Amazon Web Services 한국 블로그
AWS Glue를 이용한 파티션 데이터 처리
AWS Glue는 Hive 스타일 파티션으로 구성된 데이터 세트 처리에 향상된 기능을 제공합니다. AWS Glue 크롤러는 Amazon S3에 저장된 데이터의 파티션을 자동으로 구별합니다. AWS Glue ETL(추출, 변환, 로드) 라이브러리는 DynamicFrames로 작업할 때 기본적으로 파티션을 지원하며, DynamicFrames는 스키마를 지정하지 않더라도 분산된 데이터 콜렉션을 나타냅니다. DynamicFrames를 생성할 때 S3를 호출하지 않더라도 서술자를 통해 파티션을 필터링할 수 있습니다. 또한 DynamicFrames를 Aparche Spark DataFrames로 변환하지 않고 파티셔닝 된 디렉토리에 직접 쓰는 기능이 추가되었습니다.
파티셔닝은 다양한 빅데이터 시스템에서 효율적으로 쿼리가 가능하도록 데이터 세트를 구성하는데 중요한 기술입니다. 데이터는 하나 이상 컬럼의 고유값에 기반하여 계층적인(hierarchical) 디렉토리 구조로 구성됩니다. 예를 들어, Amazon S3에 애플리케이션 로그를 날짜(연, 월, 일) 기준으로 파티션을 나눌 수 있습니다. 이 경우 하루 동안의 로그 데이터는 s3://my_bucket/logs/year=2018/month=01/day=23/ 과 같은 프리픽스 아래에 저장 됩니다.
Amazon Athena, Amazon Redshift Spectrum, AWS Glue와 같은 서비스들은 이렇게 파티션 된 데이터를 이용하여 S3에 불필요한 호출을 수행하지 않고도 데이터를 필터링 할 수 있습니다. 이렇게 하면 몇 개의 파티션만 읽는 애플리케이션의 성능이 크게 향상됩니다.
이 글을 통해 AWS Glue를 사용하여 파티션 된 데이터 세트를 효율적으로 처리하는 방법을 설명합니다. 우선 Glue 크롤러를 설정하여 자동으로 파티션 된 데이터 세트를 스캔하고 AWS Glue 데이터 카탈로그에서 테이블과 파티션을 생성하는 방법에 대해 설명합니다. 그 뒤 AWS Glue 라이브러리를 이용하여 파티션 된 데이터를 처리하는 기능을 살펴봅니다. 이제 SQL 표현식이나 사용자 정의 함수를 활용하여 파티션을 필터링함으로 Amazon S3에서 불필요한 데이터를 읽지 않아도 됩니다. 추가로 Spark SQL DataFrames에 의존하지 않고 AWS Glue DynamicFrames를 파티션에 직접 쓸 수 있도록 ETL 라이브러리 기능이 추가 되었습니다.
파티션 된 데이터 크롤링
이 예제에서는 Scala support in AWS Glue 포스트에서 사용한 GitHub archive 데이터세트를 활용합니다. 이 데이터는 GitHub archive의 공개 데이터로GibHub 서비스로의 모든 API 요청을 JSON 형태의 레코드로 갖고 있습니다. 2017년 1월 이후 한달 간의 데이터를 포함한 샘플 데이터 세트는 다음 경로에서 이용할 수 있습니다:
s3://aws-glue-datasets-<region>/examples/githubarchive/month/data/<region>은 이용 중인 AWS 리전으로 변경(us-east-1의 형태) 해야 하고, 데이터세트는 연, 월, 일로 파티션되어 있기 때문에 실제 파일의 경로는 다음과 같습니다:
s3://aws-glue-datasets-us-east-1/examples/githubarchive/month/data/2017/01/01/part1.json이 데이터를 크롤링하기 위해서는 AWS Glue Developer Guide를 참고하거나 제공된 AWS CloudFormation템플릿을 활용할 수 있습니다. 템플릿을 통해 생성하는 AWS CloudFormation 스택에는 다음의 내용이 포함되어 있습니다:
- AWS Glue 리소스에 접근하기 위한 IAM 역할
- AWS Glue 데이터 카탈로그의 githubarchive_month 데이터베이스
- GitHub 데이터세트를 크롤링하기 위한 Glue 크롤러
- AWS Glue 개발 엔드포인트(다음 섹션에서 데이터 변환에 사용)
스택 생성을 위해서는 Output을 위한 S3 버킷과 프리픽스를 제공해야 하며, 템플릿을 통해 생성되는 IAM 역할의 경우 해당 버킷에만 쓰기 권한을 갖습니다. 또한 개발 엔드포인트 접근을 위한 공개 SSH 키를 제공해야 합니다. SSH 키를 생성하는 방법에 관해서는 Development Endpoint tutorial에 자세한 설명이 나와있습니다. AWS CloudFormation스택을 생성하고 난 뒤에는 AWS Glue 콘솔에서 크롤러를 실행할 수 있습니다.
