AWS 기술 블로그
달파의 Amazon EKS Hybrid Nodes를 활용한 클러스터 안정성 및 비용 절감 사례
소개
달파는 기업의 비즈니스 문제를 쇼핑하듯 해결하는 B2B AI 에이전트 플랫폼 기업입니다. 2023년 서울에 설립된 달파는 150여 개 이상의 모듈화 된 AI 솔루션을 제공하며 업무 자동화, 내부 효율화 등 다양한 측면에서 기업을 지원하고 있습니다. CJ올리브네트웍스, SK스토아, 마켓컬리, KT커머스 등 국내 주요 대기업 및 유통사들을 포함한 150여 개 이상의 기업이 이미 달파의 AI 솔루션을 도입하여 성과를 내고 있습니다.
최근에는 소비재 브랜드사를 위한 AI 에이전트 운영 플랫폼을 출시해 기존 ERP, 단순 자동화 도구를 넘어 판매·재고·마케팅 데이터 분석, 재고 최적화, 인플루언서 마케팅 등 실무를 지원하는 ‘운영 중심 AI 플랫폼’으로 거듭나고 있습니다. 뷰티·패션·식품·리빙 등 주요 소비재 브랜드사 10개사와 협업하며, 악성 재고 비용, 마케팅 비용 최적화 등 실질적인 비즈니스 성과 개선을 이루어내고 있습니다.
달파는 Amazon EKS(Amazon Elastic Kubernetes Service)를 기반으로 AI 워크로드를 운영하고 있으며, 고객에게 비용 효율적이고 안정적인 서비스를 제공하는 것을 목표로 하고 있습니다. 달파는 클라우드와 온프레미스 GPU 서버팜을 효과적으로 결합한 최적의 인프라 운영 방안을 모색하던 중, Amazon EKS Hybrid Nodes를 도입하게 되었습니다.
달파의 EKS Hybrid Nodes 선택 배경
달파는 GPU 기반 AI 워크로드를 제공하면서 다음과 같은 과제에 직면했습니다.
비용 효율성
GPU 인스턴스를 클라우드에서 온디맨드로 사용할 경우 유연성과 확장성을 확보할 수 있지만, 지속적인 사용 시 비용 부담이 있었습니다. 이에 달파는 기존에 보유한 온프레미스 GPU 자원을 활용하기 위해 docker compose 기반의 환경을 구축하였습니다. 그러나 온프레미스 환경에서 별도의 Kubernetes 클러스터를 독립적으로 관리하는 것은 상당한 운영 부담을 수반했고, 이로 인해 온프레미스 GPU 자원의 적극적인 활용이 제한되었습니다.
클러스터 관리 부담
온프레미스에서 독립적인 Kubernetes 클러스터를 운영하는 것은 상당한 관리 부담을 수반했습니다. 컨트롤 플레인 관리, 업그레이드, 보안 패치 등의 작업이 지속적으로 필요했습니다. 또한 권한 부여 측면에서도 node 단위에 불필요하게 많은 권한을 부여하는 등의 misconfiguration으로 인한 보안/장애 우려 지점도 존재했습니다.
가용성 및 안정성
온프레미스 노드에 장애가 발생할 경우 서비스 연속성을 보장할 수 있는 백업 방안이 필요했습니다. 별도 Kubernetes 클러스터 운영 환경에서는 백업 플랜을 운영할 때 시스템의 복잡도가 크게 증가했습니다. 이에 가용성이 중요시되는 서비스는 온프레미스 이전에 부담이 있었습니다.
네트워크 복잡도
온프레미스와 클라우드 환경을 별도로 운영할 경우 네트워크 구성이 복잡해지고, 서비스 간 통신에 어려움이 있었습니다. 내부망에서 가동되는 서비스의 public endpoint를 open 하고 IP 기반 접근제어를 하는 불안정한 구조를 갖고 있었습니다.
이러한 과제를 해결하기 위해 달파는 Amazon EKS Hybrid Nodes를 도입하기로 결정했습니다.
