O blog da AWS
Como otimizar inferências de LLMs com Amazon EKS e NVIDIA Dynamo
Fernando Schroder, Arquiteto de Soluções para Setor Público na AWS e Michael Silva, Sr. Solutions Architect na AWS.
Com o crescimento do uso dos Modelos de Linguagem (LLMs e SLMs), também cresceu a demanda por infraestrutura que comporte esse tipo de aplicação. Segundo o Gartner mais de 75% de todas as implementações de IA utilizarão a tecnologia de contêineres como o ambiente de computação subjacente até 2027. O crescimento é impulsionado pela capacidade dos contêineres de fornecer ambientes consistentes e escaláveis para a implantação de modelos de IA. Com isso vem o uso de uma orquestração de container baseada em Kubernetes, por conta de diversos benefícios que esse tipo de arquitetura oferece para cargas de trabalho de Machine Learning, que aprofundaremos mais durante esse blogpost.
O Amazon Elastic Kubernetes Service (Amazon EKS) é o serviço gerenciado para trabalhar com cluster kubernetes na nuvem da AWS. O Amazon EKS é escolhido por usuários para inferência de LLMs por trazer benefícios aos que optam pelo seu uso como por exemplo:
- Otimização de custos – O Amazon EKS permite que você combine instâncias sob Demanda, Spot e Instâncias reservadas para compor o poder computacional do seu cluster.
- Alta escalabilidade – O Amazon EKS pode escalar até 100 mil nós dentro de um mesmo cluster, tendo integração nativa com plug-in e add-ons para controle dessa escalabilidade.
- Customização avançada – nesse cenário o usuário possui total controle sobre o modelo e os dados que estão sendo utilizados, além das configurações dos parâmetros e dos recursos utilizados pelo modelo.
- Possibilidade de ser hospedado de múltiplas formas – Seja na nuvem, on-premises ou na borda e de forma consistente.
- Redução da complexidade operacional em um ambiente kubernetes – Por padrão, o Control Plane do seu cluster já é gerenciado pela AWS. O Auto Mode do Amazon EKS permite que você delegue o gerenciamento de tarefas operacionais dos seus nós para a AWS, clique aqui para saber mais.