파일 타입과 스키마를 추론하기 위해 크롤러는 자동으로 데이터 세트의 파티션 구조를 확인하고 AWS Glue Data Catalog 를 구성합니다. 이를 통해 데이터가 논리 테이블에 정확히 그루핑(grouping)되고 AWS Glue ETL 작업이나 Amazon Athena와 같은 쿼리 엔진이 파티션 컬럼을 이용할 수 있게 됩니다.
테이블을 크롤링한 뒤에는 AWS Glue 콘솔의 테이블로 이동하면 View partitions 메뉴를 선택해 파티션을 볼 수 있습니다. 파티션은 다음과 같은 형태로 보여집니다:
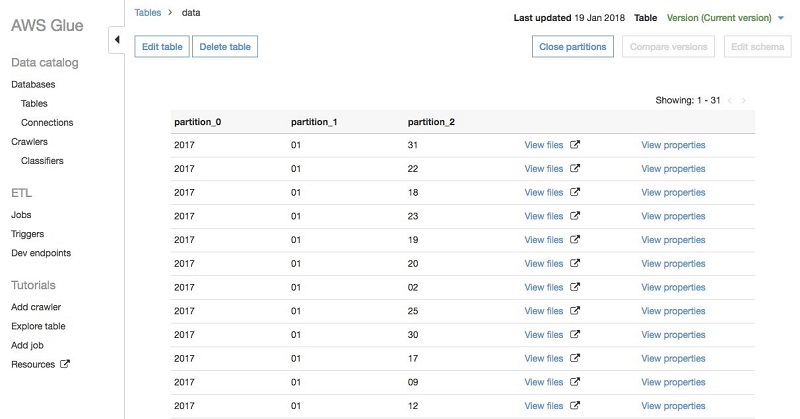
key=val 형태의 Hive 스타일로 파티션 된 경로는 크롤러가 자동으로 컬럼명을 채웁니다. 이번 경우에는 GitHub 데이터가 2017/01/01 의 형태로 디렉토리에 저장되어 있기 때문에 크롤러가 partition_0, partition_1 과 같은 형태의 디폴트 컬럼명을 사용했습니다. 이러한 이름은 AWS Glue 콘솔에서 쉽게 변경할 수 있습니다: 테이블로 이동한 뒤 Edit schema 옵션을 선택하고, partition_0 을 year로 partition_1 은 month 로 마지막으로 partition_2 는 day로 변경합니다.
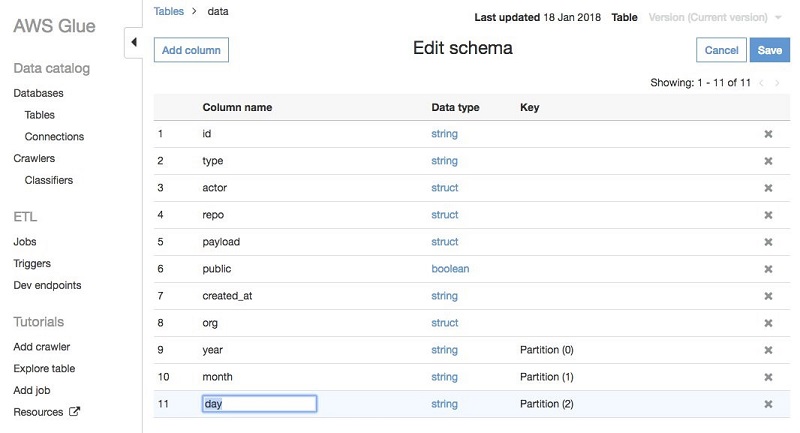
여기까지 했다면 데이터 세트를 크롤링한 뒤 파티션을 적합하게 변경한 것입니다. 이제 AWS Glue ETL 작업에서 파티션 된 데이터를 어떻게 이용하는지 살펴보겠습니다.
