が評価 → 具体的な問題を指摘
全体のフローを図にするとこのようになります。あくまで一例です。
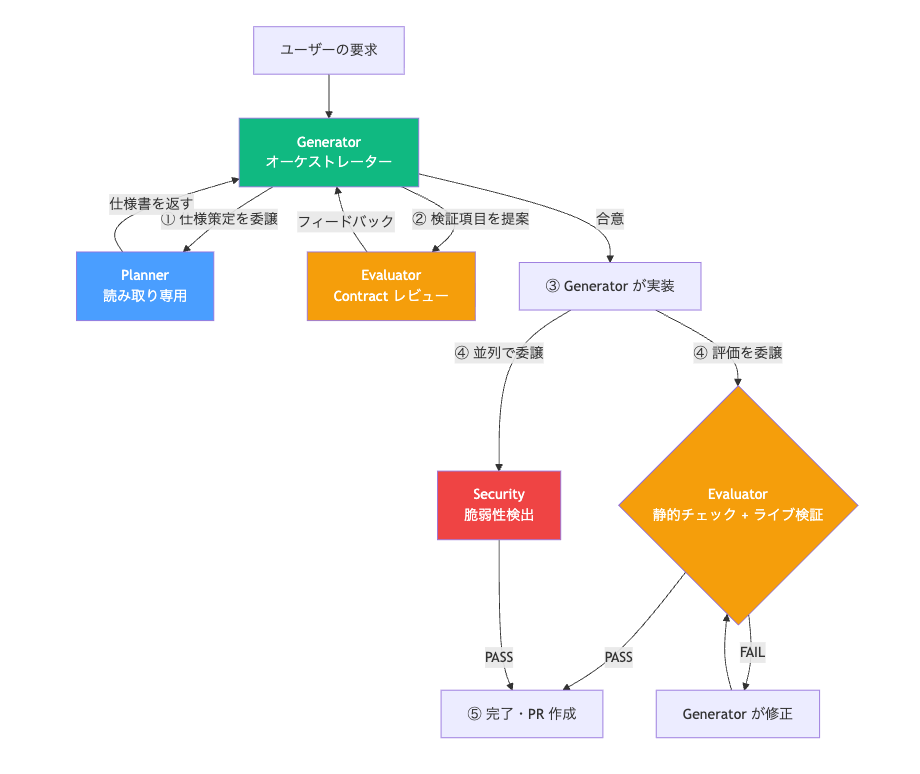
2. Sprint Contract で「完了」の定義を事前に合意する
ソフトウェア開発で最もよくある問題の 1 つは「完了の定義が曖昧」なことです。人間のチームでも「実装しました」「いや、この場合のテストは?」というやりとりは日常的に起きます。エージェント同士でも同じです。
Sprint Contract は、実装前に generator と evaluator が「何をテストするか」を交渉して合意するステップです。
具体例で説明します。planner が「ユーザーがファイルをアップロードできる機能」という仕様を書いたとします。この仕様だけでは evaluator は何を検証すればいいかわかりません。
そこで、
- Generator が検証項目を提案する、「ドラッグ&ドロップでアップロードできること」「10MB 超のファイルでエラーが出ること」「アップロード中にプログレスバーが表示されること」
- Evaluator がレビューする、「PDF 以外のファイル形式のテストが抜けている」「ネットワークエラー時の挙動も検証すべき」
- 合意する、最終的な検証項目リストをチェックボックスとして確定する
## Sprint Contract (合意済み)
- [ ] ドラッグ&ドロップでファイルをアップロードできる
- [ ] 10MB 超のファイルでエラーメッセージが表示される
- [ ] PDF, DOCX, TXT 形式がアップロードできる
- [ ] アップロード中にプログレスバーが表示される- [ ] ネットワークエラー時にリトライボタンが表示される
実装後、evaluator はこのチェックボックスを 1 つずつ検証し、PASS / FAIL を付けます。「何を検証するか」が事前に合意されているため、evaluator の検証漏れも generator の実装漏れも防げます。
3. Evaluator はライブアプリを操作して検証する
記事で最も効果が大きかったのは、evaluator が Playwright でライブアプリを実際に操作して検証するパターンです。コードを読むだけの静的レビューでは見つからないバグ (ボタンが反応しない、フォームの送信が壊れている等) を、ユーザーと同じ操作で発見できます。
記事の DAW (デジタルオーディオワークステーション) の例では、evaluator が以下のような具体的な問題を発見しています。
Rectangle fill tool only places tiles at drag start/end points instead of filling the region. fillRectangle function exists but isn't triggered properly on mouseUp.