Amazon EKS Hybrid Nodes 소개
Amazon EKS Hybrid Nodes는 Amazon EKS on AWS Outposts 및 Amazon EKS Anywhere에 더하여, 하이브리드 Kubernetes 배포에 대한 지원을 확장합니다. 각 EKS 하이브리드 배포 옵션을 사용하여 Kubernetes 및 하드웨어 구성 요소를 관리하는 방법을 비교할 수 있습니다.
| 구성 요소 | EKS on Outposts | EKS Hybrid Nodes | EKS Anywhere |
|---|---|---|---|
| 하드웨어 | AWS 관리 | 고객 관리 | |
| Kubernetes 컨트롤 플레인 | AWS에서 호스팅 및 관리 | 고객이 호스팅 및 관리 | |
| Kubernetes 노드 | Amazon EC2 | 고객이 관리하는 물리적 또는 가상 머신 | |
Amazon EKS Hybrid Nodes는 온프레미스 인프라와 AWS 클라우드를 단일 Kubernetes 클러스터로 통합 관리할 수 있는 솔루션입니다. 이를 통해 기업은 기존 온프레미스 투자를 활용하면서도 AWS의 관리형 Kubernetes 서비스의 이점을 누릴 수 있습니다.
아키텍처 구성 요소
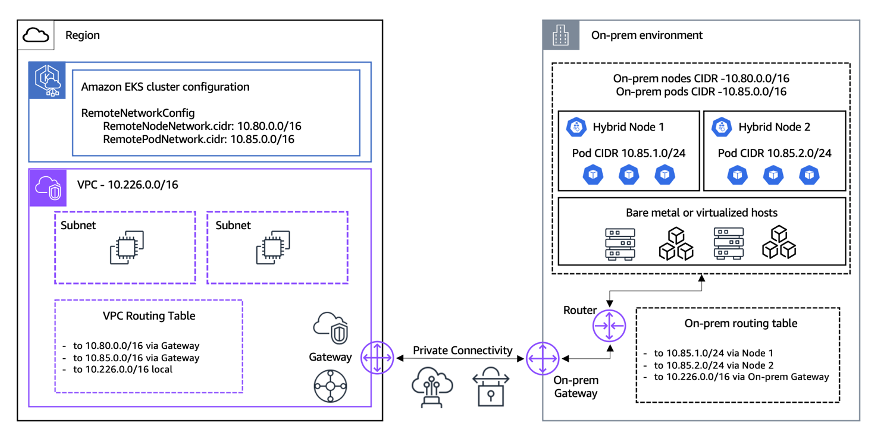
위 다이어그램은 Amazon EKS Hybrid Nodes의 네트워크 아키텍처를 보여줍니다.
AWS 클라우드 환경 (왼쪽)
Amazon EKS 클러스터는 RemoteNetworkConfig를 통해 온프레미스 환경과의 하이브리드 네트워크를 구성합니다. RemoteNodeNetwork CIDR은 10.80.0.0/16으로 온프레미스 하이브리드 노드의 호스트 네트워크를 정의하고, RemotePodNetwork CIDR은 10.85.0.0/16으로 온프레미스 파드 네트워크를 정의합니다. VPC(10.226.0.0/16)는 여러 서브넷을 포함하며, VPC 라우팅 테이블은 다음과 같이 구성됩니다.
- 10.80.0.0/16으로 가는 트래픽은 게이트웨이 경유
- 10.85.0.0/16으로 가는 트래픽은 게이트웨이 경유
- 10.226.0.0/16은 로컬 처리
온프레미스 환경 (오른쪽)
온프레미스 노드 CIDR은 10.80.0.0/16이며, 온프레미스 파드 CIDR은 10.85.0.0/16입니다. 하이브리드 노드 1은 파드 CIDR 10.85.1.0/24를 할당받고, 하이브리드 노드 2는 파드 CIDR 10.85.2.0/24를 할당받습니다. 이러한 노드들은 베어메탈 또는 가상화된 호스트에서 실행됩니다. 온프레미스 라우팅 테이블은 다음과 같이 구성됩니다.
- 10.85.1.0/24로 가는 트래픽은 노드 1로 라우팅
- 10.85.2.0/24로 가는 트래픽은 노드 2로 라우팅
- 10.226.0.0/16으로 가는 트래픽은 온프레미스 게이트웨이 경유
프라이빗 연결
AWS VPC와 온프레미스 환경은 프라이빗 연결(Private Connectivity)을 통해 안전하게 통신합니다. 프라이빗 연결은 AWS Direct Connect 또는 Site-to-Site VPN 등을 통해 구성할 수 있습니다.
