Amazon Web Services 한국 블로그
MXNet 기반 Sockeye를 통한 기계 번역 학습 해보기
언어 번역을 위해 기계 학습(Machine Learning)을 어떻게 사용할 수 있는지 궁금하신가요? AWS가 공개한 새로운 프레임워크인 Sockeye를 사용하면 기계 번역(Machine Translation) 및 기타 시퀀스 간 작업을 모델링 할 수 있습니다. Sockeye는 Apache MXNet을 기반으로 만들어져 있으며, 시퀀스-시퀀스(Sequence-to-Sequence) 모델 구축, 트레이닝 및 운영에 필요한 작업을 수행할 수 있습니다.
우선 기계 번역에 필요한 자연어 처리(NLP)에서 많은 작업은 시퀀스 예측 문제를 해결하는 데 집중합니다. 예를 들어, 기계번역에서 특정 작업은 일련의 입력 단어가 주어지면 번역된 단어의 순서를 예측합니다. 이러한 종류의 작업을 수행하는 모델을 시퀀스-시퀀스 모델이라고합니다. 최근에는 심층 신경망 (Deep Neural Networks)가 이러한 모델의 성능을 크게 향상 시켰습니다. Sockeye는 신경망 기반 기계 번역 (NMT)모델을 구현하고, NMT 연구를 수행하는 플랫폼을 제공합니다.
Sockeye는 빠르고 확장 가능한 딥러닝 학습 라이브러리인 Apache MXNet을 기반으로합니다. Sockeye 소스 코드는 MXNet의 고유 한 기능을 활용합니다. 예를 들어, 선언 및 명령어 기반 프로그래밍 스타일을 그대로 활용하여 명령형 MXNet API 활용할 뿐만 아니라 데이터 병렬 처리를 사용하여 멀티 GPU에서 모델을 학습합니다.
이 글에서는 NMT의 개요를 설명한 다음 Sockeye를 사용하여 최소한의 NMT 모델을 훈련시키는 방법을 소개함으로서 어떻게 기계 번역 프로젝트를 시작할 수 있는지 살펴보겠습니다.
시퀀스-시퀀스 모델 동작 방법
Sockeye에서 진행중인 작업을 이해하기 위해 많은 학계와 업계에서 일반적으로 사용하는 신경망 아키텍처를 살펴 보겠습니다.
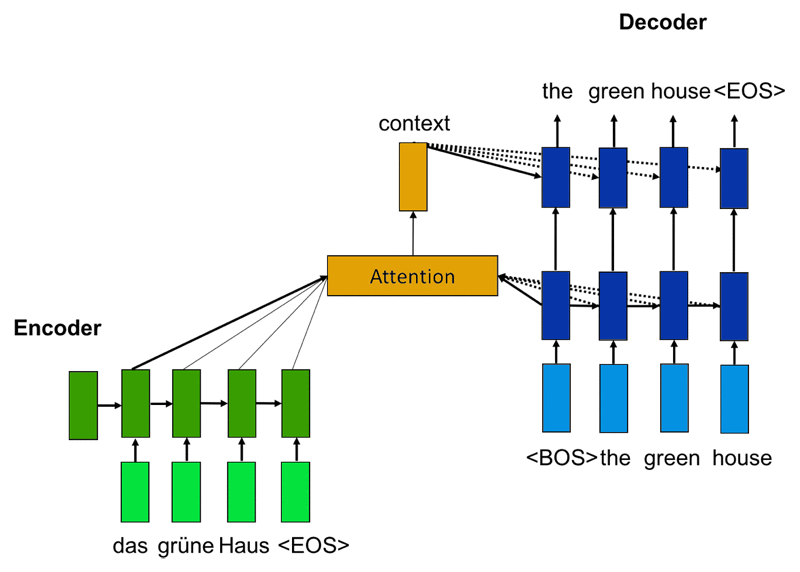
네트워크에는 세 가지 주요 구성 요소 인코더, 디코더, 주의 메커니즘(Attention mechanism)이 있습니다. 인코더는 문장의 끝(<EOS>)까지 한 번에 한 단어 씩 원본 문장을 읽고 숨겨진 문장을 만듭니다. 인코더는 종종 LSTM(long-term-memory) 네트워크와 같은 순환 신경망(Recurrent Neural Networks, RNN)로 구현됩니다.
디코더는 RNN으로 구현되어 문장의 시작 부분 (<BOS>)으로 시작하여 한 번에 한 단어 씩 대상 문장을 생성합니다. 콘텍스트 벡터를 생성한 주의 메커니즘을 통해 원본 문장에 접근할 수 있습니다. 주의 메커니즘을 사용하여 디코더는 다음 단어를 생성하는 데, 가장 적합한 단어를 결정할 수 있습니다. 이 방법을 통해 디코더는 항상 전체 입력 문장에 접근할 수 있습니다.
