AWS 기술 블로그
대규모 EC2 환경에서의 운영 전략 : EBS Initialization 자동화 MCP 서버 구현 및 연동
개요
2025년 7월 AWS가 EBS 볼륨 초기화 상태에 대한 가시성을 제공하기 시작하면서, 사용자들은 실제 초기화 진행 상황을 직접 모니터링할 수 있게 되었습니다.
Amazon EBS 볼륨 초기화는 스냅샷에서 생성된 볼륨의 모든 블록을 미리 읽어 후속 I/O 작업의 지연을 방지하는 필수 프로세스입니다. 그러나 AWS의 기본 초기화 과정은 예측 불가능한 소요 시간으로 인해 서비스 배포 지연을 야기하며, Amazon EBS Fast Snapshot Restore(FSR)이나 초기화 속도 지정 옵션은 추가 비용이 발생합니다. 비용 효율적인 대안으로 fio나 dd 명령어를 활용한 수동 초기화가 가능하지만, 이는 운영팀의 업무 효율성을 저하시킵니다.
본 글에서는 Model Context Protocol(MCP)을 활용하여 개발한 EBS Volume Initialization MCP Server를 소개합니다. AI 에이전트와 통합되어 복잡한 명령어 대신 직관적인 자연어 명령만으로 EBS 볼륨 초기화를 자동화합니다. 특히 대규모 인스턴스 환경에서의 병렬 처리 최적화와 EBS 볼륨 초기화 시간 예측 기능을 통해, 전통적인 수동 방식의 한계를 극복하는 구체적인 MCP 활용 사례를 제시합니다.
본 글은 전체 코드를 공개하기보다는 핵심 아키텍처와 구현 원리를 중심으로 MCP를 활용한 앞으로의 인프라 운영의 방향성을 제시합니다.
비즈니스 배경 및 고객 니즈
기업들은 비즈니스 성장에 따른 스케일 아웃, 신규 서비스 런칭, 그리고 개발/테스트 환경 구축을 위해 지속적으로 새로운 EC2 인스턴스를 프로비저닝하고 있습니다. 특히 엔터프라이즈 환경에서는 스냅샷을 통한 신규 인스턴스 배포가 주기적으로 발생할 수 있으며, 이때마다 필요로하는 만큼의 워크로드가 정상적으로 활성화 되기 위해서는 인스턴스의 EBS 볼륨 초기화 과정을 완료해야만 합니다. EBS 초기화가 진행 중인 상태에서는 각 볼륨이 설계된 최대 I/O 성능을 발휘할 수 없어 실제 워크로드 운영에 제약이 발생하기 때문입니다.
기존 EBS 초기화 방식의 한계
1. AWS 기본 초기화 프로세스의 한계
AWS는 스냅샷에서 생성된 EBS 볼륨에 대해 자동으로 백그라운드에서 초기화를 수행하지만, 이 프로세스에는 다음과 같은 제약사항이 있습니다:
- 예측 불가능한 완료 시간: 동일한 크기와 타입의 볼륨이라도 AWS 내부 리소스 상황에 따라 초기화 시간이 달라짐
- 초기화 속도 : 인스턴스에 접속하여 fio 혹은 dd 명령어를 통한 수동 초기화 방식보단 느리게 진행됨.
- 인스턴스별 진행률 추적 불가: AWS 콘솔이나 API를 통해 인스턴스 별 전체 초기화 진행률을 확인할 수 없음
2. 수동 초기화 방식의 한계
이러한 AWS 기본 프로세스의 한계로 인해 많은 운영팀들이 인스턴스에 fio나 dd 명령어를 활용한 수동 초기화를 선택하고 있지만 아래의 불편한 점이 있습니다:
- 수동 작업의 번거로움: 각 인스턴스에 개별 SSH 접속 혹은 SSM 명령어 수행을 통한 수동 실행 필요
- 대규모 환경 관리 복잡성: 수십 개 인스턴스에서 동시에 작업 시 관리 부담 증가
- 휴먼 에러 위험: 반복적인 수동 작업으로 인한 명령어 실수 가능성
EBS 볼륨 초기화가 필요한 주요 시나리오
- 신규 환경 구축 및 스케일 아웃
- 비즈니스 확장이나 새로운 서비스 구축 및 런칭 시점에는 대량의 EC2 인스턴스 내 EBS 볼륨을 동시에 프로비저닝해야 합니다. 스냅샷에서 생성된 볼륨들은 초기화 과정 없이는 I/O 집약적인 애플리케이션들의 성능 저하가 발생할 수 있어 서비스 품질에 직접적인 영향을 미칠 수 있습니다.
- 재해 복구 및 백업 복원
- 재해 상황이나 정기적인 백업 테스트 시, 스냅샷에서 복원된 수십 개의 인스턴스내 볼륨들이 AWS 내부 초기화 프로세스로 인해 전환 후 업무 테스트를 진행할 때 IO 집악적 워크로드에 따라 예측 불가능한 지연 시간이 발생할 수 있습니다. 이러한 불확실성은 RTO(Recovery Time Objective) 목표 달성을 어렵게 만들며, 특히 금융, 대고객 플랫폼 등 미션 크리티컬 환경에서는 복구 시간의 예측 불가능성이 비즈니스 연속성에 직결됩니다.
비즈니스 임팩트 및 기회 비용
정량적 임팩트
- 배포 지연: 신규 서비스 런치 시 EBS 초기화로 인한 추가 대기 시간 발생 가능성
- 운영 비용: EBS초기화를 도와주는 FSR(빠른 스냅샷 복구) 혹은 스냅샷으로 부터 볼륨 생성 시 수동 ‘초기화 속도 지정’ 옵션 사용할 때 비용 발생. (e.g FSR 스냅샷 1개 진행시 최소 0.75USD)
정성적 임팩트
- 개발 생산성 저하: 테스트 환경 구축 지연으로 인한 개발 주기 연장
- 운영 스트레스: 긴급 상황에서의 수동 작업 부담 및 휴먼 에러 위험
- 확장성 제약: 비즈니스 성장에 따른 인프라 스케일링 시 운영 복잡도 증가
위 내용들을 기반으로 EBS 초기화의 정확한 적용 대상(신규 EC2, 스냅샷 복구 볼륨)을 명확히 하여 더욱 현실적이고 구체적인 비즈니스 시나리오로 재구성했습니다.