데이터 변형과 필터링
AWS Glue ETL 라이브러리를 사용하기 위해서 AWS Glue 개발 엔트포인트와 Apache Zeppelin 노트북을 사용할 수 있습니다. AWS Glue 개발 엔드포인트는 Apache Spark과 AWS Glue ETL 라이브러리를 사용하여 스크립트를 작성하고 실행할 수 있는 대화형(interactive) 환경을 제공합니다. 이러한 개발 환경은 디버깅, 탐색적 분석, 반복적인 작업으로 마이그레이션 하기 전 스크립트를 개발하고 테스트 하는데 유용합니다.
이전 섹션에서 AWS CloudFormation 템플릿을 이용했다면 이미 partition-endpoint 라는 이름의 개발 엔드포인트가 생성되어 있습니다. 그렇지 않다면 development endpoint tutorial 의 가이드를 따르면 됩니다. 이러한 방법은 모두 locally이나 EC2 instance에서 Apache Zeppelin 노트북 세팅이 필요합니다. 개발 엔드포인트와 노트북 설정에 관한 더 자세한 정보는 AWS Glue Developer Guide 를 참고하기 바랍니다.
다음 예제는 Scala 프로그래밍 언어를 기반으로 작성되었지만 조금 수정하면 Python으로 실행도 가능합니다.
파티션 된 데이터 세트 읽기
본격적으로 시작하기 위해 데이터 세트를 읽고 파티션이 스키마에 어떻게 반영되어 있는지 확인합니다. 우선 예제에 사용할 클래스들을 임포트하고, 데이터를 읽고 쓰는데 메인으로 사용할 클래스 GlueContext 를 설정합니다.
다음 코드를 Zeppelin 단락에서 실행합니다:
%spark
import com.amazonaws.services.glue.DynamicFrame import com.amazonaws.services.glue.DynamicRecord
import com.amazonaws.services.glue.GlueContext
import com.amazonaws.services.glue.util.JsonOptions import org.apache.spark.SparkContext
import java.util.Calendar
import java.util.GregorianCalendar
import scala.collection.JavaConversions._
@transient val spark: SparkContext = SparkContext.getOrCreate()
val glueContext: GlueContext = new GlueContext(spark)다음 두 가지 사항을 주의 해야 합니다: 첫번째는 각각의 단락은 %spark 으로 시작해서 Scala 코드임을 명시해야 합니다. 둘째로 spark 변수는 @transient 로 표시하여 직렬화(serialization) 이슈를 피해야 합니다. 이것은 Zeppelin 노트북에서 코드를 실행할 때만 필요합니다.
%spark
val githubEvents: DynamicFrame = glueContext.getCatalogSource(
database = "githubarchive_month",
tableName = "data"
).getDynamicFrame()
githubEvents.schema.asFieldList.foreach { field =>
println(s"${field.getName}: ${field.getType.getType.getName}")
}그 뒤 GitHub 데이터를AWS Glue 스크립트에서 사용되는 기본 데이터 구조인 DynamicFrame으로 읽습니다. 이것은 분산된 데이터 콜렉션을 나타냅니다. DynamicFrame은 Spark DataFrame과 유사하지만, ETL 변환에 추가 기능이 있습니다. DynamicFrame은 AWS Glue Now Supports Scala Scripts 와 AWS Glue API documentation 에서 보다 자세한 내용을 다루고 있습니다.
다음 스니펫은 크롤링한 데이터 카탈로그 테이블을 참조하여 DynamicFrame을 생성하고 스키마를 출력합니다.
