「この記事、スライドにして」を実現する AI エージェントの裏側
2026-06-02 | Author: 片岡 翔太郎、吉川 直仁、岡本 晋太朗

はじめに
「この記事をスライドにして」——そう伝えるだけでプレゼン資料ができるツール Spec-Driven Presentation Maker (SDPM) を 2026 年 4 月 13 日に OSS として公開しました。このエージェントの裏側には、2 月の社内プロトタイプから公開版に至るまでの試行錯誤があります。SDPM の内部設計の概要については、先に Zenn の技術解説記事「AI でプレゼンテーションスライドを作る - Spec-Driven Presentation Maker 技術解説」をご一読ください。
本記事では、SDPM の実装の過程で直面した 5 つの設計判断に焦点を当て、AI エージェントを自ら開発したい方 — 特に MCP (Model Context Protocol) を活用したアプリケーションや、複数エージェントを連携させるシステムを構築しようとしている方——に向けて、その開発過程で直面した技術的な課題とその対処法を届けます。
builders.flash メールメンバー登録
2 月のプロトタイプから 4 月の公開版へ
SDPM の原型は2026 年 2 月に生まれました。当時、Markdown からスライドを生成するツールは存在していましたが、「PowerPoint で自分で編集できる」「デザインの一貫性を保って自由な生成ができる」という要件を満たすものはありませんでした。JSON で論理構造を定義し、そこから PowerPoint ファイルを生成するアプローチで開発を始め、コーディングエージェント用のスキルとして社内公開したところ、数日で大きな反響がありました。
一方で、フィードバックも明確でした。「Web で使えると嬉しい」「非技術者にはコーディングエージェント上で動かすのはハードルが高い」——こうした声を受けて Web UI の開発が始まりました。
この過程で、もう一つ大きな転換がありました。もともとのツールには「ペルソナ→ゴール→ヒアリング→アウトライン→生成」という流れがあり、これは Kiro が提唱する Spec-Driven Development (仕様駆動開発) の考え方に近いものでした。この「仕様を先に定義する」思想を前面に押し出し、brief (目的定義) ・outline (構成定義) ・art-direction (デザイン定義) の 3 ファイルで仕様を明文化する設計に整理しました。
結果として、AWS アカウントなしで使えるスキル版から、フルスタックの Web UI 版まで、段階的に導入できる構成として公開に至っています。詳細は 紹介ブログ をご覧ください。
1. 「仕様を書いたら並列化できた」— Spec-Driven が解いた技術的課題
Design Description の限界
SDPM の社内版には「Design Description」というフィールドがありました。スライドの JSON 定義の中に、そのスライドをどう作るべきかを自然言語で記述する項目です。Chain of Thought (思考の連鎖) 的に、LLM にあらかじめ全体像を考えさせてからスライドを構成させる狙いでした。
しかし、実際に運用してみると問題が見えてきました。スライド毎に Design Description を生成するため処理が遅い。効果も不明確で、LLM が Description の内容を無視してスライドを作ることもありました。
