AI エージェントに DJ と VJ パフォーマンスをさせてみた。
2026-07-02 | Author : 深澤 真愛、菊地 泰斗、片岡 翔太郎

はじめに
今年の AWS Summit Japan 2026 の Builders Fair のブースに、少し変わったデモを出展していました。その名も DJ Agent。AI エージェントたちが、その場で音楽のコードと映像のコードを並行して書き、リアルタイムに音と絵を生み出し続ける — 誰も演奏していないし、誰も VJ (映像でライブを演出する役割) をしていないのに、音楽も映像も止まらないライブパフォーマンスです。
観客がスマホからリアクションを送ると AI がそれに応えて演奏を変え、投票では次の曲のテーマが決まります。ブースの LED 照明も AI が刻むビートに合わせて光ります。本記事では、この「AI に DJ と VJ をさせる」をどう実現したのか、その仕組みをご紹介します。
まずは実際に生成された画面をご覧ください。音楽・映像・照明が連動して変化しています。これはエージェントが視聴者への投票などをもとに、どのようなパフォーマンスをすべきかを自律的に判断して演奏や映像・リアル会場の演出を作っています。

builders.flash メールメンバー登録
builders.flash メールメンバー登録で、毎月の最新アップデート情報とともに、AWS を無料でお試しいただけるクレジットコードを受け取ることができます。
そもそもライブコーディングって?
DJ Agent のベースになっているのは、ライブコーディングというパフォーマンス手法です。普通、音楽を作るなら楽器を弾いたり作曲ソフトで打ち込んだりしますし、映像なら撮影したりアニメーションを作ったりします。ライブコーディングはそのどちらでもなく、プログラムのコードを書くことで音や映像を生み出します。たとえば「キックを 4 つ打ちで鳴らして、ハイハットを裏拍に入れて、ベースをこのパターンで重ねて」という指示をコードで書くと、リアルタイムに音が鳴り始めます。アーティストがステージ上でコードを打ち込み、観客がその画面を見ながら音楽を楽しむというパフォーマンスです。
このパフォーマンスがとにかくかっこいいのです。自分たちもやってみたくなりました。でもライブコーディングのスキルはありません。そこで思ったのが、「AI にコードを書かせたらどうなるだろう ?」という発想でした。
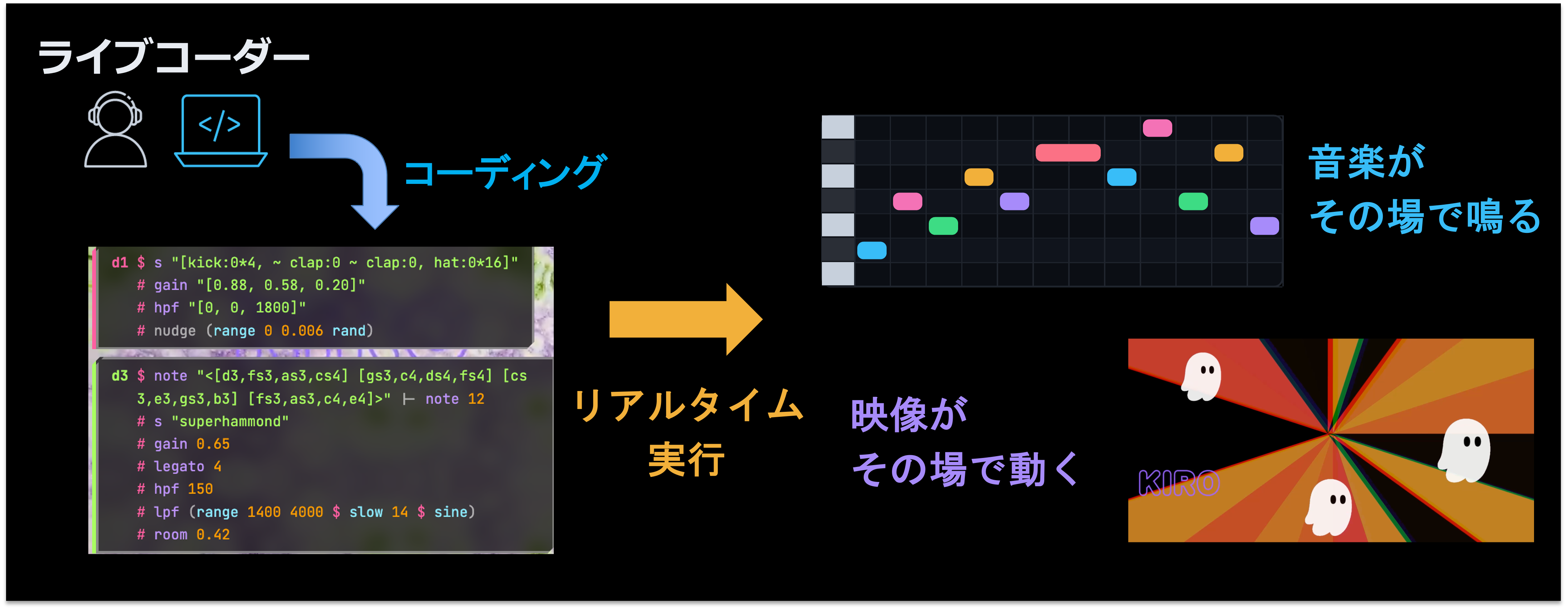
やらせてみたら、ちゃんと演奏できた。でも…