Neste blog post vamos explorar as principais ferramentas e maneiras para você otimizar o seu processo de inferência entre diferentes modelos utilizando o Amazon EKS, além de prover benchmarks reais entre eles.
Arquitetura utilizada:
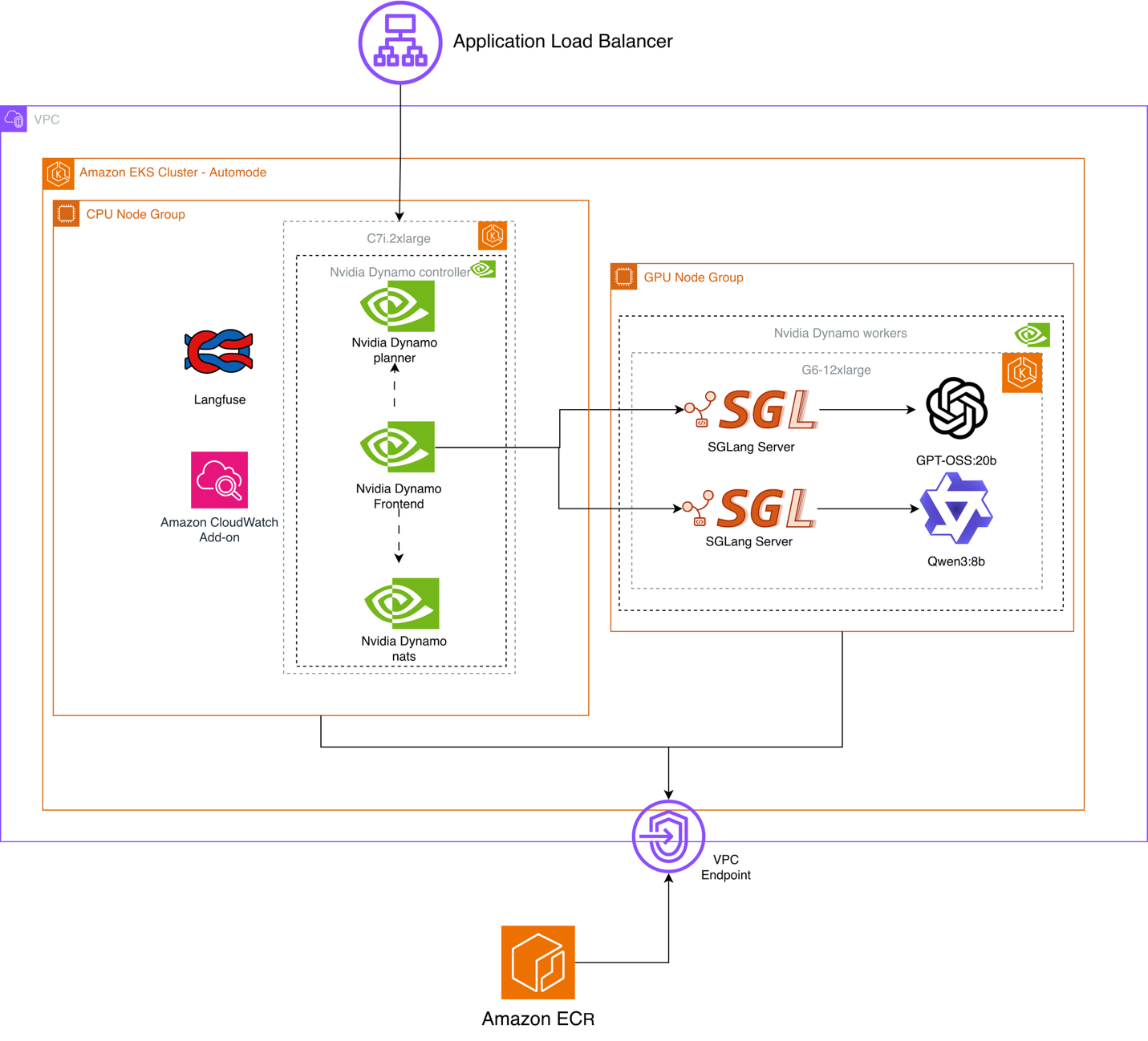
Figura 1 – Arquitetura da hospedagem de múltiplos modelos no Amazon EKS
| Ferramenta | Função na Arquitetura | Provedor |
| Application Load Balancer | Balanceador de carga | AWS |
| Amazon Elastic Container Registry (ECR) | Armazenamento de imagens docker | AWS |
| Amazon Elastic Compute Cloud (EC2) | Serviço de máquinas virtuais (suporta computação acelerada por GPU) | AWS |
| Amazon EKS Auto Mode | Escalabilidade automática do cluster com base em demanda | AWS |
| Amazon CloudWatch | Observabilidade das métricas de computação do cluster (Uso de memória, CPU, GPU) | AWS |
| Langfuse | Observabilidade das métricas de performance de machine learning: Tokens de entrada, tokens de saída, Time-to-First-Token (TTFT) e tempo total de inferência. | Open Source |
Modelos Utilizados:
GPT-OSS-20B: Modelo Open-Source da OpenAI, resultados semelhantes ao OpenAI o3‑mini, específico para baixa latência e casos de uso especializados e tarefas agênticas. Dentre as suas especificações, ele necessita de uma instância de no mínimo 16GB de memória de GPU para ser hospedado.
Qwen3-8B: A mais recente geração de modelos de linguagem grandes da série Qwen da Alibaba Group, oferecendo um conjunto abrangente de modelos densos e mixture-of-experts (MoE). Construído sobre treinamento extensivo, o Qwen3 oferece avanços revolucionários em raciocínio, seguimento de instruções, capacidades de agente e suporte multilíngue.
Aprofundando mais na hospedagem de LLMs dentro do Amazon EKS, e para auxiliar no melhor uso desses recursos, foram usadas 2 ferramentas que auxiliam os usuários a melhorarem seu uso de computação acelerada durante as inferências.