コードレビューだけでは見逃しやすい、実行時の結合バグを検出できるのがライブ検証の強みです。
マルチエージェント協調パターンとの関係
Anthropic のハーネス設計記事と関連して、2026 年 4 月に Claude 公式ブログで「Multi-agent coordination patterns」が公開されています。この記事では、マルチエージェントシステムの 5 つの協調パターンが整理されています。
|
パターン
|
概要
|
適するケース
|
|---|---|---|
|
Generator-Verifier
|
生成 → 検証 → FAIL なら修正ループ |
品質が重要で、評価基準を明示できる場合 |
|
Orchestrator-Subagent
|
リーダーがサブタスクを委譲し結果を統合 |
タスク分解が明確で、サブタスクが独立している場合 |
|
Agent Teams
|
長時間の独立タスクを並列実行 |
並列で進められる大規模な作業がある場合 |
|
Message Bus
|
イベント駆動のパイプライン |
ワークフローがイベントから動的に決まる場合 |
|
Shared State
|
共有ストアを通じた協調 |
エージェント同士が発見を共有しながら作業する場合 |
重要な指摘
ハーネス設計の 3 エージェント構造は、この分類でいうと Generator-Verifier と Orchestrator-Subagent の組み合わせです。
- Generator-Verifier の部分、generator がコードを書き、evaluator が検証し、FAIL なら修正して再評価するループ
- Orchestrator-Subagent の部分、generator がオーケストレーターとして planner、qa、security にタスクを委譲する階層構造
記事の中で特に重要な指摘が 2 つあります。
1 つ目は「verifier は基準が明示されていないと rubber-stamp する」という点です。「良いかどうかチェックして」とだけ言われた verifier は、generator の出力をそのまま承認してしまう。これは前述の few-shot キャリブレーションで対処すべき問題そのものです。
2 つ目は「反復ループは停滞しうる」という点です。generator が verifier のフィードバックに対応できない場合、システムは収束せずに振動する。記事は「最大反復回数の制限 + フォールバック戦略 (人間にエスカレート、最善の結果を注釈付きで返す) 」を推奨しています。これは今回のオシレーション防止とピボット判断に直接対応します。
この 5 パターンの分類を知っておくと、自分のハーネスがどのパターンの組み合わせなのかを意識でき、パターンごとの弱点に対する対策を事前に設計できます。
汎用的なハーネス設計パターン
記事から抽出した、どのプロジェクトにも適用できるパターンをまとめます。
パターン 1 : 3 エージェント分離
|
エージェント
|
責務
|
権限
|
|---|---|---|
|
Planner
|
仕様策定。プロダクト視点で「何を作るか」を定義 |
読み取り専用 |
|
Generator
|
実装。仕様に従ってコードを書く |
全権限 |
|
Evaluator
|
品質評価。コードを読み、テストを実行し、採点する |
読み取り + コマンド実行 |
重要なのは evaluator にコード修正権限を与えない ことです。修正権限があると「問題を見つけたら自分で直す」方向に流れ、generator へのフィードバックが曖昧になります。
パターン 2 : 採点基準の明示と few-shot キャリブレーション
「このデザインは良いか ?」は答えにくいですが、「このデザインは我々の原則に従っているか ?」は具体的に採点できます。
evaluator には、
- 採点基準を明示する (何を見るか)
- 各スコアに判定例を付ける (5 点はこういう状態、3 点はこういう状態)