まず試しに、1 つの AI エージェントに「かっこいい曲を演奏して」と頼んでみました。結果は想像以上で、きちんと音が出ました。ドラムが鳴り、ハイハットが刻まれ、ベースが入ります。AI がその場で書いたコードが、一応は音楽の形をしています。
ただ、しばらく聴いていると物足りなく感じてきました。曲全体としての起伏がないため、盛り上がりや面白さがないのです。AI は目の前の数小節のことしか考えておらず、「このパフォーマンス全体で何を聴かせたいか」という長い視点を持っていませんでした。人間の DJ なら当たり前にやっている「曲の構成」という観点が、すっぽり抜け落ちていたのです。
アイディア:考える人と、演奏する人を分ける
そこで考え方を変えました。人間のバンドやライブイベントでは、全体の流れを構想するプロデューサーと、実際に楽器を弾くプレイヤーで役割が分かれています。プロデューサーは一曲全体もしくは数曲の流れの中での盛り上がりや構成を考え、プレイヤーは今この一音に集中します。AI も同じように役割を分ければいいのではないか——そう考えて生まれたのが、「考える層」と「演奏する層」の 2 層構成です。
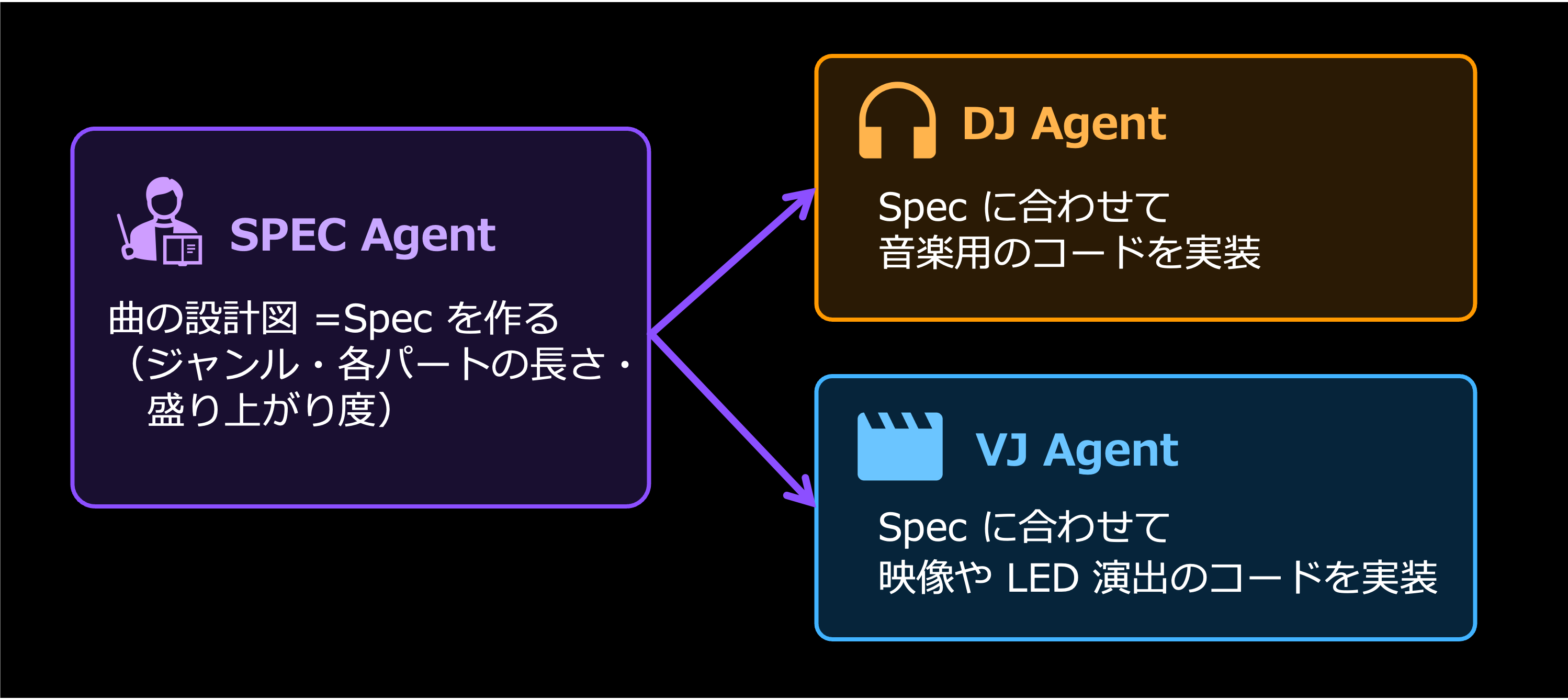
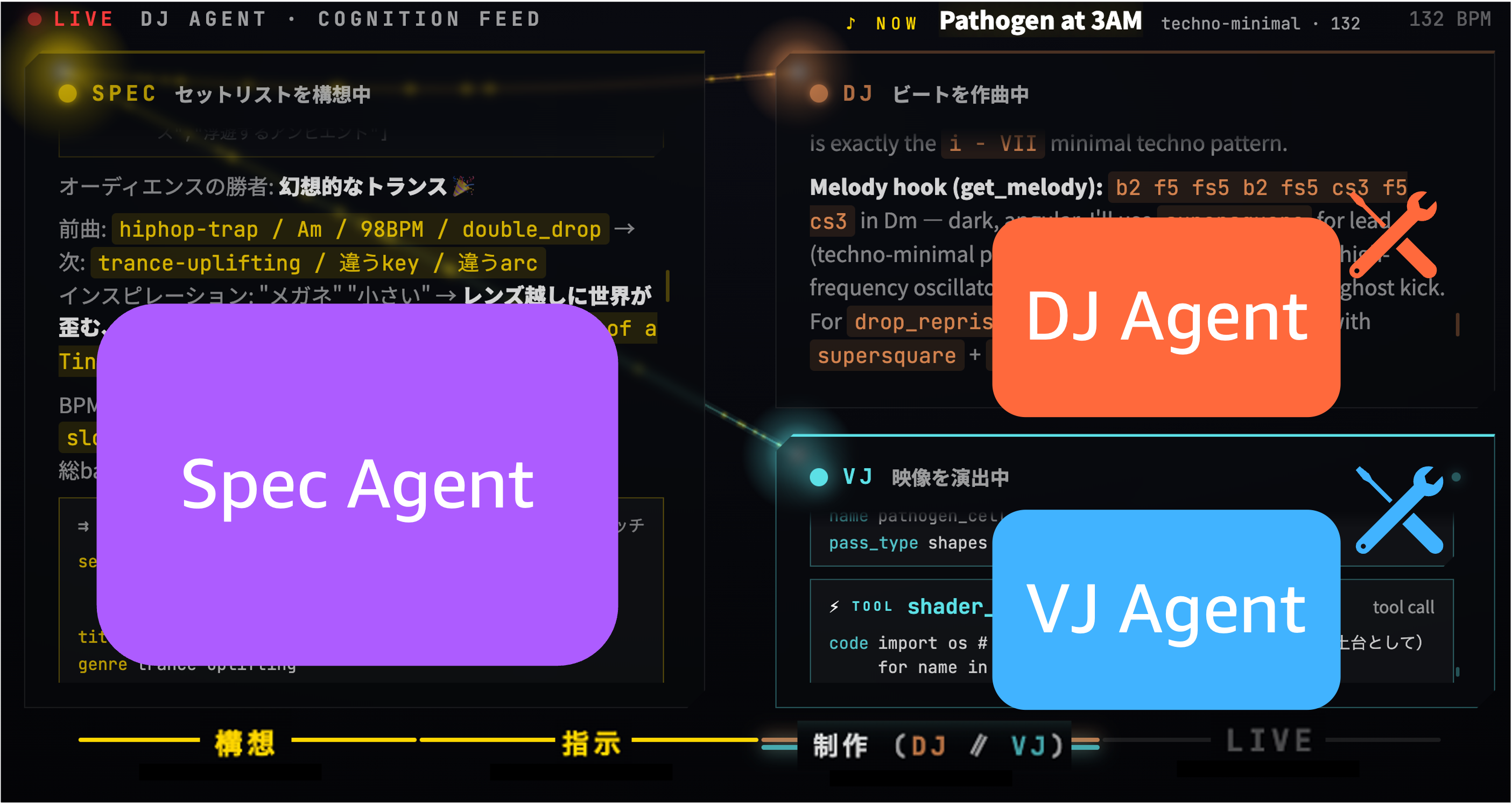
2 層のエージェント構成
2 層のエージェント構成では上位層の SPEC エージェントが曲全体のストーリーを描き、下位層の DJ と VJ がそれぞれの専門領域でそれを実現します。
- SPEC エージェント は、プロデューサーのように「今の観客はまだ温まってないから少しずつ上げよう」「次はもっと激しい曲にしよう」と曲全体のストーリーを構想し、どんなセクションをどう並べるかの曲の構成を決めます。
- DJ エージェント は、その骨格に沿って実際の音楽用のコードを書きます。
- VJ エージェント は、同じ骨格に沿って映像のコードや演出の組み合わせを書きます。
特徴的なのは、DJ エージェントと VJ エージェントはお互いの作ったものを見ないという点です。両者は SPEC エージェント から渡される同じタイトル・ジャンル・BPM・曲の構成情報をもとに、別々に音と映像を作ります。それでも同じストーリーを共有しているため、結果的に音と映像が自然と同じ世界観に揃いました。
この 2 層構成にした途端、音楽と映像は見違えるように良くなりました。静かに始まり、徐々に高まり、クライマックスで盛り上がり、また落ち着くといった、「曲」になったのです。
言ってみれば、「曲全体として良いか」という AI が判定しづらい大きな問いを SPEC エージェント が引き受けることで、DJ / VJ エージェントには「設計どおりに実装する」というもっと小さな仕事だけをさせるようにした、ということでもあります。AI が苦手な判定は、なるべくスコープを狭めてあげる ── これがこのプロジェクト全体の基本方針になりました。
