O blog da AWS
Construindo linhagem de dados de assets customizados no Amazon SageMaker Catalog
Por Andrey Luiz Pelegrini, arquiteto de soluções especialista em Dados na AWS e Luiz Yanai, arquiteto especialista sênior em Data & AI na AWS.
Empresas que operam com governança de dados em escala frequentemente precisam rastrear a linhagem de dados além dos assets tradicionais, como tabelas e views do ambiente analítico. Dashboards do Amazon Quick, Tableau, Power BI e modelos de ML — todos são peças críticas do pipeline de dados, mas historicamente o grafo de linhagem não incluía esses elementos.
Conectar dashboards, notebooks e outros artefatos de analytics ao grafo de dados é um passo essencial para eliminar pontos cegos de governança.
Para resolver esse problema, o Amazon DataZone permite catalogar e rastrear a linhagem de dados entre ambientes AWS, on-premises e de terceiros com o suporte a eventos de linhagem customizados via OpenLineage, integrando qualquer asset externo ao grafo de linhagem e mantendo a visibilidade completa do seu ecossistema de dados.
Neste blog post, utilizaremos o Amazon SageMaker Catalog, que proporciona uma experiência de catálogo e governança de dados integrada ao Amazon SageMaker.
A AWS construiu o Amazon SageMaker Catalog sobre o Amazon DataZone, e oferece as mesmas capacidades de linhagem via OpenLineage, com a vantagem de estar integrado ao ambiente de ML e analytics do SageMaker.
Você aprenderá como usar eventos OpenLineage para publicar a linhagem de um dashboard customizado, desde o JSON do evento até a criação da revisão do asset no catálogo. Ao final, você terá a linhagem completa dos seus dados – da criação das tabelas, passando pelas rotinas de transformação, até os consumidores finais.
Visão geral da solução
O fluxo que vamos implementar é simples:
- Construir um evento OpenLineage que descreve a relação entre um asset de entrada (tabela) e um asset de saída (dashboard customizado)
- Enviar o evento para o Amazon DataZone via API PostLineageEvent
- Vincular o asset customizado ao catálogo do DataZone para que ele apareça no grafo visual de linhagem
A arquitetura segue este modelo:

Pré-requisitos
- Um domínio do Amazon SageMaker Unified Studio e um Projeto criados
- Recuperar o id do domínio e do projeto do Amazon SageMaker Unified Studio. Para recuperá-los, você pode acessar a sessão de Project Details do seu projeto no Amazon SageMaker Unified Studio
- AWS CLI v2 instalada e configurada
- Permissões IAM para datazone:PostLineageEvent e datazone:CreateAssetRevision
Você executará todos os passos a seguir via AWS CLI, porém o serviço também suporta outras formas de execução (como ferramentas de infraestrutura como código e linguagens de programação com a AWS SDK).
Passo 1: Criar um tipo de asset customizado no catálogo
O Amazon DataZone aceita a criação de tipos assets customizados, onde você pode catalogar vários tipos de asset que o serviço não suporta nativamente, como dashboards e modelos de ML.
Vamos usar a api do Amazon Datazone para criar o tipo de asset customizado, com o evento abaixo:
aws datazone create-asset-type \
--domain-identifier {id-dominio} \
--name Dashboards \
--description "Dashboards custom asset" \
--owning-project-identifier {id-projeto} \
--forms-input '{"MyCustomForm": {"required": true, "typeIdentifier": "amazon.datazone.RelationalTableFormType","typeRevision":"1"}}'Passo 2: Criar um custom asset no catálogo
Após a criação de um tipo de asset customizado, iremos realizar a criação de um asset customizado com o tipo criado anteriormente, identificado pelo nome (–name).
Vamos usar a api do Amazon Datazone para criar o asset customizado, com o evento abaixo:
aws datazone create-asset \
--domain-identifier {id-dominio} \
--name 'Customers Revenue Dashboard' \
--owning-project-identifier {id-projeto} \
--type-identifier DashboardsPasso 3: Recuperar o identificador do asset customizado criado
Após a criação de um asset customizado, precisamos recuperar seu identificador para utilizarmos na publicação dos eventos de linhagem, identificando pelo nome do asset customizado criado anteriormente (–name e –search-text).