신경망이 생성하는 다음 단어는 디코더에 대한 입력이됩니다. 디코더는 생성 된 단어 및 숨겨진 표현을 기반으로 후속 단어를 생성합니다. 네트워크는 <EOS>와 같은 문장 끝 기호를 생성 할 때까지 단어 생성을 계속합니다.
Sockeye – MXNet기반 기계 번역을 위한 시퀀스-시퀀스 모델링
Sockeye는 MXNet을 기반으로 시퀀스-시퀀스 모델을 구현합니다. 이 모델의 모든 가상 매개 변수에 적절한 기본값을 제공합니다. 최적화를 위해 중단 기준(stopping criteria), 통계 추적(metric tracking), 및 가중치 초기화(weight initialization)에 대해 걱정할 필요가 없습니다. 트레이닝을 위해 간단한 명령줄 인터페이스(CLI)를 통해 실행할 수 있습니다.
다음 요소를 포함하여 기본 모델 아키텍처를 쉽게 변경할 수 있습니다.
- RNN 셀 유형 (LSTM 또는 GRU) 및 숨겨진 상태 크기
- RNN 레이어의 수
- 소스 및 대상 시퀀스 포함 크기
- 소스 인코딩에 적용된주의 메커니즘 유형
Sockeye는 다음과 같은 고급 기능도 지원합니다.
- Beam search inference
- Easy ensembling of multiple models
- Residual connections between RNN layers (Wu et al., 2016)
- Lexical biasing of output layer predictions (Arthur et al., 2016)
- Modeling coverage (Tu et al., 2016)
- Context gating (Tu et al., 2017)
- Cross-entropy label smoothing (e.g., Pereyra et al., 2017)
- Layer normalization (Ba et al, 2016)
트레이닝을 위해 Sockeye는 중요한 최적화 매개 변수를 완벽하게 제어 할 수 있습니다. 예를 들어, 옵티 마이저 유형(optimizer types), 학습 속도(learning rate), 모멘텀(momentum), 가중치 감소(weight decay) 및 조기 정지 조건(early-stopping conditions)을 설정할 수 있습니다. Sockeye는 트레이닝 및 검증 데이터에 대한 여러 측정 항목(BLEU와 같은 MT 관련 측정 항목 포함)을 추적합니다.
앞으로 NMT에 대한 새로운 아이디어를 실험 할 수있는 플랫폼을 여러분에게 제공하기 위해 Sockeye 기능을 지속적으로 확장 할 계획입니다.
자동 번역을 위한 최소 모델 트레이닝 해보기
이제 첫 번째 NMT 모델을 트레이닝을 해 봅시다. 실습은 간단하게 Linux 또는 Mac OS X와 등의 운영체제 셀 명령어로 진행됩니다.
1. 데이터 세트 가져오기
먼저 문장 목록과 번역본을 가진 병렬 코퍼스(Parallel Corpus)를 가져옵니다. Sockeye는 모든 입력 데이터가 공백으로 구분되도록 하고, 데이터를 보내기 전에 항상 단어와 구두점을 구분하는 토크 나이저를 실행합니다. 이 글에서는 Conference on Machine Translation (WMT)에서 사용한 2017 뉴스 번역 작업에서 사용한 샘플 데이터를 다운로드합니다.
뉴스 기사에서 독일어 및 영어로 된 문장을 다운로드하려면 다음 쉘 명령을 사용하십시오.
트레이닝에서는 처음으로 1,000,000 문장 만 사용합니다. 실제로는 훨씬 큰 데이터 세트를 모델 학습하게 됩니다. 트레이닝 과정에서 보이지 않는 문장에 대한 품질 통계를 추적하려면, 유효성 검증 세트를 다운로드하십시오.
이제 병렬 훈련 문장을 포함한 train.de 및 train.en 파일과 유효성 검사 문장이 포함 된 newstest2016.tc.de 및 newstest2016.tc.en 파일을 다운 받았습니다. 본 모델이 이전에 보지 못했던 새로운 문장에 대해 얼마나 잘 수행 할 것인지를 정확하게 예측하기 위해 훈련 중에 보지 못한 문장에 대한 모델을 평가하는 것이 중요합니다.
2. Sockeye 설치하기
모델 컴퓨팅 비용이 비싸기 때문에 일반적으로 Sockeye를 GPU에서 실행하는 것이 좋습니다만, GPU 없이 컴퓨터에서 실행할 수도 있습니다. CPU에서 Sockeye를 실행하려면 다음 명령을 사용하여 Sockeye를 설치하십시오.