ただし、これで「AI に DJ をさせる」問題がすべて片付いたわけではありません。「曲の構成」の課題は解決しましたが、高品質な曲や映像の生成には複数の壁が存在しました。
AI の課題:「良し悪し」が判定できない AI をどう制御したか
AIは音楽や映像を「生成」できますが、生成したものが良いかどうかを自分では判定できません。 ジャンルらしさ、メロディのフック、配色の組み合わせ、壊れた出力。こういった問題に次々と直面し、その度に「AI に任せる範囲」と「機械的に縛る範囲」を設計で分ける作業を続けることになりました。ここからは特に苦労した 5 つの壁をご紹介します。
5 つの壁
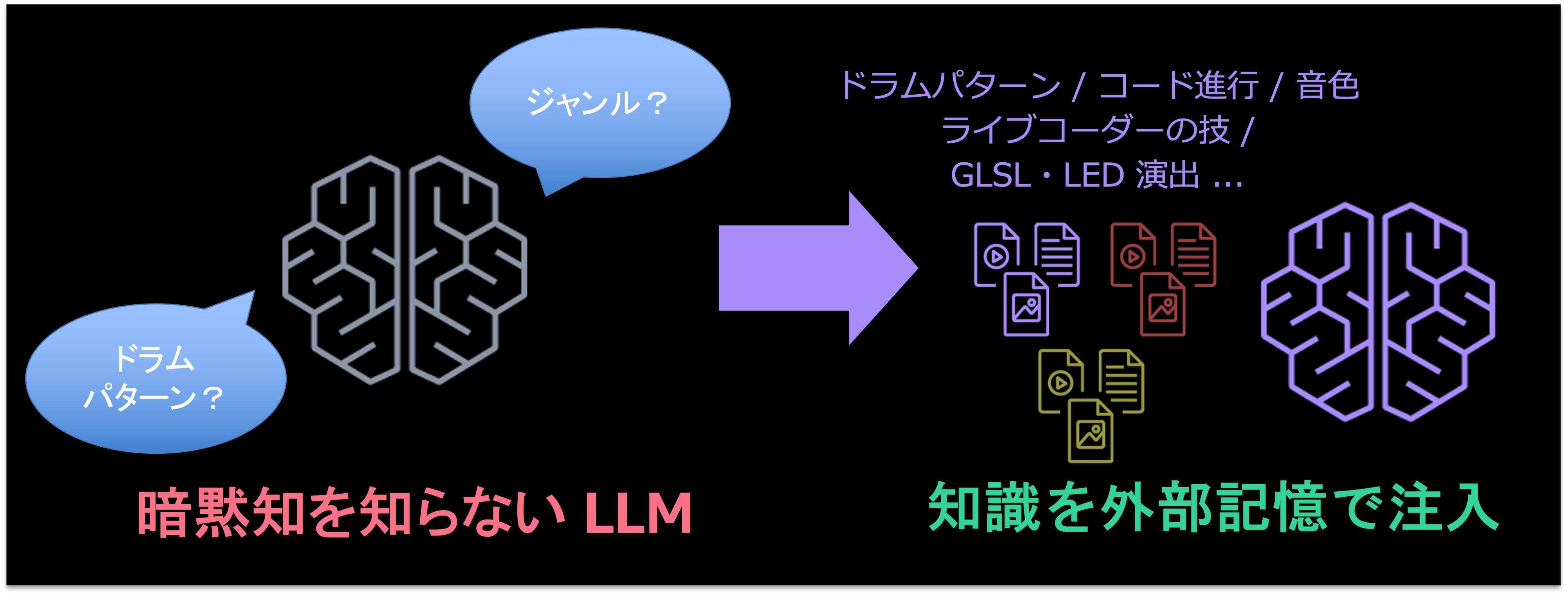
まず対処したのは知識の壁です。LLM はリズムの記法やシンセの名前は知っていても、「どのドラムパターンが Deep House っぽいか」「このコード進行が次にどう展開すると気持ちいいか」といった暗黙知を持っていません。
そこで私たちはジャンルごとのドラムパターン集、コード進行のボイシング戦略、サンプルの音色カタログ、実在のライブコーダーから抽出したテクニック集といった、音楽のナレッジを整備しました。「こういう音楽を作りたいなら、こういう素材をこう組み合わせる」という音楽の教科書的な知識を、外部記憶として丸ごとエージェントに渡しています。映像側も同じで、映像を生成するコードの書き方やジャンル別の映像の効かせ方を、別ファイルにまとめて VJ エージェントに渡しています。
AI がセンスで補ってくれることを期待しても、それは難しいところです。知識として必要な部分は、人間が言語化して渡すしかありませんでした。
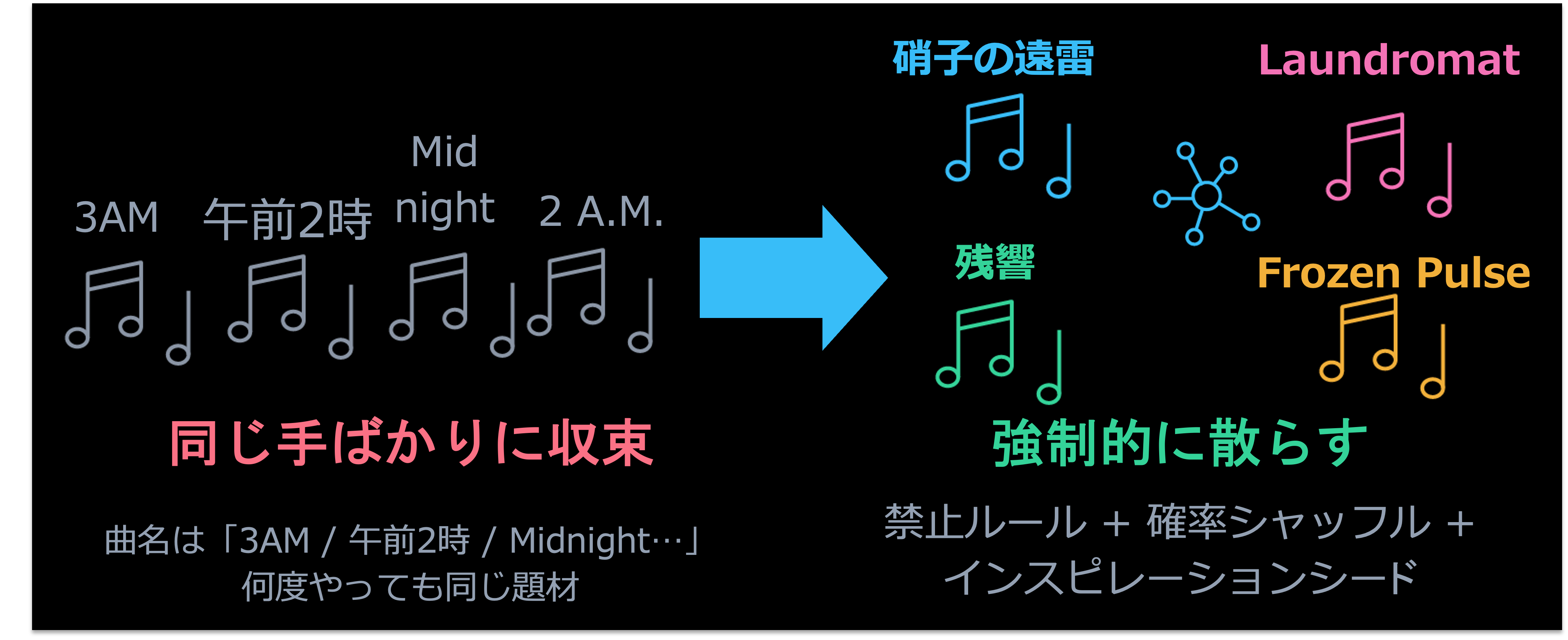
次に直面したのが、多様性の問題です。LLM は確率的に「最もありそうな」続きを生成するので、工夫をしないと同じ表現パターンを出力してしまいます。実際、初期の AI が生成する曲のタイトルは「3 AM」「午前 2 時」「Midnight〜」ばかりで、何度生成させても同じ題材を選びがちでした。
そこで、SPEC エージェントのプロンプトに「前の曲と同じジャンル・同じキー・同じ展開を連続で使うことは禁止」と書き、メロディの選択には確率的なシャッフルを混ぜる工夫を行いました。
さらに、1 サイクルごとに「インスピレーションシード」として、辞書から無作為に選んだ単語をいくつか渡しています。例えば、「冷たい・コインランドリー・呼び出し音」のような、互いに無関係な名詞と形容詞を渡します。AI はこれらの単語を発想の起点にするため、毎回違う世界観の曲が生まれるようになりました。