이 아키텍처를 통해 AWS 클라우드의 관리형 EKS 클러스터와 온프레미스 환경의 하이브리드 노드를 단일 Kubernetes 클러스터로 통합하여, 워크로드를 두 환경에 유연하게 배치하고 관리할 수 있습니다.
달파의 EKS Hybrid Nodes 도입 과정 및 아키텍처
달파는 2025년 상반기부터 EKS Hybrid Nodes를 도입하여 운영하고 있습니다. 도입 과정에서 몇 가지 기술적 과제를 해결하며 안정적인 하이브리드 환경을 구축했습니다.
아키텍처 구성
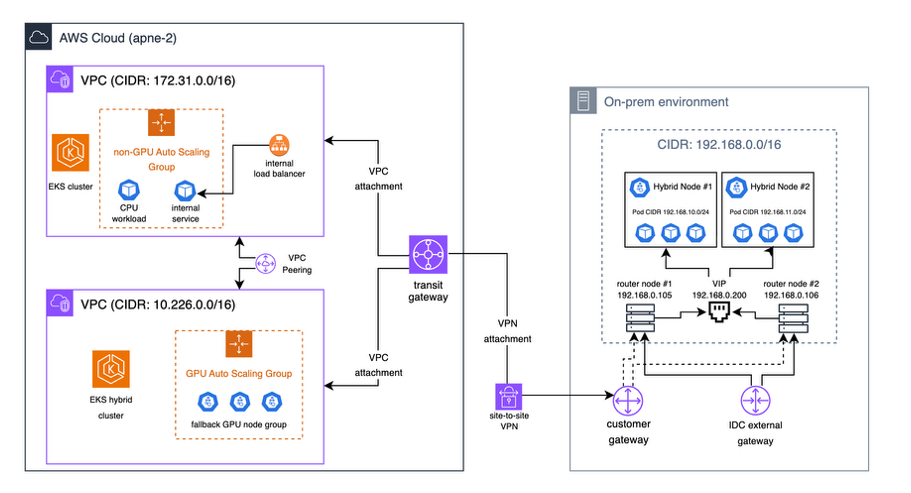
- EKS 컨트롤 플레인: AWS 관리형 EKS 컨트롤 플레인을 사용하여 클러스터를 중앙에서 관리합니다.
- 온프레미스 GPU 노드: 기존 온프레미스 GPU 자원을 EKS Hybrid Nodes로 등록하여 주요 AI 워크로드를 처리합니다.
- 클라우드 GPU 노드: AWS의 GPU 인스턴스를 백업 자원으로 활용하여 장애 시 페일오버를 지원합니다.
- Site-to-Site VPN: 온프레미스와 AWS VPC 간 안전한 연결을 제공합니다.
- Transit Gateway: VPC와 온프레미스 간 통합된 네트워크 연결을 제공하여 서비스 간 통신을 단순화합니다.
도입 과정의 기술적 과제 및 해결
Site-to-Site VPN 연결 안정성 강화
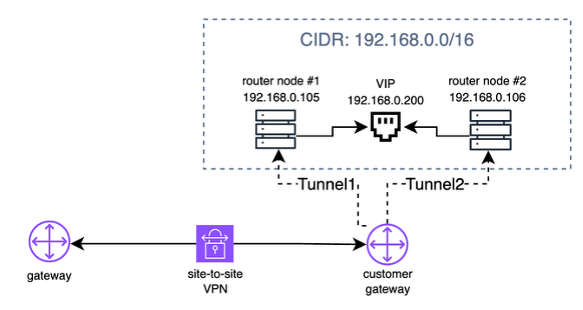
Site-to-Site VPN 연결 환경에서는 네트워크 조건에 따라 일시적인 연결 재협상이 발생할 수 있으며, 이는 하이브리드 노드와 컨트롤 플레인 간 통신의 연속성에 영향을 줄 수 있었습니다. 안정적인 서비스 제공을 위해 VPN 연결의 고가용성 구성이 필요했습니다.
strongSwan 기반 IPsec Site-to-Site VPN 환경 위에 ipsec status를 script로 모니터링하는 keepalived 세팅을 구성하였습니다. VPN 터널이 수립되거나 종료될 때의 status를 기반으로 active-standby 구조를 구성해 router node의 VIP를 active 노드가 가져가게 자동화했습니다. 이를 통해 각 node의 컨트롤 플레인 연결 장애를 예방할 수 있었습니다.