솔루션 구축 아이디어
솔루션 요구사항 도출
이러한 배경에서 AWS의 기본 EBS 초기화 프로세스의 한계를 보완하고, 수동 fio/dd 방식의 번거로움을 해결하는 자동화된 EBS 볼륨 초기화 솔루션에 대한 필요성이 대두되었습니다:
- 예측 가능한 초기화 시간: 볼륨 크기, 타입, 인스턴스별 처리량을 고려한 사전 완료 예상 시간 제공
- 자동화된 fio/dd 실행: 수동 SSH 접속 없이 AWS Systems Manager를 통한 중앙집중식 제어 방식
- 대규모 병렬 처리: 다수의 인스턴스 볼륨들을 동시에 처리하며 통합 관리 가능
- 실시간 진행률 추적: 전체 초기화 작업 진척도와 개별 인스턴스 진행 상태의 실시간 모니터링 제공
- AI 클라이언트 호환성: Model Context Protocol(MCP) 기반의 자연어 인터페이스 지원
솔루션 아키텍처
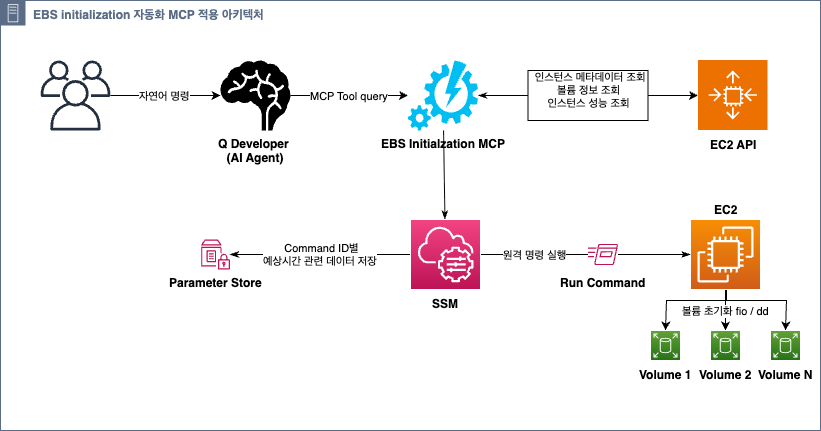
EBS 볼륨 초기화 자동화 솔루션은 Model Context Protocol(MCP)을 중심으로 아키텍처로 설계되어, AI 도구와의 자연스러운 통합과 대규모 인프라 환경에서의 확장성을 동시에 제공합니다.
전체 솔루션의 데이터 흐름은 다음과 같습니다:
- AI Client (Amazon Q Developer, Claude Code 등 )에서 자연어 명령을 MCP 서버로 전송 ( Claude code사용 시 AWS 계정에 대한 Credentials은 기본적으로 설정되어 있어야 함)
- MCP 서버가 EC2 API를 통해 인스턴스 및 볼륨 정보를 수집하고 볼륨의 이전 Snapshot 유무 및 성능치를 기준으로 예상 초기화 예상 시간 추정
- Systems Manager Run Command를 통해 다중 인스턴스 (혹은 단일 인스턴스)에 단일 명령 전송
- 각 EC2 인스턴스에서 IMDS를 활용해 자신의 볼륨만 필터링하여 fio/dd 실행
- Parameter Store에 다중 인스턴스 추정 예상시간 데이터 저장 및 실시간 진행률 추적 정보 제공
- IAM을 통한 최소 권한 기반 보안 제어로 전체 프로세스 보호
이 구조를 통해 기존 수동 SSH 방식을 완전 자동화하고, AI 도구에서 “~태그를 가진 인스턴스들을 혹은 ~분 이후에 launch한 인스턴스들을 초기화 해줘” 라는 간단한 명령만으로 EBS 초기화를 수행할 수 있습니다.
EBS Initialization 자동화 MCP 서버 구현
사전 요구사항
필수 IAM 권한
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"ec2:DescribeInstances",
"ec2:DescribeVolumes",
"ssm:SendCommand",
"ssm:GetCommandInvocation",
"ssm:PutParameter",
"ssm:GetParameter",
"ssm:DeleteParameter"
],
"Resource": ""
}
]
}지원 운영체제
- Amazon Linux 2/2023
- Red Hat Enterprise Linux (RHEL)
- Ubuntu (18.04, 20.04, 22.04, 24.04)
- SUSE Linux Enterprise Server (SLES)
핵심코드
FastMCP 프로토콜 기반 서버 설정
FastMCP는 전통적인 MCP 프로토콜보다 간편한 서버 구축을 지원합니다. decorator 기반의 도구 등록 방식을 통해 AI 클라이언트가 호출할 수 있는 함수를 자동으로 MCP 도구로 변환합니다. 이를 통해 Amazon Q Developer 같은 AI Client에서 자연어 명령을 직접 API 호출로 변환할 수 있습니다.
from mcp.server.fastmcp import FastMCP
...
# FastMCP 서버 인스턴스 생성 - 서버 이름은 AI 클라이언트에서 식별용으로 사용
mcp = FastMCP("EBS Initialization Server")
@mcp.tool()
def get_instance_volumes(instance_id: str, region: str = DEFAULT_REGION) -> str:
"""
Get all EBS volumes attached to an EC2 instance
docstring은 AI가 도구 사용법을 이해하는데 활용됨
"""
try:
ec2 = get_ec2_client(region)
response = ec2.describe_volumes(
Filters=[{'Name': 'attachment.instance-id', 'Values': [instance_id]}]
)
... AWS API 통합 및 볼륨 정보 처리
EC2 describe_volumes API를 사용하여 특정 인스턴스에 연결된 볼륨만을 선별적으로 조회합니다.
필터를 사용하여 네트워크 트래픽을 최소화하고, attachment 정보를 통해 실제로 연결된 볼륨만을 처리하며 볼륨의 메타데이터를 정규화하여 일관된 형태로 변환합니다.
...
@mcp.tool()
def get_instance_volumes(instance_id: str, region: str = DEFAULT_REGION) -> str:
try:
ec2 = get_ec2_client(region)
# 네트워크 효율성을 위해 필터 사용 - 특정 인스턴스의 볼륨만 조회
response = ec2.describe_volumes(
Filters=[{'Name': 'attachment.instance-id', 'Values': [instance_id]}]
)
volumes = []
for volume in response['Volumes']:
for attachment in volume['Attachments']:
# 실제 연결된 볼륨만 처리 (attachment state가 'attached'인 것)
if attachment['InstanceId'] == instance_id:
# 볼륨 정보를 표준화된 형태로 변환
volumes.append(create_volume_summary(volume))
# AI 클라이언트가 파싱하기 쉬운 구조화된 JSON 응답
result = {
"instance_id": instance_id,
"region": region,
"total_volumes": len(volumes),
"volumes": volumes
}
return json.dumps(result, indent=2)
...인스턴스별 처리량 계산
EC2의 describe_instance_types API를 활용하여 인스턴스 타입별 EBS 처리량 정보를 조회합니다. 이는 정적 테이블보다 정확하며, 새로운 인스턴스 타입이 출시되어도 자동으로 지원됩니다.
