Amazon Web Services 한국 블로그
Amazon DynamoDB 데이터 백업 및 복원 방법 – (1) Datapipeline 및 오픈 소스 도구 활용하기
Amazon DynamoDB는 서비스 규모와 관계없이 10밀리초 미만의 지연 시간이 일관되게 요구되는 모든 애플리케이션을 위한 빠르고 유연한 NoSQL 데이터베이스 서비스입니다. 또한, 완전 관리형 클라우드 데이터베이스로서 문서 모델과 키-값 스토어 모델을 모두 지원합니다. 특히, 유연한 데이터 모델과 안정적인 성능을 갖추고 있어 모바일, 웹, 게임, 광고 기술, IoT를 비롯한 그 밖의 많은 애플리케이션에 매우 적합합니다.
특히 Amazon DynamoDB는 AWS 리전의 세 개 시설에 데이터를 동기적으로 적재하는 구조를 가지고 있어, 매우 높은 가용성과 데이터 안정성을 제공합니다. 따라서, 데이터 유실에 대한 우려를 크게 낮출 수 있습니다. 그런데, 필요에 따라서 DynamoDB에 저장되어 있는 데이터를 백업하거나 다른 리전으로 복사해야 할 필요가 생길 수 있습니다. 이는 전통적인 데이터 유실에 대한 데이터 백업이나 복원 목적이라기 보다는 로컬에서 데이터 활용을 하거나, 타 리전에 데이터 이동에 목적으로 생각할 수 있습니다.
이 글에서는 DynamoDB에 저장된 데이터를 백업하는 몇 가지 방법을 알아보도록 하겠습니다. Amazon DynamoDB를 이용하여 테이블(Table)을 생성하면 DynamoDB는 직접 내보내기 및 가져오기 기능을 제공하고 있습니다. 원하면 언제든지 테이블의 내용을 백업하거나, 백업한 테이블의 내용을 다른 테이블로 넣을 수 있습니다.
DynamoDB 내보내기(Export) 기능
먼저 테이블 내보내기 기능 부터 살펴 보겠습니다. 아래의 그림과 같이 원하는 테이블을 선택하고 Export를 실행하면됩니다.

DyanmoDB의 내보내기 기능은 AWS의 다른 서비스 중 하나인 AWS Data Pipeline을 이용합니다. Data Pipeline은 Amazon EMR을 실행하도록 되어 있으며, 바로 EMR Cluster를 생성하고 생성된 EMR Hadoop Cluster가 바로 DyanmoDB의 데이터를 가져오는하는 작업(Job)을 실행하는 구조로 되어 있습니다.
AWS Data Pipeline은 DynamoDB 테이블 백업 뿐만 아니라 온프레미스 데이터 소스 및 다른 AWS 컴퓨팅 및 스토리지 서비스 간에 데이터를 안정적으로 지정된 간격으로 이동할 수 있게 해 주는 서비스입니다. AWS Data Pipeline을 사용하면 저장 데이터에 정기적으로 접근하고, 데이터 크기를 변환 처리하며 Amazon S3, Amazon RDS, Amazon DynamoDB 및 Amazon Elastic MapReduce(EMR)와 같은 AWS 서비스에 그 결과를 효율적으로 전송할 수 있습니다.
DynamoDB에서도 테이블을 선택하고 내보내기(Export)를 누르면 아래와 같이 새로운 파이프라인(Pipeline)을 생성합니다. 테이블의 내용을 바로 Amazon Simple Storage Service(S3)에 저장합니다.

