AWS 기술 블로그
클라우드 환경에서의 비디오 인텔리전스 구현: TwelveLabs로 시작하는 AI 영상 분석 4부 – TwelveLabs Marengo 3.0 임베딩 및 검색 전략과 구현 가이드
배경
비디오는 단순한 단일 데이터 스트림이 아닙니다. 시간 축을 따라 visual(화면 시각 정보), audio(소리 이벤트), speech/transcription(대화 내용)이 동시에 공존하는 복합 매체입니다. 따라서 비디오 검색 쿼리는 “완전히 시각적”이거나 “완전히 전사(transcription)”인 경우가 드뭅니다. 예를 들어, “Q3 세일즈 장표를 발표하는 여성의 모습”이라는 쿼리는 시각 정보, 대화 내용, 그리고 오디오 정보를 모두 포함해야 합니다.
TwelveLabs의 Marengo 3.0은 모든 모달리티(비디오 프레임, 음성, 자막 등)를 하나의 통합 벡터 공간(shared latent space)으로 변환해 “any-to-any” 검색(텍스트 → 비디오, 이미지 → 비디오)을 가능하게 합니다. 이는 멀티모달 검색 경험의 근간이 되는 기술로, 기존 시스템의 근본 한계를 극복합니다.
하지만 멀티벡터 아키텍처는 역사적으로 여러 벡터 인덱스를 관리하는 복잡성과 여러 벡터 유형의 출력을 병합하는 어려움 등 또 다른 도전 과제를 제시합니다.
Multi-Vector 검색의 핵심 과제
3개의 모달리티 임베딩을 분리 제공하는 것은 강력한 기능이지만, 동시에 새로운 시스템 설계 과제를 만들어냅니다. 단순히 “벡터 검색”이 아니라, 모달리티별 가중치 부여, 멀티 벡터 반환 전략, 전략적인 라우팅, 그리고 랭킹과 스코어 보정과 같은 과제를 해결해야 합니다. 해당 블로그에서는 1) Fused Embeddings, 2) Multi Vector Retrieval(Score-based, RRF), 3) Intent based routing 3가지 비디오 임베딩 및 검색 전략을 설명하고 시스템 구현 가이드를 제공합니다.
접근법 1 – Fused Embeddings
가장 단순한 방식으로 세그먼트 별 저장 시점에 3개 모달리티 임베딩을 하나의 벡터로 합칩니다. Marengo 3.0은 하나의 비디오 클립에 대해 visual, audio, transcription 세 개의 독립된 임베딩 벡터를 반환합니다. Fused 방식은 저장 시점에 3개 벡터를 가중 합산 후 세그먼트별 정규화하고 하나의 인덱스로 통합하는 것입니다. (세그먼트 별 모달리티가 없을 경우, 0으로 고정)
시각적으로 무거운 비디오 검색 벤치마크와 많은 시각 중심 아카이브를 위해, TwelveLabs가 권장하는 기본 융합 가중치는 Visual (0.8), Audio (0.1), Transcription (0.05)입니다.
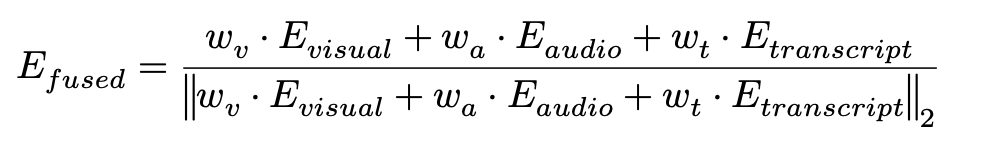
[그림 1. Fused embedding 공식]
Fused embeddings 방식은 통합된 1개의 인덱스로 통합하는 방법으로 관리가 편하고 비용이 저렴하지만 아래와 같은 한계가 있습니다.
한계
비가역적: 가중치가 적용된 임베딩 변경이 불가함으로 가중치 변경 시, 영상을 재처리해야 합니다.
쿼리 의도와 무관한 고정 가중치 적용: visual을 0.8로 부여했다면 “군중 환호”와 같은 오디오 중심 쿼리에도 visual 가중치가 0.8로 적용되어 쿼리의 의도와 무관하게 시각 정보가 지배적입니다.