3 ファイル定義への転換
そこで、スライド単体に付随する Description を廃止し、プレゼンテーション全体の仕様を 3 つのファイルで定義する方式に切り替えました。
- brief.md — プレゼンの目的、ペルソナ、ゴールを定義
- outline.md — スライド構成とストーリーラインを定義
- art-direction.html — デザイントークン (配色、フォント、余白) を CSS 変数で定義し、HTML でプレビュー可能に
art-direction を HTML にしたのは、Spec-Driven の思想と深く関係しています。HTML ならブラウザでプレビューできるため、人間とエージェントの双方がデザイン方針を確認できます。さらに CSS の語彙はスライドのエレメント定義と親和性が高く、エージェントがデザイン指示を正確に解釈しやすいという利点もありました。
仕様があるから並列化できる
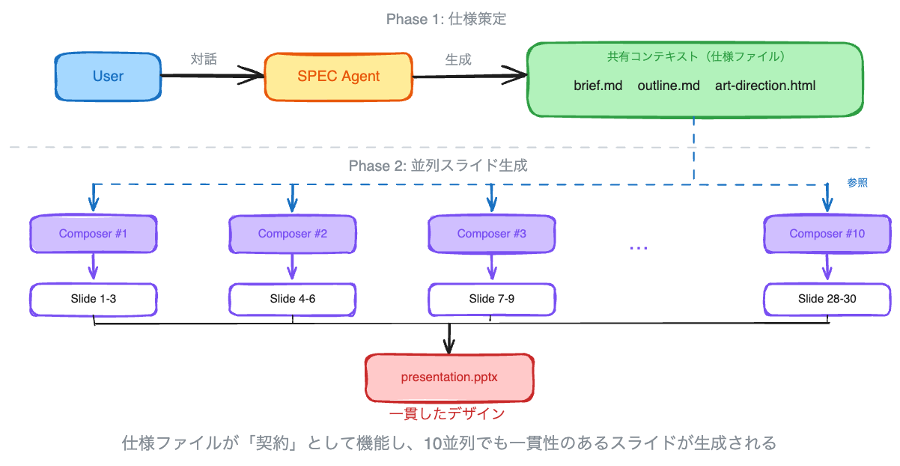
この設計変更がもたらした最大の効果は、スライド生成の並列化でした。Spec-Driven というパラダイムを選んだことで、brief・outline・art-direction という共有コンテキストが自然に形成されました。仕様ファイルがない状態で複数のエージェントにスライドを分担させると、デザインの一貫性が崩壊します。あるエージェントは青基調で作り、別のエージェントは緑基調で作る——そうした事態が起きます。しかし、共通の仕様ファイルがあれば、各エージェントは自分の担当範囲だけに集中しても、全体としてのデザイン一貫性が担保されます。少なくとも SDPM では、Spec-Driven を選ばなければこの共有コンテキストは生まれず、並列化には至っていなかったでしょう。
SDPM では、SPEC エージェント (Phase 1: 対話・仕様策定) と Composer エージェント (Phase 2: スライド生成) を分離し、Composer を最大 10 並列で動作させています。エージェントの構築には Strands Agents を使用しています。Strands Agents は、プロンプトとツールのリストを定義するだけでエージェントを構築できるオープンソース SDK で、モデルが自律的に計画・推論・ツール呼び出しを行います。この並列実行も、Strands の Agents as Tools パターン——あるエージェントのツールとして別のエージェントを呼び出す仕組み——で実現しています。図は、各モードの定義です。
agent/modes/__init__.py
MODES: dict[str, ModeConfig] = {
# Phase 1: ユーザーと対話して仕様を策定するエージェント
"separated": ModeConfig (parts=[
_COMMON_LANGUAGE,
Part (Source.file ("role/spec_agent") , target="system") ,
_COMMON_ATTACHMENTS,
_WF_CANCELLATION,
_WF_POST_COMPOSE,
_WF_SLIDE_GROUPS,
_NOW,
_PREFETCH_BRIEFING, # ← ワークフローを事前読み込み (後述)
