O blog da AWS
Crie aplicações de alto desempenho com AWS Lambda Managed Instances
Por Maria Debasis Rath, Arquiteto de Soluções Sênior na Amazon Web Services e Stephen Liedig, Principal GTM SA Serverless na Amazon Web Services.
Aplicações de alto desempenho, como processamento intensivo de CPU, análises com uso intensivo de memória e pipelines de dados em estado estacionário, geralmente exigem recursos de computação mais previsíveis do que as configurações padrão do AWS Lambda oferecem. O AWS Lambda Managed Instances (LMI) resolve isso ao permitir que você execute funções Lambda em tipos de instância Amazon EC2 selecionados, mantendo o modelo de programação do Lambda. Você pode escolher entre mais de 400 tipos de instância do Amazon Elastic Compute Cloud (Amazon EC2) de famílias de uso geral, otimizadas para computação ou otimizadas para memória para atender aos requisitos da carga de trabalho. O AWS Lambda continua a gerenciar operações de infraestrutura, como gerenciamento do ciclo de vida da instância, aplicação de patches do sistema operacional, atualizações de runtime, roteamento de solicitações e escalabilidade automática. Essa abordagem dá às suas equipes maior controle sobre as características de computação, modelo de preços do EC2 e reduz a sobrecarga operacional de gerenciar servidores ou clusters.
Nesta publicação, você vai aprender a configurar o AWS Lambda Managed Instances criando um Capacity Provider que define sua infraestrutura de computação, associando sua função Lambda a esse provedor e publicando uma versão da função para provisionar os ambientes de execução. Concluímos com práticas recomendadas para produção, incluindo estratégias de escalabilidade, segurança de thread e observabilidade para um desempenho confiável.

Figura 1. Criando Função no LMI
Criando Capacity Providers
Um Capacity Provider define o blueprint de infraestrutura para executar funções LMI no Amazon EC2. Ele especifica tipos de instância, posicionamento de rede e comportamento de escalabilidade. Para criar um Capacity Provider, você precisa de dois parâmetros: uma função IAM (Capacity Provider Operator Role) que concede permissões ao Lambda para iniciar e gerenciar instâncias e a configuração de VPC com sub-redes e grupos de segurança. Crie essa função na sua conta com a política gerenciada AWSLambdaManagedEC2ResourceOperator seguindo o Princípio do Menor Privilégio (conceder apenas as permissões mínimas necessárias).
Este comando cria um Capacity Provider com tipos de instância e configuração de escalabilidade:
Este comando retorna um ARN do Capacity Provider que você usará para criar sua função LMI. O comportamento das suas funções depende de quatro configurações principais no capacity provider:
Seleção de instância
Atualmente, o Lambda suporta três famílias de instâncias Amazon EC2 (.large e superiores): C (otimizadas para computação) para cargas intensivas de CPU, M (uso geral) para cargas de trabalho balanceadas e R (otimizadas para memória) para grandes conjuntos de dados. Escolha arquiteturas x86 (Intel/AMD) ou ARM (Graviton). Se você não especificar tipos de instância, o Lambda usa como padrão instâncias apropriadas com base na configuração de memória e CPU da sua função. Esse é o ponto de partida recomendado, exceto se você tiver requisitos específicos de desempenho. Se você precisar de mais controle, use AllowedInstanceTypes para especificar apenas os tipos de instância que o Lambda pode usar ou use ExcludedInstanceTypes para excluir tipos específicos e permitir todos os outros. Você não pode usar ambos os parâmetros juntos.
VPC e rede
Configure várias sub-redes em diferentes Zonas de Disponibilidade. O Lambda cria uma frota mínima de três instâncias Amazon EC2 distribuídas nas Zonas de Disponibilidade configuradas para manter disponibilidade e resiliência. O tráfego de saída das funções, incluindo logs do Amazon CloudWatch, transita pela interface de rede da instância Amazon EC2 em sua Amazon Virtual Private Cloud (Amazon VPC). Como as funções enviam logs e métricas para o CloudWatch, você vai precisar de acesso à internet por meio de um NAT Gateway ou endpoints de VPC com AWS PrivateLink para o Amazon CloudWatch. Isso afeta apenas o tráfego de saída — as solicitações de invocação não passam pela sua VPC. Os grupos de segurança associados às suas instâncias devem permitir apenas o tráfego necessário para o código da sua função. Com o LMI, configure a VPC uma vez no nível do Capacity Provider em vez de por função, o que simplifica o gerenciamento de várias funções LMI. As funções Lambda padrão continuam usando suas próprias configurações de VPC. Essa configuração de VPC do Capacity Provider se aplica apenas a funções LMI.