디버깅 불가: 검색 결과가 어떤 모달리티가 기여했는지 분석할 수 없습니다.
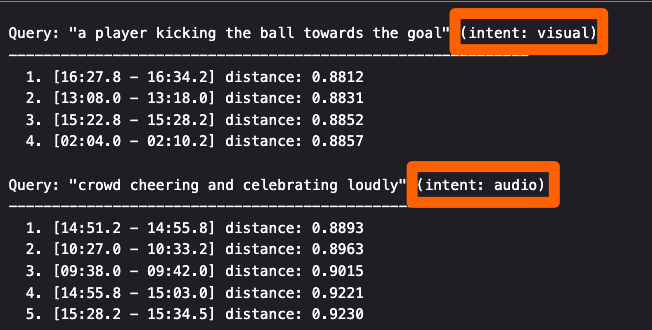
[그림 2. 쿼리 의도(intent)와 무관한 고정 가중치 적용 예시]
위와 같은 한계에도 불구하고 기업에서 관리하는 영상의 포맷이 일관되고 몇번의 테스트를 통해 가중치를 설정할 수 있다면 비디오 임베딩 및 검색을 비용 효율적으로 할 수 있는 방법입니다. 하지만 반대로 영상의 구조가 일관되지 않고 영상별 모달리티 간 가중치가 달라야 하는 상황이라면 아래의 Multi-Vector 방식을 고려해봐야 합니다.
접근법 2 – Multi-Vector Fixed Weights
3개 모달리티 임베딩 결과를 별도의 인덱스에 분리 저장하고, 검색 시점에 각 결과를 합산하는 방식입니다. Fused 방식과 달리 원본 벡터가 보존되므로, 언제든 가중치를 바꿔서 재검색할 수 있습니다.
- 가역성: 가중치가 맞지 않으면, 영상을 재처리하지 않고 가중치만 바꿔서 즉시 재검색 가능
- 디버깅: 각 모달리티가 최종 점수에 얼마나 기여했는지 분석 가능
- 유연성: A/B 테스트로 가중치 조합을 실험하기 용이
아래는 점수를 합산하는 방식으로 Score-based Fusion방식과 RRF(Reciprocal Rank Fusion)방식을 설명합니다.
1) Score-based Fusion
각 모달리티 검색 결과의 코사인 유사도 점수에 가중치를 곱해 합산합니다. Fused embeddings방식이 사전에 정의된 가중치를 기준으로 하나의 통합된 인덱스에 저장하는 것이라면, Score-based Fusion은 3개 모달리티에 대한 Indice는 보존한 상태로 검색마다 점수를 산출하여 검색 결과를 랭킹하는 것입니다.
Fused는 벡터를 먼저 합치고 정규화한 뒤 유사도를 계산하고, Score-based는 유사도를 각각 계산한 뒤 점수를 합칩니다. 정규화 과정에서 벡터 방향이 바뀌기 때문에 결과가 달라집니다.
가장 큰 차이는 Score-based Fusion방식은 결과마다 모달리티별 기여도를 정확히 분석하고 디버깅이 가능하기 떄문에 최적의 가중치를 찾기 위해 튜닝을 할 수 있습니다.
2) RRF (Reciprocal Rank Fusion)
점수가 아닌 순위 기반으로 합산하는 방식으로, 모달리티 간 점수 스케일 차이에 영향받지 않고 모든 모달리티를 동등하게 취급합니다. Score-based Fusion에서는 점수가 낮지만 해당 모달리티 내에서 순위가 높은 결과가 최종 랭킹에서 과소평가될 수 있습니다.
예를 들어, “Amazon 현수막 아래에서 춤을 추는 남자”로 검색했을 때, “춤”이라는 시각적 요소는 visual 인덱스에서 높은 유사도 점수를 받을 수 있습니다. 반면 transcription 인덱스에서 “Amazon”이라는 키워드와 매칭된 결과는 해당 모달리티 내에서 상위 3위에 위치하더라도, 절대적인 유사도 점수는 visual에 비해 상대적으로 낮을 수 있습니다. 이때 점수 기반으로만 합산하면 transcription의 기여가 묻혀, 더 정확한 검색 결과를 제공할 수 있는 기회를 놓치게 됩니다.
