進化し続ける Kiro の仕様駆動開発を一度立ち止まって整理する
2026-06-02 | Author : 稲田 大陸 (いなりく)

はじめに
こんにちは ! ソリューションアーキテクトの いなりく です !
みなさんは、AI コーディングエージェントを使っていて「指示通りに書いてくれたのに、なぜか期待と違うコードが出てきた」という経験はありませんか ? チャットで指示を出してコードを生成するスタイルは手軽で直感的ですが、機能の規模が大きくなるほど「伝言ゲーム」のようにズレが蓄積していきます。
この問題の根本原因は、多くの場合コードではなく「仕様」にあります。要件が曖昧なまま AI にコードを書かせると、AI は曖昧さを「推測」で埋めます。その推測が正しいかどうかは運次第です。
Kiro が提唱する Spec-Driven Development (SDD) は、この課題に正面から向き合うアプローチです。「まず仕様を固め、その仕様に基づいてコードを書く」当たり前のことのように聞こえますが、AI エージェントの力を借りることで、この「当たり前」を驚くほど低コストで実践できるようになりました。
本記事では、Kiro の SDD がどのような仕組みで成り立っているのか、その全体像を俯瞰し、開発シナリオに応じてどの機能をどう使い分けるべきかを整理します。なお、Kiro をこれから導入する方は「Kiro 導入ガイド:始める前に知っておくべきすべてのこと」も合わせてご覧ください。
builders.flash メールメンバー登録
builders.flash メールメンバー登録で、毎月の最新アップデート情報とともに、AWS を無料でお試しいただけるクレジットコードを受け取ることができます。
Spec-Driven Development (SDD) とは
SDD は、AI エージェントによるコード生成の前に 構造化された仕様 (Spec) を作成し、その仕様をもとに実装を進める開発手法です。 Kiro では、Spec は以下の 3 つの成果物で構成されます。
3 つの成果物
|
ファイル
|
役割り
|
含まれる内容
|
|---|---|---|
|
requirements.md
|
何を作るか |
ユーザーストーリー、受け入れ基準 (EARS 記法) |
|
design.md
|
どう作るか |
システムアーキテクチャ、シーケンス図、エラーハンドリング戦略 |
|
tasks.md
|
どの順序で作るか |
実装タスクのリスト、依存関係、進捗状態 |