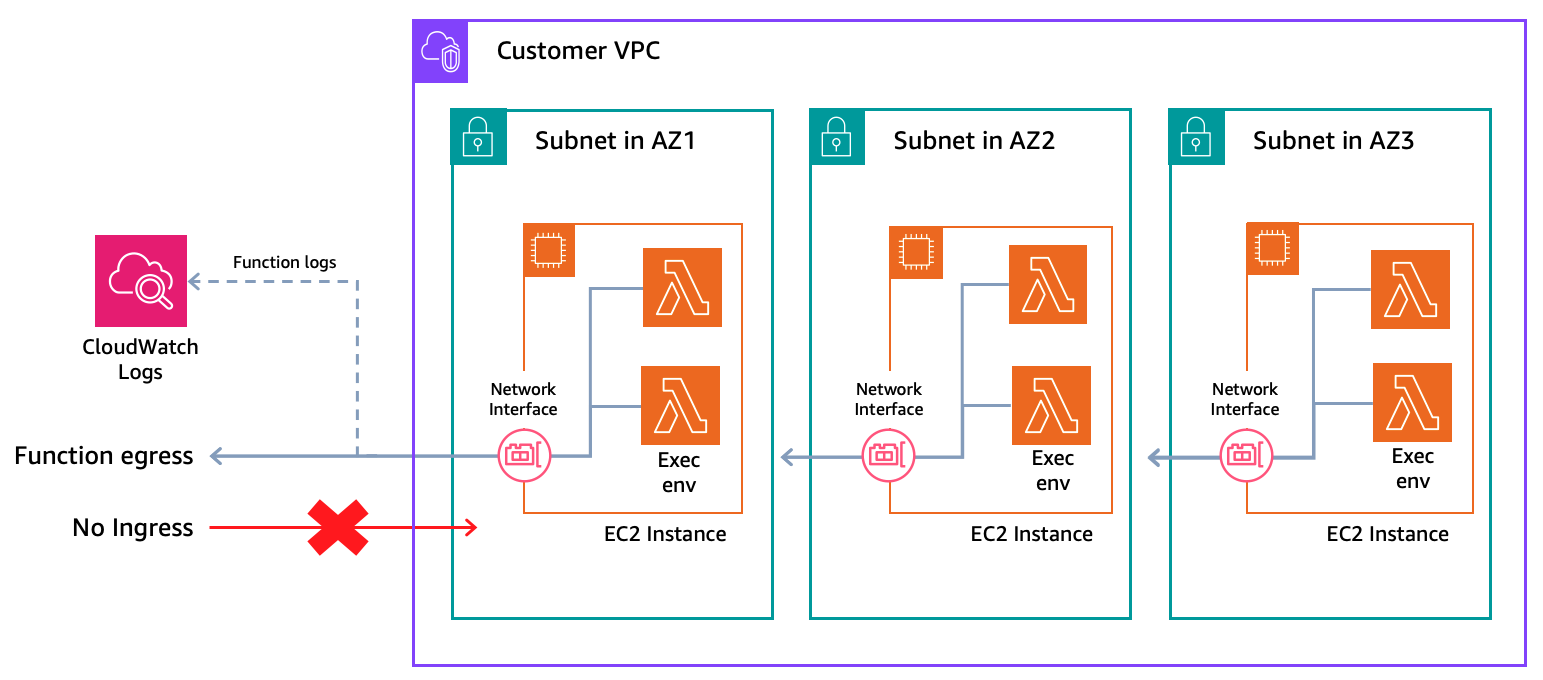
Figura 2. Rede LMI
Configuração de escalabilidade
Defina MaxVCpuCount para limitar a capacidade de computação e controlar custos. Quando esse limite é atingido, novas invocações são limitadas até que a capacidade seja liberada. O Lambda monitora a utilização de CPU e escala instâncias automaticamente. Escolha o modo de escalabilidade automática, em que o Lambda ajusta os limites com base nos padrões de carga, ou o modo manual, em que você define uma porcentagem-alvo de utilização de CPU. Várias funções podem compartilhar o mesmo Capacity Provider para reduzir custos com melhor utilização de recursos, embora provedores separados possam ser mais adequados para funções com requisitos diferentes de desempenho ou isolamento.