]) ,
# Phase 2: スライドを実際に生成するサブエージェント
"composer": ModeConfig (
parts=[
Part (Source.file ("role/composer") , target="system") ,
Part (Source.mcp ("read_workflows", {"names": ["create-new-2-compose"]}) ,
target="system", label="create-new-2-compose") ,
Part (Source.mcp ("read_guides", {"names": ["grid"]}) ,
target="history:tool_result", label="read_guides") ,
Part (Source.mcp ("read_examples", {"names": ["components/all"]}) ,
target="history:tool_result", label="read_examples") ,
# ...
],
use_composer=False,
) ,
}ModeConfig と Part は Strands Agents 本体の API ではなく、SDPM が独自に実装したヘルパー構造体です。ModeConfig はエージェントのシステムプロンプトとメッセージ履歴をどう組み立てるかを宣言的に定義する仕組みで、Part はコンテンツの取得元 (ファイル、MCP ツール呼び出し、動的生成) と注入先 (システムプロンプト、メッセージ履歴) を指定します。
ポイントは、SPEC エージェントが作った仕様ファイル (brief / outline / art-direction) を、Composer エージェントが共通のコンテキストとして参照する構造になっていることです。仕様ファイルが「契約」として機能するため、10 並列で動いても一貫性のあるスライドが生成されます。
2. 「100 ページの PDF を渡したらエージェントが沈黙した」— 流し読みさせるツール設計
全文読みの限界
SDPM では、ユーザーが URL を指定して Web 上の資料をスライドの参考にできます。しかし、長大な HTML ページや 100 ページを超える PDF を全文読みするとコンテキストが枯渇し、エージェントが応答しなくなることがありました。画像をそのままコンテキストに入れると、さらにトークン消費が加速します。
ページネーションと画像インデックス
この問題に対して、web_fetch ツールに 2 つの仕組みを入れました。
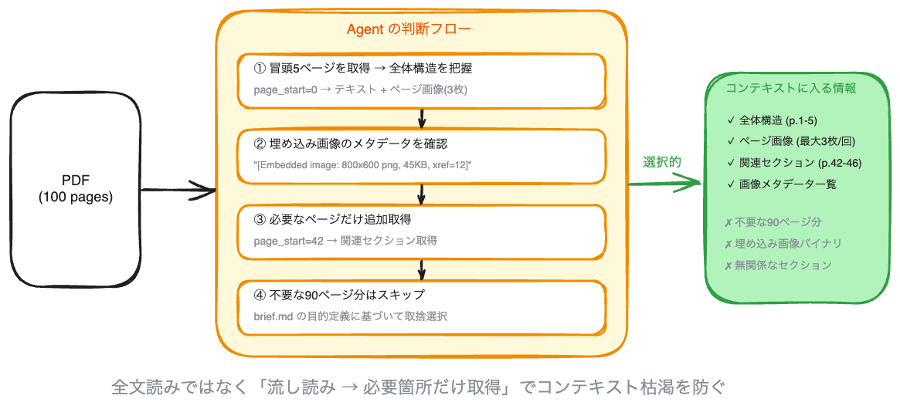
ページネーション: PDF は 1 回の呼び出しで最大 5 ページ分だけ返し、page_start で必要な箇所にジャンプします。HTML も start / max_chars でチャンク読みできます。どちらの場合も、エージェントは冒頭を読んで全体構造を把握してから、必要な箇所だけを追加で取得します。
画像インデックス : PDF 内の埋め込み画像はバイナリを返さず、メタデータ (サイズ、フォーマット、バイト数) だけをテキストで返します。HTML では include_images=True にすると Markdown 内に ![alt] (url) が残ります。どちらの場合も、エージェントはインデックスを見て「このスライドに使えそうだ」と判断した画像だけを個別に取得します。
agent/tools/web_tools.py — 埋め込み画像はメタデータのみ返す
ページ画像のレンダリング (枚数制限付き)
if page_images_rendered < MAX_PAGE_IMAGES:
pix = page.get_pixmap (dpi=150)
img_bytes = pix.tobytes ("png")
content.append ({"image": {"format": "png", "source": {"bytes": img_bytes}}})
page_images_rendered += 1