Router Node 와의 IP Routing Setup 문제
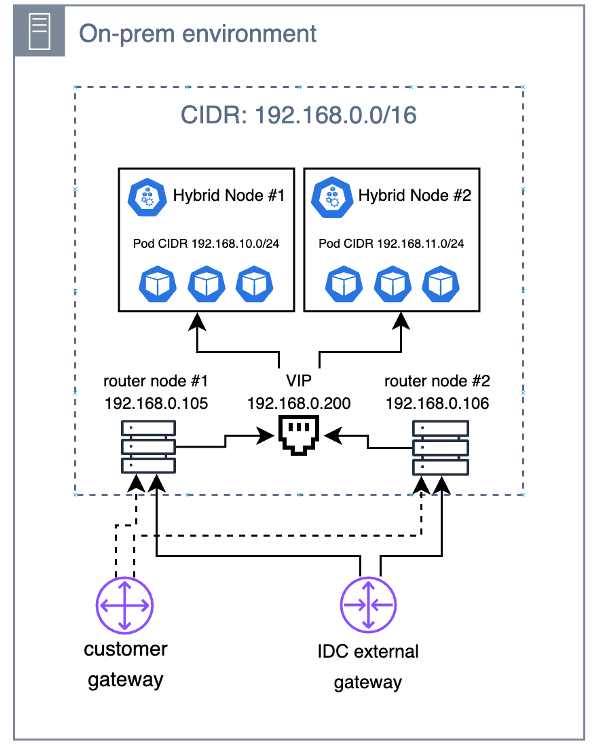
EKS에 등록된 node들이 site-to-site VPN 접근을 위해 router node를 거치도록 routing table을 update 해야 했습니다. 관리해야 할 VPC 대역이 늘어남에 따라 ansible 기반의 script 자동화 방식의 routing table 형상 관리로는 human error 가 자주 발생하고, node reboot 등의 장애 상황에 빠른 인지 및 대응에 어려움이 있었습니다.
BGP (Border Gateway Protocol) daemon을 각 node에 세팅해 ip route 설정을 자동화했습니다. (AWS 의 transit gateway 제품도 BGP를 활용해 dynamic route를 구성합니다. 참고) 구축 시에는 bird daemon을 활용했습니다. 각 node를 등록할 때 router node에 pod CIDR route를 구성해두고, router node에서는 내부 CIDR에 대한 route를 export 하도록 했습니다.
각 hybrid node 에서는 daemonset 으로 bird 를 띄웠습니다.
apiVersion: v1
kind: ConfigMap
metadata:
name: bird-config
namespace: kube-system
data:
bird.conf: |
# Hybrid node BIRD configuration
router id {{NODE_IP}};
protocol device {
}
protocol direct {
interface "*";
}
protocol bgp router {
local as 65210;
neighbor 192.168.0.200 as 65200;
multihop;
ipv4 {
import all;
export none;
};
}
---
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: bird
namespace: kube-system
spec:
selector:
matchLabels:
app: bird
template:
metadata:
labels:
app: bird
spec:
hostNetwork: true
hostPID: true
containers:
- name: bird
image: pierky/bird:3.1.2
securityContext:
privileged: true
env:
- name: NODE_IP
valueFrom:
fieldRef:
fieldPath: status.hostIP
command:
- sh
- -c
- |
sed "s/{{NODE_IP}}/${NODE_IP}/" /etc/bird/bird.conf > /run/bird.conf
bird -c /run/bird.conf -d
volumeMounts:
- name: bird-config
mountPath: /etc/bird
volumes:
- name: bird-config
configMap:
name: bird-config
---Cilium에서도 BGP 기능을 지원하므로 향후에는 bird daemonset 이 아닌 cilium 기반으로 일원화하는 것을 개선과제로 두고 있습니다.