주의: CPU에서 Sockeye를 실행할 때는 --use-cpu 를 모든 명령에 추가해야 합니다. 그렇지 않으면 Sockeye는 GPU에서 실행하려고 시도하고 실패합니다. GPU를 사용할 수있는 경우 다음 명령을 사용하여 CUDA 8.0 용 Sockeye를 설치하십시오.
CUDA 7.5 용으로 설치하려면 다음 명령을 사용하십시오.
3. 모델 학습하기
이제 모든 독일어 – 영어 NMT 모델을 익힐 수 있습니다. 다음 명령을 실행하여 교육을 시작하십시오.
이는 128 및 512개의 숨겨진 단위를 포함한 모델을 학습합니다. 학습 과정에서 Sockeye는 정기적으로 유효성 측정 지표를 인쇄합니다.
AWS의 p2 인스턴스에서 한개의 K80 GPU로 학습하는 데는 약 13시간이 걸립니다. 학습이 끝나면 모델이라는 매개 변수와 같은 모든 아티팩트를 model이라는 디렉토리에서 찾을 수 있습니다. (GPU가 더 많은 P2 인스턴스를 활용하면 더 빠르게 끝납니다.)
4. 번역해보기
모델을 학습한 후 토큰 화 된 문장을 입력하여 번역을 시작할 수 있습니다.
이것은 “Green Houce”로 해석됩니다. 좀 더 어려운 문장을 번역 해 보려면, 공백으로 모든 단어와 구분되는 토큰 화 된 문장을 입력하십시오. 모델이 단어를 모르는 경우, <UNK> 토큰을 나타내는 것을 알 수 있습니다.
주의 네트워크를 시각화 할 수도 있습니다. 이를 위해 matplotlib 를 추가로 설치 해야합니다 (아직 수행하지 않은 경우).
주의 네트워크를 시각화하는 align_1.png 파일을 만들려면 출력 유형을 align_plot으로 설정하십시오.
결과는 다음과 유사해야 합니다.
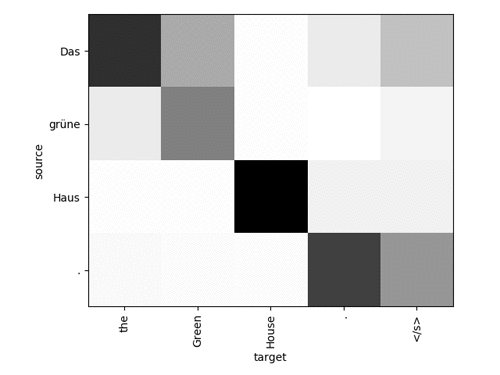
대상의 각 단어에 대해 네트워크에서 주목 한 단어를 소스에서 확인합니다. 고 품질 번역을 하기 위해, 모델에 주의를 기울일 필요는 없습니다. 더 복잡한 문장의 경우 다음과 같이 보입니다.
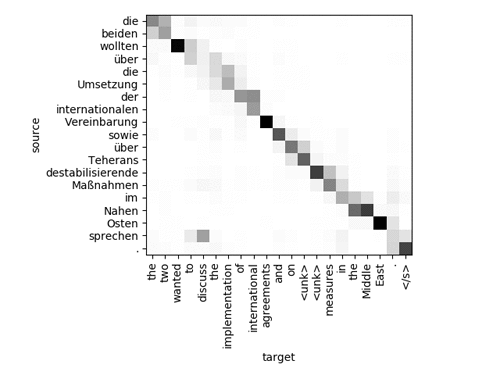
본 모델은 “sprechen”이라는 단어가 문장에서 매우 다른 위치에 있음에도 불구하고 영어로 “discussion”한다는 것을 알아 냈습니다. 또한 네트워크가 일부 단어를 알고 <UNK> 토큰으로 그들을 표현되지 않은 것을 볼 수 있습니다.
결론
이 글에서는 NMT의 sequence-to-sequence 모델과 MXNET을 기반으로 한 시퀀스 간 프레임 워크 인 Sockeye를 사용하여 최소 NMT 모델을 학습하고 실행하는 방법을 배웠습니다. 질문이나 제안 사항이나 Sockeye와 관련된 문제가 발생하면 GitHub의 문제 추적기를 통해 알려주십시오.
이 글은 Amazon AI 블로그의 Train Neural Machine Translation Models with Sockeye의 한국어 번역으로 Amazon Berlin에서 기계 번역 연구를 하고 있는 Felix Hieber 및 Tobias Domhan이 작성하였습니다.