%spark
val githubEvents: DynamicFrame = glueContext.getCatalogSource(
database = "githubarchive_month",
tableName = "data"
).getDynamicFrame()
githubEvents.schema.asFieldList.foreach { field =>
println(s"${field.getName}: ${field.getType.getType.getName}")
}또한 githubEvents.printSchema() 를 통해 전체 스키마를 출력할 수도 있습니다. 하지만 전체 스키마가 상당히 크기 때문에 이번에는 최상위 컬럼만을 출력했습니다. 이 단락을 실행하는 데는 일반적인 AWS Glue 개발 엔드포인트를 이용했을 때 약 5분 정도 소요됩니다. 실행이 완료되면 다음 아웃풋을 확인할 수 있습니다:
id: string
type: string
actor: struct
repo: struct
payload: struct
public: boolean
created_at: string
year: string
month: string
day: string
org: struct파티션 컬럼인 year, month, day 가 자동으로 각각의 레코드에 추가된 것을 확인할 수 있습니다.
파티션 컬럼을 통한 필터링
데이터를 파티셔닝 하는 큰 이유는 파티션의 하위 집합에서 작업이 더욱 편해지기 때문입니다. 이제부터 파티션 컬럼을 이용하여 데이터를 필터링하는 부분을 다루겠습니다. 특히, 주말 동안의 GitHub 활동을 통해 사람들이 쉬는 시간에 무엇을 개발하고 있는지 살펴보겠습니다. 이를 수행하는 한가지 방법은 앞서 생성한 githubEvents DynamicFrame 에서 filter transformation 을 사용하여 적절한 이벤트를 선택하는 것입니다:
%spark
def filterWeekend(rec: DynamicRecord): Boolean = {
def getAsInt(field: String): Int = {
rec.getField(field) match {
case Some(strVal: String) => strVal.toInt
// The filter transformation will catch exceptions and mark the record as an error.
case _ => throw new IllegalArgumentException(s"Unable to extract field $field")
}
}
val (year, month, day) = (getAsInt("year"), getAsInt("month"), getAsInt("day"))
val cal = new GregorianCalendar(year, month - 1, day) // Calendar months start at 0.
val dayOfWeek = cal.get(Calendar.DAY_OF_WEEK)
dayOfWeek == Calendar.SATURDAY || dayOfWeek == Calendar.SUNDAY
}
val filteredEvents = githubEvents.filter(filterWeekend)
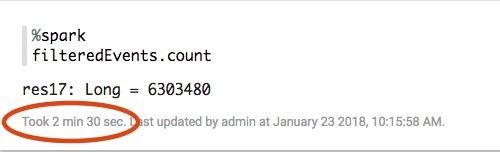
filteredEvents.count이 스니펫은 Java의 Calendar 클래스의 filterWeekend 함수를 정의하여 파티션 컬럼(year, month, day) 중 주말에 해당하는 레코드를 식별합니다. 이 코드를 실행하면 2017년 1월의 주말에 전체 29,160,561개 중 6,303,480개의 GitHub 이벤트가 발생한 것을 알 수 있습니다. 여기에서 22% 의 이벤트가 주말에 발생했고 그 달의 29% 는 주말에 감소한 것을 알 수 있습니다 (31개 중 9개). 그래서 사람들은 주말에 GitHub을 약간 덜 사용하고 있지만, 여전히 꽤 많은 활동을 보여주는 것을 알 수 있습니다!
파티션 컬럼에 대한 술어(Predicate) 푸시 다운
이러한 방식의 필터링 변환을 사용하는 것의 큰 단점은 Amazon S3 데이터의 일부만 필요하더라도 모든 데이터 세트를 리스트하고 읽어야 한다는 것입니다. 이는 한 달 분량의 데이터를 다룰 때는 괜찮지만, 더 많은 데이터를 처리하려고 한다면 레코드를 읽는 작업에 너무 많은 시간이 소모되게 될 것입니다.
이런 이슈를 해결하기 위해 최근에 AWS Glue 데이터 카탈로그에 지정된 파티션 컬럼에 대한 술어를 푸시 다운하는 기능을 최근에 발표했습니다. 데이터를 읽고 클러스터의 실행 프로그램에서 DynamicFrame을 필터링 하는 것 대신에 카탈로그에서 사용할 수 있는 파티션 메타데이터에 필터를 직접 적용할 수 있습니다. 그런 다음 Amazon S3 의 데이터 중 처리가 필요한 것만 리스트하고 읽으면 됩니다.