Segurança
O Lambda criptografa volumes do Amazon Elastic Block Store (Amazon EBS) anexados a instâncias EC2 com uma chave gerenciada pelo serviço por padrão. Você pode fornecer sua própria chave do AWS Key Management Service (AWS KMS) para criptografia. Coloque instâncias em sub-redes privadas com grupos de segurança restritivos para segurança aprimorada.
Criando Funções Lambda Managed Instance
Você cria uma função LMI de forma semelhante à criação de uma função Lambda padrão. Você empacota seu código, define seu runtime, atribui uma função de execução e configura a memória. A diferença está em especificar um CapacityProviderConfig para indicar ao Lambda qual Capacity Provider usar e como dimensionar cada ambiente de execução. Especifique o CapacityProviderConfig durante a criação da função com o ARN do Capacity Provider e defina dois parâmetros do ambiente de execução. ExecutionEnvironmentMemoryGiBPerVCpu define a proporção de memória para vCPU (2:1, 4:1 ou 8:1) com base no tipo de carga de trabalho e PerExecutionEnvironmentMaxConcurrency define quantas solicitações simultâneas podem compartilhar cada ambiente de execução. A tabela a seguir mostra como a alocação de memória e vCPU é distribuída nas proporções de ambiente de execução suportadas.
| Proporção 2:1 (Otimizada para computação) | Proporção 4:1 (Uso geral) | Proporção 8:1 (Otimizada para memória) | |||
| Memória (GB) | vCPU(s) | Memória (GB) | vCPU(s) | Memória (GB) | vCPU(s) |
| 2 | 1 | 4 | 1 | 8 | 1 |
| 4 | 2 | 8 | 2 | 16 | 2 |
| 6 | 3 | 12 | 3 | 24 | 3 |
| 8 | 4 | 16 | 4 | 32 | 4 |
| 10 | 5 | 20 | 5 | ||
| 12 | 6 | 24 | 6 | ||
| 14 | 7 | 28 | 7 | ||
| 16 | 8 | 32 | 8 | ||
| … | … | ||||
| 32 | 16 | ||||
Configuração de Memória-para-CPU da Função
Defina o tamanho da memória da função (até 32 GB para LMI) e a proporção ExecutionEnvironmentMemoryGiBPerVCpu. A proporção padrão é 2:1. Uma proporção 2:1 mapeia para instâncias otimizadas para computação para tarefas intensivas de CPU, como codificação de vídeo, 4:1 mapeia para uso geral para cargas de trabalho balanceadas e 8:1 mapeia para instâncias otimizadas para memória para grandes conjuntos de dados na memória ou cache. Você deve definir a memória em múltiplos da proporção. O LMI requer um mínimo de 2 GB, pois os ambientes de execução precisam de memória suficiente para lidar com várias solicitações simultâneas. O LMI suporta até 32 GB de memória por ambiente de execução.
Configurações de Multi-Concorrência
O LMI suporta múltiplas invocações simultâneas compartilhando o mesmo ambiente de execução, reduzindo o custo por invocação ao maximizar a utilização de vCPU. Isso é especialmente eficaz para cargas de trabalho vinculadas a I/O, em que invocações aguardando consultas de banco de dados ou chamadas de API cedem vCPU para outras invocações durante períodos ociosos. Por padrão, o Lambda define a concorrência máxima por ambiente de execução com base no runtime: Node.js (64 por vCPU), Java e .NET (32 por vCPU), Python (16 por vCPU). Use PerExecutionEnvironmentMaxConcurrency para definir um limite inferior com base nas necessidades de recursos da sua carga de trabalho. Reduza esse valor se houver pressão de memória ou contenção de CPU. Quando os ambientes atingem a concorrência máxima configurada, novas invocações são limitadas até que a capacidade seja liberada no nível do ambiente de execução. A tabela a seguir mostra a concorrência máxima por vCPU para cada linguagem de programação suportada.