...
def get_instance_ebs_throughput(instance_type: str, region: str = DEFAULT_REGION) -> float:
"""
boto3 API를 통한 동적 처리량 조회로 최신 인스턴스 타입 자동 지원
하드코딩된 테이블 대신 AWS API를 활용하여 정확성 보장
"""
try:
ec2 = get_ec2_client(region)
# t2 인스턴스는 EBS 최적화 미지원으로 t3 매핑 처리
mapped_instance_type = instance_type
if instance_type.startswith('t2.'):
mapped_instance_type = instance_type.replace('t2.', 't3.')
response = ec2.describe_instance_types(InstanceTypes=[mapped_instance_type])
if response['InstanceTypes']:
instance_info = response['InstanceTypes'][0]
ebs_info = instance_info.get('EbsInfo', {})
# Mbps를 MB/s로 변환 (1 Mbps = 1/8 MB/s)
baseline_throughput_mbps = ebs_info.get('EbsOptimizedInfo', {}).get('BaselineThroughputInMbps', 1000)
return baseline_throughput_mbps / 8
...초기화 완료 시간 예상 알고리즘
AWS EBS의 실제 처리량 할당 알고리즘을 모델링한 시뮬레이션입니다. 개별 볼륨별 처리량 한계치와 인스턴스 타입별 한계치를 모두 계산하여 예상시간을 보다 정확하게 추정할 수 있는 알고리즘을 계산하도록 하여 초기화 시간 예측을 제공합니다.
def estimate_parallel_initialization_time(volumes: List[Dict[str, Any]],
instance_max_throughput_mbps: float) -> float:
"""Calculate estimated completion time for parallel volume initialization."""
total_time_seconds = 0.0
remaining_volumes = [(v['size_gb'], v['max_throughput_mbps']) for v in volumes]
while remaining_volumes:
total_throughput_demand = sum(throughput for _, throughput in remaining_volumes)
if total_throughput_demand <= instance_max_throughput_mbps:
volume_throughputs = [throughput for _, throughput in remaining_volumes]
else:
# AWS EBS allocation logic: smaller throughput volumes get priority
n = len(remaining_volumes)
fair_share = instance_max_throughput_mbps / n
volume_throughputs = []
remaining_instance_throughput = instance_max_throughput_mbps
volumes_needing_fair_share = []
# First pass: allocate full throughput to volumes smaller than fair share
for i, (_, vol_throughput) in enumerate(remaining_volumes):
if vol_throughput <= fair_share:
volume_throughputs.append(vol_throughput)
remaining_instance_throughput -= vol_throughput
else:
volume_throughputs.append(0)
volumes_needing_fair_share.append(i)
...실제 디바이스 매핑 스크립트
EC2 인스턴스의 다양한 가상화 환경(Xen, Nitro)과 디바이스 명명 규칙(/dev/sd, /dev/xvd, /dev/nvme*)을 자동 감지하여 올바른 디바이스 경로를 찾습니다. 이는 AWS의 디바이스 명명이 인스턴스 타입과 가상화 기술에 따라 달라지는 문제를 해결합니다. lsblk 명령을 통해 실제 시스템의 블록 디바이스를 확인한 후 적절한 매핑 로직을 선택합니다.
...
DEVICE_MAPPING_SCRIPT = '''#!/bin/bash
# EC2 인스턴스 타입별 디바이스 명명 규칙 자동 감지
echo "=== Detecting actual device names ==="
# 실제 시스템의 블록 디바이스 목록 확인
LSBLK_OUTPUT=$(lsblk -o NAME,SIZE,TYPE)
echo "Device listing:"
echo "$LSBLK_OUTPUT"
# Xen 하이퍼바이저 환경: /dev/xvd* 디바이스 사용
if echo "$LSBLK_OUTPUT" | grep -q "^xvd"; then
echo "Detected xvd* device naming (Xen hypervisor type)"
DEVICE_PREFIX="xvd"
# Nitro 시스템: /dev/nvme* 디바이스 사용
elif echo "$LSBLK_OUTPUT" | grep -q "^nvme"; then
echo "Detected nvme device naming (Nitro system)"
DEVICE_PREFIX="nvme"
else
...
fi단일 SSM 명령을 통한 다중 인스턴스 제어
AWS Systems Manager Run Command를 활용하여 SSH 접속 없이 보안이 강화된 원격 명령 실행을 수행합니다. 하나의 SSM 명령으로 여러 인스턴스에 동시에 초기화 작업을 전송할 수 있으며, 각 인스턴스는 IMDS를 통해 자신에게 속한 볼륨만 선별적으로 처리합니다. 이는 대규모 환경에서 관리 효율성을 크게 향상시킵니다.
# 다중 인스턴스용 초기화 명령 생성
commands = build_initialization_commands(all_volume_info, method, parallel=True)
...
# 단일 SSM 명령으로 모든 인스턴스에 동시 전송
ssm_response = ssm.send_command(
InstanceIds=target_instances, # ['i-abc123', 'i-def456', 'i-ghi789']
DocumentName='AWS-RunShellScript', # 표준 bash 스크립트 실행 문서
Parameters={
'commands': commands, # 실제 실행될 bash 명령어 배열
'executionTimeout': ['7200'] # 2시간 타임아웃 (대용량 볼륨 고려)
},
...
command_id = ssm_response['Command']['CommandId'] # 추후 상태 추적용 ID
...Parameter Store를 활용한 다중 인스턴스 상태 데이터 관리
SSM Run Command의 Comment 필드는 100자 제한으로 인해 다중 인스턴스 초기화 시 관련 데이터를 저장하기 부족합니다. 이를 해결하기 위해 Parameter Store를 중앙 저장소로 활용하여 각 CommandID별 상세한 모니터링 정보를 JSON 형태로 저장합니다. 이는 실시간 모니터링과 진행률 계산에 필수적인 데이터를 제공합니다.
또한 작업 완료 또는 취소 시 Parameter Store에 저장된 임시 데이터를 정리하여 불필요한 리소스 사용을 방지합니다. 이는 비용 최적화와 함께 깔끔한 리소스 관리를 보장합니다.
# 다중 인스턴스 초기화 관련 데이터를 Parameter Store에 저장
if len(target_instances) > 1 and instance_estimations:
estimations_data = {
"command_id": command_id,
"target_instances": target_instances, # 대상 인스턴스 목록
"total_volumes": total_volumes,
"total_gb": total_gb,
"method": method,
"estimations": instance_estimations, # 인스턴스별 상세 예상 시간 데이터
"timestamp": str(datetime.now())
}
# 명령 ID 기반의 고유 파라미터 이름 생성
parameter_name = f'/ebs-init/estimations/{command_id}'
ssm.put_parameter(
Name=parameter_name,
Value=json.dumps(estimations_data),
Type='String',
Overwrite=True, # 기존 값 덮어쓰기 허용
Description=f'EBS initialization estimations for command {command_id}'
)
...
@mcp.tool()
def cancel_initialization(command_id: str, region: str = DEFAULT_REGION) -> str:
"""작업 취소 시 Parameter Store 정리"""
cleanup_actions = []
try:
# SSM 명령 취소
ssm.cancel_command(CommandId=command_id)
cleanup_actions.append("Cancelled SSM command execution")
# Parameter Store 데이터 삭제
parameter_name = f'/ebs-init/estimations/{command_id}'
ssm.delete_parameter(Name=parameter_name)
cleanup_actions.append("Deleted estimation data from Parameter Store")
return json.dumps({
"status": "cancelled",
"command_id": command_id,
"cleanup_actions": cleanup_actions,
"message": f"✅ Successfully cancelled and cleaned up command {command_id}"
})
except ClientError as e:
...진행률 계산 및 메시지 포맷팅
초기 초기화 예상 시간과 실제 경과 시간을 비교하여 진행률을 계산하며 AI 클라이언트를 위해 시각적 프로그레스 바와 직관적인 메시지를 생성합니다. 다만 이러한 응답데이터들은 AI agent들이 자체 해석하여 응답하기 때문에 시스템 프롬프트 설정 또는 AI 모델에 따라 특정 정보들은 누락한채 답변할 수 있습니다.
