AWS News Blog
New – Step Functions Support for Dynamic Parallelism

|
Microservices make applications easier to scale and faster to develop, but coordinating the components of a distributed application can be a daunting task. AWS Step Functions is a fully managed service that makes coordinating tasks easier by letting you design and run workflows that are made of steps, each step receiving as input the output of the previous step. For example, Novartis Institutes for Biomedical Research is using Step Functions to empower scientists to run image analysis without depending on cluster experts.
Step Functions added some very interesting capabilities recently, such as callback patterns, to simplify the integration of human activities and third-party services, and nested workflows, to assemble together modular, reusable workflows. Today, we are adding support for dynamic parallelism within a workflow!
How Dynamic Parallelism Works
States machines are defined using the Amazon States Language, a JSON-based structured language. The Parallel state can be used to execute in parallel a fixed number of branches defined in the state machine. Now, Step Functions supports a new Map state type for dynamic parallelism.
To configure a Map state, you define an Iterator, which is a complete sub-workflow. When a Step Functions execution enters a Map state, it will iterate over a JSON array in the state input. For each item, the Map state will execute one sub-workflow, potentially in parallel. When all sub-workflow executions complete, the Map state will return an array containing the output for each item processed by the Iterator.
You can configure an upper bound on how many concurrent sub-workflows Map executes by adding the MaxConcurrency field. The default value is 0, which places no limit on parallelism and iterations are invoked as concurrently as possible. A MaxConcurrency value of 1 has the effect to invoke the Iterator one element at a time, in the order of their appearance in the input state, and will not start an iteration until the previous iteration has completed execution.
One way to use the new Map state is to leverage fan-out or scatter-gather messaging patterns in your workflows:
- Fan-out is applied when delivering a message to multiple destinations, and can be useful in workflows such as order processing or batch data processing. For example, you can retrieve arrays of messages from Amazon SQS and Map will send each message to a separate AWS Lambda function.
- Scatter-gather broadcasts a single message to multiple destinations (scatter) and then aggregates the responses back for the next steps (gather). This can be useful in file processing and test automation. For example, you can transcode ten 500 MB media files in parallel and then join to create a 5 GB file.
Like Parallel and Task states, Map supports Retry and Catch fields to handle service and custom exceptions. You can also apply Retry and Catch to states inside your Iterator to handle exceptions. If any Iterator execution fails because of an unhandled error or by transitioning to a Fail state, the entire Map state is considered to have failed and all its iterations are stopped. If the error is not handled by the Map state itself, Step Functions stops the workflow execution with an error.
Using the Map State
Let’s build a workflow to process an order and, by using the Map state, work on the items in the order in parallel. The tasks executed as part of this workflow are all Lambda functions, but with Step Functions you can use other AWS service integrations and have code running on EC2 instances, containers or on-premises infrastructure.
Here’s our sample order, expressed as a JSON document, for a few books, plus some coffee to drink while reading them. The order has a detail section where there is a list of items that are part of the order.
{
"orderId": "12345678",
"orderDate": "20190820101213",
"detail": {
"customerId": "1234",
"deliveryAddress": "123, Seattle, WA",
"deliverySpeed": "1-day",
"paymentMethod": "aCreditCard",
"items": [
{
"productName": "Agile Software Development",
"category": "book",
"price": 60.0,
"quantity": 1
},
{
"productName": "Domain-Driven Design",
"category": "book",
"price": 32.0,
"quantity": 1
},
{
"productName": "The Mythical Man Month",
"category": "book",
"price": 18.0,
"quantity": 1
},
{
"productName": "The Art of Computer Programming",
"category": "book",
"price": 180.0,
"quantity": 1
},
{
"productName": "Ground Coffee, Dark Roast",
"category": "grocery",
"price": 8.0,
"quantity": 6
}
]
}
}To process this order, I am using a state machine defining how the different tasks should be executed. The Step Functions console creates a visual representation of the workflow I am building:
- First, I validate and check the payment.
- Then, I process the items in the order, potentially in parallel, to check their availability, prepare for delivery and start the delivery process.
- At the end, a summary of the order is sent to the customer.
- In case the payment check fails, I intercept that, for example to send a notification to the customer.