さらに踏み込んだのが、メロディの壁です。LLM にメロディを直接書かせると、フックのある旋律がなかなか出てきません。スケール上を上り下りする無難な音列か、同じ音をひたすら繰り返す単調なラインに収束しがちです。
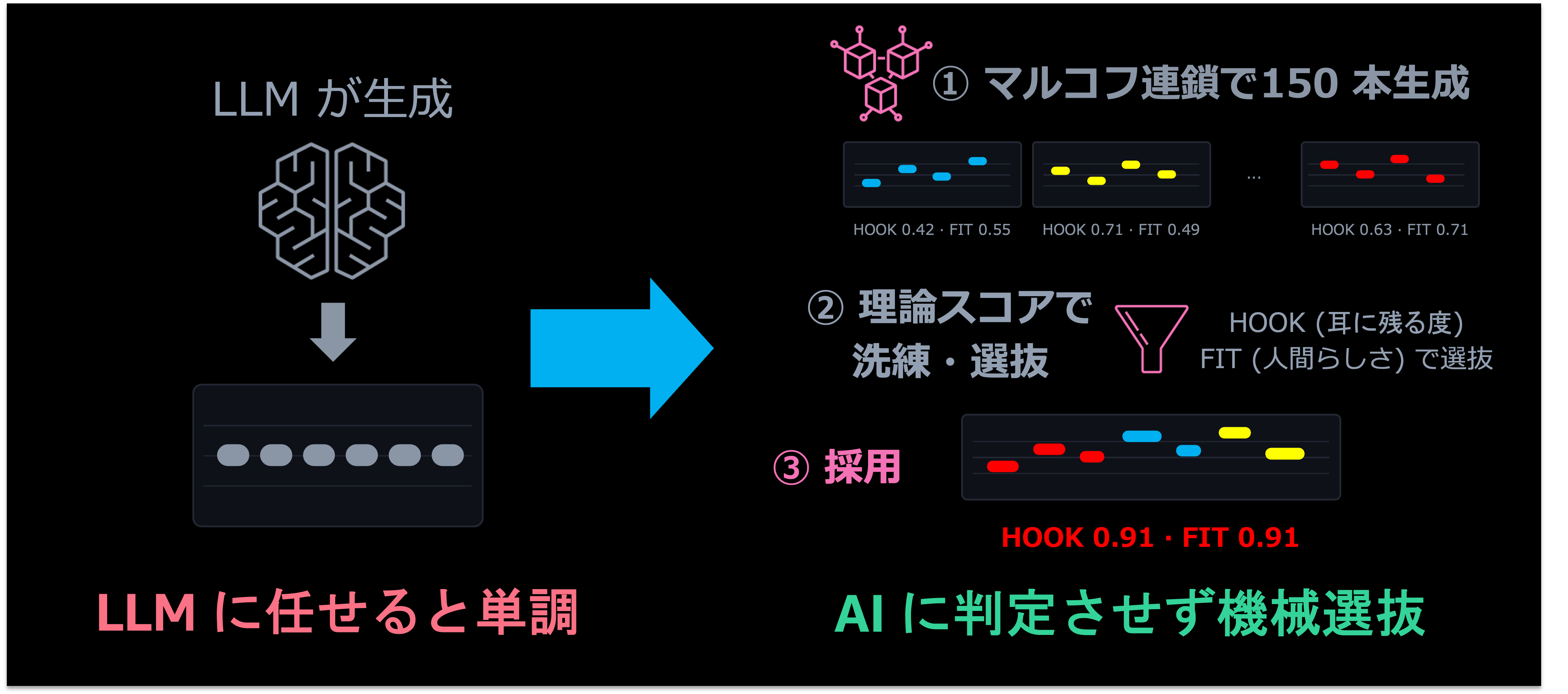
そこで、メロディの生成だけは LLM の外に切り出すことにしました。実際の楽曲データから「次にどの音が来やすいか」の確率を学習させた単純なモデル (マルコフ連鎖) に、音楽理論の制約 (順次進行を優先、跳躍したら反行で解決、強拍ではコードの構成音に着地) を組み合わせて、候補メロディを 150 本一気に生成させます。そこから、音域・動き・反復で表現力を測り、実際の楽曲と統計的にかけ離れたものを弾いて、最良の 1 本を返す。これをツールとして実装し、AI はキーやスケール、ムードといった引数を自由に選んで呼び出し、返ってきたメロディを楽曲に組み込みます。
生成の中身は LLM を一切通さないデータ駆動のパイプラインですが、何を・いつ・どう使うかは AI が決める ── 苦手な仕事だけを切り出して、専用の道具に任せる設計です。
映像生成でも、音楽と同じ課題に直面しました。VJ エージェントに色を自由に選ばせると、緑と茶色を組み合わせたような不快な配色が時々出てきます。粒柄の映像を生成させた時も粒の密度がスカスカで間延びしたり、線が細すぎて画面に埋もれたりします。「これは綺麗ですか ?」と AI 自身に聞いても、答えられません。
対策の方向性は音楽と同じで、「AI に判定させない」ことにしました。色相を AI に直接選ばせるのをやめ、あらかじめ用意した複数のカラーパレットから選ぶようにしました。下の画像のように、人間が綺麗だと感じる色の組み合わせであるカラーパレットを用意しました。柄についても、シェーダー側で線幅と粒の密度に最低ラインを設けて、一定以下にスカスカにならないよう制限しています。映像のクオリティの差を、設計の段階で減らすという考え方です。

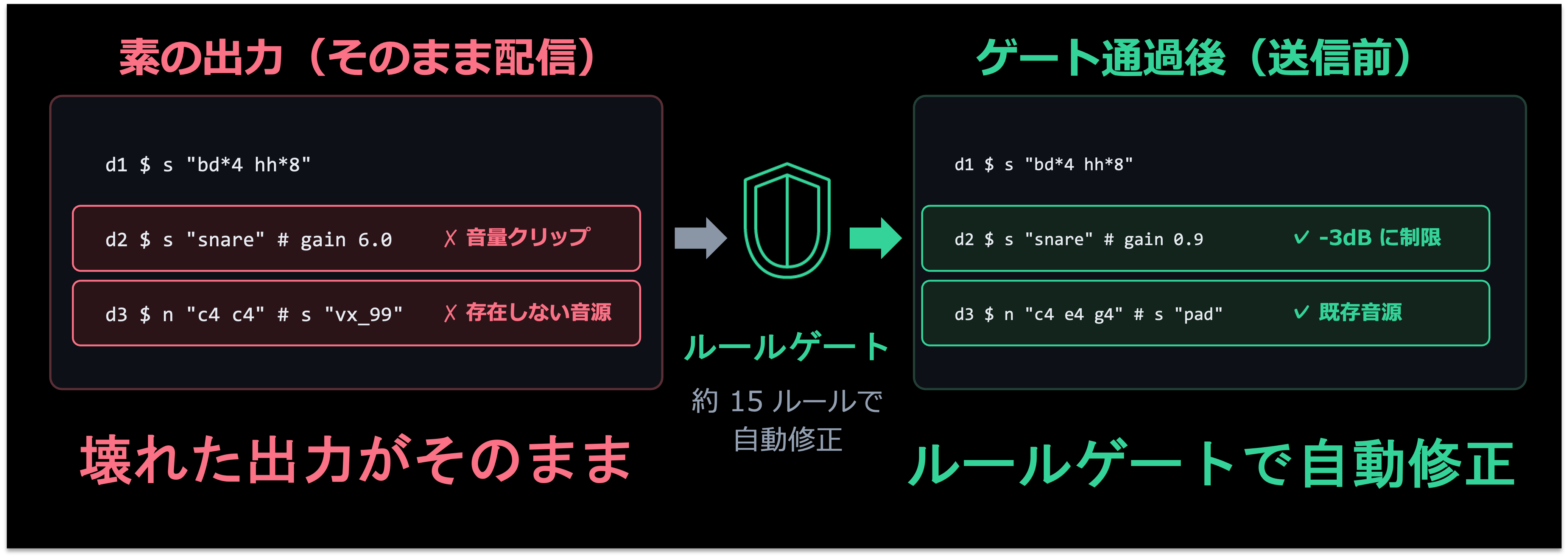
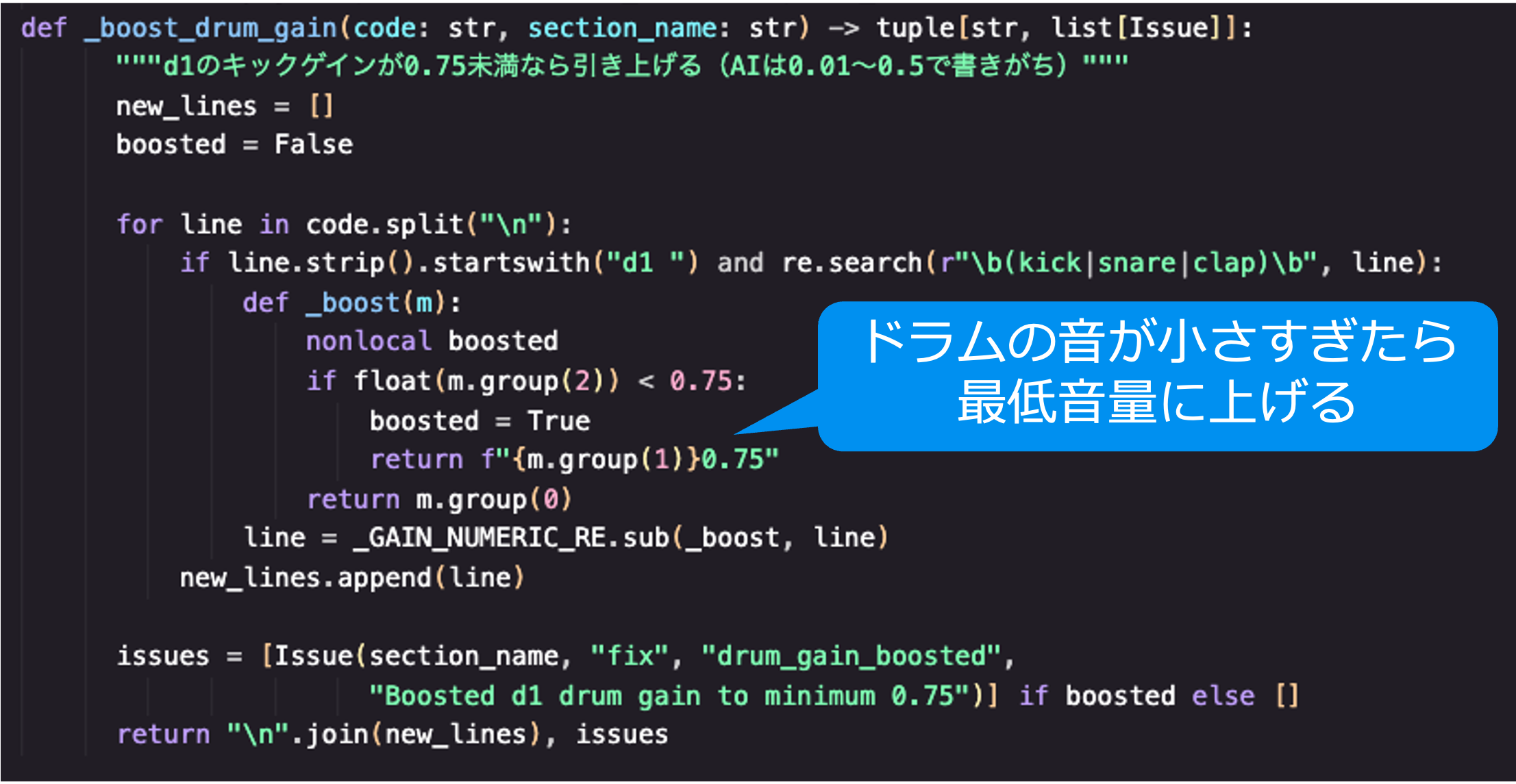
最後に取り組んだのが、出力の品質チェックです。AI の創造性は活かしたいものの、「存在しないサンプルを指定する」「音量が大きすぎてクリップする」「メロディが同じ音を延々繰り返す」といった問題は機械的に防ぎたいところです。