| Linguagem | Concorrência Máxima Padrão |
| Node.js | 64 por vCPU |
| Java | 32 por vCPU |
| .NET | 32 por vCPU |
| Python | 16 por vCPU |
Este comando cria uma função Lambda e a associa ao seu Capacity Provider:
Publicando Funções Lambda Managed Instance
Importante: publique uma versão da função antes de invocá-la. A publicação faz com que o Lambda provisione instâncias Amazon EC2 e inicialize ambientes de execução, para que a capacidade base configurada esteja pronta antes de você começar a invocar. Aguarde um breve intervalo antes de o código entrar em operação, enquanto o Lambda provisiona e inicia instâncias Amazon EC2. Com o LMI, os ambientes de execução são pré-aquecidos após a publicação e permanecem prontos para invocação, sem cold starts para versões publicadas. Os ambientes Lambda padrão inicializam apenas na primeira invocação (cold starts).
Este comando publica uma versão da função Lambda e provisiona capacidade:
Após a publicação, a função opera com os métodos de invocação padrão, incluindo invocações diretas, mapeamentos de origem de eventos e integrações de serviço com Amazon API Gateway, Amazon Simple Storage Service (Amazon S3), Amazon DynamoDB Streams e Amazon EventBridge.
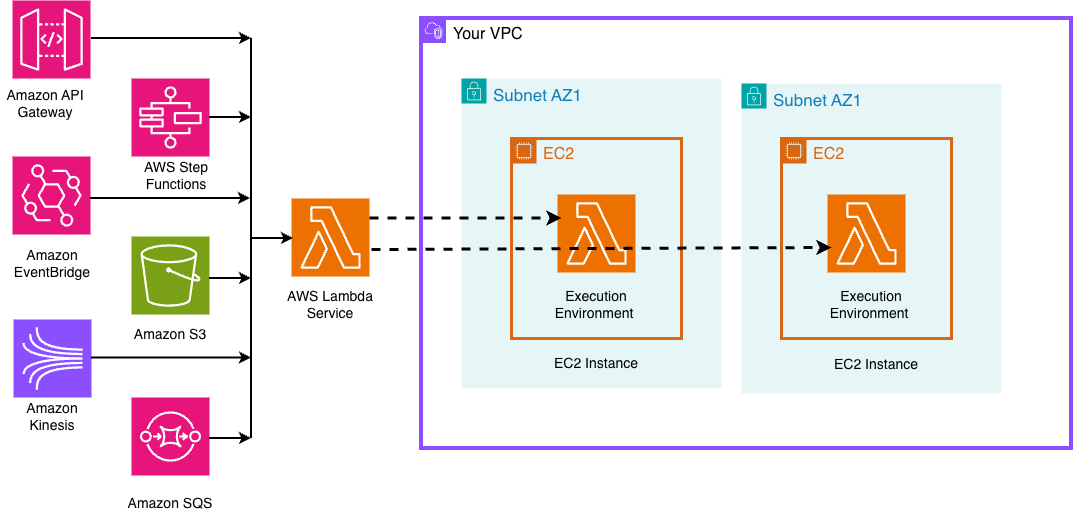
Figura 3. Invocação LMI de origens de eventos
Escalando Funções LMI
O Lambda monitora a utilização de CPU no nível do Capacity Provider. Quando a utilização de CPU atinge o limite-alvo, o Lambda provisiona instâncias EC2 adicionais automaticamente e cria mais ambientes de execução nessas instâncias, até o limite MaxVCpuCount que você configurou para seu capacity provider. Quando a demanda diminui, o Lambda consolida as cargas de trabalho em menos instâncias EC2. Você pode escolher o modo de escalabilidade automática (o Lambda ajusta os limites com base nos seus padrões) ou o modo manual (você define uma porcentagem-alvo de CPU). O modo automático funciona bem para padrões de tráfego variáveis ou quando você está começando. O modo manual é indicado quando você tem padrões previsíveis e quer controle preciso sobre os limites de escalabilidade para otimizar custos.