Amazon EKS Hybrid Nodes를 구성하기 위한 자세한 사항은 Amazon EKS Hybrid Nodes 사전 조건 설정 문서를 참고하십시오.
달파의 EKS Hybrid Nodes 도입 성과
달파는 EKS Hybrid Nodes 도입을 통해 다음과 같은 성과를 달성했습니다.
비용 절감 70%
GPU 노드를 온디맨드로 이용하는 것에 비해 약 70%의 비용을 절감했습니다. 온프레미스 GPU 자원을 비용 효율적으로 활용하면서도 배치 파이프라인 처리 등 특정 시점에 필요시 클라우드 자원을 가용할 수 있는 유연성을 확보했습니다.
클러스터 운영 부담 감소
온프레미스에서 독립적인 클러스터를 운영할 때의 관리 부담을 크게 줄였습니다. AWS 관리형 컨트롤 플레인을 활용하여 업그레이드, 패치, 모니터링 등의 작업이 간소화되었습니다. 또한 GPU 워크로드에 IAM Roles for Service Accounts(IRSA)를 활용해 세밀한 권한 부여가 가능해져 구조적으로도 안정성을 갖출 수 있었습니다.
향상된 가용성
노드 장애 시 클라우드의 GPU 자원을 폴백 (fallback)으로 활용할 수 있게 되어 서비스 연속성이 크게 향상되었습니다. 온프레미스 노드에 문제가 발생해도 워크로드를 클라우드로 자동 전환할 수 있습니다. fallback 수단을 확보하게 되면서 가용성 우려가 있는 서비스도 쉽게 이전할 수 있게 되었습니다.
네트워크 복잡도 감소
Transit Gateway를 활용하여 온프레미스와 클라우드 VPC 간 서비스 통신을 단순화했습니다. 별도의 복잡한 네트워크 구성 없이 VPC 간 peering 한 것과 같이 CIDR 대역을 공유해 내부망 서비스를 외부에 노출하지 않고 운영할 수 있게 되었습니다.
결론
이 글에서는 달파가 Amazon EKS Hybrid Nodes를 도입해 클러스터 안정성을 강화하고 운영 비용을 절감한 사례를 살펴보았습니다. 달파 내부에서는 본 도입을 성공적인 프로젝트로 평가하고 있으며, 비용 효율성과 운영 안정성이라는 두 가지 핵심 목표를 동시에 달성했습니다. 더 나아가, 향후 GPU 기반 AI 워크로드 확장에도 유연하게 대응할 수 있는 인프라 기반을 확보했습니다.
Amazon EKS Hybrid Nodes는 다음과 같은 핵심 가치를 제공합니다.
- 통합 관리: 온프레미스와 클라우드 노드를 단일 EKS 클러스터에서 일관되게 운영
- 유연한 워크로드 배치: 워크로드 특성에 따라 온프레미스와 클라우드 간 최적 배치 가능
- 하이브리드 네트워킹: VPC와 온프레미스 네트워크를 통합해 네트워크 구성 및 운영 복잡도 감소
- 운영 부담 감소: AWS 관리형 컨트롤 플레인을 활용해 클러스터 운영 부담 최소화
달파는 온프레미스 GPU 자원과 AWS 클라우드를 효과적으로 결합함으로써 다음과 같은 성과를 거두었습니다.
- GPU 비용 약 70% 절감
- 클러스터 운영 및 관리 부담 감소
- 노드 장애 발생 시 클라우드 페일백을 통한 가용성 향상
- 네트워크 구성 및 운영 복잡도 감소
Amazon EKS Hybrid Nodes는 기존 온프레미스 투자를 보호하면서도 클라우드의 유연성과 관리 편의성을 함께 제공하는 현실적인 하이브리드 아키텍처입니다. GPU 기반 AI 워크로드를 운영하거나 확장을 고려하는 조직이라면, 비용 효율성과 안정성을 동시에 확보할 수 있는 선택지로 적극 검토할 가치가 있습니다.
Amazon EKS Hybrid Nodes에 대해 더 자세히 알아보려면 공식 문서를 참고하시기 바랍니다. 하이브리드 클라우드 구축과 운영 경험에 대한 의견이나 질문이 있다면 댓글로 공유해 주세요.