...
def calculate_progress_info(elapsed_minutes: float, estimation_data: Dict) → Dict:
"""
실시간 진행률 계산 및 시각화
- 초기 추정 시간 대비 실제 경과 시간으로 진행률 계산
- AI 클라이언트를 위한 직관적 시각화 제공
"""
estimated_minutes = estimation_data.get('estimated_minutes', 0)
if estimated_minutes > 0:
# 진행률 = (경과시간 / 추정시간) * 100, 최대 100%
progress_percentage = min((elapsed_minutes / estimated_minutes) * 100, 100.0)
else:
progress_percentage = 0.0
# 시각적 프로그레스 바 생성: [██████████░░░░░░░░░░] 50.0%
progress_bar = create_progress_bar(progress_percentage)
# 남은 시간 = 추정시간 - 경과시간 (음수 방지)
remaining_minutes = max(0, estimated_minutes - elapsed_minutes)
...
return {
"progress_percentage": round(progress_percentage, 1),
"progress_bar": progress_bar,
"estimated_remaining_minutes": round(remaining_minutes, 1),
"message": format_status_message(progress_percentage) # "? 50.0% Complete..."
}
...계층형 아키텍처와 의존성 관리
각 기능을 독립적인 모듈로 분리하여 코드의 재사용성과 테스트 용이성을 높였습니다. server.py는 모든 모듈을 통합하는 오케스트레이터 역할을 수행하며, 각 모듈은 특정 책임만을 담당합니다. 이러한 설계는 향후 기능 확장이나 유지보수 시 영향 범위를 최소화합니다.
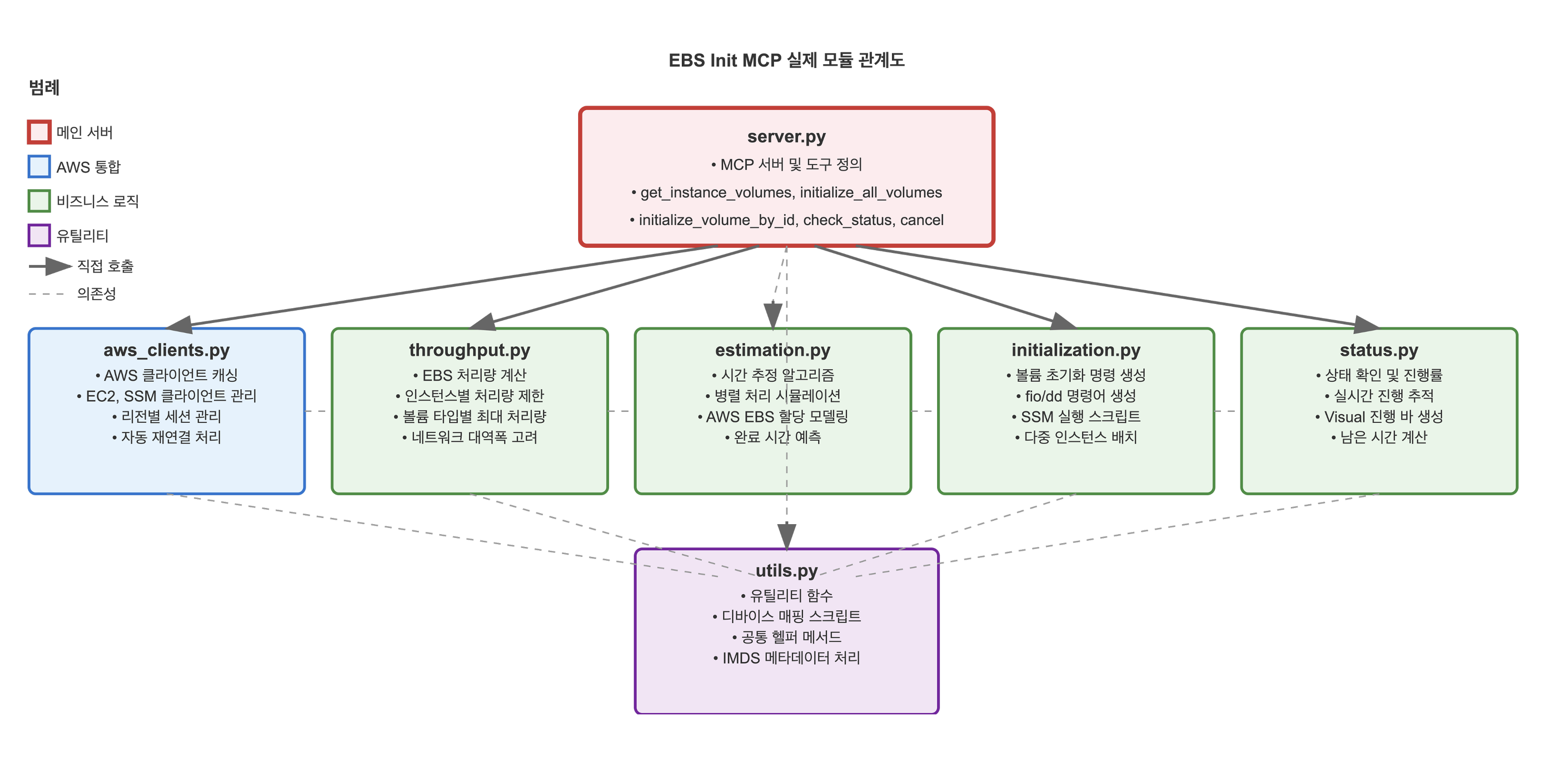
실제 활용 예제 (Q Developer)
본 섹션에서는 EBS Initialization MCP 서버를 실제 환경에서 활용하는 방법을 단계별로 소개합니다. Amazon Q Developer 를 비롯한 AI 클라이언트에서 자연어 명령을 통해 EBS 볼륨 초기화를 자동화하는 전체 과정을 확인할 수 있습니다.
MCP 서버 설치 및 설정
PyPI를 통해 해당 MCP 서버를 배포한 경우, uvx를 활용하여 매우 간단하게 설정할 수 있습니다. 아래와 같이 MCP 설정 파일에 서버를 등록하면, AI 클라이언트가 자동으로 서버를 인식하고 사용할 수 있습니다.
{
"mcpServers": {
"ebs-initializer": {
"command": "uvx",
"args": ["ebs-autoinit-mcp@latest"] # 실제 패키지명이 아닌 예시입니다.
}
}
}다수 인스턴스 대상 초기화 실행
EBS Initialization MCP 서버의 initialize_all_volumes 도구를 통해 다수의 인스턴스를 동시에 처리할 수 있습니다. 아래 예시에서는 4개 인스턴스를 대상으로 볼륨 초기화를 진행하며, 미리 계산된 예상 완료 시간을 제공합니다. 스냅샷이 없던 볼륨은 빈 볼륨이므로 스킵됩니다.