Vamos usar a api do Amazon Datazone para recuperar o identificador do asset customizado, com o evento abaixo:
aws datazone search \
--domain-identifier {id-dominio} \
--search-scope ASSET \
--owning-project-identifier {id-projeto} \
--search-text "Customers Revenue Dashboard" \
--region us-east-1 \
--query "items[].assetItem.[identifier,name]" \
--output tablePasso 4: Construir o evento OpenLineage
O Amazon DataZone aceita eventos no formato OpenLineage, um padrão aberto para rastreamento de linhagem de dados. O evento descreve um job (a transformação), seus inputs e outputs. Aqui temos dois pontos chave:
- facet symlinks: é ele que permite mapear um dataset do evento para um asset existente no catálogo — ou criar a referência para um asset do tipo CUSTOM_ASSET e;
- em outputs, colocar o nome exato do asset customizado criado anteriormente (no nosso caso, “Customers Revenue Dashboard”), para garantir que nosso asset customizado tenha um link com o output do evento de linhagem.
Crie o arquivo do evento:
cat > /tmp/lineage_event.json << 'EOF'
{
"eventTime": "2026-03-09T14:16:00.000Z",
"producer": "https://example.com/glue",
"schemaURL": "https://openlineage.io/spec/2-0-2/OpenLineage.json#/$defs/RunEvent",
"eventType": "COMPLETE",
"run": {
"runId": "d3a1f8c2-1234-4b5a-9c6d-7e8f9a0b1c2d"
},
"job": {
"namespace": "{id-dominio}",
"name": "Customers Revenue Dashboard Load",
"facets": {
"jobType": {
"_producer": "https://example.com/glue",
"_schemaURL": "https://openlineage.io/spec/facets/2-0-2/JobTypeJobFacet.json#/$defs/JobTypeJobFacet",
"processingType": "BATCH",
"integration": "SPARK",
"jobType": "JOB"
}
}
},
"inputs": [
{
"namespace": "{id-dominio}",
"name": "Customer Table",
"facets": {
"symlinks": {
"_producer": "https://example.com/glue",
"_schemaURL": "https://openlineage.io/spec/facets/1-0-0/SymlinksDatasetFacet.json#/$defs/SymlinksDatasetFacet",
"identifiers": [
{
"namespace": "{id-dominio}",
"name": "customer",
"type": "TABLE"
}
]
}
}
},
{
"namespace": "{id-dominio}",
"name": "Sales Table",
"facets": {
"symlinks": {
"_producer": "https://example.com/glue",
"_schemaURL": "https://openlineage.io/spec/facets/1-0-0/SymlinksDatasetFacet.json#/$defs/SymlinksDatasetFacet",
"identifiers": [
{
"namespace": "{id-dominio}",
"name": "sales",
"type": "TABLE"
}
]
}
}
}
],
"outputs": [
{
"namespace": "{id-dominio}",
"name": "Customers Revenue Dashboard",
"facets": {
"symlinks": {
"_producer": "https://example.com/tableau",
"_schemaURL": "https://openlineage.io/spec/facets/1-0-0/SymlinksDatasetFacet.json#/$defs/SymlinksDatasetFacet",
"identifiers": [
{
"namespace": "{id-dominio}",
"name": "{nome-asset-customizado}",
"type": "CUSTOM_ASSET"
}
]
}
}
}
]
}
EOFVamos detalhar os elementos mais importantes:
| Campo | Descrição |
| namespace | O identificador do domínio DataZone. Deve corresponder ao domínio onde a linhagem de dados será registrada. |
| symlinks.identifiers[].type | Define o tipo do asset. Use TABLE para tabelas existentes no catálogo e CUSTOM_ASSET para assets externos como dashboards. |
| symlinks.identifiers[].name | O nome que será usado para vincular o evento ao asset no catálogo do DataZone. |
| eventType | O estado da execução. COMPLETE indica que o job finalizou com sucesso. Outros valores possíveis: START, RUNNING, FAIL, ABORT. |
| job.facets.jobType.integration | Identifica a ferramenta de origem (ex: tableau, powerbi, custom-etl). |
Passo 5: Enviar o evento para o Amazon DataZone
Com o evento construído, envie-o usando a AWS CLI:
aws datazone post-lineage-event \
—domain-identifier {id-dominio} \
—region us-east-1 \
—event fileb:///tmp/lineage_event.jsonNote o uso de fileb:// (com o “b”) — isso garante que o conteúdo seja enviado como binary payload, que é o formato esperado pela API.
Uma resposta bem-sucedida retorna HTTP 200 sem corpo, confirmando que o serviço aceitou o evento e o processará de forma assíncrona.