# 埋め込み画像はメタデータのみ (バイナリは返さない)
for img_info in page.get_images (full=True) :
xref = img_info[0]
base_image = doc.extract_image (xref)
w = base_image.get ("width", "?")
h = base_image.get ("height", "?")
ext = base_image.get ("ext", "?")
size = len (base_image.get ("image", b"") )
content.append ({"text": f"[Embedded image page {i + 1}: {w}x{h} {ext}, {size} bytes, xref={xref}]"}) あたかも人間が資料を流し読みして「ここが使えそう」と判断するのと同じ動きです。
仕様ファイルがここでも効く
セクション 1 で述べた仕様ファイルが、ここでもエージェントの判断基準として機能しています。brief.md に「何を伝えたいか」が明文化されているからこそ、エージェントは膨大な資料の中から必要な箇所を選択できます。
3. 「プロンプトに入れたら読まなくなった」—— エージェントに知識を渡す技法
役割が生んだ副作用
SDPM の SPEC エージェントには、「ブリーフィングのワークフローに従ってヒアリングを進める」という固定の役割があります。この進め方は read_workflows というツールで読み込む「ワークフロー」として定義されており、エージェントは起動時にこれを参照して手順に従います。
開発の過程で、パフォーマンス改善のためにワークフローの内容をシステムプロンプトに直接埋め込んでみたことがありました。ツール呼び出しのオーバーヘッドを省けるはずだ、という判断です。
ところが、結果は逆でした。エージェントが read_workflows を呼ばなくなったのです。システムプロンプトに書かれた内容を「最初から知っている知識」として認識し、ツールの存在自体に気づかなくなりました。ワークフローの手順には従うものの、ツールを通じて追加の情報を取得する行動が消えてしまったのです。
Prefill (歴史改変) という解決策
ここで言う「Prefill」とは、エージェントが実際にツールを呼び出す前に、ツール呼び出しとその結果をメッセージ履歴に事前に差し込む手法です。本記事ではこれを便宜上「歴史改変」と呼びます。
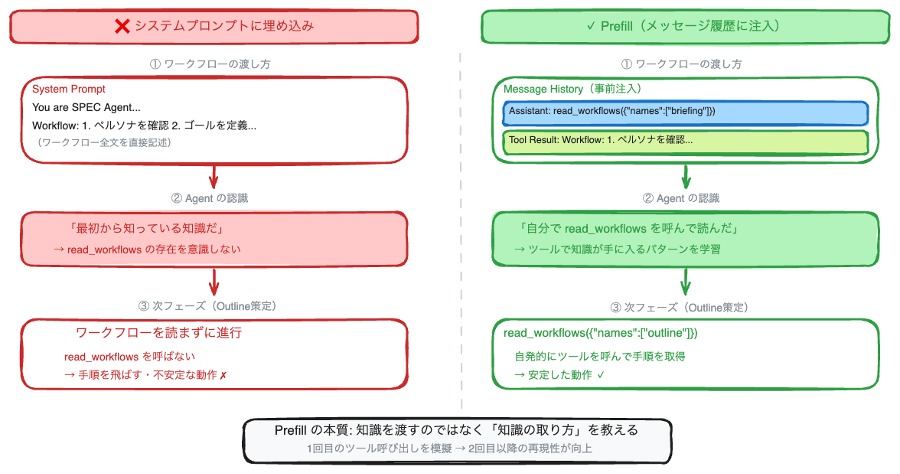
解決策は、ワークフローを事前に読み込みつつも、「エージェントが自分の意思でツールを呼んで読んだ」という形でメッセージ履歴に挿入するというものでした。
agent/composition.py
def _tool_result_pair (label: str, content: str, prefill_text: str = "") -> list[dict]:
"""エージェントが「自分で読んだ」形にするメッセージペアを生成する"""
tool_use_id = f"prefill-{uuid.uuid4 () .hex[:8]}"
text = prefill_text or f"I'll read {label}."
return [
# エージェントがツールを呼んだことにする (assistant ロール)
{
"role": "assistant",
"content": [
{"text": text},
{"toolUse": {"toolUseId": tool_use_id, "name": label, "input": {}}},
],
},
# ツールの結果としてコンテンツを返す (user ロール)
{
"role": "user",
"content": [
{"toolResult": {
"toolUseId": tool_use_id,
"content": [{"text": content}],
"status": "success",
}},
],
},
]