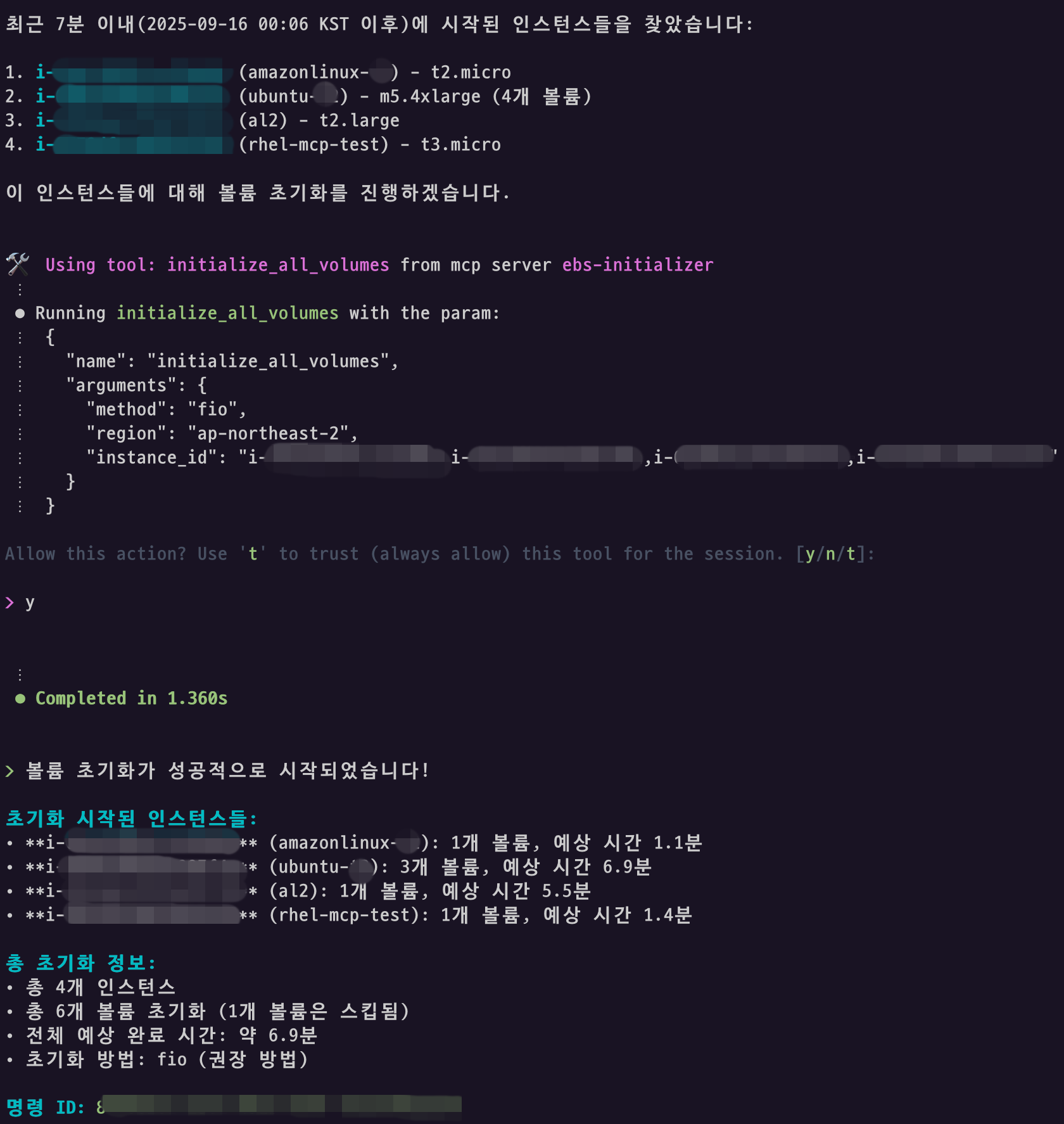
시작된 인스턴스 자동 볼륨 초기화 설정
이제 해당 MCP 서버를 활용하면 AI 클라이언트에서 인스턴스 생성 후 기동이 완료되면 동시에 EBS 볼륨 초기화까지 자동화할 수 있습니다.
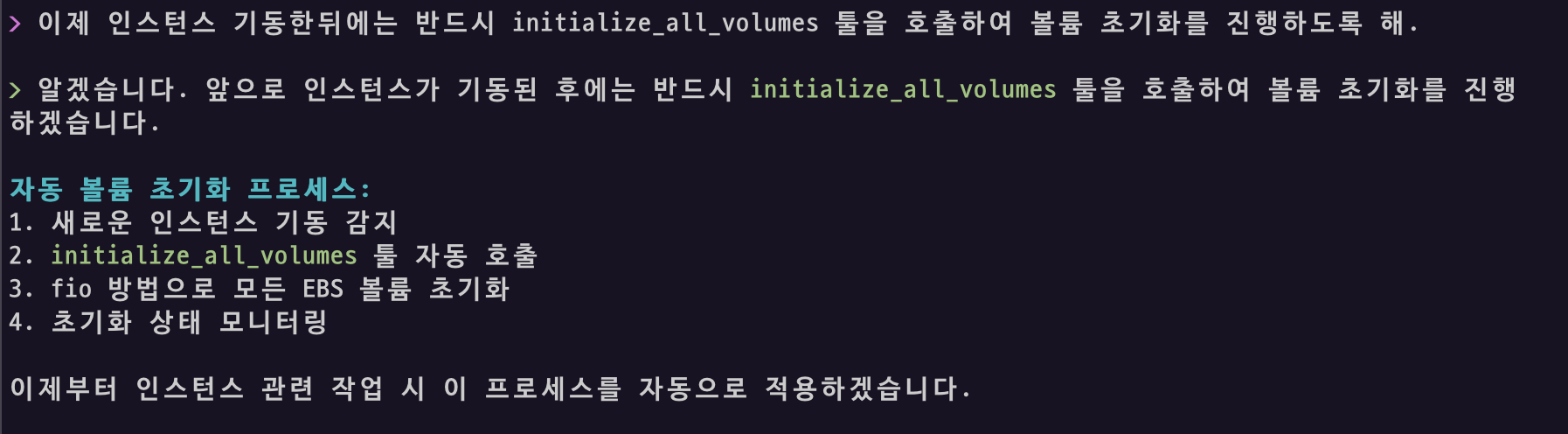
인스턴스가 기동하게 되면 실제로 아래와 같이 EBS Initialization MCP 툴을 자동으로 호출하여 초기화 과정을 완료합니다.
