ロジスティック回帰とは何ですか?
ロジスティック回帰とは何ですか?
ロジスティック回帰とは、数学を使用して 2 つのデータ因子間の関係を見つけるデータ分析手法です。その後、この関係を使用して、一方の因子の値を他方の因子に基づいて予測します。通常、予測の結果の数は有限です (「はい」や「いいえ」など)。
例えば、ウェブサイトの訪問者がショッピングカートでチェックアウトボタンをクリックするかどうかを推測するとします。ロジスティック回帰分析では、ウェブサイトでの滞在時間やカート内の商品数など、過去の訪問者の行動を調べます。この分析では、訪問者が過去に 5 分間を超える時間にわたってサイトに滞在し、かつ、カートに 4 つ以上の商品を追加した場合に、チェックアウトボタンをクリックしたと判断されました。ロジスティック回帰関数は、この情報を使用して、ウェブサイトの新規訪問者の行動を予測できます。
ロジスティック回帰が重要なのはなぜですか?
ロジスティック回帰は、人工知能と機械学習 (AI/ML) の分野における重要な手法です。ML モデルは、人間の介入なしに複雑なデータ処理タスクを実行するようにトレーニングできるソフトウェアプログラムです。ロジスティック回帰を使用して構築された ML モデルは、組織がビジネスデータから実用的なインサイトを得るのに役立ちます。これらのインサイトを予測分析に使用して、運用コストを削減し、効率を高め、より迅速にスケールできます。例えば、企業は、従業員の定着率を向上させたり、より収益性の高い製品設計につながったりするパターンを探り出すことができます。
他の ML 手法と比較して、ロジスティック回帰を使用することで得られるいくつかのメリットを以下に示します。
シンプルさ
ロジスティック回帰モデルは、他の ML 手法よりも数学的に複雑ではありません。したがって、機械学習に関する深い専門知識を持っている人がチームにいなくても実装できます。
速度
ロジスティック回帰モデルは、メモリや処理能力などの計算能力が少なくて済むため、大量のデータを高速に処理できます。そのため、ML プロジェクトを開始しようとしている組織が短期間で成果を生み出すのに理想的です。
柔軟性
ロジスティック回帰を使用して、2 つ以上の有限な結果を持つ質問に対する回答を見つけることができます。また、データの前処理にも使用できます。例えば、ロジスティック回帰を使用すると、広い範囲の値を持つデータ (銀行取引など) を、より狭く有限な範囲の値に並べ替えることができます。その後、この小さなデータセットを他の ML 手法を使用して処理し、より正確な分析を行うことができます。
可視性
ロジスティック回帰分析により、デベロッパーは、他のデータ分析手法よりも詳細に内部ソフトウェアプロセスを把握できます。計算がそれほど複雑ではないため、トラブルシューティングとエラー修正もより簡単です。
ロジスティック回帰はどのように適用できますか?
ロジスティック回帰は、多くのさまざまな業界において、現実世界のいくつかの場面で適用されています。
製造
製造企業は、ロジスティック回帰分析を使用して、機械の部品故障の可能性を推定します。その後、将来の故障を最小限に抑えるために、この推定に基づいてメンテナンススケジュールを計画します。
医療
医療分野の研究者は、患者の疾患の可能性を予測することにより、予防的ケアと治療を計画します。これらの研究者は、ロジスティック回帰モデルを使用して、家族歴または遺伝子が疾患に及ぼす影響を比較します。
金融
金融企業は、詐欺がないかを確認するために金融取引を分析し、ローンの申請と保険申請のリスクを評価する必要があります。これらの問題は、リスクが高いか低いか、または詐欺であるか否か、など、はっきり区別される結果をもたらすため、ロジスティック回帰モデルに適しています。
マーケティング担当
オンライン広告ツールは、ロジスティック回帰モデルを使用して、ユーザーが広告をクリックするかどうかを予測します。その結果、マーケティング担当者は、さまざまな単語や画像に対するユーザーの反応を分析し、顧客が関心を示す、パフォーマンスの高い広告を作成できます。
回帰分析はどのように機能しますか?