Source DynamoDB table name은 내보내고 싶은 테이블명으로 자동으로 입력이 되어 있습니다. Output S3 folder는 내보내기 후 데이터가 저장될 S3 버킷 폴더를 지정합니다. DynamoDB read throughput ratio는 현재 소스가 되는 DynamoDB의 읽기 용량 중에 어느 정도 비율을 사용할지 지정하는 중요한 파라미터입니다. 만약 운영 중인 서비스의 테이블이라면 읽기 용량의 일부를 지정한 비율만큼 내보내기 작업에 사용하므로, 너무 큰 비율을 지정하면 읽기 용량이 모자라게 되면 서비스에 영향이 있으므로 주의하여야 합니다.
따라서, Consumed read capacity unit을 CloudWatch 통계치를 확인하여 적절한 비율을 입력하도록 합니다. 위의 예제에서는 0.25로 기본 값이 지정되어 있습니다. 즉, Provisioned Read Capacity Unit중에 약 25%를 내보내기를 하는데 사용합니다. Throughput ratio를 정식 서비스 환경에서는 항상 유의하여 지정해야만 합니다. Region은 DynamoDB 테이블이 있는 리전을 선택합니다. Schedule은 Data Pipeline에서 바로 실행할지, 아니면 특정 시기/시간에 주기적으로 실행할지 여부를 구성합니다.
주기적으로 실행하도록 구성하면 Data Pipeline이 알아서 주기적으로 DynamoDB 테이블 내보내기를 진행하여 운영에 편의성을 제공합니다. Logging은 Log 내용을 남길 S3 위치를 지정하게 됩니다. 뒤에 작업(Job)이 실패했을 경우 문제가 어떤 것인지 찾을 수 있도록 로그 정보를 제공합니다.
Activate를 눌러 다음으로 진행하면 Data Pipeline이 생성됩니다. Data Pipeline은 EMR Cluster를 생성하고 데이터 내보내기를 진행하게 됩니다.
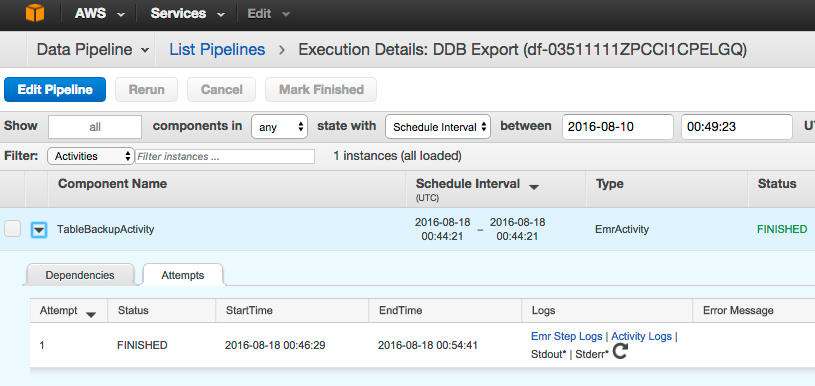
위 그림과 같이 작업이 끝나게 되면 Status가 FINISHED로 상태가 바뀌게 되며, Logs에서 작업 중에 남겨진 로그 내용을 직접 확인할 수도 있습니다. 위 예제에서 s3://ilho-virginia-01 S3 Location을 설정 하였으므로 해당 버킷 밑에서 백업된 파일을 직접 확인할 수 있습니다.

작업이 일어난 시간으로 폴더가 생성되고 내보내기한 파일이 조금 복잡한 이름으로 생성되어 저장이 되어 있습니다. 나중에 해당파일을 직접 접근할 때는 manifest파일을 보면 안에 해당 파일에 대한 s3 주소가 저장되어 있어, 직접 확인하지 않고도 접근할 수도 있습니다. 아래는 내보낸 DynamoDB 테이블 데이터 내용입니다. (예제는 웹페이지의 레퍼러(referrer)를 저장한 테이블입니다.)
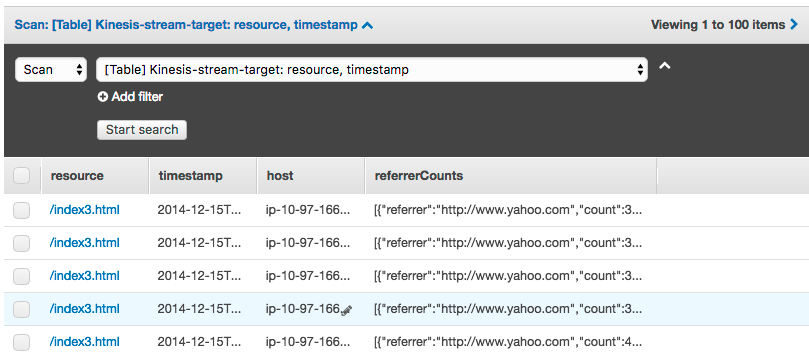
파일을 열어보면 아래와 같이 JSON 형태로 저장되어 있는 것을 확인 하실 수 있습니다. 따라서, 해당 파일을 데이터 분석과 같은 다른 용도로 사용할 경우, 빠르게 활용할 수 있습니다.

DynamoDB Import 기능 소개
내보내기 파일을 이용하여 새로운 DynamoDB Table에서 해당 데이터를 가져오기(Import)할 수 있습니다. 단, 동일한 키(key)를 가지도록 먼저 대상 테이블(Target table)을 생성하고 가져와야 합니다. 따라서, 먼저 테이블을 생성하고, Primary Partition key, Primary Sort key를 동일하게 설정하여 새로운 테이블을 만듭니다.
아래와 같이 Import-test라는 테이블을 만들고 resource, timestamp를 Partition key와 Sort key로 지정하였습니다. 한가지 고려할 사항은 처리 용량(Provisioned Capacity)을 지정할 때 기본 값보다는 쓰기 용량(Write Capacity units)을 크게 지정하여 가져오기 하는 시간을 단축할 수 있습니다.