この関数は、assistant ロールの「ツールを呼ぶ」メッセージと、user ロールの「ツール結果を返す」メッセージのペアを生成します。実際にはエージェントがツールを呼んでいないのですが、メッセージ履歴上は「エージェントが自発的にツールを使って情報を取得した」ように見えます。この「歴史改変」により、エージェントは「このツールを読めばこの知識が手に入る」というパターンを学習し、以降も必要に応じてツールを呼ぶ行動を維持するようになりました。
agent/modes/__init__.py
実際の適用箇所を見てみましょう。
_PREFETCH_BRIEFING = Part (
Source.mcp ("read_workflows", {"names": ["create-new-1-briefing"]}) ,
target="history:tool_result", # ← システムプロンプトではなくメッセージ履歴に注入
label="read_workflows",
prefill_text="Starting the Briefing phase. I'll read the workflow to conduct the hearing properly.",
) target="history:tool_result" が鍵です。target="system" にするとシステムプロンプトに入り、エージェントは「最初から知っている」と認識します。target="history:tool_result" にすると、メッセージ履歴の中に「ツールを呼んで結果を得た」という体験として挿入されます。この違いは微妙に見えますが、エージェントの行動に大きな影響を与えました。私たちの観察では、「ツールを呼んで知識を得る」というパターンが履歴にあると、以降も同じ行動を取りやすくなります。Prefill なしだとフェーズ遷移時に read_workflows を呼ばないケースが頻発しましたが、Prefill ありでは安定してツールを呼ぶようになりました。
シングルエージェントでは不要、マルチエージェントモードで必要になる理由
DPM には MCP クライアントから直接呼び出すシングルエージェントモードと、SPEC・Composer を役割分担させるマルチエージェントモードがあります。以下は後者を主な対象として話を進めます。
シングルエージェントモードでは、そもそもワークフローをシステムプロンプトに埋め込む必要がありません。システムプロンプトは「You are a helpful assistant」程度の最小限のもので、能力のほとんどは MCP の server_instructions (MCP サーバーがクライアントに返すメタ情報) から獲得しており、ユーザーの指示に応じてツールを探して使うだけで十分機能します。
シングルエージェントは「何でもできるエージェント」なので、ユーザーの指示に応じてツールを探して使えばよく、server_instructions だけで十分です。一方、マルチエージェントモードではそれぞれのエージェントごとに役割が決まっています。SPEC エージェントは起動した瞬間から「ブリーフィングのワークフローに従ってヒアリングを始める」という決まった行動をしなければなりません。
ここで問題になるのがワークフローの渡し方です。システムプロンプトに入れると内容は伝わりますが、エージェントは「read_workflows を呼んで読んだ」という体験をしていません。そのため、次のフェーズ (outline・art-direction) のワークフローを読む必要が出たとき、同じツールを使うという発想に至りません。Prefill で渡すと、「自分が read_workflows を呼んで読んだ」という記憶があるため、次のフェーズでも自然に同じツールを呼びます。
つまり Prefill の本質は「知識を渡す」ことではなく、「知識の取り方を教える」ことだと解釈しています。1 回目のツール呼び出しを模擬することで、2 回目以降のツール呼び出しの再現性を高めています。
4. 「何もしないツール」が UI になるまで
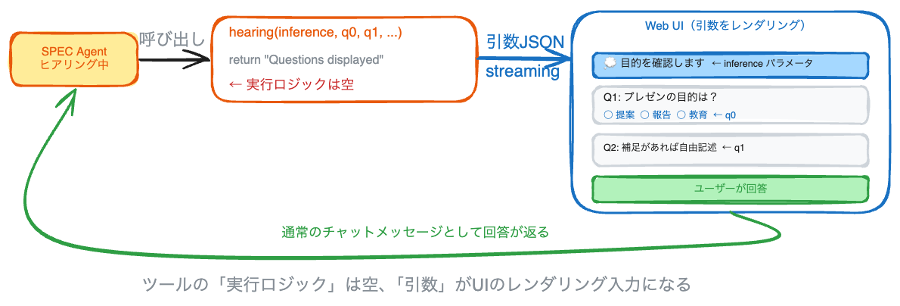
ツールが返すのは「表示しました」だけ
SDPM の SPEC エージェントは、ユーザーにヒアリングを行う際に hearing というツールを使います。このツールのコードを見ると、驚くほどシンプルです。