SGLang: é um framework Open source de alta performance para servir modelos de linguagem e modelos de visão-linguagem, projetado para entregar inferência de baixa latência e alto throughput desde uma única GPU até grandes clusters distribuídos. Oferece runtime backend eficiente com recursos como RadixAttention para cache de prefixos, paralelismo tensor/pipeline/expert/dados, quantização (FP4/FP8/INT4/AWQ/GPTQ), e suporte extensivo a modelos generativos (Llama, Qwen, DeepSeek, GPT, Gemma, Mistral) e hardware diverso (NVIDIA, AMD, Intel). Além de ser open-source com comunidade ativa e adoção industrial ampla, oferecendo interface intuitiva para programação de aplicações LLM com compatibilidade às APIs OpenAI e modelos Hugging Face.
NVIDIA Dynamo: Motor de inferência agnóstico (suporta TRT-LLM, vLLM, SGLang) que pode maximizar throughput de GPU através de inferência prefill/decode desagregada, agendamento dinâmico de GPU, roteamento inteligente de requisições LLM, transferência acelerada de dados usando NIXL e offloading de cache KV para maior throughput do sistema. Em termos de componentes, destaca-se o Dynamo Planner, que monitora sinais em tempo real (taxa de requisições, tamanhos de sequência, capacidade de GPU e filas) e decide dinamicamente entre servir de forma desagregada ou agregada, ajustando workers