ロジスティック回帰は、データサイエンティストが機械学習 (ML) で一般的に使用するいくつかの異なる回帰分析手法の 1 つです。ロジスティック回帰を理解するには、まず基本的な回帰分析を理解する必要があります。以下では、線形回帰分析の例を使用して、回帰分析がどのように機能するかを示します。
質問を特定する
データ分析は、ビジネス上の質問から始まります。ロジスティック回帰では、特定の結果を得るために質問を組み立てる必要があります。
- 雨の日は毎月の販売に影響しますか? (「はい」または「いいえ」)
- 顧客が行おうとしているクレジットカードの利用はどのタイプですか? (承認済み、不正、または潜在的に不正)
履歴データを収集する
質問を特定したら、関係するデータ因子を特定する必要があります。その後、すべての因子の過去のデータを収集します。例えば、上記の最初の質問に答えるには、過去 3 年間の各月の雨の日の数と月次販売データを収集することが考えられます。
回帰分析モデルをトレーニングする
回帰ソフトウェアを使用して履歴データを処理します。ソフトウェアはさまざまなデータポイントを処理し、方程式を使用して数学的につなぎます。例えば、3 か月間の雨の日数が 3、5、8 で、その月の販売数が 8、12、18 の場合、回帰アルゴリズムはこれらの因子を次の式で結び付けます。
販売数 = 2*(雨の日の数) + 2
不明な値を予測する
不明な値については、ソフトウェアは方程式を使用して予測を行います。7 月に 6 日間雨が降ることがわかっている場合、ソフトウェアは 7 月の販売の値を 14 と推定します。
ロジスティック回帰モデルはどのように機能しますか?
ロジスティック回帰モデルを理解するために、まず方程式と変数を理解しましょう。
方程式
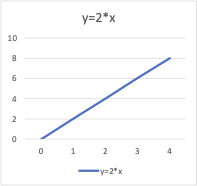
数学では、方程式は x と y の 2 つの変数の関係を示します。これらの方程式または関数を使用して、x と y の異なる値を入力することにより、x 軸と y 軸に沿ってグラフをプロットできます。例えば、関数 y = 2*x のグラフをプロットすると、以下のような直線が得られます。したがって、この関数は一次関数とも呼ばれます。
変数
統計では、変数は値が変化するデータ因子または属性です。どの分析でも、特定の変数は独立変数または説明変数です。これらの属性は結果の原因です。他の変数は従属変数または応答変数で、その値は独立変数に依存します。一般に、ロジスティック回帰は、独立変数が 1 つの従属変数にどのように影響するかを、両方の変数の履歴データの値を確認することによって調べます。