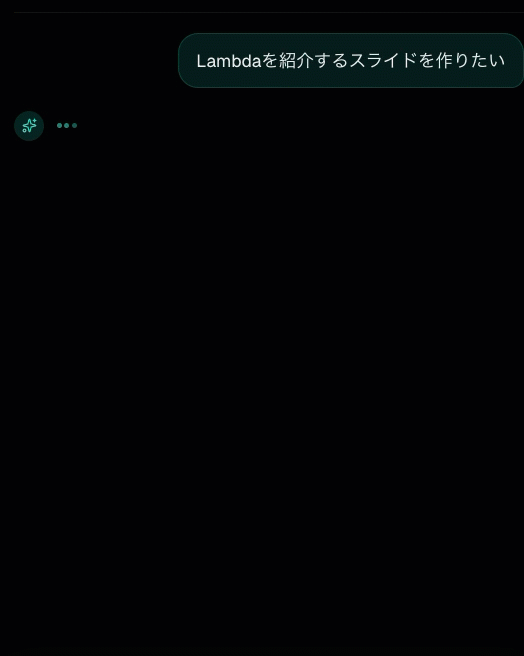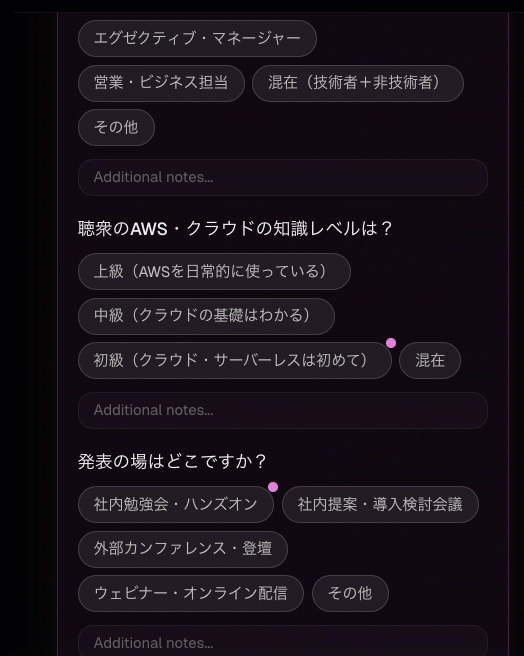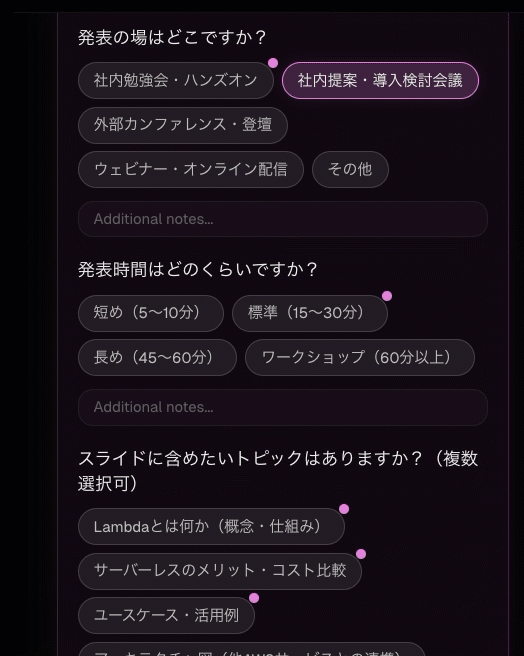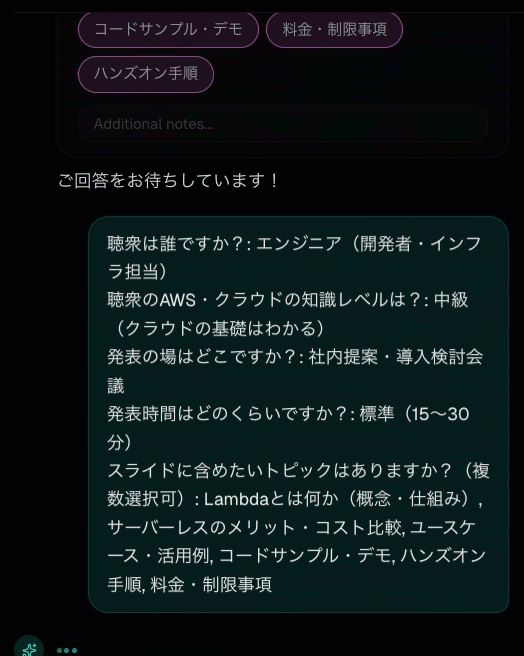
agent/tools/hearing_tool.py
@tool
def hearing (
inference: str,
q0: dict,
q1: dict = None,
q2: dict = None,
q3: dict = None,
q4: dict = None,
) -> str:
"""Present structured questions to the user via a rich UI card."""
return "Questions displayed to user. Wait for their response."動作の流れ
ツール本体は文字通り何もしません。引数を受け取り、「質問を表示しました。ユーザーの回答を待ってください」という文字列を返すだけです。
では何が起きているのか。ポイントは、ツールコールの引数そのものが Web UI のレンダリング入力になっていることです。エージェントがこのツールを呼ぶと、ツール呼び出しの JSON (inference や q0〜q4 の内容) が Web UI のストリーミングで送信されます。Web UI はその JSON をパースして、選択式・自由記述式の質問カードとして描画します。ユーザーが回答すると、その内容が通常のチャットメッセージとしてエージェントに返されます。
「何もしないフィールド」から「何もしないツール」へ
この設計には前段がありました。SDPM の MCP サーバーには run_python (コードインタープリター) というツールがあり、そこに purpose というフィールドが存在します。このフィールドに何を書いてもコードの実行には影響しませんが、Web UI に「何のために Python を実行しているか」が表示されます。
「何もしないフィールド」が UI 表示に有用だと分かったことで、「では何もしないツール全体を作ったらどうか」という発想に至りました。
ストリーミングと引数設計の工夫
hearing ツールの引数設計にも試行錯誤がありました。当初、質問を questions: [...] というリスト形式で定義していました。しかし、LLM が extended thinking (拡張思考) で全体の質問リストを考えてから一気に送信するため、ユーザーは 20 秒近く待たされることがありました。
そこで、引数を q0, q1, q2... と独立したパラメータに分離しました。Claude の extended thinking (拡張思考) ではパラメータを順番に生成するため、inference が完成した時点でそれが表示され、q0 が完成したらそれが追加表示される——という段階的なストリーミングが実現しました。
Human-in-the-Loop をツール抽象化に組み込む
この設計を俯瞰すると、エージェントから見た hearing ツールは、人間という外部リソースにクエリを投げて結果を受け取る構造になっています。データベースに問い合わせるツールや API を呼ぶツールと、構造的には同じです。
Human-in-the-Loop (人間の介在) を MCP の「ツール」という抽象化の中に自然に組み込んだ実装と言えます。ツールの実行が完了した時点でエージェントのループは止まっていないため、ユーザーが回答しなくても直接チャットで会話を続けることもできます。
5. 「ツールの中に Code Interpreter を入れる」— 1 回のツール呼び出しに束ねる
エージェントにツールを渡すのではなく、ツールの中にエージェントの実行環境を入れる