Spec Driven Development のフロー
この 3 つは .kiro/specs/ディレクトリ配下に Spec ごとに生成されます。ポイントは、これらが単なるドキュメントではなく、Kiro が実装時に参照し続ける「実行可能な仕様」 であるという点です。タスクを実行するとき、Kiro は requirements.md の受け入れ基準を満たしているか、design.md のアーキテクチャに沿っているかを常に意識しながらコードを書きます。
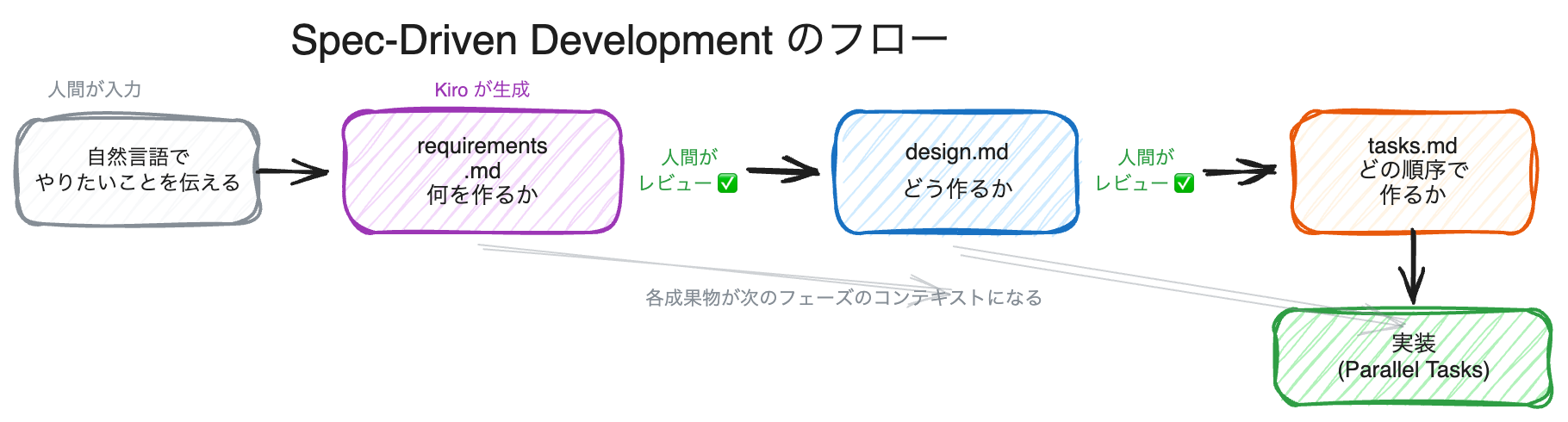
1 つの Spec のスコープ感
「1 Spec でどのくらいの範囲をカバーするのか ?」は、SDD を始めるにあたって最初に迷うポイントです。私の経験から、うまく機能する Spec のスコープには以下のような傾向があります。
適切なスコープ
- アプリケーションの中の 1 つの独立した機能単位 (例 : 認証システム、通知サービス、レビュー UI)
- requirements.md の Requirement 数は 7〜10 個 程度
- 各 Requirement に紐づく受け入れ基準は 3〜7 個
- tasks.md のメインタスクは 10〜14 個、サブタスク含めると 30〜40 項目
スコープが大きすぎるサイン
- Requirement が 15 個を超える
- 複数の独立した画面やエンドポイントにまたがる* 「このSpec、何の機能だっけ ?」と一言で説明できない
スコープが大きすぎる場合は、Spec を分割しましょう。「ユーザー認証」と「権限管理」を 1 つの Spec に詰め込むのではなく、それぞれ独立した Spec として扱うほうが、requirements.md のレビューも tasks.md の並列実行も効率的になります。
なぜ 3 つに分かれているのか
従来の開発でも「要件定義 → 設計 → 実装」というフェーズは存在します。SDD がユニークなのは、この 3 フェーズを AI が高速に生成・検証し、人間はレビューと意思決定に集中できる点です。
- requirements.md で「何を作るか」に合意する → スコープの膨張を防ぐ
- design.md で「どう作るか」に合意する → 実装後の大幅な手戻りを防ぐ
- tasks.md で「どの順序で作るか」を決める → 並列実行と進捗追跡が可能になる
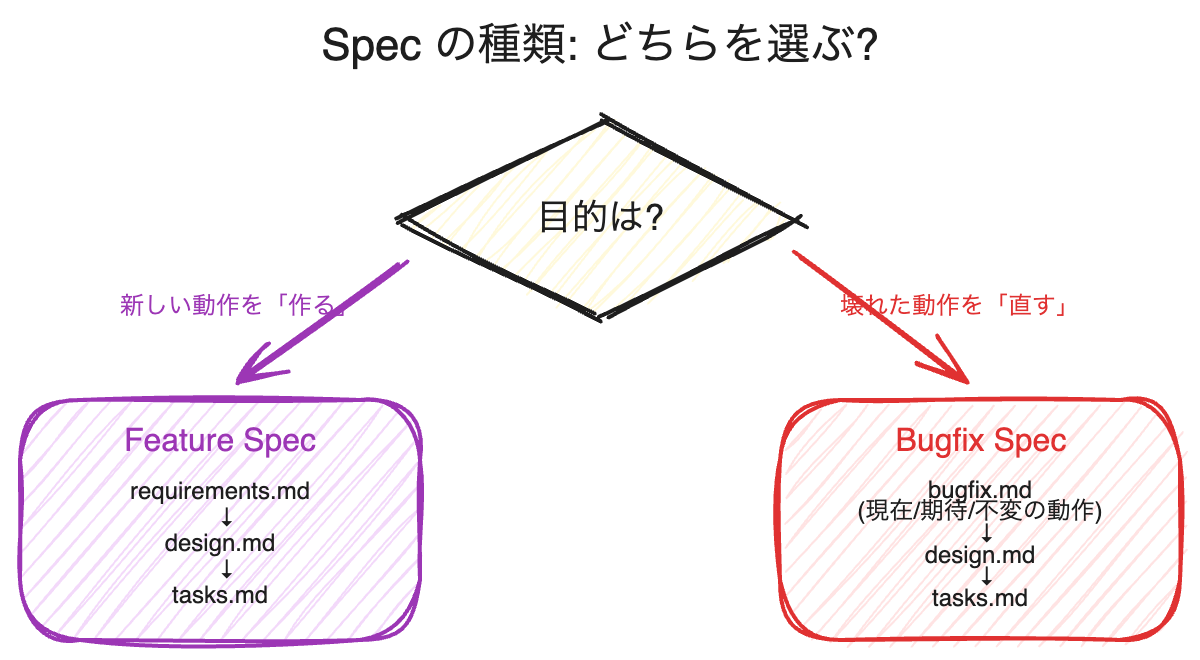
Spec の種類