Ambientes de execução mínimos e máximos
Controle a escalabilidade no nível da função com ambientes de execução mínimos e máximos. O mínimo padrão é de 3 ambientes de execução para manter alta disponibilidade entre Zonas de Disponibilidade. A concorrência total da função é igual ao número de ambientes de execução multiplicado por PerExecutionEnvironmentMaxConcurrency. Por exemplo, com o mínimo definido como 3 e PerExecutionEnvironmentMaxConcurrency de 10, você terá capacidade para 30 invocações simultâneas. Com o máximo definido como 20, é possível escalar até 200 invocações simultâneas conforme o tráfego de entrada, com base na utilização de CPU ou saturação de concorrência por ambiente de execução. Defina o máximo para limitar a concorrência total e evitar problemas de noisy neighbor quando várias funções compartilham um Capacity Provider. O LMI mantém um número mínimo de ambientes de execução com uma frota mínima de Amazon EC2, enquanto o Lambda padrão escala até zero quando ocioso. Defina o mínimo e o máximo como 0 para desativar uma função sem excluí-la.
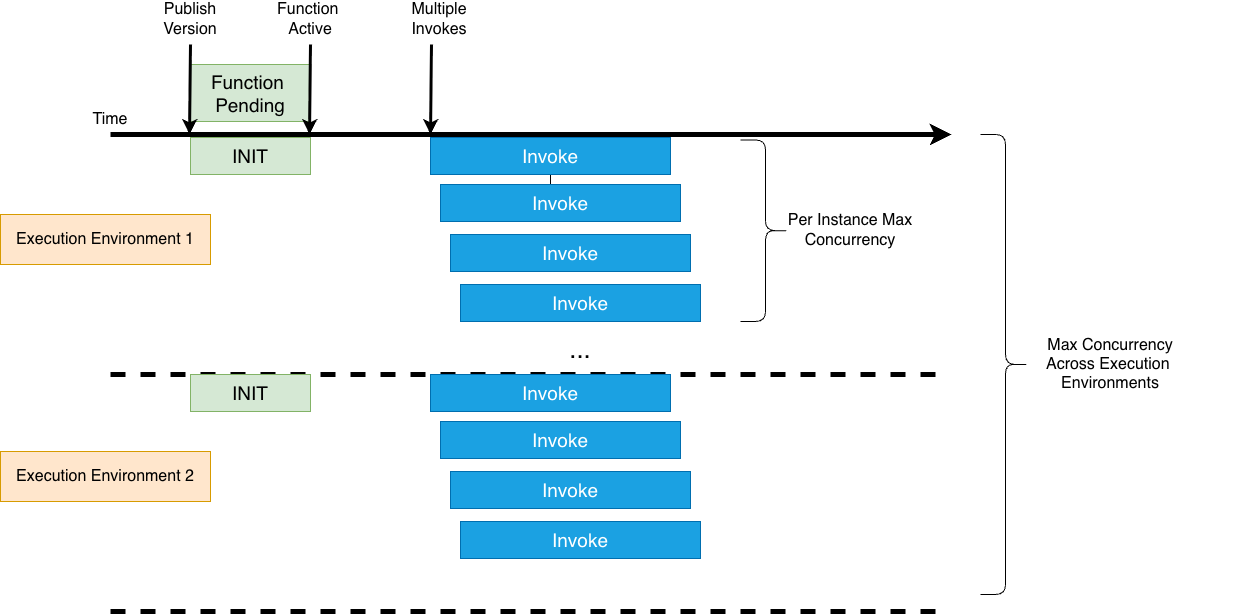
Figura 4. Escalabilidade LMI
Este comando atualiza os ambientes de execução mínimos e máximos para sua função:
Vamos abordar padrões de escalabilidade e estratégias de otimização de throughput com mais detalhes em uma publicação separada.
Práticas Recomendadas e Considerações de Produção
Segurança de Thread
Como o LMI suporta várias invocações compartilhando ambientes de execução, seu código precisa ser thread-safe. Código que não é thread-safe pode causar corrupção de dados, problemas de segurança ou comportamento imprevisível sob carga simultânea.