「Code Interpreter を MCP サーバーとして公開する」という記事は多く見かけますが、SDPM ではその逆のアプローチを取っています。MCP ツールの内部から Code Interpreter を呼び出し、前後に処理を挟むという設計です。いわばファサードパターンで、バリデーション・計測・保存を 1 回のツール呼び出しに束ねています。
通常、エージェントが「ファイルを書き込む → バリデーションする → 計測する → プレビューを生成する」という一連の作業を行うには、複数のツール呼び出しが必要です。しかし SDPM の run_python ツールは、これを 1 回の呼び出しで完結させます。エージェントから見たツール呼び出し回数が減ることで、推論の安定性が向上します。
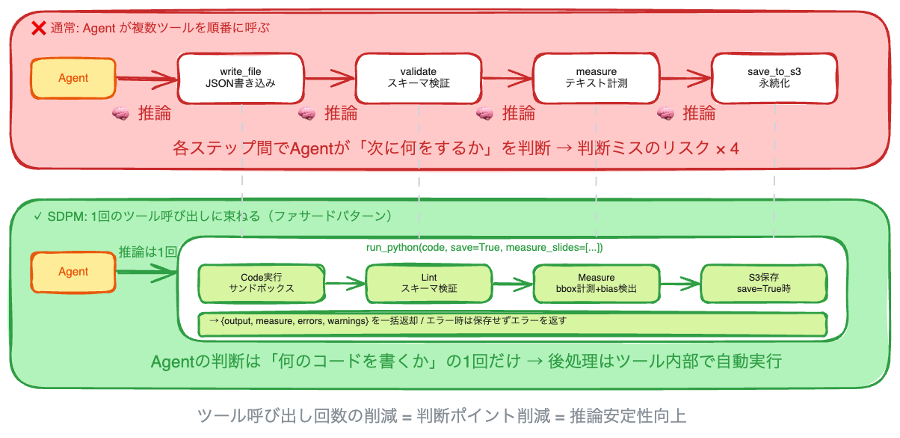
mcp-server/server.py — run_python ツールの定義 (抜粋)
@mcp.tool ()
def run_python (purpose: str, code: str, deck_id: str | None = None, save: bool = False,
files: list[str] | None = None, measure_slides: list[str] | None = None) -> str:
"""Execute Python code in a secure sandbox.
If deck_id is provided, the entire deck workspace is loaded as files:
slides/{slug}.json — per-slide data (read/write via json.load/json.dump)
specs/brief.md — briefing document
attachments/ — imported files via import_attachment
If save=True, all modified/new workspace files are written back to S3.
Always specify measure_slides when editing slides. Runs validation after
code execution: text bbox measurement, lint diagnostics, layout bias detection.
"""
# purpose: UI に表示されるだけで実行には影響しない「何もしないフィールド」
# code: サンドボックス内で実行される Python コード
# save=True: 実行後にバリデーション → S3 に永続化
# measure_slides: 指定スラッグの計測 + プレビュー生成を後処理で実行
...ツールが Code Interpreter を内包することで、いくつかの利点が生まれます。エージェントが書いた JSON が不正であれば保存せずにエラーを返せる。計測結果やプレビュー画像を同じレスポンスに含められる。Amazon S3 からのデータ取得もツール側が行い、サンドボックス内に配置してから Code Interpreter を実行するため、エージェントがストレージを直接操作する必要がない。
purpose パラメータは、セクション 4 で述べた「何もしないフィールド」です。
タイムバジェットとソフトストップ —— フック機構による並列エージェントの制御
並列エージェントのもう一つの課題は、一部のエージェントがスライドの推敲に時間をかけすぎて全体の完了を遅らせることでした。 これに対して、スライド 1 枚あたり 90 秒のタイムバジェットを設定しています。
# agent/modes/separated/composer.py
BUDGET_PROMPT = (
"Time budget reached. If any assigned slides are still unwritten, "
"finish them with a rough-but-coherent draft. "
"Do NOT polish slides that are already written — stop measuring and refining. ..."