Kiro は、開発の目的に応じて 2 種類の Spec を提供しています。
Feature Spec — 新機能を作るとき
新しい機能やケイパビリティを追加する場合に使います。requirements.md → design.md → tasks.md の順に成果物を生成し、各フェーズで人間のレビュー・承認を挟みます。
Feature Spec には、さらに 3 つのワークフローバリエーションがあります (後述) 。
Bugfix Spec — バグを直すとき
既存のバグを修正する場合に使います。Feature Spec とは異なり、最初のフェーズで生成されるのは requirements.md ではなく bugfix.md です。
ります。bugfix.md には以下が整理されます。
- 現在の動作 (Current Behavior) : 何が起きているか
- 期待する動作 (Expected Behavior) : 本来どうあるべきか
- 変更してはいけない動作 (Unchanged Behavior) : 修正の影響範囲外として保護すべきもの
この「変更してはいけない動作」の明示が重要です。バグ修正で別の箇所が壊れる ― いわゆるデグレーションは、「何を変えるか」だけでなく「何を変えないか」が曖昧なときに起こります。Bugfix Spec はこのリスクを構造的に軽減します。
どちらを選ぶか
判断は単純です。
- 既存の動作が「壊れている」→ Bugfix Spec
- まだ存在しない動作を「作る」→ Feature Spec
迷うのは「既存機能の改善」のケースですが、その場合は Feature Spec を使い、requirements.md に「既存動作を維持する」旨の受け入れ基準を含めるのがおすすめです。
Feature Spec のワークフロー: 3 つのバリエーション
Feature Spec を作成する際、Kiro は開発の状況に応じて 3 つのワークフローを提供しています。ここが使い分けの最も重要なポイントです。
1. Requirements-First (要件先行)
向いている場面 :
- 「何を作りたいか」はぼんやりあるが、具体的な要件がまだ固まっていない
- ステークホルダーとの合意形成が必要
- スコープを慎重にコントロールしたい
流れ :
- 自然言語でやりたいことを伝える
- Kiro が requirements.md を生成 (ユーザーストーリー + 受け入れ基準)
- 人間がレビュー・修正・承認 ✅
- Kiro が design.md を生成