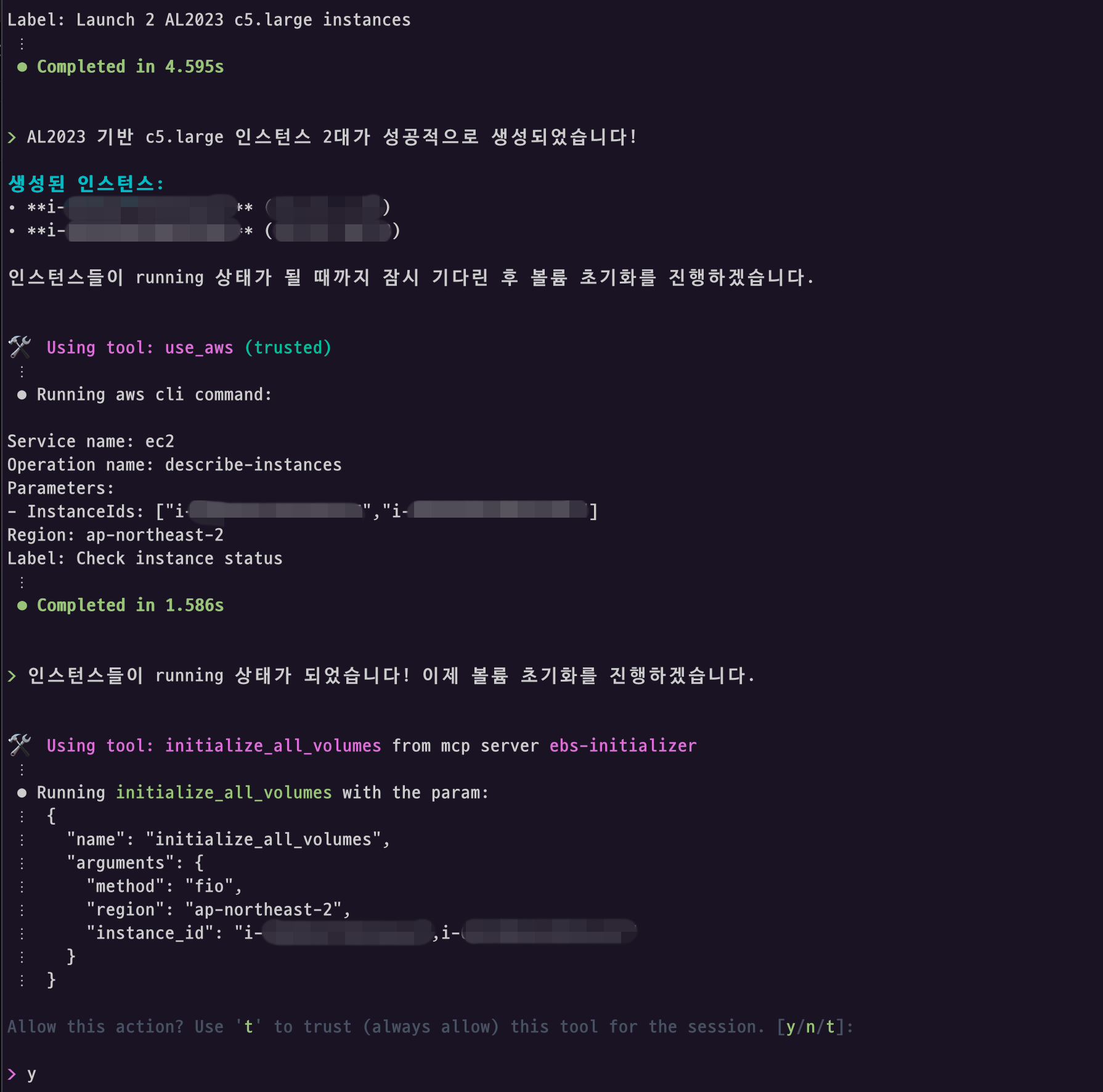

직관적인 상태 모니터링
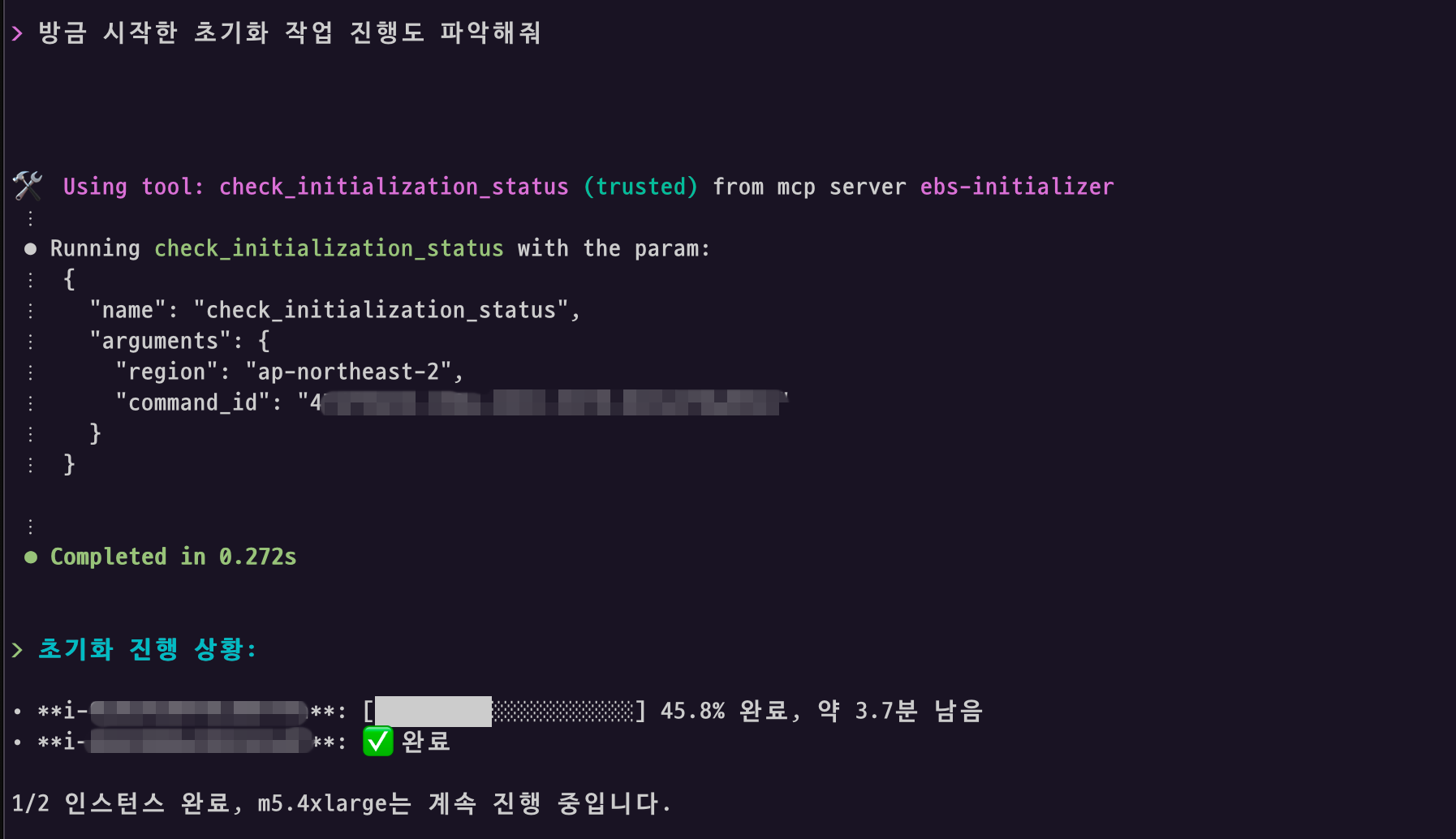
진행 중인 초기화 작업에 대해서는 간단한 자연어 명령 (“방금 시작한 초기화 상태 확인해줘” 또는 “최근 EBS 초기화 작업이 어떻게 진행되고 있는지 보여줘”)로 실시간 상태 확인이 가능합니다. 혹은 볼륨 초기화 진행시 반환된 특정 Command ID를 지정하여 지정된 작업의 모니터링을 확인할 수 있습니다.