Passo 6: Gerar uma nova revisão do asset customizado ao catálogo
O evento de linhagem cria os nós no grafo, mas para que o asset customizado apareça como um asset navegável no catálogo do DataZone, é necessário vinculá-lo usando o campo sourceIdentifier no formulário do asset (recuperado no Passo 3). O formato é {namespace}/{name}, onde os valores devem corresponder exatamente ao que foi definido no output do evento OpenLineage.
aws datazone create-asset-revision \
--domain-identifier {id-dominio} \
--identifier {identificador-asset-customizado} \
--name "Customer Revenue Dashboard" \
--forms-input '[{"formName":"AssetCommonDetailsForm","typeIdentifier":"amazon.datazone.AssetCommonDetailsFormType","content":"{\"sourceIdentifier\":\"{id-dominio}/{nome-asset-customizado}\"}"}]' \
--region us-east-1O sourceIdentifier segue o padrão {namespace}/{name} e é o que conecta o asset do catálogo ao nó correspondente no grafo de linhagem. Sem esse vínculo, o evento de linhagem existe mas o asset aparece como um nó “desconhecido” no grafo visual.
Ao final dos passos anteriores, podemos ver que o grafo de linhagem foi corretamente publicado no nosso asset customizado.
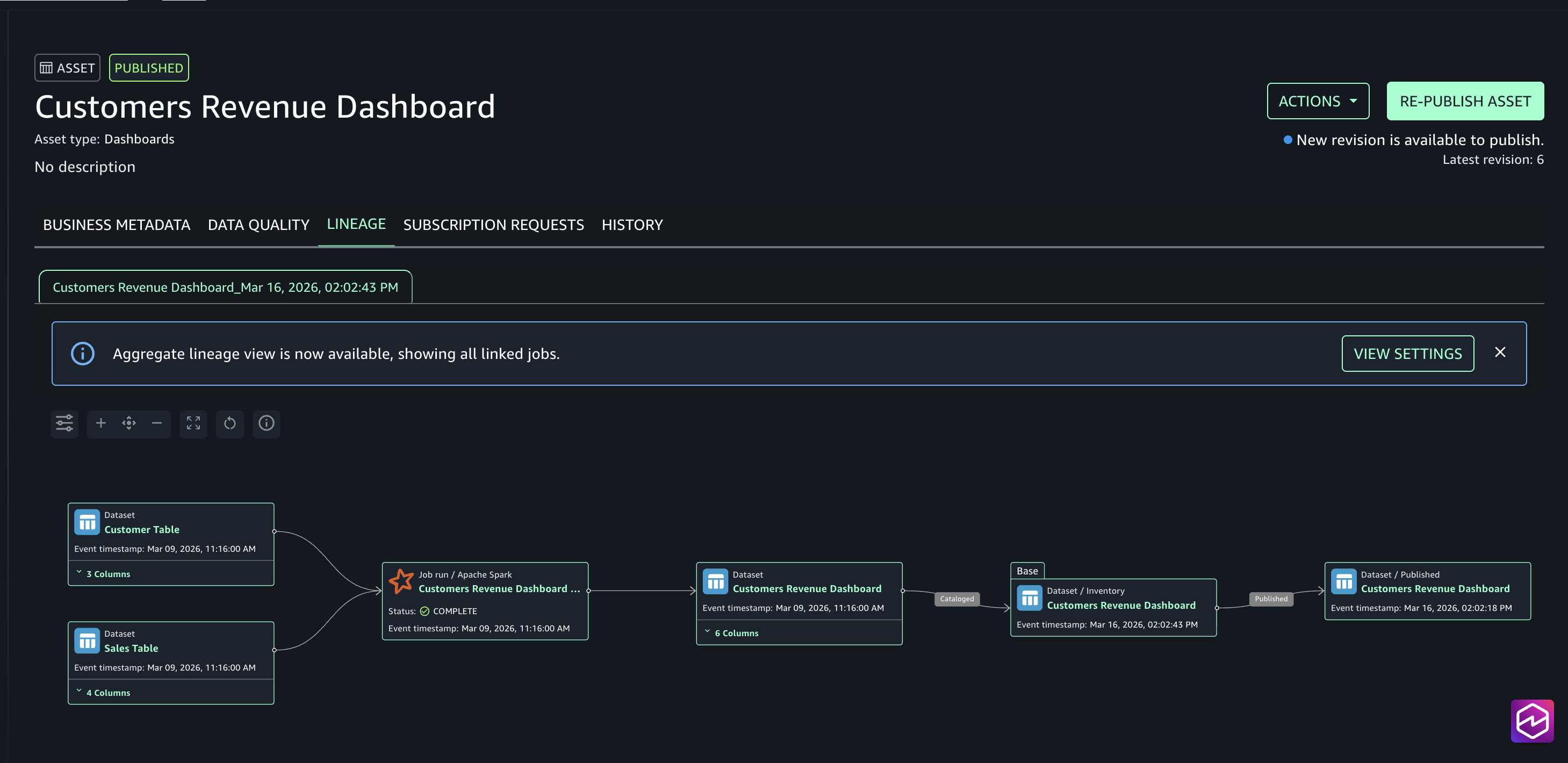 Fig. 1 – Resultado final de linhagem de dados com o asset customizado do dashboard representado
Fig. 1 – Resultado final de linhagem de dados com o asset customizado do dashboard representado
O que acontece nos bastidores
Quando o Amazon DataZone recebe o evento OpenLineage:
- O serviço faz o parse do evento e identifica os datasets de input e output
- Para cada dataset com symlinks, ele tenta resolver o asset correspondente no catálogo usando namespace + name + type
- Assets do tipo TABLE são resolvidos automaticamente se já existirem no catálogo
- Assets do tipo CUSTOM_ASSET precisam do vínculo manual via sourceIdentifier (Passo 6)
- O grafo de linhagem é atualizado e fica disponível na console do DataZone
Considerações e boas práticas
- Idempotência: Eventos com o mesmo runId e eventType são tratados como idempotentes. Reenviar o mesmo evento não duplica nós no grafo.
- Namespace consistente: Use sempre o domain identifier como namespace para garantir que os assets sejam resolvidos corretamente dentro do domínio.
- Automação: Em produção, integre o envio de eventos ao pipeline de integração contínua e implantação contínua (CI/CD) ou ao scheduler de atualização do dashboard, para manter a linhagem atualizada automaticamente.