- 人間がレビュー・修正・承認 ✅
- Kiro が tasks.md を生成
- タスクを実行
各フェーズに 承認ゲート があるため、方向性のズレを早期に修正できます。「急がば回れ」型のワークフローです。
2. Design-First (設計先行)
向いている場面 :
- 要件はすでに明確 (外部の仕様書やチケットに書かれている)
- アーキテクチャの検討から始めたい
- 技術的な制約条件を先に整理したい
流れ :
- 要件や制約を Kiro に伝える
- Kiro が design.md を先に生成 (アーキテクチャ、コンポーネント設計)
- 人間がレビュー・修正・承認
- design.md に基づいて requirements.md を逆生成
- Kiro が tasks.md を生成
- タスクを実行
「要件は分かっているが、どう実現するかの技術検討が必要」というケースで効果的です。既存システムへの機能追加や、技術的負債の解消で重宝します。
3. Quick Plan (一括生成)
向いている場面 :
- スコープが明確で小さい
- 1 人で完結する作業
- 承認ゲートを挟む必要がない (自分で判断できる)
- とにかく速く実装に入りたい
流れ :
- やりたいことを Kiro に伝える
- Kiro が明確化のための質問をいくつか投げる (スコープ、制約、エッジケース)
- 回答すると、requirements.md → design.md → tasks.md を一括生成
- タスクリストに直接到着、すぐに実行可能
承認ゲートが無いため、Spec の生成にかかる時間が大幅に短縮されます。ただし、各成果物の中間レビューを省略しているため、規模の大きい機能や複数人での開発には不向きです。
ワークフロー選択の判断チャート
Quick Plan が生成した Spec のタスク数が想定を超えて膨らんだ場合は、無理にそのまま実行するのではなく、Requirements-First に切り替えて各フェーズをレビューするほうが安全です。
規模感の目安
|
ワークフロー
|
想定タスク数
|
想定 Requirement 数
|
|---|---|---|
|
Requirements-First
|
10〜14+ |
7〜10+ |
|
Design-First
|
6〜14 |
5〜10 |
|
Quick Plan
|
3〜6 |
3〜5 |
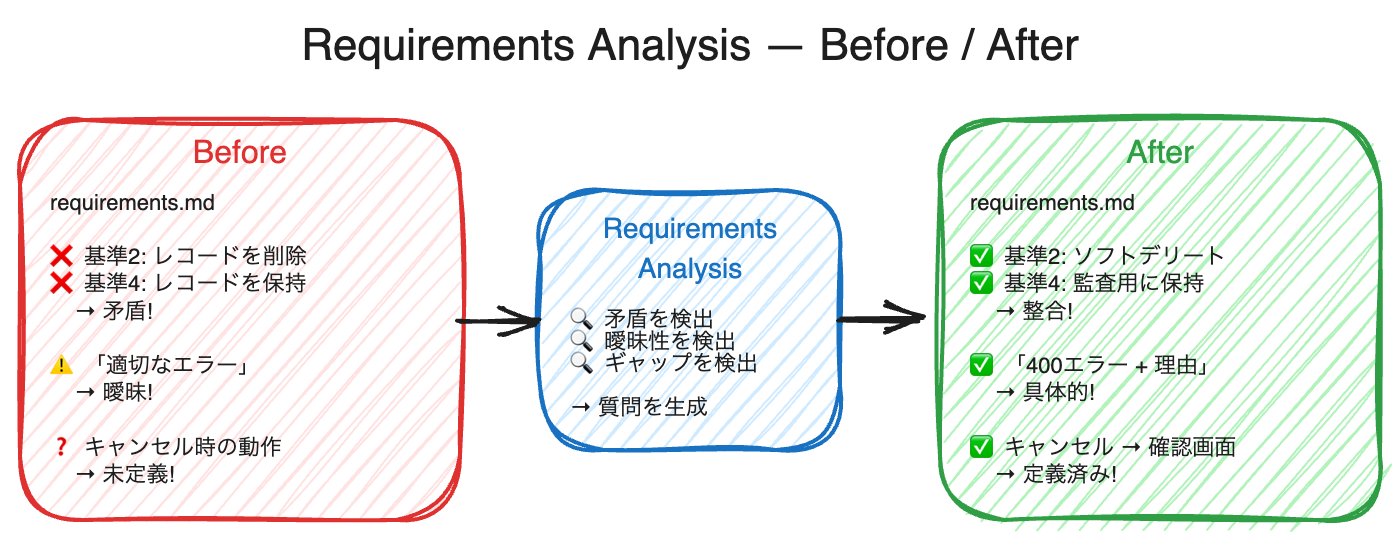