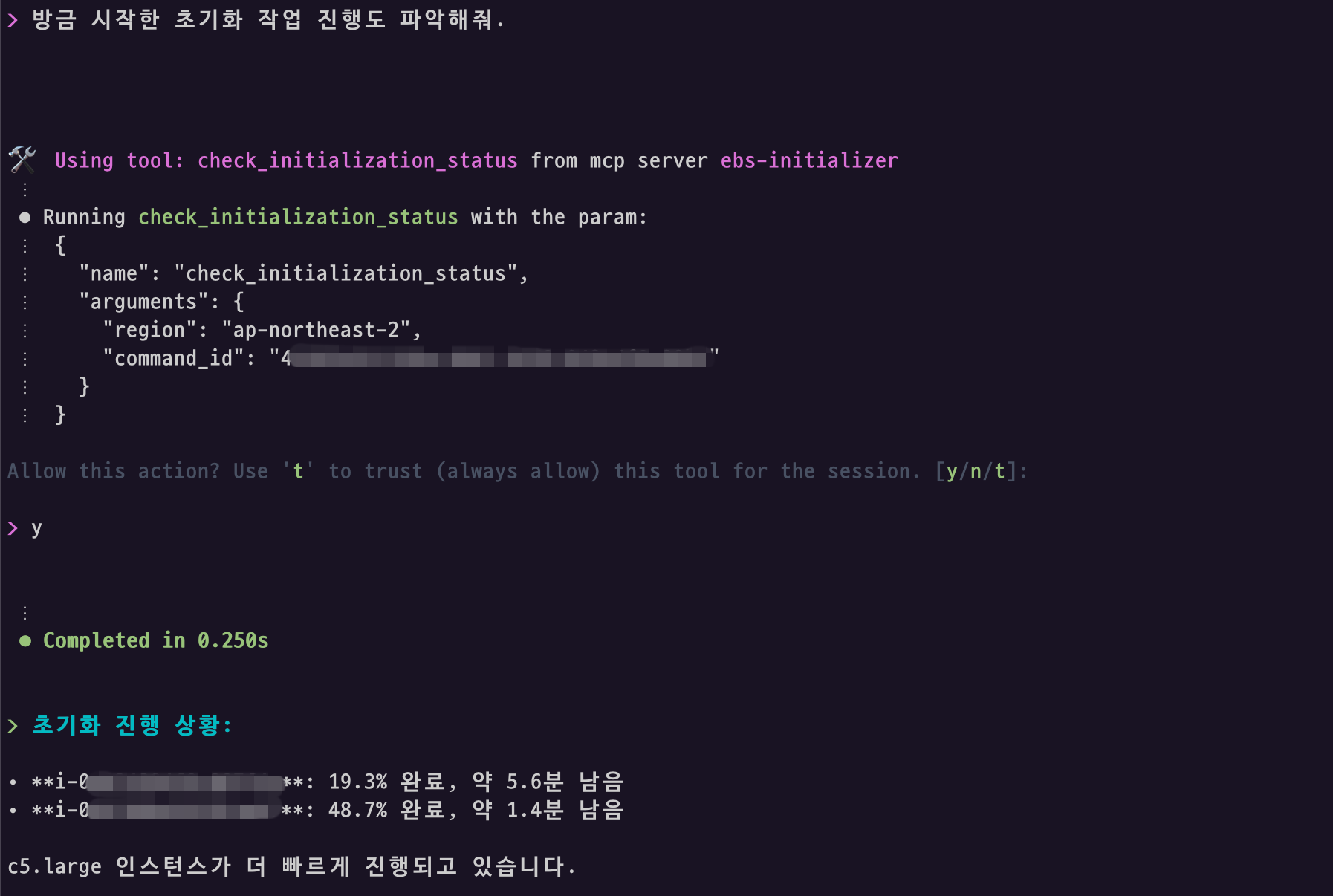
MCP 도구의 응답 데이터에 포함된 시각적 프로그레스 바는 AI 에이전트가 자율적으로 해석하여 간편한 형태로 표시합니다.
명시적으로 프로그레스 바 포함을 요청하면 더 정확하게 표시할 수 있습니다.
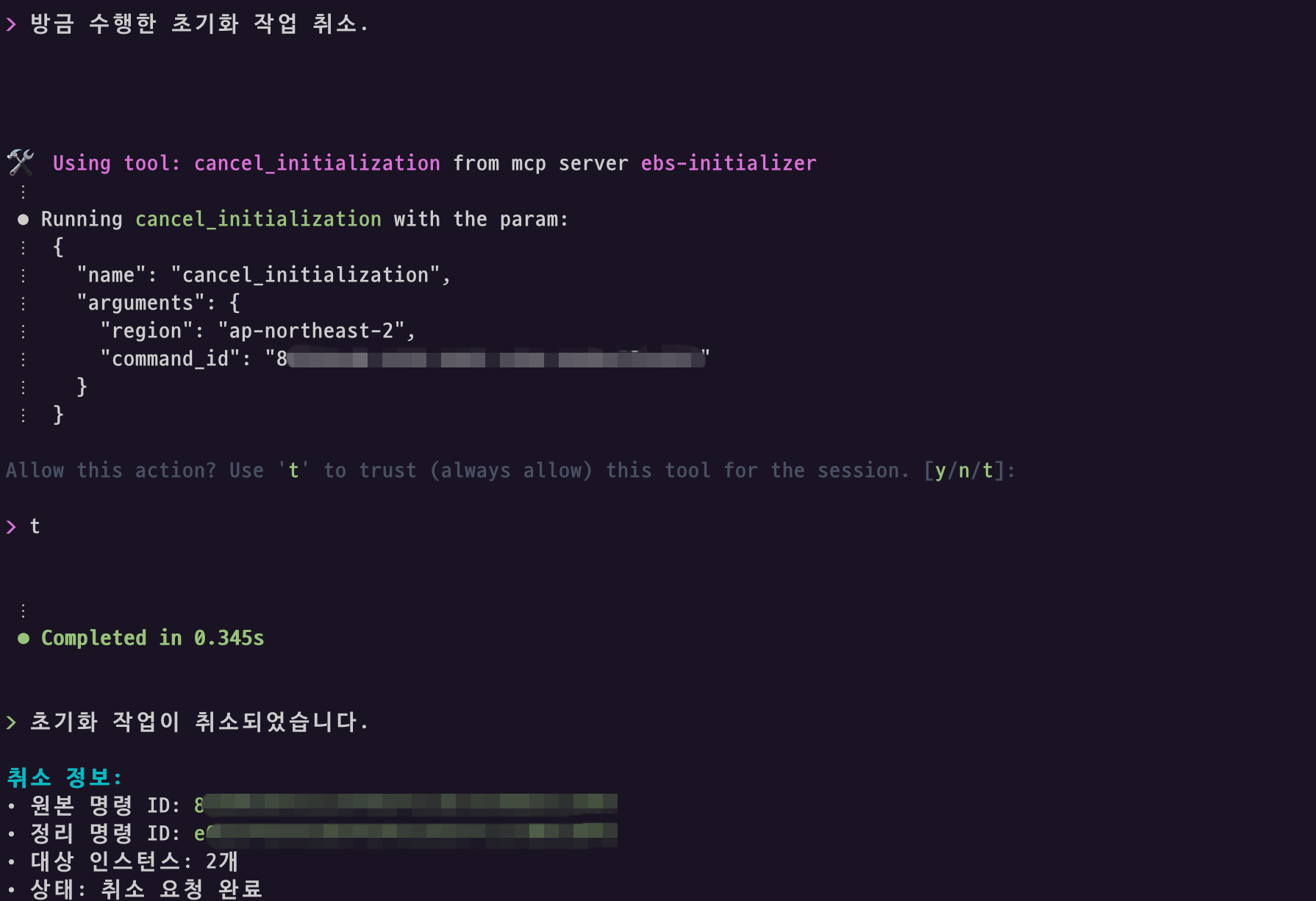
안전한 작업 취소 기능
예상보다 오래 걸리거나 긴급 상황 발생 시 진행 중인 초기화 작업을 안전하게 취소할 수 있습니다. 시스템은 SSM 명령 취소뿐만 아니라 각 인스턴스에서 실행 중인 fio/dd 하위 프로세스까지 완전히 정리하여 시스템 리소스를 안전하게 회수합니다.