上記の例では、x は既知の値を持つため、独立変数、予測変数、または説明変数と呼ばれます。Y は、その値が不明であるため、従属変数、結果変数、または応答変数と呼ばれます。
ロジスティック回帰関数
ロジスティック回帰は、数学のロジスティック関数、またはロジット関数を x と y の方程式として使用する統計モデルです。ロジット関数は y を x のシグモイド関数としてマッピングします。
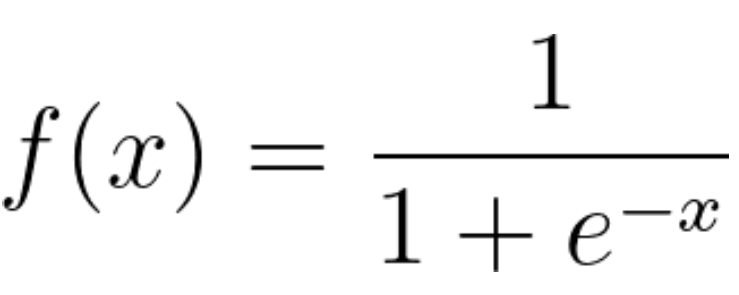
このロジスティック回帰式をプロットすると、以下に示すような S カーブが得られます。
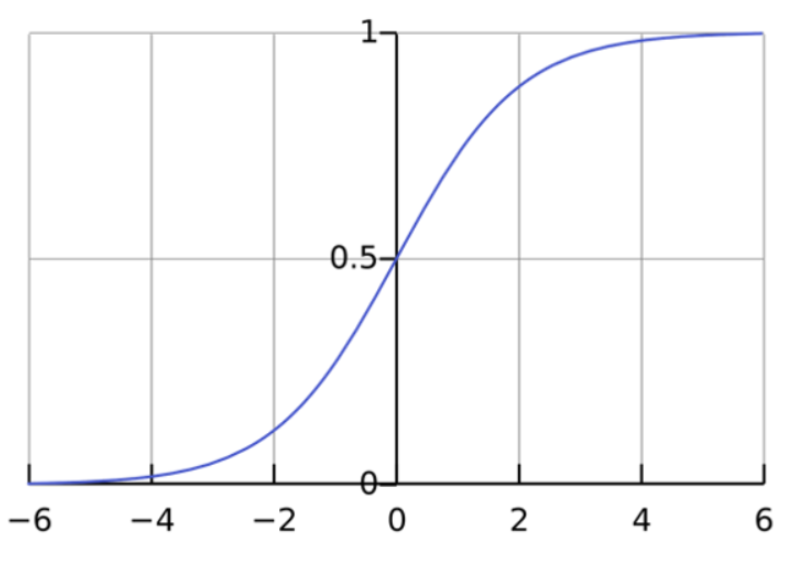
ご覧のとおり、ロジット関数は、独立変数の値にかかわらず、従属変数として 0~1 の値のみを返します。このようにして、ロジスティック回帰は従属変数の値を推定します。また、ロジスティック回帰法では、複数の独立変数と 1 つの従属変数の間の方程式がモデル化されます。
複数の独立変数を使用したロジスティック回帰分析
多くの場合、複数の説明変数が従属変数の値に影響します。このような入力データセットをモデル化するために、ロジスティック回帰式は異なる独立変数間の線形関係を仮定します。シグモイド関数を変更し、最終的な出力変数を次のように計算できます。
y = f(β0 + β1x1 + β2x2+… βnxn)
記号 β は回帰係数を表します。ロジットモデルは、従属変数と独立変数の両方の既知の値を持つ十分な大きさの実験データセットを与えると、これらの係数値を逆計算できます。
対数オッズ
ロジットモデルは、成功と失敗の比率または対数オッズを決定することもできます。例えば、友人とポーカーをプレイしていて、10 回中 4 回勝った場合、勝利のオッズは 6 分の 4 になります。これは、成功と失敗の比率です。一方、勝つ確率は 10 分の 4 です。
数学的には、確率に関するオッズは p/(1 - p) で、対数オッズは log (p/(1 - p)) です。以下に示すように、ロジスティック関数を対数オッズで表すことができます。
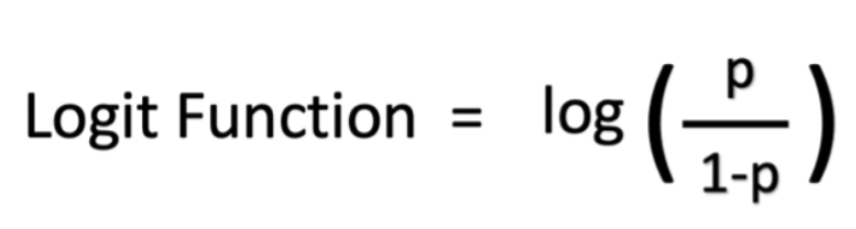
ロジスティック回帰分析のタイプにはどのようなものがありますか?