- 閾値を設定する (3 未満は FAIL)
### 機能完全性
- 5/5 : 全 AC 達成 + エッジケース処理 + エラーハンドリング完備
- 3/5 : 全 AC 達成だがエッジケース未処理
- 1/5 : AC の半数以上が未達
few-shot 例がないと、evaluator の採点は実行ごとにブレます。
パターン 3 : フィードバックループ + オシレーション防止
FAIL → 修正 → 再評価のループは必須ですが、無制限に回すと、
- 同じ箇所を「A に修正」→「B に戻す」→「A に修正」と振動する
- 修正が別の箇所を壊し、永遠に収束しない
これらの対策として、以下のアプローチが可能です。
- 最大ラウンド数を設定する (3 ラウンドが実用的)
- オシレーション検出: 同じ箇所に 2 回異なる方向の指摘 → 最初の修正で確定
- ピボット判断: 2 ラウンド目で改善が見られない場合、アプローチ自体を見直す
パターン 4 : 静的解析ツールによる即時フィードバック
エージェントは自分のミスに自力で気づきにくいため、コードを書いた直後に機械的にフィードバックを返す仕組みが重要です。人間のエンジニアなら「あ、これもう使ってないな」と気づくところを、エージェントは気づかないまま次の実装に進みます。
実際のプロジェクトでは、以下のようなツールを 2 つのタイミングで回しています。
書いた瞬間 (postToolUse hook) :
Kiro のカスタムエージェントには hooks 機能があり、ファイル書き込みのたびに自動でフォーマッタ・リンターを実行できます。
{
"hooks": {
"postToolUse": [
{
"matcher": "fs_write",
"command": "npx biome check --write --unsafe \"$TOOL_FILE_PATH\""
},
{
"matcher": "fs_write",
"command": "ruff format \"$TOOL_FILE_PATH\" && ruff check --fix \"$TOOL_FILE_PATH\""
}
]
}
}上の例では TypeScript 用 (Biome) と Python 用 (ruff) を別々に書いていますが、実際のプロジェクトでは 1 つの hook 内で拡張子を判定する bash スクリプトにまとめることが多いです。matcher: "fs_write" はファイル書き込みツールの内部名で、$TOOL_FILE_PATH に書き込まれたファイルのパスが渡されます。
これにより、エージェントが書いたコードは保存された瞬間にプロジェクトの規約に矯正されます。エージェントが次にそのファイルを読んだとき、常に正しいフォーマットのコードが見えるため、悪いパターンの増幅を防げます。
評価時 (Evaluator の静的チェック) :
以下は一例です。プロジェクトの技術スタックに応じて、同等の役割を果たすツールを選択してください。
TypeScript / JavaScript
|
ツール
|
何をするツールか ?
|
検出対象
|
レイテンシー
|
|---|---|---|---|
|
tsc --noEmit
|
TypeScript コンパイラ。コードを出力せず型チェックだけ実行する |
型エラー、シグネチャ変更後の呼び出し元不整合 |
数秒 |
|
Biome
|
Rust 製の高速リンター兼フォーマッター。ESLint + Prettier の代替 |
コーディング規約違反、未使用 import |
数秒 |
|
knip
|
未使用の export、ファイル、依存関係を検出する専用ツール |
デッドコード、不要な npm パッケージ |
数秒 |
|
vitest
|
Vite ベースの高速テストランナー。Jest 互換の API を持つ |
ロジックエラー、リグレッション |
数十秒 |
Python
|
ツール
|
何をするツールか ?