RRF는 점수 대신 순위를 사용함으로써 이러한 모달리티 간 점수 스케일 불균형 문제를 해소합니다. 아래는 Reciprocal Rank Fusion(RRF)의 공식이며, k는 순위 간 차이를 완화하는 상수(일반적으로 60), s는 비디오 세그먼트, m은 모달리티를 나타냅니다.
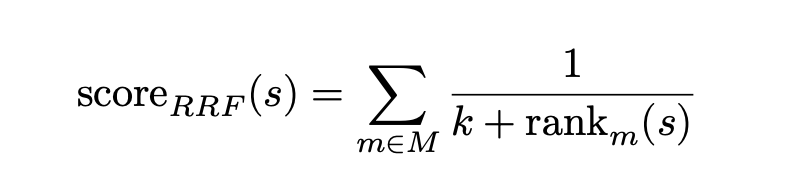
[그림 3. Reciprocal Rank Fusion (RRF) 공식]
그렇다면 k상수를 부여하는 이유는 무엇일까요? k 없이 순위 역수만 쓰면 상위권 순위 변동이 결과를 과도하게 지배하기 때문입니다.
k가 없을 때 (k=0) 각 세그먼트의 RRF를 계산하면 다음과 같습니다.
1위: 1/1 = 1.000
2위: 1/2 = 0.500
3위: 1/3 = 0.333
10위: 1/10 = 0.100
1위와 2위의 점수 차이가 0.5로, 2위와 10위의 차이(0.4)보다 큽니다. 즉 1위냐 2위냐가 전체 결과를 좌우합니다.
하지만 아래처럼 k = 60으로 계산할 경우 아래와 같은 결과를 얻습니다.
1위: 1/61 = 0.01639
2위: 1/62 = 0.01613
3위: 1/63 = 0.01587
10위: 1/70 = 0.01429
2가지 방법 결과 예시
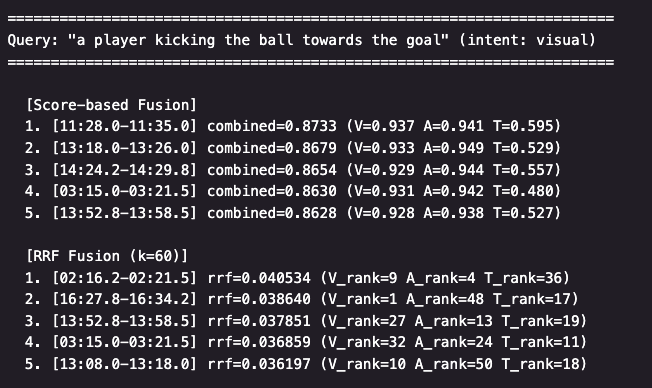
[그림 4. 동일한 쿼리에 대한 Score-based Fusion과 RRF 방식의 결과 차이]
Score-based Fusion은 그때마다 가중치를 튜닝할 수 있으므로 튜닝을 통한 최적화와 커스터마이징을 원할 경우, 적합할 수 있습니다. RRF는 모든 모달리티를 동등하게 대하는만큼 특정 모달리티를 우선시하는 것이 불가한 한계가 있으므로 추가적으로 가중치를 부여하는 방식을 적용하여 검색 결과를 고도화하는 방법을 택할 수도 있습니다.
접근법 3 – Intent-based Dynamic Routing
지금까지의 방법은 모두 고정된 가중치를 부여하는 방식으로 장기적으로 관리에 피로도가 누적될 수 있습니다. 3번째 접근법인 Intent-based Dynamic Routing의 핵심 아이디어는 쿼리 텍스트 자체에서 의도를 파악하여, 모달리티 가중치를 자동으로 조절하는 것입니다.
실제 사용자 쿼리는 의도가 다양합니다. 하나의 비디오 검색 시스템에 아래와 같은 쿼리가 동시에 들어올 수 있습니다:
- “빨간 스포츠카가 고속도로를 달리는 장면” → visual이 핵심
- “해설자와 관중이 환호하는 소리” → audio가 핵심
- “축구 감독이 보드에서 전략을 수정하는 부분” → transcription이 핵심
Intent-based Dynamic Routing은 크게 2단계로 구성됩니다.