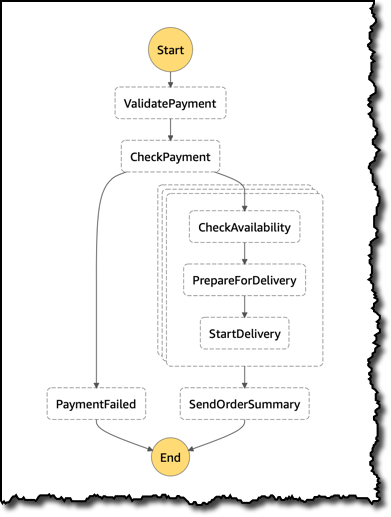
Here is the same state machine definition expressed as a JSON document. The ProcessAllItems state is using Map to process items in the order in parallel. In this case, I limit concurrency to 3 using the MaxConcurrency field. Inside the Iterator, I can put a sub-workflow of arbitrary complexity. In this case, I have three steps, to CheckAvailability, PrepareForDelivery, and StartDelivery of the item. Each of this step can Retry and Catch errors to make the sub-workflow execution more reliable, for example in case of integrations with external services.
{
"StartAt": "ValidatePayment",
"States": {
"ValidatePayment": {
"Type": "Task",
"Resource": "arn:aws:lambda:us-west-2:123456789012:function:validatePayment",
"Next": "CheckPayment"
},
"CheckPayment": {
"Type": "Choice",
"Choices": [
{
"Not": {
"Variable": "$.payment",
"StringEquals": "Ok"
},
"Next": "PaymentFailed"
}
],
"Default": "ProcessAllItems"
},
"PaymentFailed": {
"Type": "Task",
"Resource": "arn:aws:lambda:us-west-2:123456789012:function:paymentFailed",
"End": true
},
"ProcessAllItems": {
"Type": "Map",
"InputPath": "$.detail",
"ItemsPath": "$.items",
"MaxConcurrency": 3,
"Iterator": {
"StartAt": "CheckAvailability",
"States": {
"CheckAvailability": {
"Type": "Task",
"Resource": "arn:aws:lambda:us-west-2:123456789012:function:checkAvailability",
"Retry": [
{
"ErrorEquals": [
"TimeOut"
],
"IntervalSeconds": 1,
"BackoffRate": 2,
"MaxAttempts": 3
}
],
"Next": "PrepareForDelivery"
},
"PrepareForDelivery": {
"Type": "Task",
"Resource": "arn:aws:lambda:us-west-2:123456789012:function:prepareForDelivery",
"Next": "StartDelivery"
},
"StartDelivery": {
"Type": "Task",
"Resource": "arn:aws:lambda:us-west-2:123456789012:function:startDelivery",
"End": true
}
}
},
"ResultPath": "$.detail.processedItems",
"Next": "SendOrderSummary"
},
"SendOrderSummary": {
"Type": "Task",
"InputPath": "$.detail.processedItems",
"Resource": "arn:aws:lambda:us-west-2:123456789012:function:sendOrderSummary",
"ResultPath": "$.detail.summary",
"End": true
}
}
}The Lambda functions used by this workflow are not aware of the overall structure of the order JSON document. They just need to know the part of the input state they are going to process. This is a best practice to make those functions easily reusable in multiple workflows. The state machine definition is manipulating the path used for the input and the output of the functions using JsonPath syntax via the InputPath, ItemsPath, ResultPath, and OutputPath fields:
InputPathis used to filter the data in the input state, for example to only pass thedetailof the order to theIterator.ItemsPathis specific to theMapstate and is used to identify where, in the input, the array field to process is found, for example to process theitemsinside thedetailof the order.ResultPathmakes it possible to add the output of a task to the input state, and not overwrite it completely, for example to add asummaryto thedetailof the order.- I am not using
OutputPaththis time, but it could be useful to filter out unwanted information and pass only the portion of JSON that you care about to the next state. For example, to send as output only thedetailof the order.
Optionally, the Parameters field may be used to customize the raw input used for each iteration. For example, the deliveryAddress is in the detail of the order, but not in each item. To have the Iterator have an index of the items, and access the deliveryAddress, I can add this to a Map state:
"Parameters": {
"index.$": "$$.Map.Item.Index",
"item.$": "$$.Map.Item.Value",
"deliveryAddress.$": "$.deliveryAddress"
}Available Now
This new feature is available today in all regions where Step Functions is offered. Dynamic parallelism was probably the most requested feature for Step Functions. It unblocks the implementation of new use cases and can help optimize existing ones. Let us know what are you going to use it for!
— Danilo