従属変数の結果に基づくロジスティック回帰分析には、3 つのアプローチがあります。
バイナリロジスティック回帰
バイナリロジスティック回帰は、可能な結果が 2 つしかない二項分類問題に適しています。従属変数は、「はい」と「いいえ」、または 0 と 1 など、2 つの値のみを持つことができます。
ロジスティック関数が 0~1 の範囲の値を算出しても、バイナリ回帰モデルではその回答を最も近い値に丸めます。一般に、0.5 未満の回答は 0 に丸められ、0.5 を超える回答は 1 に丸められるため、ロジスティック関数はバイナリの結果を返します。
多項ロジスティック回帰
多項回帰は、結果の数が有限である限り、複数の可能な結果がある問題を分析できます。例えば、人口データに基づいて住宅価格が 25%、50%、75%、または 100% 上昇するかどうかを予測することはできますが、住宅の正確な価値を予測することはできません。
多項ロジスティック回帰は、結果値を 0 と 1 の間のさまざまな値にマッピングすることで機能します。また、ロジスティック関数は 0.1、0.11、0.12 などの連続データの範囲を返すことができるため、多項回帰は結果を可能な限り近い値にグループ化します。
順序ロジスティック回帰
順序ロジスティック回帰、または順序ロジットモデルは、数値が実際の値ではなくランクを表す問題向けの特殊な多項回帰です。例えば、順序回帰を使用して、1 年間に購入した商品数などの数値に基づいて、サービスを不良、普通、良好、または優秀としてランク付けするよう顧客に求めるアンケートの質問に対する回答を予測します。
他の ML 手法と比較すると、ロジスティック回帰についてはどのようなことが言えますか?
2 つの一般的なデータ分析手法は、線形回帰分析と深層学習です。
線形回帰分析
上記で説明したように、線形回帰は、線形結合を使用して従属変数と独立変数の関係をモデル化します。線形回帰の式は次のようになります。
y= β0X0 + β1X1 + β2X2+… βnXn+ ε。ここで、β1 から βn および ε は回帰係数です。
ロジスティック回帰と線形回帰
線形回帰は、特定の一連の独立変数を使用して連続従属変数を予測します。連続変数は、価格や年齢など、一定の範囲の値を持つことができます。したがって、線形回帰は従属変数の実際の値を予測できます。「10 年後に米の価格はどうなるか?」などの質問に回答できます。
線形回帰とは異なり、ロジスティック回帰は分類アルゴリズムです。連続データの実際の値を予測することはできません。「今後 10 年間で米の価格は 50% 上昇するか?」などの質問に回答できます。
深層学習
深層学習は、情報を分析するために人間の脳をシミュレートするニューラルネットワークまたはソフトウェアコンポーネントを使用します。深層学習の計算は、ベクトルの数学的概念に基づいています。
ロジスティック回帰と深層学習
ロジスティック回帰は、深層学習よりも複雑ではなく、使用される計算もより少ないです。さらに重要なのは、深層学習の計算は、その複雑で機械駆動型の性質のため、デベロッパーが調査したり変更したりできないことです。一方、ロジスティック回帰計算は透明性が高く、トラブルシューティングが容易です。
AWS でロジスティック回帰分析を実行するにはどうすればいいですか?
AWS でロジスティックリグレッションを実行するには、Amazon SageMaker を使用します。SageMaker は、他のいくつかの統計ソフトウェアパッケージと同様に、線形回帰とロジスティック回帰のための組み込みアルゴリズムを備えた、フルマネージド機械学習 (ML) サービスです。
- あらゆるデータサイエンティストは SageMaker を使用して、ロジスティック回帰モデルを迅速に準備、構築、トレーニング、およびデプロイできます。
- SageMaker は高品質モデルの開発を容易にするため、ロジスティック回帰の各ステップから手間のかかる作業を取り除きます。
- SageMaker は、ロジスティック回帰に必要なすべてのコンポーネントを 1 つのツールセットで提供します。これにより、モデルをより迅速かつ簡単に、より低コストで本番稼働環境に移行できます。
今すぐ AWS アカウントを作成して、ロジスティックリグレッションを始めましょう。
Browse all cloud computing concepts
Browse all cloud computing concepts content here:
Did you find what you were looking for today?
Let us know so we can improve the quality of the content on our pages