새로 생성된 테이블을 선택하고 Import를 메뉴에서 선택합니다. 역시 Data Pipeline을 설정하는 페이지가 열리면서 내보내기할 때와 비슷한 내용을 입력합니다. 단, Import 이므로 반대로 Input S3 folder로 Export에 백업 파일이 있는 위치를 입력합니다. 내보내기할 때는 읽기 용량(Read capacity)사용에 대한 비율을 지정하였으나, 가져오기에서는 반대로 쓰기 용량(Write capacity)에 대해서 설정을 합니다. 새로 만든 테이블이므로 최대한 빠르게 가져오기를 진행하려면 100%로 지정하여, 모든 Write capacity를 가져오기에 사용할 수 있습니다. 단, 이는 예제이므로 서비스 상황에 따라 설정하여 사용합니다.

설정 후에 Activate를 진행하면 Data Pipeline이 생성되고 EMR Cluster를 생성하여 S3에 Export된 데이터로부터 DynamoDB Table에 데이터를 넣는 작업(Job)을 실행합니다. Job이 FINISHED로 끝난 것을 확인하고 대상이 되는 Table에 실제 데이터가 들어왔는지 확인합니다.

테이블에 데이터가 입력된 것을 확인 할 수 있으며, CloudWatch 통계에서 읽기 처리 그래프(Write Capacity Graph)를 보면 입력한 것처럼 전체 읽기 용량을 이용하여 데이터 가져오기 작업을 진행한 것을 확인 할 수 있습니다. (본 예제에서는 쓰기 용량(Write capacity) 값을 100으로 미리 설정(Provisioning)하고, 일정시간 동안 100의 용량이 소모된 것을 볼 수 있습니다.)