Requirements Analysis — 仕様の「バグ」を実装前に潰す
Spec を作成したら、すぐに実装に入りたくなるものです。しかし、requirements.md に書かれた受け入れ基準自体に問題が潜んでいたらどうでしょうか。
Kiro の Requirements Analysis は、受け入れ基準を自動推論エンジンで分析し、以下の 3 種類の「仕様バグ」を検出します。
検出される仕様バグの種類
|
種類
|
説明
|
例
|
|---|---|---|
|
矛盾 (Contradiction)
|
2 つの基準が互いに矛盾している |
「レコードを削除する」と「監査のためレコードを保持する」が同時に存在 |
|
曖昧性 (Ambiguity)
|
実装方法の解釈が複数ある |
「適切なエラーメッセージを表示する」 (何が「適切」か不明) |
|
完全性ギャップ (Completeness Gap)
|
どの基準にも該当しないシナリオが存在 |
正常系と異常系は定義されているが、キャンセル時の動作が未定義 |
分析の流れ
分析結果はチャット上に明確化のための質問として表示されます。開発者はその質問に答えるだけで、requirements.md が修正・補完されます。
いつ使うべきか
- Feature Spec を作成した 直後 (タスク実行前)
- レビューで「この要件、解釈が分かれそうだな」と感じたとき* 複数人で開発する機能の受け入れ基準を固めるとき
Requirements Analysis は「保険」のようなものです。小さな Spec では不要に感じることもありますが、Requirement が 5 個を超え、受け入れ基準が合計 20 個以上あるような規模の Spec では、人間のレビューだけで矛盾や漏れを発見するのは困難です。特に、受け入れ基準が EARS 記法 (WHEN ... THEN ... SHALL ...) で厳密に書かれている場合、基準同士の論理的な整合性は機械的な検証に向いています。実装後の手戻りコストを考えると、実行する価値は十分にあります。
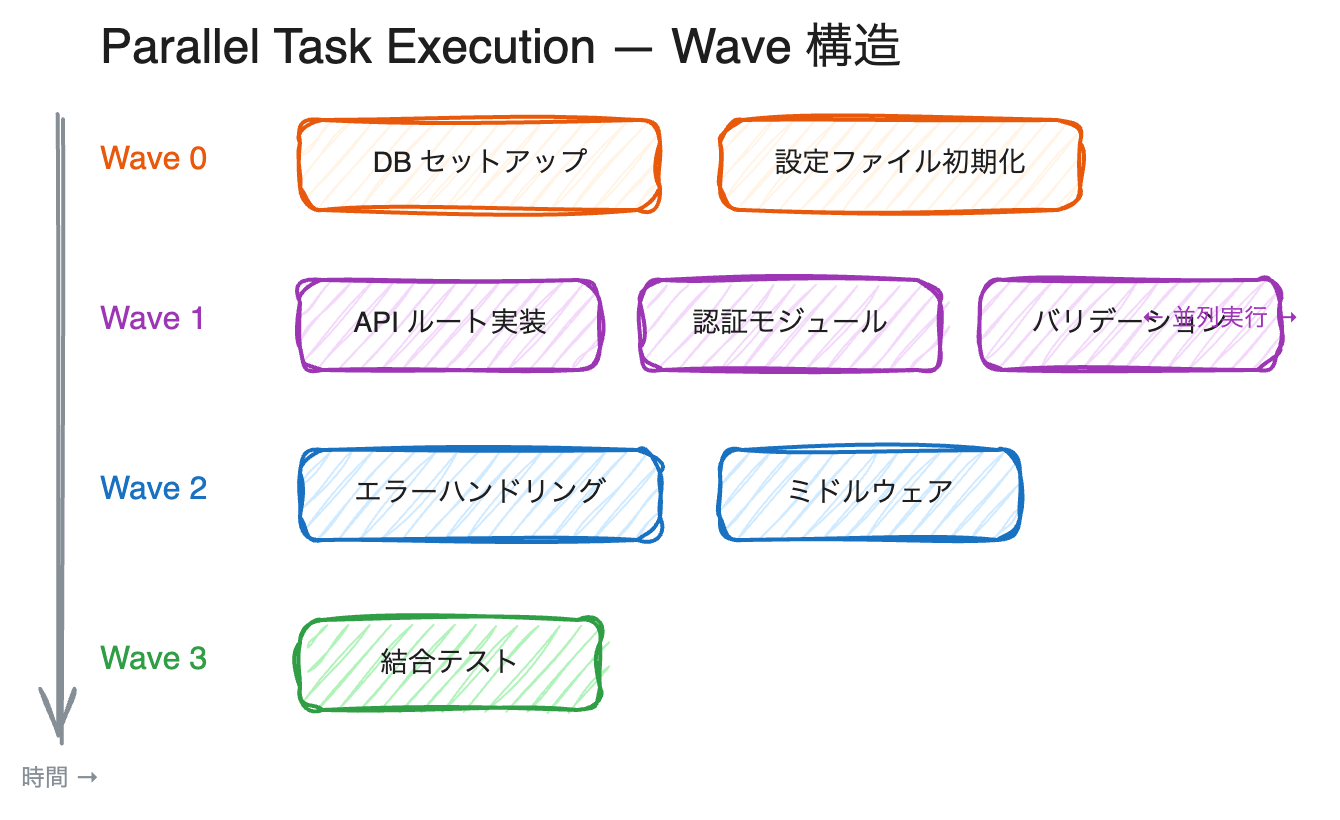
Parallel Task Execution — 依存関係を読み取り並列で実装する
tasks.md のタスクをすべて実行する「Run all Tasks」をクリックしたとき、Kiro はタスクを上から順番に実行するのではなく、依存関係を分析して並列実行可能なタスクをグルーピングします。
仕組み
- タスクリストから依存関係グラフを構築