1) Routing Anchor
첫째로 Routing Anchor입니다. 각 모달리티를 잘 설명하는 대표 텍스트(앵커)를 미리 정의하고, 인풋 쿼리가 어떤 앵커와 더 유사한지 측정하여 가중치를 결정합니다.
[모달리티별 앵커 정의]
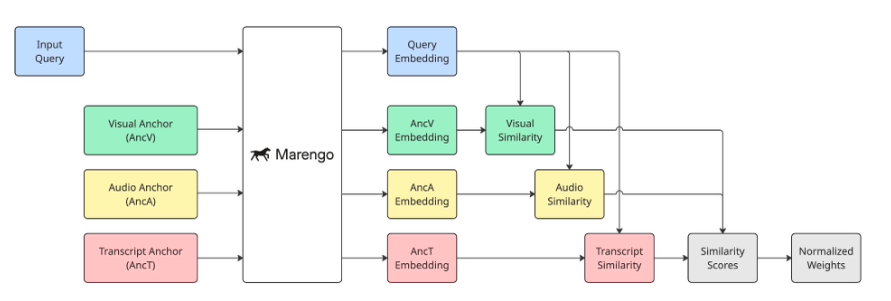
[그림 5. 입력 쿼리에 따른 동적 라우팅 가중치를 위한 라우팅 앵커 다이어그램]
2) Softmax with Temperature
softmax는 지수함수(exp)를 사용하는 정규화 함수입니다. 위 단계에서 쿼리와 각 앵커 간의 코사인 유사도를 계산한 뒤, 결과에 softmax with temperature(????)를 적용하여 가중치를 산출합니다.
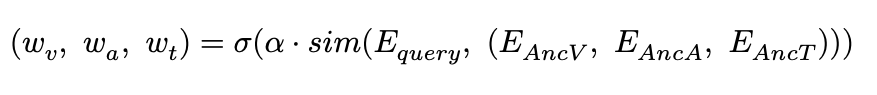 temperature α = 10을 권장하며, 차이를 증폭하기 위해 사용됩니다. 예를 들어 위 단계의 anchor 유사도 결과가 0.17, 0.30, 0.22인 경우, 큰 차이가 느껴지지 않습니다. 하지만 temperature α = 10을 곱해주게 되면 차이가 벌어지는 것을 확인할 수 있습니다. Softmax는 Temperature가 부여된 숫자를 합이 1인 가중치로 출력하는 방법입니다. 아래 4 단계를 통해 정규화 됩니다.
temperature α = 10을 권장하며, 차이를 증폭하기 위해 사용됩니다. 예를 들어 위 단계의 anchor 유사도 결과가 0.17, 0.30, 0.22인 경우, 큰 차이가 느껴지지 않습니다. 하지만 temperature α = 10을 곱해주게 되면 차이가 벌어지는 것을 확인할 수 있습니다. Softmax는 Temperature가 부여된 숫자를 합이 1인 가중치로 출력하는 방법입니다. 아래 4 단계를 통해 정규화 됩니다.
단계 1.temperatue부여
10 × 0.17 = 1.70
10 × 0.30 = 3.00
10 × 0.22 = 2.20
단계 2.최댓값을 빼고 숫자가 너무 커지는 것을 방지합니다.
1.70 - 3.00 = -1.30
3.00 - 3.00 = 0.00
2.20 - 3.00 = -0.80
단계 3. exp (지수함수) 적용하여 어떤 입력이든 양수를 출력하게 하고 차이를 증폭합니다.
exp(-1.30) = 0.2725
exp( 0.00) = 1.0000
exp(-0.80) = 0.4493
합 = 0.2725 + 1.0000 + 0.4493 = 1.7218
단계 4. 정규화
w_visual = 0.2725 / 1.7218 = 0.158 (15.8%)
w_audio = 1.0000 / 1.7218 = 0.581 (58.1%) ← 가장 높음
w_transcription = 0.4493 / 1.7218 = 0.261 (26.1%)
위와 같은 단계를 거쳐 쿼리에 대한 의도를 파악하고 가중치를 부여하면 아래와 같이 다양한 쿼리에 대해 가중치를 동적으로 부여할 수 있습니다.