|
検出対象
|
レイテンシー
|
|---|---|---|---|
|
pyright
|
Microsoft 製の静的型チェッカー。tsc の Python 版に相当する |
型エラー、型ヒントの不整合 |
数秒 |
|
ruff
|
Rust 製の高速リンター兼フォーマッター |
コーディング規約違反、未使用 import/変数 |
数秒 |
|
vulture
|
Python のデッドコード (未使用の関数、変数、import) を検出する |
デッドコード |
数秒 |
|
pytest
|
Python の標準的なテストフレームワーク |
ロジックエラー、リグレッション |
数十秒 |
他の技術スタックの場合
他の技術スタックでも同じ考え方が適用できます。Go なら go vet + staticcheck、Rust なら clippy + cargo test など、「書いた直後に機械的にフィードバックを返す」ツールチェーンを組むことが重要です。
特に knip と vulture (デッドコード検出) はエージェント開発で価値が高いです。エージェントはリファクタリング時に古いコードを消し忘れる傾向があり、放置するとコードベースが肥大化し、エージェント自身のコンテキストを圧迫します。
これらは全て Evaluator が自動実行し、1 つでもエラーがあれば FAIL を返します。エージェントに「自分で気をつけて」と言うのではなく、ツールで機械的に検出する。これがハーネス設計の基本思想です。
パターン 5 : コードベースそのものがコンテキスト
外部の RAG システムや追加メモリファイルを構築するのではなく、コードベース自体を高品質なコンテキストとして設計するという考え方です。
- ディレクトリ構造がドキュメントである (製品概念からコードパスへの直接的なマッピング)
- 命名規則の統一 (フロントエンドとバックエンドで同じ概念に同じ名前)
- クリーンアーキテクチャの強制 (レイヤー分けがエージェントに「どこに何を書くべきか」を伝える)
良いパターンがコードベースの大部分を占めれば、エージェントは良いパターンを増幅します。逆もまた然りです。
パターン 6 : ハーネスの定期的な見直し
記事の最も重要な教訓は「ハーネスの各コンポーネントは、モデルが単独でできないことへの仮定をエンコードしている。その仮定はストレステストする価値がある」です。これは Anthropic の「Building Effective Agents」で述べられた「最もシンプルな解決策を見つけ、必要な場合にのみ複雑さを増す」という原則の延長線上にあります。
新しいモデルがリリースされたら、
- ハーネスの各コンポーネントを 1 つずつ外してみる
- 品質に影響があるか確認する
- 不要になったものは削除し、新たに可能になったものを追加する
記事では、Opus 4.5 で必須だった sprint 分割が Opus 4.6 では不要になった例が紹介されています。
Kiro のカスタムエージェントで実装する
ここからは、上記のパターンを Kiro のカスタムエージェント機能でどう実装するかを解説します。
エージェント構成
シンプルな Power の場合、すべてのガイダンスを POWER.md に直接含めます。AgentCore Power のように複雑なツールの場合は、ワークフローごとにステアリングファイルを分割します。
.kiro/agents/
├── generator.json # オーケストレーター兼実装者
├── planner.json # 仕様書ライター (読み取り専用)
├── qa.json # 品質評価者 (読み取り + コマンド実行)
├── security.json # セキュリティ評価者 (読み取り + コマンド実行)
└── prompts/
├── generator.md
├── planner.md
├── qa.md
└── security.mdAnthropic の記事は evaluator が 1 つですが、品質とセキュリティは観点が異なるため私は分離して定義しています。
Generator: オーケストレーター
generator はサブエージェントを呼び出して計画・評価を委譲し、自分は実装に集中します。
{
"name": "generator",
"tools": ["*"],
"toolsSettings": {
"subagent": {
"availableAgents": ["planner", "qa", "security"]
}
}
}ワークフローの動き
ワークフローは 5 フェーズで動かしています。
- Phase 1 : Plan → planner に仕様策定を委譲 → Issue 作成
- Phase 1.5 : Contract → qa と検証項目を交渉 (Issue コメント)
- Phase 2 : Generate → feature branch で実装
- Phase 3 : Evaluate → qa + security を並列呼び出し
- Phase 4 : Fix Loop → FAIL → 修正 → 再評価 (最大 3 ラウンド)
Planner : 高レベルに留める