そこで、出力に関する約 15 種類のルールを設け、AI が生成したコードは、演奏サーバーに送られる前に自動検査・修正されます。この工程で、存在しない音源の参照を削除し、音量を楽器の役割ごとの上限に収め、単調な繰り返しを検出したらメロディを再生成し、ミックスのバランスを整えます。
映像側にも同様の仕組みがあり、AI が指定したシェーダー名がライブラリになければ自動的に安全な代替に置き換えます。人間のサウンドエンジニアが最終チェックで修正するような作業を、ルールベースで自動化しているイメージです。
AI に任せる範囲、ルールで縛る範囲
こうして 5 つの問題に対処するうちに、一つの考え方にたどり着きました。構成やジャンル選びのように「大きな枠だけ決めてあとは任せられる部分」は AI に委ね、サンプル名・音量バランス・配色のように「人間の感覚を言語化してルールに落とせる部分」はルールベースで実装しコントロールする。何でもAIに丸投げするでもなく、全てをルールで縛るでもなく、領域ごとに役割を分けることが大切でした。そのようにしてようやく、AI に DJ と VJ をさせるという試みが形になっていきました。
ただし、この線引きでも対処できない問題が残ります。本物の DJ や VJ は、演奏しながら会場の空気を肌で感じ取り、「もっと上げるべきか」「落ち着かせるべきか」を瞬時に判断しています。「いま観客が盛り上がっているか」「いまの空気がチルなのかピークなのか」、これは AI にも分りませんし、ルールでも縛れません。そこで、その判断を観客自身に委ねることにしました。
Amazon IVS で双方向のライブ配信を実現する
観客に場の空気を判定してもらう
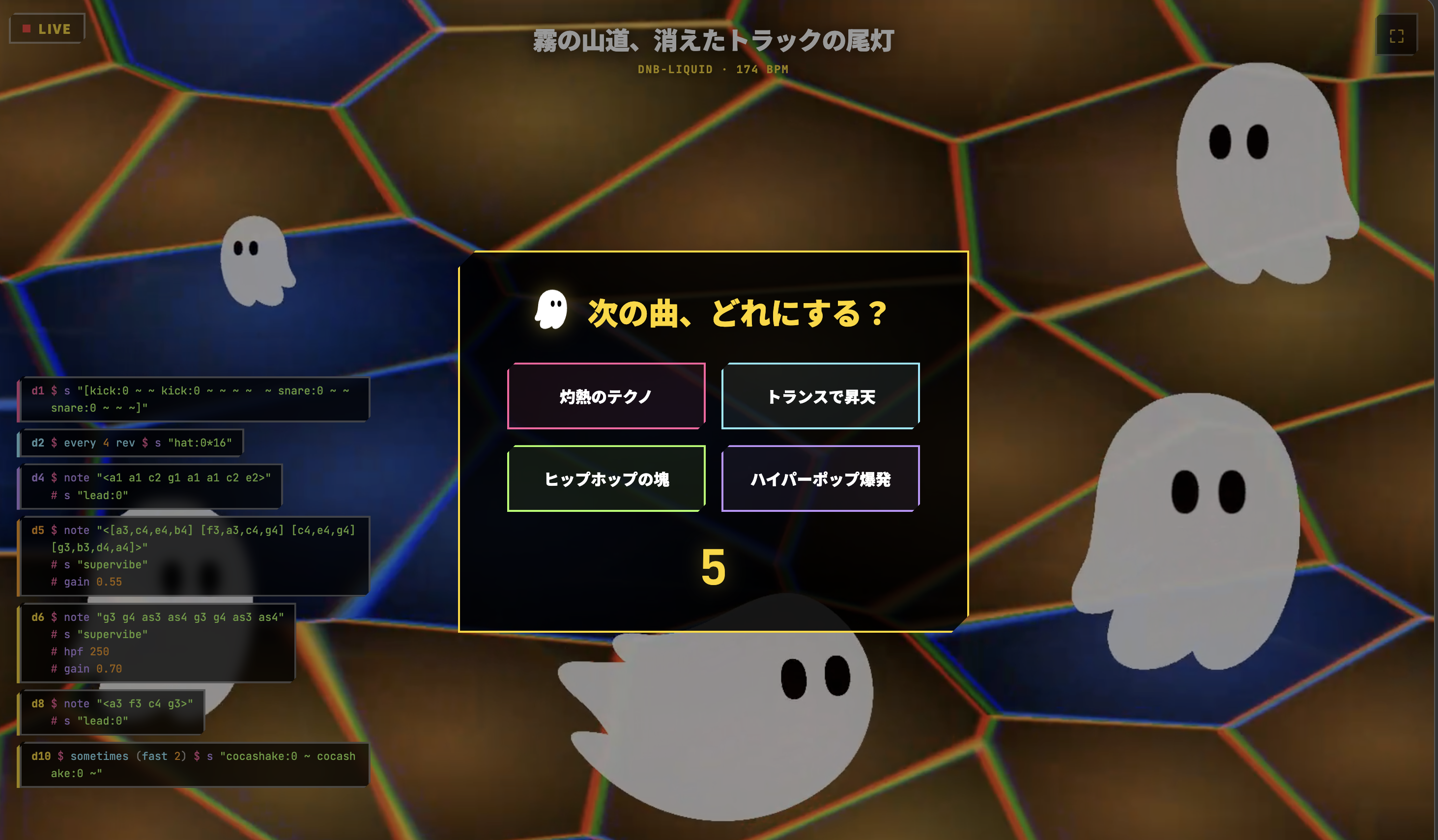
配信画面では時々「次はどんな雰囲気がいい ?」という投票が表示されます。下の画像は、投票画面の様子です。観客がスマホでタップすると票が集計され、10 秒後、勝った選択肢をもとに AI が次の曲を組み立てます。観客の総意が、次の瞬間の音楽になるのです。
このような観客参加の体験に加えて、IVS の Timed Metadata を使うことでさらに面白い演出が実現できました。
演出をデバイス側で描く:Timed Metadata の活用
IVS Timed Metadata とは、メタデータをライブ配信ストリームに埋め込んで視聴者に届ける機能です。映像の任意のタイミングにメタデータを埋め込めるため、配信遅延の大小に関わらず、すべての視聴者が映像と同期したタイミングでメタデータを受け取れます。 本デモでは、エージェントが生成した楽曲情報やコード、照明指示を JSON として配信ストリームに埋め込み、視聴者のデバイス側でリアルタイムに描画しています。映像そのものに演出を焼き込むのではなく、メタデータとして送り、受け取った側が描く。これにより同じ配信からでも、デバイスごとのレスポンシブレイアウトのような複数の異なる演出を展開できます。