- 同じファイルに書き込むタスクは同じ Wave に入れない
- テストはテスト対象コードの後に配置
- セットアップ・インフラ系のタスクを最初の Wave に配置
- 独立したタスクを Wave (波) としてグルーピングし、Wave 内は並列実行
各タスクは独立したコンテキストで実行されるため、あるタスクの失敗が他のタスクに波及しません。失敗したタスクだけを確認し、残りは正常に完了するという堅牢な設計です。
効果
- 4 つ以上の独立タスクがある Spec で最大 4 倍の高速化
- 設定不要。「Run all Tasks」を押すだけで Kiro が自動判断
- 大規模な Feature Spec (タスク 8〜10 個) で特に効果を実感
Parallel Task Execution を活かすコツ
Parallel Task Execution の効果を最大化するには、tasks.md の構造 (≒ Spec 生成時のプロンプトの伝え方) が重要です。
タスク粒度の目安
- 1 タスク = 1 ファイル or 1 コンポーネント程度
- 「全部入り」のタスクを避ける (1 つのタスクに API + UI + テストを詰め込まない)
- テストタスクは実装タスクと分離し、依存関係を明示する
効果が大きい tasks.md の構造
メインタスクが 10〜14 個ある規模の Spec では、Wave が 3〜4 段に分かれ、中間の Wave で 3〜4 タスクが並列に走ります (上図参照) 。
トレーサビリティの活用
各タスクに「どの Requirement を満たすか」の紐づけがあると、タスク実行時に Kiro がより正確に受け入れ基準を意識したコードを書きます。Kiro が自動生成する tasks.md にはこの紐づけが含まれるため、手動で追加する必要はありませんが、レビュー時に「このタスクが失敗したらどの要件が満たされないか」を追跡できる利点があります。
Quick Plan との相性
Quick Plan で一括生成された tasks.md でも Parallel Task Execution は自動で動作します。ただし、Quick Plan はスコープが小さい前提で使うため、タスク数が 3〜4 個に収まることが多く、並列化の恩恵は限定的です。タスクが 6 個以上生成された場合は、Requirements-First や Design-First で丁寧に Spec を作ったほうが、結果的に速く・正確に実装が完了することが多いです。