Fundamentos de segurança de thread
Evite alterar objetos compartilhados ou variáveis globais. Use armazenamento local de thread para dados específicos de solicitação. Inicialize clientes compartilhados (AWS SDK, conexões de banco de dados) fora do handler da função e garanta que as configurações permaneçam imutáveis entre invocações. Escreva em /tmp usando nomes de arquivo específicos por solicitação para evitar gravações simultâneas.
Orientação específica de runtime
Aplicações Java devem usar objetos imutáveis, coleções thread-safe e sincronização adequada. Aplicações Node.js devem usar contexto assíncrono para isolamento de solicitações. No Python, cada ambiente de execução roda em um processo separado. Por isso, concentre-se na coordenação entre processos e no bloqueio de arquivo para acesso a /tmp.
Otimização de Carga de Trabalho
Cargas de trabalho vinculadas a I/O apresentam melhor desempenho com maior concorrência por ambiente. Use padrões assíncronos e I/O não bloqueante para maximizar a eficiência. Cargas de trabalho vinculadas a CPU não se beneficiam de concorrência maior que uma por vCPU. Em vez disso, configure mais vCPUs por função para obter paralelismo real em tarefas pesadas de computação, como transformação de dados ou processamento de imagens.
Testes
Valide seu código em cenários de execução simultânea. Teste com várias invocações simultâneas para detectar race conditions e problemas de estado compartilhado antes de implantar em produção. Você pode usar o LocalStack para emulação local do LMI. Saiba mais sobre o suporte do LocalStack ao LMI na publicação de anúncio.
Compatibilidade
Ferramentas como Powertools para AWS funcionam com o LMI sem alterações de código. No entanto, se você estiver reutilizando código de função Lambda existente, layers ou dependências empacotadas no LMI, teste a segurança de thread e a compatibilidade com o modelo de execução multi-concorrente antes de implantar em produção.
Observabilidade
O LMI publica métricas do CloudWatch automaticamente em dois níveis: capacity provider (utilização de CPU, memória, rede e disco na frota Amazon EC2) e ambiente de execução (concorrência, CPU e memória por função). Monitore CPUUtilization para entender a margem de escalabilidade e dimensionar o MaxVCpuCount corretamente. Acompanhe ExecutionEnvironmentConcurrency em relação ao ExecutionEnvironmentConcurrencyLimit para detectar throttling antes que afete os usuários. O Lambda publica métricas a cada 5 minutos. Use alarmes do CloudWatch para se antecipar aos limites de capacidade em produção.
Conclusão
O AWS Lambda Managed Instances combina a simplicidade Serverless com a flexibilidade de computação, permitindo executar cargas de trabalho de alto desempenho com complexidade operacional reduzida. Você mantém o modelo de programação familiar do Lambda e, ao mesmo tempo, acessa os diversos tipos de instância do Amazon EC2 com preços previsíveis, o que o torna adequado para pipelines de processamento de dados, operações intensivas de computação e aplicações de estado estacionário sensíveis a custos.
Pronto para começar com o LMI? Implante nosso exemplo de simulação de risco Monte Carlo do GitHub para ver o LMI em ação com uma carga de trabalho real intensiva de computação. O exemplo inclui código de infraestrutura completo e orienta você pela configuração do capacity provider, configuração de função e otimização de desempenho.
Queremos ouvir sua opinião. Compartilhe feedback, perguntas e casos de uso no re:Post.
Este conteúdo foi traduzido da publicação original, que pode ser encontrada aqui.
Biografia do Autores
 |
Maria Debasis Rath é um Arquiteto de Soluções Sênior na Amazon Web Services. |
 |
Stephen Liedig é um Principal GTM SA Serverless na Amazon Web Services. |
Biografia do tradutores
 |
Daniel Abib é Arquiteto de Soluções Sênior e Especialista em Amazon Bedrock na AWS, com mais de 25 anos trabalhando com gerenciamento de projetos, arquiteturas de soluções escaláveis, desenvolvimento de sistemas e CI/CD, microsserviços, arquitetura Serverless & Containers e especialização em Machine Learning. Ele trabalha apoiando Startups, ajudando-os em sua jornada para a nuvem. |
 |
Rodrigo Peres é Arquiteto de Soluções na AWS, com mais de 20 anos de experiência trabalhando com arquitetura de soluções, desenvolvimento de sistemas e modernização de sistemas legados. |