コーディング演出と音楽・映像の同期
エージェントが 音楽用コードを作成するたびに、そのコードを Timed Metadata としてストリームに埋め込みます。視聴者のブラウザではこのメタデータを受信し、映像に重ねてタイピング演出として表示します。コードの変化と音楽の変化が同じ瞬間に届くため、「いま何が起きているか」が視覚的に伝わります。
ブースの照明との連動
同じ仕組みで、LED の制御命令もストリームに流しています。ブースの PC がストリームを受信し、Timed Metadata から LED コマンドを取り出して展示用 PC と接続されている ESP32 マイコンにそのまま転送します。映像・音声・照明が同一のタイムラインに乗るため、追加の同期機構なしに、ビートと光が揃います。
観客参加:投票で演奏に介入する
配信を一方的に見るだけでなく、観客が演奏に参加できる体験を目指しました。Timed Metadata で投票の開始と結果を全視聴者に同時に配信し、投票 UI を表示します。視聴者の回答は API 経由で集約し、エージェントにフィードバックして次の楽曲選択に反映します。
このように IVS Timed Metadata を用いることで配信映像と同期したタイミングで、全視聴者に一斉に多様なインタラクションを届けることを実現できています。
システム全体像
ここまでで、AI に DJ をさせるための設計と、観客とのインタラクションについて見てきました。ここから先は、それを実際に動かしている仕組みと技術スタックを少し詳しく紹介します。
1 曲が生まれるまでの仕組み
配信中、DJ Agent は短いサイクルを繰り返して曲を作り続けます。1 サイクルの中ではこのような仕組みで曲が生成されています。
Spec エージェントが前の曲の流れと観客のリアクション・投票を踏まえ、次の曲を構想します。(毎回あえて違うジャンルと構成を選ぶので、同じ曲は二度と流れません)
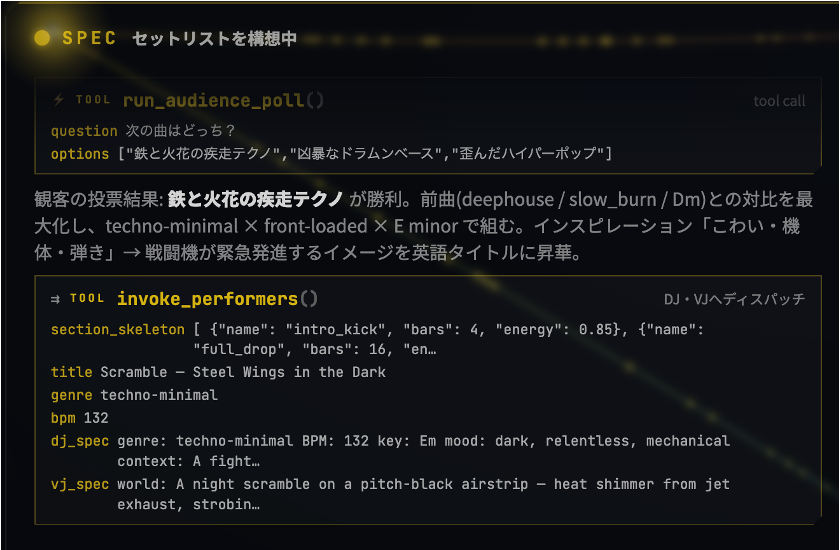
「次はどんな曲が流れるのか」が即座に画面へ表示されます。Spec エージェントが設計書を作成したタイミングで「NEXT: Neon Rain Over Shinjuku」のような予告が出ます。

DJ エージェントと VJ エージェントが同時に動き、音楽コードと映像コードをそれぞれ生成します。
生成された音楽コードは後処理を通して既知の不具合を自動補正します。AI の創造性を活かしつつ、品質の最低ラインは機械的に守る仕組みです。