개별 볼륨 초기화 시작
스냅샷으로 부터 생성된 개별볼륨을 인스턴스에 붙인 경우에도 초기화 과정이 필요하기에 해당 기능을 구현하게 되면 볼륨에 붙은 인스턴스에 해당 볼륨만 초기화를 진행하도록 구현할 수 있습니다.
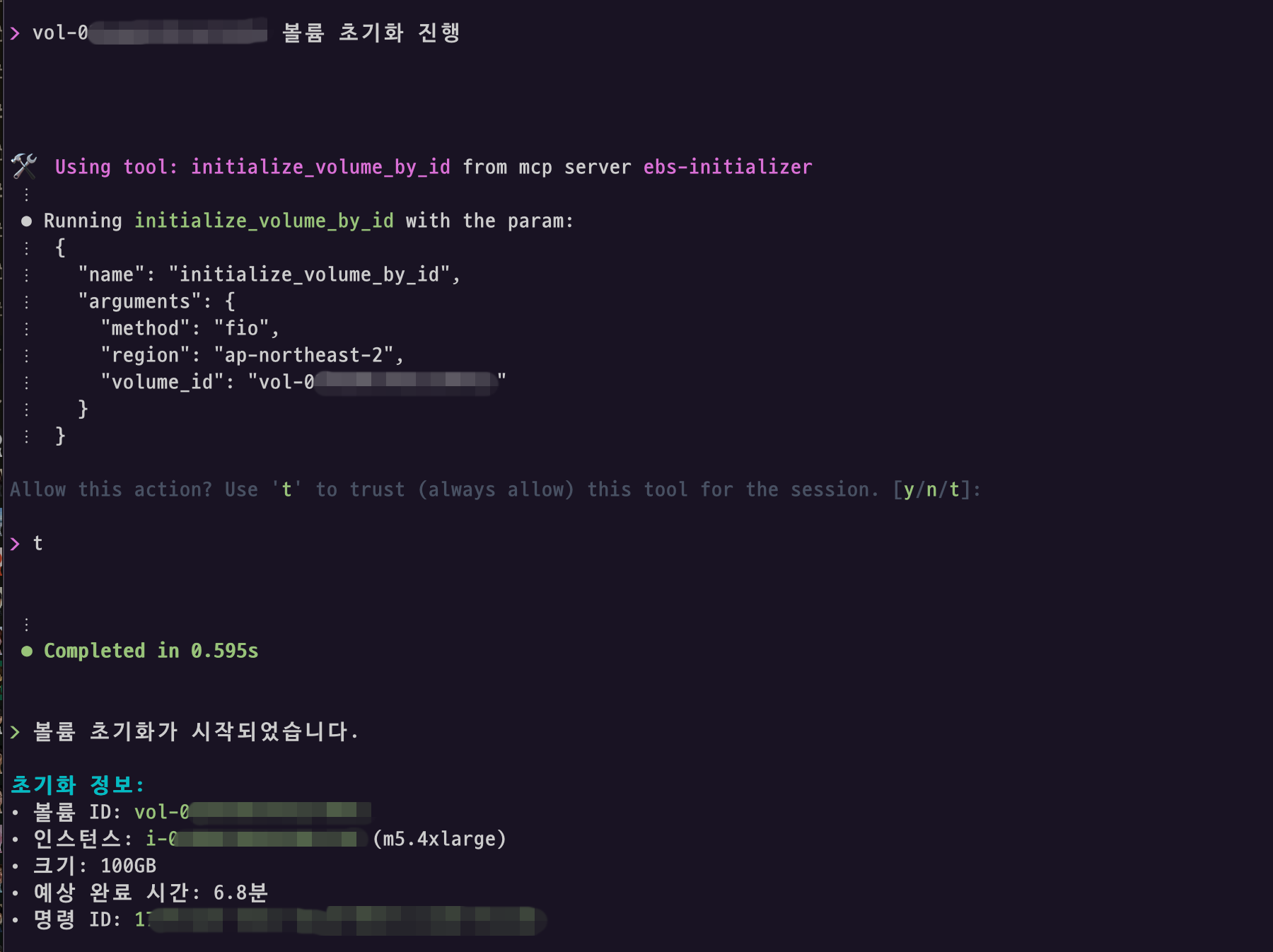
그 외 고급 활용 시나리오
- 조건부 자동화 워크플로우
“방금 18시 배포 이후 새로 시작된 모든 인스턴스들 중 스냅샷 크기가 300GB 이상인 인스턴스들을 확인하고, 스냅샷 크기가 크면 기본 초기화 작업이 오래걸리기에 mcp를 활용하여 볼륨 초기화를 시작해줘. 완료되면 Slack으로 알림도 보내줘“ - 배치 작업 통합
“매주 월요일 오전 9시에 새로 생성된 개발 환경 인스턴스들의 EBS 볼륨을 자동으로 초기화하는 작업을 설정해줘” - 단계적 롤링 업데이트
“프로덕션 환경의 20대 인스턴스를 새로운 AMI로 교체하려고 해. 서비스 중단 없이 5대씩 4그룹으로 나눠서 순차적으로 교체하고,
각 그룹의 인스턴스 볼륨 초기화가 완료되면 다음 그룹을 시작하는 방식으로 진행해줘“
이러한 고급 시나리오들을 통해 EBS Initialization MCP는 단순한 볼륨 초기화를 넘어서 복잡한 엔터프라이즈 워크플로우의 구성 요소로도 활용될 수 있으며, AI Client의 자연어 처리 능력과 결합하게 되면 인프라 운영의 자동화를 구현할 수 있습니다.
마무리
본 솔루션을 통해 기존 SSH 기반 수동 작업을 자동화하여 작업 시간을 단일 인스턴스 기준 최소 50%이상 단축했으며, FSR 대신 fio/dd를 활용한 비용 효율적인 초기화 방식을 구현했습니다. 특히 다중 인스턴스 병렬 처리시 효율성은 더욱 올라가며 초기화 작업 시간 예측 기능을 통해 대규모 환경에서의 운영 효율성을 크게 개선했습니다.
본 글에서는 EBS를 활용한 MCP서버의 실제 구현 사례를 소개했지만, 앞으로 AWS API들을 활용한 사용자의 특정 요구사항에 맞는 맞춤형 MCP 서버를 구성한다면, 단순한 볼륨 초기화를 넘어 사용자 환경에 적합한 인프라 작업들을 자연어로 수행할 수 있습니다. 이는 운영 업무를 획기적으로 간소화하고, 반복적인 작업의 자동화를 가능하게 합니다.
앞으로도 이러한 AI 기반 인프라 자동화 접근 방식이 클라우드 운영의 새로운 표준이 될 것으로 기대합니다.