de prefill/decode conforme a demanda. Além disso, a implantação no EKS inclui pods de frontend (API de entrada) e usa NATS como componente da plataforma para integração/coordenação entre serviços (junto de Operator/API Store, etc.).
O uso em conjunto das ferramentas mencionadas leva à uma redução de custos devido à redução de utilização de memória, performance em escala aumentando processing throughput e um maior nível de abstração no topo do processamento, além disso foi implementada uma técnica de paralelização de tensores (TP), dividindo os pesos do modelo em múltiplas GPUs de uma mesma máquina.
Cenário e comparação entre os modelos:
Durante os testes, abordamos cenários comparativos entre os dois modelos com as seguintes configurações:
| Usuários simultâneos | Tokens de Entrada | Tokens de saída | Máquina utilizada (Amazon EC2) | Nº de Pods | Pods por nó | TP |
| 1000 | 2500 | 550 | G6.12xlarge | 8 | 2 | 2 |
Utilizamos a ferramenta Locust, que simula cargas reais de usuários em diversas configurações, para os testes de carga. Entre as métricas selecionadas tivemos: TTFT, latência total da inferência, média de output tokens e requisições por minuto. Como resultados obtivemos as seguintes métricas:
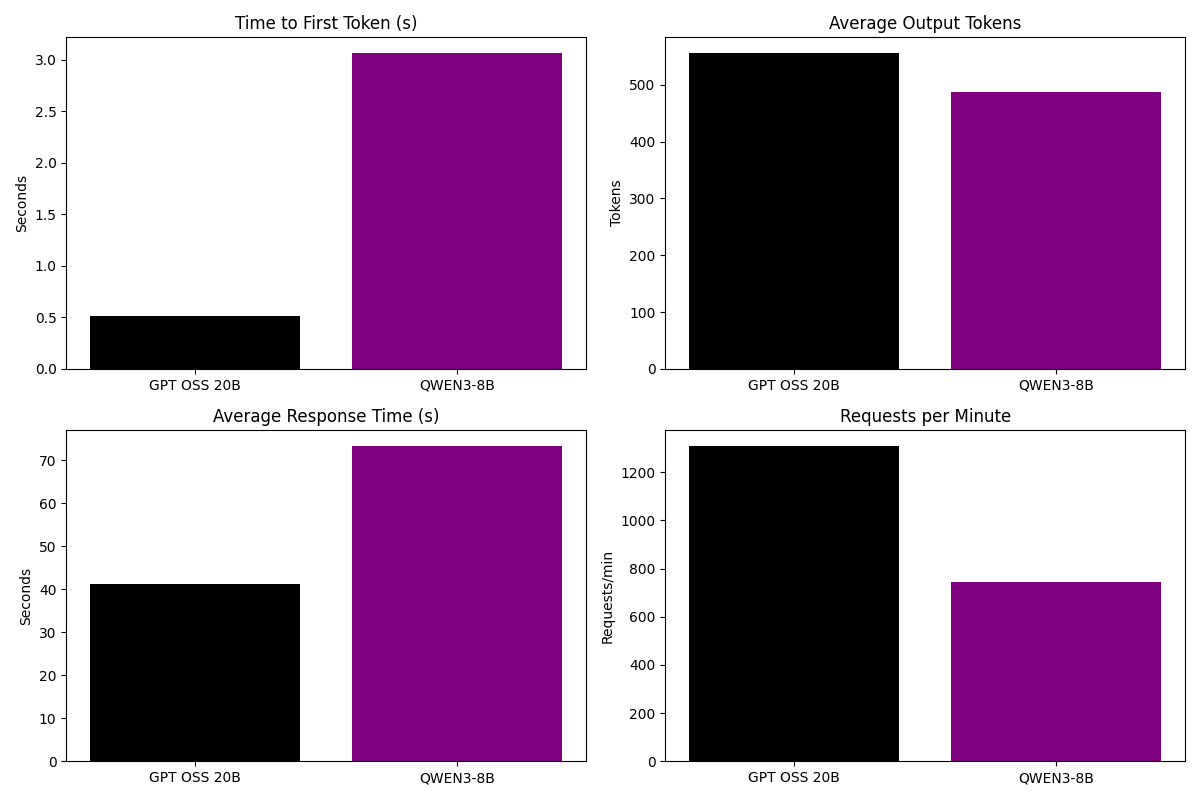
Figura 2 – Comparação de métricas dos modelos