이를 수행하기 위해 Spark SQL 술어를 getCatalogSource 메소드의 추가적인 파라미터로 지정할 수 있습니다. 이 술어는 필터링을 위해 파티션 컬럼만을 사용하는 한 어떤 SQL 표현식이나 사용자 정의 함수가 될 수 있습니다. 이를 카탈로그에 저장된 메타데이터에 적용하기 때문에 스키마의 다른 필드에는 액세스할 수 없습니다.
다음 스니펫은 이 기능을 활용하여 주말에 발생한 파티션만 읽는 법을 보여줍니다:
%spark
val partitionPredicate =
"date_format(to_date(concat(year, '-', month, '-', day)), 'E') in ('Sat', 'Sun')"
val pushdownEvents = glueContext.getCatalogSource(
database = "githubarchive_month",
tableName = "data",
pushDownPredicate = partitionPredicate).getDynamicFrame()여기에서 SparkSQL 문자열 concat 함수를 사용하여 날짜 문자열을 만듭니다. to_date 함수를 활용하여 이를 날짜 오브젝트로 변한하고 date_format 함수에 ‘E’ 파라미터를 통해 날짜를 3글자 요일(예: Mon, Tue, Wed 등) 로 변환합니다. Spark SQL 표현식 및 일반 사용자 정의 함수에 대한 자세한 내용은 Spark SQL documentation 과 list of functions 에서 확인할 수 있습니다.
pushdownPredicate 파라미터는 Python 에서도 사용할 수 있습니다. Python 에서 해당 함수를 호출하면 다음의 형태입니다:
glue_context.create_dynamic_frame.from_catalog(
database = "githubarchive_month",
table_name = "data",
push_down_predicate = partitionPredicate)각각의 Zeppelin 단락별 실행 시간을 보면 술어를 푸시 다운하는 것이 성능에 많은 영향을 미치는 것을 알 수 있습니다. Scala의 필터 함수를 사용한 것은 약 2.5분 소요됐습니다:
푸시 다운을 사용한 버전은 훨씬 적은 데이터를 리스트하고 읽었기 때문에 실행하는데 24초 밖에 걸리지 않게 됩니다. 성능이 5X 개선되었습니다!
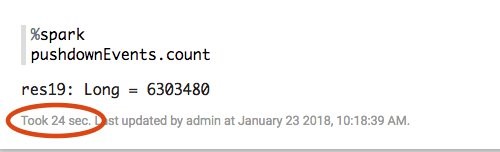
어떤 필터를 선택하는지에 따라 성능은 차이가 발생할 수 있습니다. 하지만 파티션을 많이 제외할 수록 성능은 개선됩니다.
Amazon S3 경로에 대한 Hive 스타일 파티셔닝 외에도 Parquet와 ORC 파일 포맷은 컬럼 값을 나타내는 데이터 블록으로 파일을 파티셔닝합니다. 또한 각각의 블록에는 레코드에 대한 통계(예: 컬럼 값에 대한 최소/최대 값)가 저장됩니다. AWS Glue는 술어 푸시 다운은 Hive 스타일 파티션과 이러한 형식의 블록 파티션을 지원합니다. 데이터를 읽는 동안 필요 없는 S3 파티션은 잘라내고, Parquet와 ORC 포맷의 컬럼 통계로 읽을 필요가 없다고 판단되는 블록은 건너 뜁니다.
추가적인 변환
이제 데이터 세트를 읽고 필터링했으므로 추가적인 변환을 통해 데이터를 정리하거나 수정할 수 있습니다. 예를 들어 previous AWS Glue post 에서 설명한 것과 같은 감성 분석까지 확대할 수 있습니다.