シナリオ別 : SDD 機能の使い分けまとめ
最後に、よくある開発シナリオごとに「どの Spec 種類」「どのワークフロー」「どの追加機能を使うか」を整理します。
|
シナリオ
|
Spec 種類
|
ワークフロー
|
Requirements Analysis
|
Parallel Tasks
|
|---|---|---|---|---|
|
新規機能 (大規模、チーム開発)
|
Feature |
Requirements-First |
✅ 推奨 |
✅ 効果大 |
|
新規機能 (中規模、個人開発)
|
Feature |
Design-First or Quick Plan |
△ 任意 |
✅ 効果あり |
|
小さな機能追加・改善
|
Feature |
Quick Plan |
△ 不要なことが多い |
△ タスク数次第 |
|
バグ修正
|
Bugfix |
— (固定) |
— |
△ タスク数次第 |
|
技術的負債の解消・リファクタリング
|
Feature |
Design-First |
△ 任意 |
✅ 効果あり |
|
PoC・プロトタイプ
|
Feature |
Quick Plan |
✗ 不要 |
△ タスク数次第 |
AI-DLC との関連
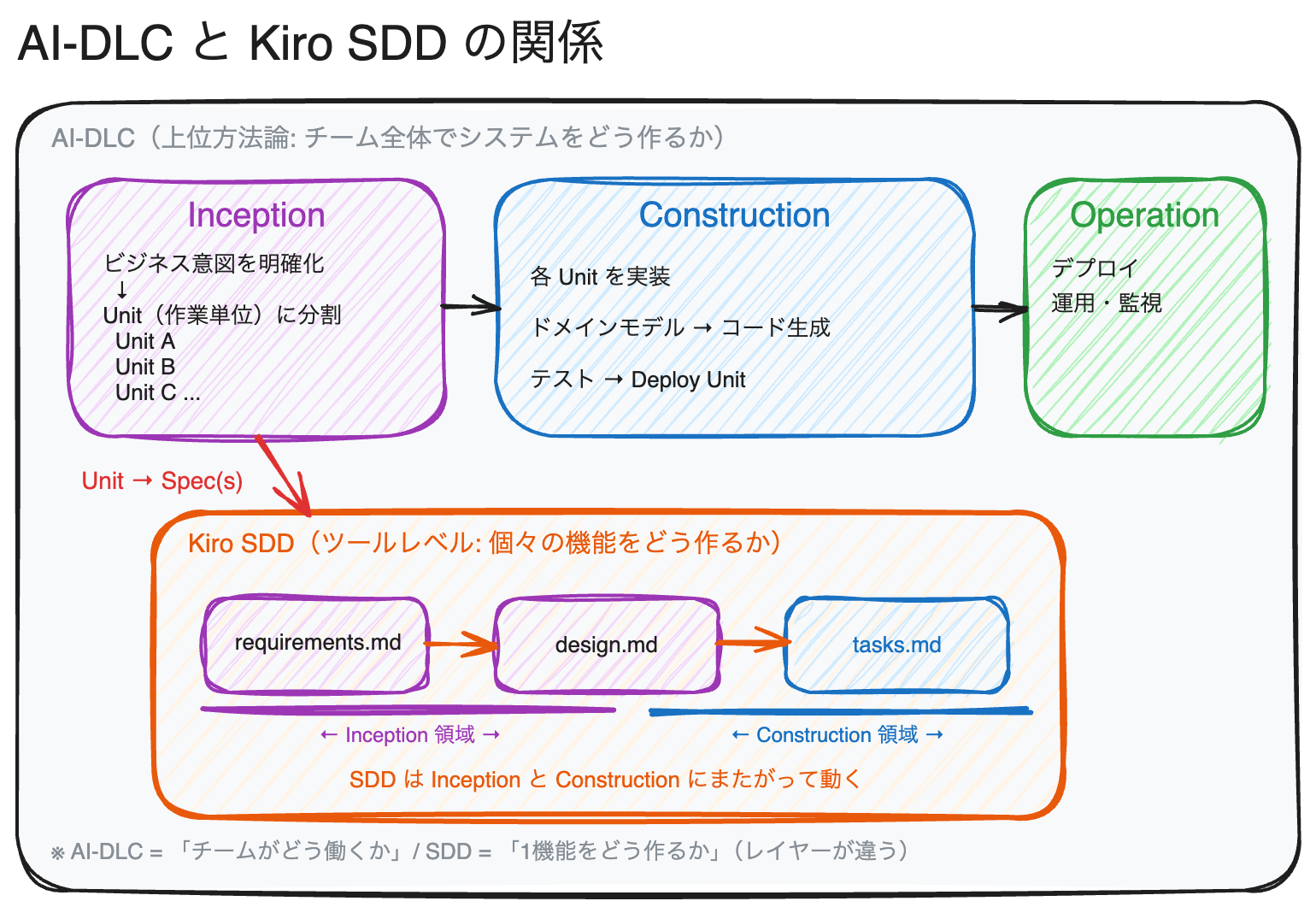
私が推進している AI 駆動開発ライフサイクル (AI-DLC) では、開発を Inception (開始) → Construction (構築) → Operation (運用) の 3 フェーズで捉えます。AI-DLC は大規模なシステムを構築するために、チームがどう働くか ― ツール・役割を整合させることを目的として設計された上位の方法論です。
AI-DLC の各フェーズでは、それぞれ以下のステップを踏みます。各ステージが次のステージのためにコンテキストを構築していく点が特徴です。
SDD の位置づけ: AI-DLC とはレイヤーが違う
Kiro の SDD は AI-DLC と同じレイヤーの話ではありません。 AI-DLC が「チーム全体でシステムをどう作るか」の方法論であるのに対し、SDD は「個々の機能をどう作るか」を支援するツールレベルの仕組みです。仕様とコードの乖離を防ぐことが SDD の役割です。
対応関係
AI-DLC の Inception フェーズでは、ビジネス意図を出発点に以下のステップを踏みます。
1. 既存コードのコンテキストを構築する
2. ユーザーストーリーで意図を詳細化する