Na tabela a seguir vemos mais detalhes das métricas avaliadas durantes os testes e a performances de cada modelo.
| Modelo | Input Tokens | Output Tokens | RPM | p95 | p50 | Máx req por seg |
| GPT-OSS-20B | 2500 | 550 | 1200 | 45 | 41 | 41 |
| Qwen3-8B | 2500 | 487 | 750 | 80 | 70 | 32 |
Nas imagens abaixo vemos a interface gráfica do Locust para avaliar o comportamento de requisições por minuto, p95 e p50 dos modelos durante os testes.
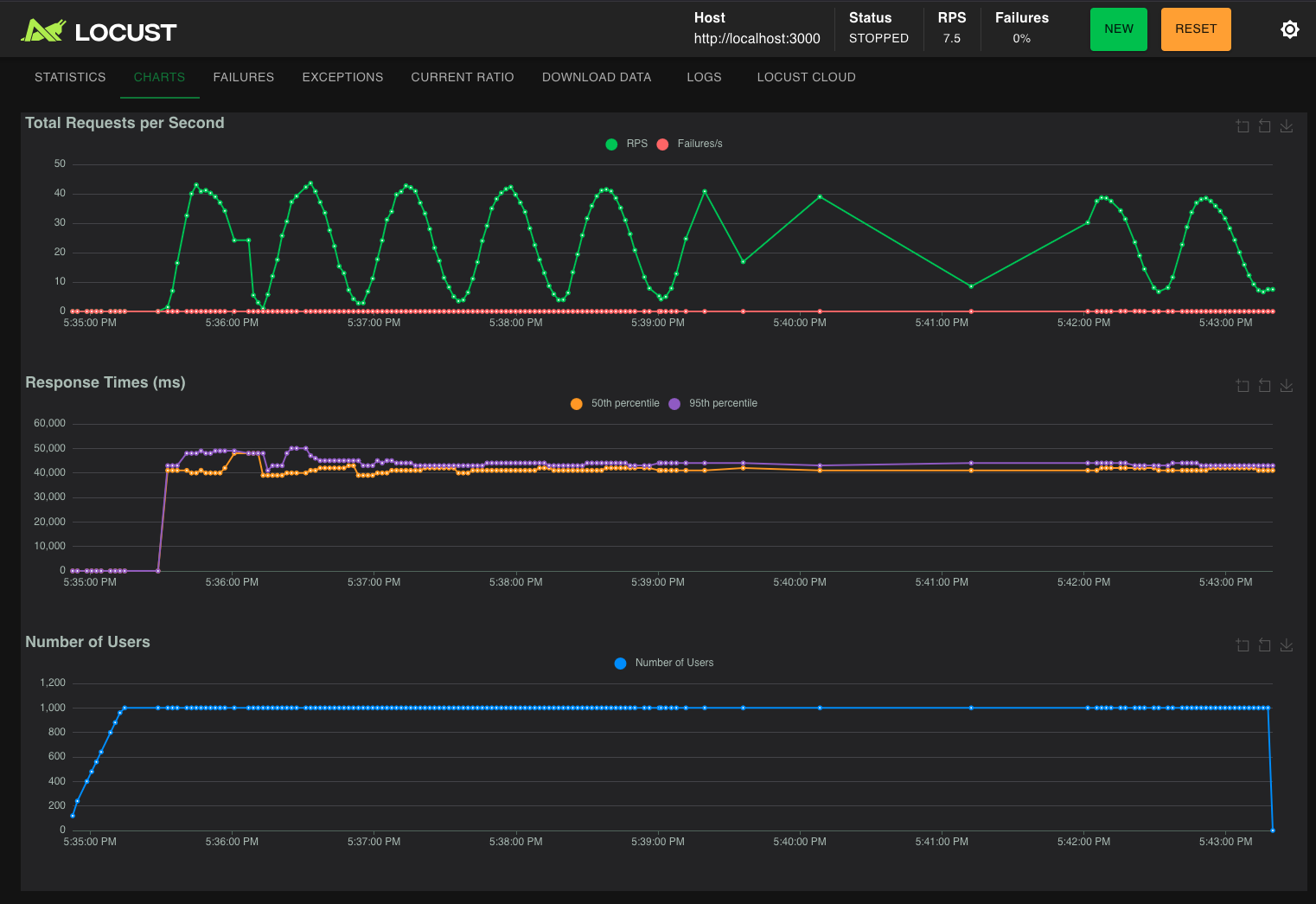
Figura 3 – interface gráfica do Locust durantes os testes do GPT-OSS-20B
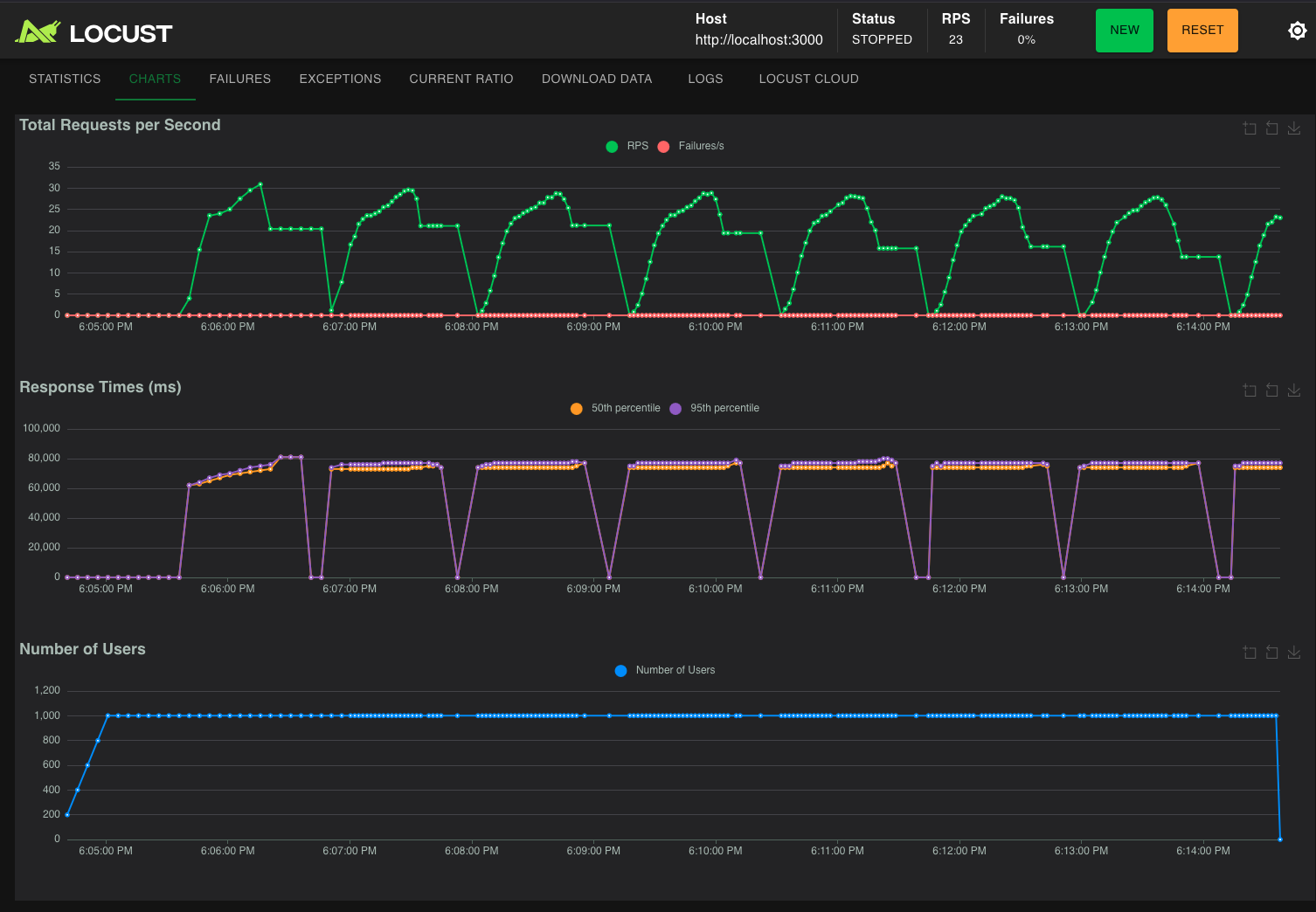
Figura 4 – interface gráfica do Locust durantes os testes do Qwen3-8B
Conclusão:
O GPT-OSS-20B apresentou uma performance superior nas métricas analisadas principalmente em TTFT e tempo total de inferência, mesmo sendo um modelo maior em parâmetros (mostrando os benefícios da quantização de modelos) sendo ideal para cenários onde é necessário maior velocidade nos tempos de resposta e maior volume de inferências simultâneas. Já o Qwen-3 se destaca por gerar menos tokens na saída do modelo, tornando ele uma opção para casos em que o modelo precisa ser mais sucinto e direto em suas respostas. Além disso, o Amazon EKS surge como uma oportunidade de flexibilidade e hospedagem de diversos modelos open-source disponíveis através de ferramentas como SGLang e NVIDIA Dynamo, possibilitando alta escalabilidade, total controle e customização dos modelos.