)
async def _after_tool (event: AfterToolCallEvent) :
if time.time () > deadline:
budget_nudge_count += 1
if budget_nudge_count == 1 or budget_nudge_count % 3 == 0:
content = list (event.result.get ("content") or [])
content.append ({"text": f"\n\n[Budget notice] {BUDGET_PROMPT}"})
event.result = {**event.result, "content": content}ツール呼び出しをユーザーの操作によってキャンセル
前述の Strands Agents のフック機構を利用し、ツール呼び出しが完了するたびに経過時間をチェックします。バジェットを超えていれば、ツールの結果に「未完成のスライドがあれば粗くてもいいので仕上げてください」というメッセージを追加します。LLM への指示はあくまで「お願い」ですが、ツール結果の中に自然に挿入されるため、エージェントはこれを無視しにくくなります。 ユーザーがキャンセルボタンを押した場合は、_before_tool フックでツール実行前に介入します。
STOP_PROMPT = (
"Operation cancelled by the user. Do not retry. "
"Stop invoking tools and respond with a brief plain-text summary of "
"what was completed, what was in progress, and any context useful for resuming later."
)
async def _before_tool (event: BeforeToolCallEvent) :
if _is_compose_stopped (parent_tool_use_id) :
event.cancel_tool = STOP_PROMPTここで注意すべき点があります。STOP_PROMPT の文言設計には工夫が必要でした。ツール出力に含めるメッセージの文言は、モデルの挙動に影響を与えます。特定のマーカーや表現パターンを使うと、モデルがそのメッセージを無視することがあるため、ツールレイヤーからの通常のメッセージとして自然な文言にすることで、エージェントが確実に従うようにしています。
タイムバジェット、ソフトストップ、連続エラー検知——これらの制御層は、いずれも LLM のツール呼び出しフックを利用して、エージェントの自律的な判断を外部から誘導するという共通のパターンに基づいています。
なお、一部の Composer が失敗しても他の Composer の成果は保持されます。失敗したスライドだけを再実行できるため、30 枚中 2 枚が失敗しても最初からやり直す必要はありません。
おわりに
本記事で紹介した設計判断から得られた教訓を挙げます。
- 並列化には共有コンテキストが不可欠。
仕様ファイルという共通の参照点があるからこそ、独立に動く複数のエージェントが一貫した成果物を生み出せました。 - 巨大なデータは全部渡さず、インデックスだけ渡してエージェントに選ばせる。
人間が資料を流し読みするのと同じ動きを、ページネーションと画像メタデータで実現しました。 - エージェントに知識を渡すときは、知識そのものではなく取得方法を教える。
システムプロンプトに書くよりも、ツール呼び出しの体験として渡す方が、以降の行動の再現性が高まりました。 - ツールの実行ロジックと引数は別々の役割を持てる。
「何もしないツール」の引数が UI のレンダリング入力になるように、ツールコールの構造自体をインターフェースとして活用できました。 - ツールの粒度はエージェントの推論安定性に直結する。
複数の処理を 1 つのツールに束ねることで、エージェントの判断ポイントが減り、安定した出力が得られました。
筆者/開発者プロフィール

片岡 翔太郎 (Shotaro Kataoka)
アマゾン ウェブ サービス ジャパン合同会社
ソリューションアーキテクト
本アセットの設計・開発を担当AI/ML関連で博士号取得後 2025 年に入社した SA。最近初めての娘が生まれ、家では常に抱っこをしている。業務効率化ツールの開発が趣味で、Kiro CLI を片手にいつも何かを作っている。

吉川 直仁 (Naohito Yoshikawa)
アマゾン ウェブ サービス ジャパン合同会社
ソリューションアーキテクト
本アセットの設計・開発を担当
大学で AI/ML の研究を行い、昨年 (2025/04) SA として新卒入社。Kiro CLI で仕事を効率的にしようとするも、何かを作り続けているので結局忙しい。

岡本 晋太朗 (Shintaro Okamoto)
アマゾン ウェブ サービス ジャパン合同会社
ソリューションアーキテクト
本アセットの設計・開発を担当
育休から復帰後、生成 AI の進化をキャッチアップ中。今年の目標は家事を技術で楽にすること。Kiro はかわいいので IDE 推しだったが、最近は CLI も愛用。