3. 作業単位 (Units of work) で計画する
Inception で生まれた Unit (作業単位) が、Kiro の Spec の入力になります。Unit のスコープが大きい場合は複数の Spec に分割しますし、小さければ 1 Unit = 1 Spec でそのまま進められます。Inception がシステム全体を俯瞰して「何を作るべきか」を Unit に分解するフェーズだとすれば、Spec はその Unit を Construction フェーズで仕様とコードを乖離させずに実装するためのガードレールです。
各ステージが次のステージのためにコンテキストを構築するという AI-DLC の原則は、SDD の中でも同じ構造で再現されています。requirements.md が design.md のコンテキストになり、design.md が tasks.md のコンテキストになる。この「コンテキストの連鎖」により、AI は仕様から逸脱しにくくなります。
Next Action
ハーネスは最初から完璧に作る必要はありません。シンプルな構成から始めて、必要に応じて複雑さを増していくのが鉄則です。
- まず 2 体から始める
Kiro CLI で /agent create して、planner + generator の 2 エージェント構成を作る。planner に仕様を書かせ、generator が実装する最小構成からはじめましょう。 - evaluator を追加する :
qa エージェントを作り、プロジェクトの型チェックとリンターを自動実行させるようにしましょう。これだけで「自己評価の甘さ」問題の大部分が解消するかと思います。 - ライブ検証を入れる :
playwright-cli スキルを qa に組み込んで、UI を実際に操作させる。静的チェックでは見つからないバグも見つけられるようにしましょう。 - 定期的に見直す:
モデルが更新されたらハーネスの各部品を 1 つずつ外して、まだ必要か確認しましょう。不要になったものは削り、新しい可能性を探ってみましょう。
筆者プロフィール
稲田 大陸 (いなりく / @inada_riku)
アマゾン ウェブ サービス ジャパン合同会社
ソリューションアーキテクト
AWS Japan で働く筋トレが趣味のソリューションアーキテクト。製造業のお客様を支援させていただいています。最近は AI 駆動開発ライフサイクル (AI-DLC) の日本のお客様への布教活動もしつつ、Kiro のブログなどを執筆しています。