Para continuar aprendendo em torno desse tema:
- AI on EKS: Projeto público com um conjunto extensivo de ferramentas e exemplos de hospedagem de diversos modelos dentro do Amazon EKS, utilizando ferramentas citadas nesse blog entre outras.
- Melhores práticas para Cargas de Trabalho de AIML: A documentação com uma série de recomendações de como implementar workloads de AIML no Amazon EKS.
- Generative AI on Amazon EKS: Um workshop prático sobre como hospedar seus modelos utilizando o Amazon EKS e GPU’s da NVIDIA.
Autores
 |
Fernando Schroder é Arquiteto de Soluções para Setor Público na AWS com foco em Inteligência Artificial e Containers. Formado em Ciência & Tecnologia, Ciência da Computação pela Universidade Federal do ABC e com 5 anos de atuação em nuvem AWS, Fernando guia e orienta clientes nas melhores práticas de utilização da AWS. |
 |
Michael Silva é Sr. Solutions Architect na AWS com foco em Fundações e Containers, incluindo expertise na integração do Amazon EKS com ferramentas open source como Crossplane, Terraform e GitOps. Em seu papel, Michael se dedica a ajudar os clientes a alcançar seus objetivos de negócios implementando as melhores práticas em design e gestão de infraestrutura em nuvem.
|