한 가지 유의하실 것이 있습니다. DynamoDB의 Table 설명 정보에는 Storage size와 Item count 정보가 있습니다. 이 정보는 현재는 약 6시간 주기로 업데이트 되는 정보로 가져오기를 끝내자 마다 해당 정보 내용을 확인하신다면, 아직 0으로 표기가 되어 있게 됩니다. 따라서 실제 데이터를 직접 읽어 확인해 보는게 필요합니다. AWS CLI에서 보면 아래와 같이 확인이 가능합니다. 참고하여 주십시오.
$ aws dynamodb describe-table --table-name Import-test --query 'Table.{Count:ItemCount,Size:TableSizeBytes}'
{
"Count": 0,
"Size": 0
}
$ aws dynamodb scan --table-name Import-test --max-item 2
{
"Count": 2777,
"Items": [
{
"timestamp": {
"S": "2014-12-15T12:49:10.147Z"
},
"host": {
"S": "ip-10-97-166-72"
},
"resource": {
"S": "/index3.html"
},
"referrerCounts": {
"S": "[{\"referrer\":\"http://www.yahoo.com\",\"count\":3},{\"referrer\":\"http://www.reddit.com\",\"count\":1},{\"referrer\":\"http://www.bing.com\",\"count\":1},{\"referrer\":\"http://www.amazon.com\",\"count\":1}]"
}
},
{
"timestamp": {
"S": "2014-12-15T12:49:10.247Z"
},
"host": {
"S": "ip-10-97-166-72"
},
"resource": {
"S": "/index3.html"
},
"referrerCounts": {
"S": "[{\"referrer\":\"http://www.yahoo.com\",\"count\":3},{\"referrer\":\"http://www.reddit.com\",\"count\":1},{\"referrer\":\"http://www.bing.com\",\"count\":1},{\"referrer\":\"http://www.amazon.com\",\"count\":1}]"
}
}
],
"NextToken": "eyJFeGNsdXNpdmVTdGFydEtleSI6IG51bGwsICJib3RvX3RydW5jYXRlX2Ftb3VudCI6IDJ9",
"ScannedCount": 2777,
"ConsumedCapacity": null
}DynamoDB Import Export 도구
AWS 콘솔에서 제공하는 가져오기 및 내보내기 기능이 아닌 오픈 소스로 제공되는 https://github.com/awslabs/dynamodb-import-export-tool이 Github에 공개되어 있습니다. 간략히 설명 드리면, Java로 개발된 도구로 Data Pipeline이나 EMR을 사용하지 않고, 프로그램이 직접 DynamoDB의 데이터를 가져와서 타겟 DynamoDB Table에 데이터를 넣어주는 일을 하게 됩니다. 또한 병렬 검색(Parallel Scan)을 지원하여, 단일 EC2 인스턴스가 아닌 여러 인스턴스를 사용하여 병렬로 작업이 가능합니다. 아래 예제는 Amazon Linux AMI를 이용해 새로운 인스턴스를 생성하고 백업 및 복원을 진행 하는 방법입니다.
- 빌드를 위해서는 maven이 필요합니다. Maven을 받아 설치를 합니다.
$ wget http://ftp.kddilabs.jp/infosystems/apache/maven/maven-3/3.3.9/binaries/apache-maven-3.3.9-bin.tar.gz $ tar -zxvf ./apache-maven-3.3.9-bin.tar.gz - 미리 Java JDK를 설치하여 mvn install 시에 중간에 에러가 없도록 준비합니다.
$ sudo yum install -y java-1.7.0-openjdk-devel - Github 의 소스를 Local로 가져옵니다.
$ git clone https://github.com/awslabs/dynamodb-import-export-tool.git - 아래 명령을 통해 빌드와 설치를 진행합니다.
$ mvn install …………………………………… [INFO] Replacing /opt/dynamodb-import-export-tool/target/dynamodb-import-export-tool-1.0.1.jar with /opt/dynamodb-import-export-tool/target/dynamodb-import-export-tool-1.0.1-shaded.jar [INFO] [INFO] --- maven-gpg-plugin:1.6:sign (sign-artifacts) @ dynamodb-import-export-tool --- Downloading: https://repo.maven.apache.org/maven2/org/sonatype/plexus/plexus-sec-dispatcher/1.4/plexus-sec-dispatcher-1.4.pom Downloaded: https://repo.maven.apache.org/maven2/org/sonatype/plexus/plexus-sec-dispatcher/1.4/plexus-sec-dispatcher-1.4.pom (3 KB at 9.9 KB/sec) Downloading: https://repo.maven.apache.org/maven2/org/sonatype/plexus/plexus-sec-dispatcher/1.4/plexus-sec-dispatcher-1.4.jar Downloaded: https://repo.maven.apache.org/maven2/org/sonatype/plexus/plexus-sec-dispatcher/1.4/plexus-sec-dispatcher-1.4.jar (28 KB at 90.8 KB/sec) [INFO] [INFO] --- maven-install-plugin:2.4:install (default-install) @ dynamodb-import-export-tool --- [INFO] Installing /opt/dynamodb-import-export-tool/target/dynamodb-import-export-tool-1.0.1.jar to /root/.m2/repository/com/amazonaws/dynamodb-import-export-tool/1.0.1/dynamodb-import-export-tool-1.0.1.jar [INFO] Installing /opt/dynamodb-import-export-tool/pom.xml to /root/.m2/repository/com/amazonaws/dynamodb-import-export-tool/1.0.1/dynamodb-import-export-tool-1.0.1.pom [INFO] ------------------------------------------------------------------------ [INFO] BUILD SUCCESS [INFO] ------------------------------------------------------------------------ [INFO] Total time: 34.017 s [INFO] Finished at: 2016-08-01T01:12:26+00:00 [INFO] Final Memory: 20M/50M [INFO] ------------------------------------------------------------------------ - 최종 빌드 된 jar파일이 있는 폴더로 이동하여 Github에 나온 안내를 참고하여 필요한 인자(Argument)를 주어 실행합니다. 아래 예제는 버지니아 리전에 있는 Kinesis-Data-Visualization-CountsDynamoDBTable-49AHMYW180WC 테이블을 동일한 리전에 Kinesis-target-3이라는 테이블로 복제하는 명령입니다. 이 도구에서도 읽기 혹은 쓰기 용량(read/write capacity)에 대해서 비율를 지정하여 얼마만큼의 Provisioned Capacity를 사용할지 지정을 하게 됩니다. 여기서는 1로 지정하여 100%를 다 사용하도록 지정하였습니다.
$ java -jar dynamodb-import-export-tool-1.0.1.jar --sourceEndpoint dynamodb.us-east-1.amazonaws.com --sourceTable Kinesis-Data-Visualization-CountsDynamoDBTable-49AHMYW180WC --destinationEndpoint dynamodb.us-east-1.amazonaws.com --destinationTable Kinesis-target-3 --readThroughputRatio 1 --writeThroughputRatio 1
앞서 말씀 드린 대로 Amazon DynamoDB는 고가용성과 안정성을 지원하도록 디자인된 관리형 서비스입니다. 가용성 측면보다 데이터 활용 측면에서 데이터 이동이 필요한 경우에는 Datapipeline을 통한 DynamoDB 가져오기 및 내보내기 기능 및 오픈 소스 도구를 활용할 수 있습니다.
또한, DynamoDB Stream을 통한 크로스 리전 복제 솔루션 역시 사용이 가능합니다. 다음에는 오픈 소스로 공개되어 있는 DynamoDB Cross-Region Replication Library를 통해 실시간 복제 방법에 대해서 알아보겠습니다.
본 글은 아마존웹서비스 코리아의 솔루션즈 아키텍트가 국내 고객을 위해 전해 드리는 AWS 활용 기술 팁을 보내드리는 코너로서, 이번 글은 김일호 솔루션즈 아키텍트께서 작성해주셨습니다.