- Múltiplos inputs: Um único evento pode referenciar múltiplos inputs, permitindo modelar dashboards que consomem dados de várias tabelas.
- Monitoramento: Use o Amazon CloudWatch para monitorar chamadas à API PostLineageEvent e configurar alarmes para falhas de ingestão.
Conclusão
Ao suportar eventos OpenLineage, o Amazon DataZone permite estender o grafo de linhagem além dos dados puramente catalogados, incluindo dashboards, notebooks, modelos de ML e qualquer outro asset que faça parte do seu pipeline. Com isso, times de governança conseguem analisar impacto de mudanças em assets de forma confiável, mesmo quando os consumidores finais estão fora do catálogo tradicional.
Neste post, mostramos como registrar assets customizados e publicar eventos de linhagem para recursos que antes ficavam fora do grafo. Adapte o exemplo ao seu pipeline de dados para ampliar a rastreabilidade e a confiança na governança do seu ambiente.
Se governança de dados é prioridade na sua organização, é importante incluir a linhagem de dados nas decisões estratégicas: comece mapeando seus assets customizados através de eventos OpenLineage no Amazon DataZone e envolva data owners, times de segurança e negócio na definição de políticas em torno desse grafo. É assim que a linhagem deixa de ser apenas um diagrama técnico e passa a sustentar decisões, auditorias e gestão de risco em escala.
Recursos adicionais:
- Amazon DataZone Documentation — Data Lineage
- OpenLineage Specification
- API Reference — PostLineageEvent
Sobre os autores
 |
Andrey Luiz Pelegrini é arquiteto de soluções especialista em Dados na AWS. Possui mais de 10 anos de experiencia em arquiteturas de software e dados, entre diferentes industrias do mercado. Atua como trusted advisor na jornada de dados dos clientes, liderando o desenvolvimento de soluções em Data Mesh, Governança de Dados, Operational Analytics, Processamento batch e streaming, e plataformas de dados na nuvem. |
 |
Luiz Yanai é arquiteto especialista sênior em Data & AI na AWS atuando com clientes nativos na nuvem e empresas do ramo financeiro em suas jornadas para se tornarem data-driven. Possui 20 anos de experiência em arquitetura e desenvolvimento de soluções envolvendo sistemas empresariais e de missão crítica sendo que os últimos 7 anos estão focados na nuvem AWS. |