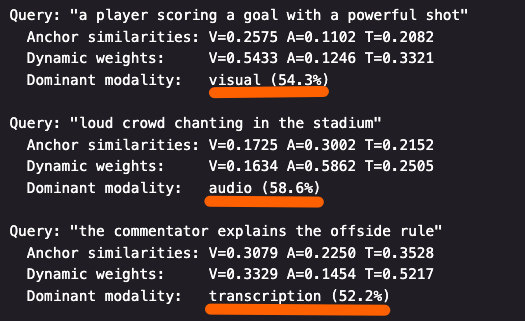
[그림 6. 쿼리별 동적 가중치 부여 예시]
Intent-based Dynamic Routing 방법을 사용하면 쿼리 의도에 자동으로 가중치를 부여하는 검색 엔진을 구축할 수 있고, 관리 측면에서도 쿼리별 가중치 적용 이력을 모니터링 할 수 있어 성능 개선이 용이합니다. 튜닝 역시도 앵커 텍스트 내용과 α 값 두 가지만 조절하면 됩니다.
한계
- 앵커 텍스트 품질 의존: 앵커가 해당 모달리티를 잘 설명하지 못하면 가중치가 부정확해질 수 있음
- 인덱스 3개 필요: Fused 대비 저장 공간과 검색 횟수가 3배
- α 튜닝 필요: 도메인에 따라 최적 α가 다를 수 있음 (스포츠 영상 vs 강의 영상 등)
접근법 비교
| 항목 | Fused | Multi-Vec Score | Multi-Vec RRF | Dynamic Routing |
|---|---|---|---|---|
| 인덱스 수 | 1개 | 3개 | 3개 | 3개 + 앵커 |
| 검색 횟수/쿼리 | 1회 | 3회 | 3회 | 3회 |
| 가중치 적용 | 저장 시 고정 | 저장 시 고정 | 없음 (동등) | 검색 시 자동 |
| 디버깅 | 불가 | 가능 | 가능 | 가능 + 설명 |
| 쿼리 적응성 | 없음 | 없음 | 없음 | 있음 |
| 가역성 | 비가역 | 가역 | 가역 | 가역 |
| 권장사항 | 빠른 프로토타이핑 | 최적화 의지가 있고 영상의 구조가 일관될 경우 | 모든 모달리티를 순위에 적용할 때 (추가 가중치로 고도화 가능) | 자연어 질의를 처리하는 고도화된 방법 |
결론
TwelveLabs Marengo 3.0의 멀티모달 임베딩은 단순히 하나로 합쳐서 사용하는 것보다 훨씬 다양하고 정교한 활용이 가능합니다. 해당 블로그에서는 비디오 임베딩 및 검색을 고도화하기 위한 방법으로 1)Fused embeddings, 2) Multi Vector Retrieval(Score-based, RRF), 3) Intent-based Dynamic Routing 3가지를 소개하였습니다. 각 방법마다 트레이드오프가 존재하므로 시스템의 요구사항과 업무 성숙도에 따라 달라질 수 있습니다. Marengo 3.0모델 임베딩의 구조적 분리를 최대한 활용하여, 시각 · 청각 · 언어 정보를 아우르는 정밀한 비디오 검색 경험을 구축해 보시기 바랍니다.
클라우드 환경에서의 TwelveLabs 기반 비디오 인텔리전스 구현 블로그는 총 5개의 시리즈로 구성이 되어 있습니다. 아래에서 관심 있는 주제를 추가로 살펴보시기 바랍니다.
TwelveLabs로 시작하는 AI 영상 분석 1부 – VoD환경에서의 비디오 분석 파이프라인 구축하기
TwelveLabs로 시작하는 AI 영상 분석 2부 – 준실시간 환경에서 AWS Elemental을 활용한 분석 파이프라인 구축하기
TwelveLabs로 시작하는 AI 영상 분석 3부 – Strands Agents SDK기반의 에이전틱 비디오 분석 에이전트 만들기
TwelveLabs로 시작하는 AI 영상 분석 5부 – AWS에서 Marengo 3.0 비디오 임베딩을 저장하고 검색하기