단순하게 ApplyMapping 변환을 사용하여 데이터 세트에서 일부 컬럼만 선택합니다:
%spark
val projectedEvents = pushdownEvents.applyMapping(Seq(
("id", "string", "id", "long"),
("type", "string", "type", "string"),
("actor.login", "string", "actor", "string"),
("repo.name", "string", "repo", "string"),
("payload.action", "string", "action", "string"),
("org.login", "string", "org", "string"),
("year", "string", "year", "int"),
("month", "string", "month", "int"),
("day", "string", "day", "int")
))ApplyMapping은 프로젝션(projection)과 타입 형변환(type-casting)을 수행하는 유연한 변환입니다. 이 예제에서는 actor 필드에 매핑되는 actor.login과 같은 몇가지 필드를 unnest 하기 위해서 사용합니다. 또한 id 컬럼을 long으로 파티션 컬럼을 integer 타입으로 변환했습니다.
파티션 된 데이터 쓰기
마지막 단계는 변환한 데이터 세트를 Amazon S3에 써서 Amazon Athena와 같은 다른 시스템에서 데이터를 처리할 수 있도록 하는 것입니다. 기본적으로 DynamicFrame에 쓸 때 파티션 되지 않은 모든 아웃풋 파일은 지정된 아웃풋 경로의 최상위 레벨로 쓰여집니다. 최근까지도 DynamicFrame을 파티션에 쓰는 유일한 방법은 쓰기 전에 Spark SQL DataFrame으로 변환하는 것이었습니다. 하지만 이제는 DynamicFrame이 일련의 키를 통해 네이티브(native) 파티셔닝을 지원합니다.
이 작업은 sink를 생성할 때 추가적인 partitionKeys 옵션을 전달하여 수행할 수 있습니다. 예를 들어 다음 코드는 Parquet포맷으로 만든 데이터 세트를 type 필드로 파티션 된 S3의 디렉토리에 쓰게 됩니다.
%spark
glueContext.getSinkWithFormat(
connectionType = "s3",
options = JsonOptions(Map("path" -> "$outpath", "partitionKeys" -> Seq("type"))),
format = "parquet")
.writeDynamicFrame(projectedEvents)여기에서 $outpath는 S3의 기본 아웃풋 경로를 나타냅니다. partitionKeys 파라미터는 Python의 connection_options dict에서도 다음처럼 정의할 수 있습니다:
glue_context.write_dynamic_frame.from_options(
frame = projectedEvents,
connection_options = {"path": "$outpath", "partitionKeys": ["type"]},
format = "parquet")위의 코드를 실행하면 type 필드는 개별 레코드에서 삭제되고 디렉토리 구조로 인코딩됩니다. 이를 증명하기 위해서 AWS CLI의 aws s3 ls 명령을 사용하여 출력 경로를 나열할 수 있습니다.
PRE type=CommitCommentEvent/
PRE type=CreateEvent/
PRE type=DeleteEvent/
PRE type=ForkEvent/
PRE type=GollumEvent/
PRE type=IssueCommentEvent/
PRE type=IssuesEvent/
PRE type=MemberEvent/
PRE type=PublicEvent/
PRE type=PullRequestEvent/
PRE type=PullRequestReviewCommentEvent/
PRE type=PushEvent/
PRE type=ReleaseEvent/
PRE type=WatchEvent/예상한대로 각 개별 이벤트 유형 마다 파티션이 있습니다. 이 예제에서는 하나의 값으로 파티셔닝 했지만 꼭 이럴 필요는 없습니다. 예를 들어 원래 파티션인 year, month, days를 유지하려면 partitionKeys옵션을 Seq(“year”, “month”, “day”)로 설정하면 됩니다.
결론
이 글에서는 AWS Glue에서 파티션 된 데이터로 처리하는 방법을 설명했습니다. 파티셔닝은 대규모 데이터 세트를 최대한 활용하는데 중요한 기술입니다. Amazon Athena, Amazon Redshift Spectrum을 포함한 AWS의 빅 데이터 에코시스템의 많은 도구들은 파티션을 활용하여 쿼리 성능을 가속화합니다. AWS Glue는 파티션 된 데이터를 쓰기, 크롤링, 필터링 메커니즘을 제공하므로 원하는 경우 Amazon S3에서 데이터를 구성하여 빅 데이터 애플리케이션에서 최상의 성능을 얻을 수 있습니다.
지금 바로 시도해보세요!
이 글은 AWS Big Data Blog의 Work with partitioned data in AWS Glue의 한국어 번역으로 AWS코리아의 안효빈 솔루션즈 아키텍트가 번역해 주셨습니다.