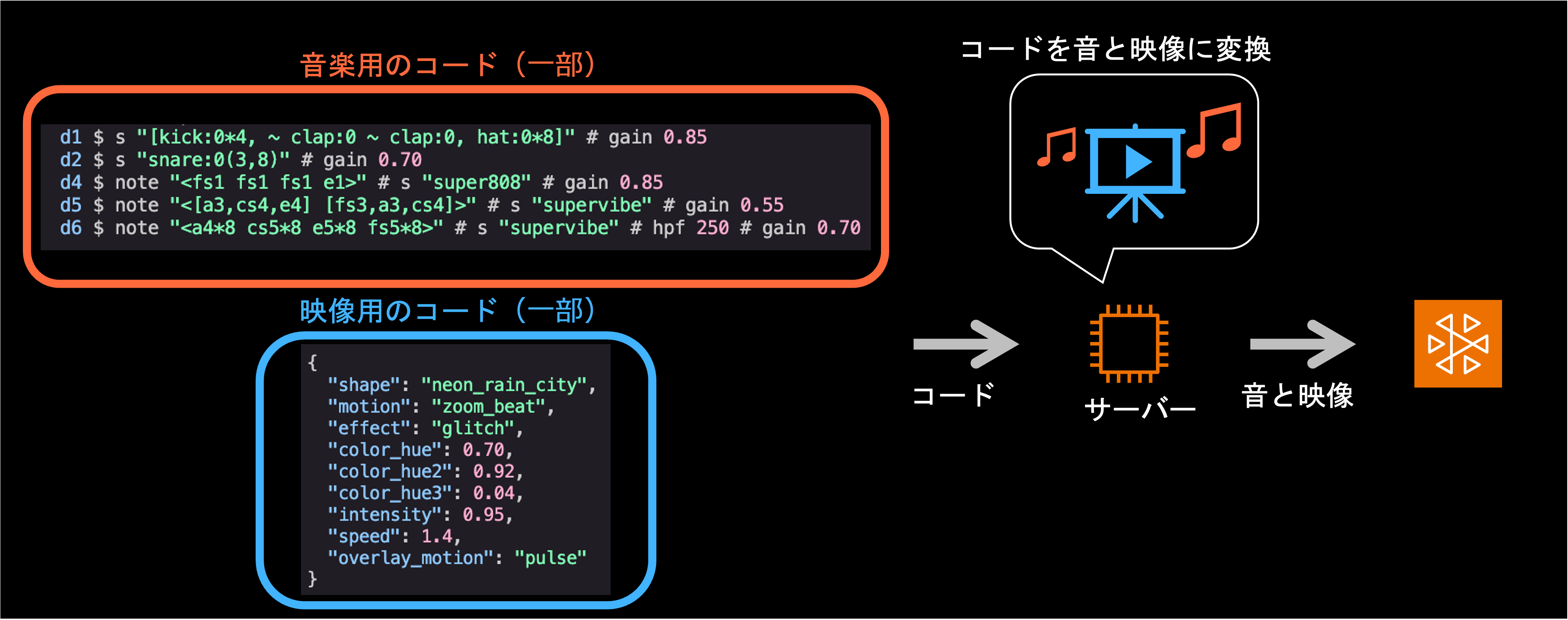
演奏サーバーがコードを実行し、音と映像をリアルタイム生成して配信 IVS へ送られます。
Spec エージェントは Amazon Bedrock の AgentCore Runtime 上で動き、その中から DJ・VJ を Strands Agents SDK の「道具」として呼び出しています。この agent-as-tool パターンが、二層構成の正体です。
全体アーキテクチャ
この DJ Agent 全体の構成はこちらです。
構築までの流れ
音楽と映像のリアルタイム生成は、GPU 付きの Amazon EC2 インスタンス上で行っています。
DJ エージェントが書くのは、リズムやメロディを短い式で記述できる音楽専用のプログラミング言語「Tidal Cycles」のコードで、その指示を受けて実際に音を鳴らすのが音響合成エンジンの「SuperCollider」です。
映像については、VJ エージェントが GPU 上で動く小さな映像生成プログラム「GLSL シェーダー」を書き、グラフィックス用ツールキットの「openFrameworks」がそれを 1080p・60fps で描き出します。こうしてできた音と映像を、配信の定番ツール「FFmpeg」が一本のストリームにまとめて IVS へ送り出す、という流れです。
視聴ページと管理ページは、Web 画面を作るライブラリ「React」で実装し、AWS Amplify Hosting で公開しています。そしてインフラ全体は、構成をコードで定義する AWS CDK で管理しています。
おまけ : DJ・VJ 以外への応用可能性
ここまで「AI に DJ / VJ をさせる」という話をしてきましたが、使っている部品を一歩引いて眺めると、応用の幅はぐっと広がります。
たとえば 「考える人と弾く人を分ける」サブエージェント構成は、音楽に限った話ではありません。全体の方針を立てる役割と、それを専門領域で実行する役割を分け、それぞれに必要な知識だけを持たせる — このパターンは、計画と実行が分かれるあらゆるタスクに効きます。マーケティング戦略の立案と各チャネルでの実行、設計と実装、レポートの構成と各セクションの執筆。1 つの巨大なプロンプトに全部詰め込むより、役割を分けたほうが品質も安定性も上がる、というのはこのデモで実感したことです。
そして IVS の Timed Metadata で「演出を映像に焼き込まず、視聴者デバイス側で描く」発想も、実はさまざまな場面に応用できます。
- スポーツ中継:ゴールの瞬間に、視聴者のデバイスでエフェクトやスタッツを出す