- プロダクト視点で考える。「ユーザーにとって何が価値か」に集中する
- acceptance criteria は具体的かつテスト可能にする
- コードを書く- 技術スタックの選定をする
- 実装順序を指定する
ツールの制限
ツールも読み取り専用に制限します。
{
"tools": ["read", "code", "grep", "glob"]
}QA : 静的チェック + ライブ検証
qa エージェントには playwright-cli スキルを組み込み、ライブアプリの操作検証を可能にします。
{
"tools": ["read", "shell", "code", "grep", "glob"],
"resources": [
"skill://.kiro/skills/playwright-cli/SKILL.md"
]
}評価手順は 2 段階としています。
- 静的検証 : tsc --noEmit, lint, test, ruff check
- ライブ検証 (UI 変更時) : playwright-cli でブラウザを開き、acceptance criteria に沿って操作
## ライブ UI 検証
1. playwright-cli open <URL> でブラウザを開く
2. playwright-cli snapshot で要素の ref を取得する
3. acceptance criteria に沿って操作する
4. 問題を発見したら screenshot で証拠を保存する
Issue との連携
私は、sprint contract を GitHub の Issue 上で管理しています。これによって、トレーサビリティが自然に生まれます。
- Phase 1 : gh issue create (仕様 + AC)
- Phase 2 : Issue コメントで検証項目を交渉 → 本文にチェックボックス追記
- Phase 3 : Generate → feature branch で実装
- Phase 4 : qa が検証結果を Issue コメントに記録
- Phase 5 : Fix Loop の結果も Issue コメントに追記
- Phase 6 : gh pr create --body "Closes #123" で完了
まとめ
Anthropic の記事から得られる最も重要な教訓は、ハーネス設計は一度作って終わりではないということです。
モデルが改善されれば不要になるコンポーネントがあり、新たに可能になる組み合わせがある。定期的にハーネスの各部品をストレステストし、不要なものを削り、新しいものを追加していく。その継続的なチューニングこそが、AI エンジニアリングの本質です。
今回紹介したパターンをまとめると、
- Generator と Evaluator を分離する — 自己評価の甘さは構造で解決する
- Sprint Contract で完了条件を事前に合意する — 曖昧な仕様を検証可能な項目に変換する
- Evaluator にライブアプリを操作させる — 静的レビューでは見つからないバグを検出する
- 採点基準を明示し few-shot で校正する — 評価のブレを抑える
- フィードバックループにオシレーション防止を入れる — 無限ループを防ぐ
- 静的解析ツールで即時フィードバックを返す — エージェントのミスを機械的に検出する
- コードベースそのものをコンテキストとして設計する — 良いパターンはエージェントが増幅する8. モデル更新時にハーネスを見直す — 不要になった部品を削り、新しい可能性を探る
これらは Kiro に限らず、どのコーディングエージェントのハーネス設計にも適用できる汎用的なパターンです。
Next Action
ハーネスは最初から完璧に作る必要はありません。シンプルな構成から始めて、必要に応じて複雑さを増していくのが鉄則です。
- まず 2 体から始める
Kiro CLI で /agent create して、planner + generator の 2 エージェント構成を作る。planner に仕様を書かせ、generator が実装する最小構成からはじめましょう。 - evaluator を追加する :
qa エージェントを作り、プロジェクトの型チェックとリンターを自動実行させるようにしましょう。これだけで「自己評価の甘さ」問題の大部分が解消するかと思います。 - ライブ検証を入れる :
playwright-cli スキルを qa に組み込んで、UI を実際に操作させる。静的チェックでは見つからないバグも見つけられるようにしましょう。 - 定期的に見直す:
モデルが更新されたらハーネスの各部品を 1 つずつ外して、まだ必要か確認しましょう。不要になったものは削り、新しい可能性を探ってみましょう。
筆者プロフィール
稲田 大陸 (いなりく / @inada_riku)
アマゾン ウェブ サービス ジャパン合同会社
ソリューションアーキテクト
AWS Japan で働く筋トレが趣味のソリューションアーキテクト。製造業のお客様を支援させていただいています。最近は AI 駆動開発ライフサイクル (AI-DLC) の日本のお客様への布教活動もしつつ、Kiro のブログなどを執筆しています。