- ライブビューイング:配信遅延に関わらずライブ映像と会場演出のタイミングを同期する
- リアルタイム投票・アンケート:配信中に視聴者の意見を集めて、その場で反映する
DJ Agent でやっている「観客の投票で次の曲が決まる」も「映像・音声以外の演出を同期させる」も、突き詰めれば 低遅延のライブ配信に、視聴者が参加できる双方向性を足すという同じ仕組みです。
まとめ
DJ Agent は音楽・映像ライブパフォーマンスを AI エージェントにやらせてみた実験的取り組みです。やってみると、LLM には得意なこともあれば苦手なこともある、という気づきがありました。実験により判明した苦手なことは外部の仕組みで補ってあげるような設計が効果的なアプローチでした。
- AI に大きく預けたところ — 曲全体の流れ、ジャンル選び、タイトルの世界観、シェーダーの個性。曖昧さに価値がある領域は、Spec エージェントが大きな枠を引き、DJ・VJ エージェントがその中で自由に表現する 2 層構成にしました。
- 決定論的なルールで制御したところ — メロディ生成 (マルコフ連鎖 + 音楽理論スコア)、配色 (7 つのプリセットパレット)、出力チェック。「生成物が低品質な場合の判定が機械的にできるところ」は、AI に判定させずにルールで制御する方が確実でした。
- 観客に委ねたところ — 「いま会場が盛り上がっているか」「次の曲はチル系か激しめか」── ルールでも制御できず、AI にも分からない部分は、Amazon IVS の投票を通して、観客自身に決めてもらう設計にしました。
この 「自由に任せる場所・ルールで制御する場所・人間に判断を委ねる場所、を意識して分ける」という考え方は、おそらく DJ に限らず、AI を実際の仕事に組み込むときに、いつでも有効な設計指針です。AI に「自由にやって」と言うだけでも、「全部こうしろ」と縛るだけでもない ── 領域ごとに線を引く。私たちが格闘の末にたどり着いたのは、案外シンプルな結論でした。
筆者プロフィール


菊地 泰斗 (Taito Kikuchi)
アマゾン ウェブ サービス ジャパン合同会社
ソリューションアーキテクト
2025 年 4 月入社。Kiro CLI で業務効率化に励むも、効率化そのものが楽しくなりすぎて、気づいたら退勤時間が遅くなるのが最近の悩み。

片岡 翔太郎 (Shotaro Kataoka)
アマゾン ウェブ サービス ジャパン合同会社
ソリューションアーキテクト
AI/ML 関連で博士号取得後 2025 年に入社した SA。最近初めての娘が生まれ、家では常に抱っこをしている。業務効率化ツールの開発が趣味で、Kiro CLI を片手にいつも何かを作っている。