O blog da AWS
Otimizando Cargas de Trabalho Serverless com Uso Intensivo de Computação com Rust Multi-threaded no AWS Lambda
Por Daniel Abib, arquiteto de soluções sênior na AWS.
Os clientes usam o AWS Lambda para criar aplicações Serverless para uma ampla variedade de casos de uso, desde backends de API simples até pipelines complexos de processamento de dados. A flexibilidade do Lambda o torna uma excelente escolha para muitas cargas de trabalho e, com suporte para até 10.240 MB de memória, agora você pode lidar com tarefas com uso intensivo de computação que anteriormente eram desafiadoras em um ambiente Serverless. Quando você configura o tamanho da memória de uma função Lambda, você aloca memória RAM e o Lambda fornece automaticamente poder de CPU proporcional. Quando você configura 10.240 MB de memória, sua função Lambda tem acesso a até 6 vCPUs.
No entanto, há uma consideração importante que muitos desenvolvedores descobrem: simplesmente alocar mais memória pode não tornar sua função automaticamente mais rápida. Se seu código é executado sequencialmente, ele usará apenas uma vCPU, independentemente de quantas estiverem disponíveis. As vCPUs restantes ficam ociosas enquanto você ainda está pagando pela alocação completa de memória.
Para ajudar a se beneficiar das capacidades multi-core do Lambda, seu código deve implementar explicitamente processamento concorrente por meio de multi-threading ou execução paralela. Sem isso, você está pagando por poder de computação que não está usando.
Rust fornece excelente suporte para esse padrão. O AWS Lambda Rust Runtime fornece aos desenvolvedores uma linguagem que combina desempenho excepcional com primitivas de concorrência integradas. Nesta publicação, mostramos como implementar multi-threading em Rust para alcançar melhorias de desempenho de 4 a 6x para cargas de trabalho com uso intensivo de CPU.
Nossa Carga de Trabalho de Teste: Por Que Hashing de Senha Bcrypt?
Para esta análise, usamos hashing de senha bcrypt como nossa carga de trabalho com uso intensivo de CPU para avaliar o comportamento de escalonamento multi-core. Esta escolha foi feita por várias razões:
- Relevância do mundo real: Bcrypt é comumente usado em sistemas de autenticação, tornando nossos benchmarks praticamente relevantes em vez de sintéticos.
- Trabalho de CPU previsível: Bcrypt com fator de custo 10 fornece aproximadamente 100ms de trabalho de CPU puro por operação em hardware típico, criando uma linha de base consistente e mensurável.
- Embarrassingly parallel: Cada operação de hash é completamente independente, tornando-a uma candidata ideal para processamento paralelo sem estado compartilhado ou contenção de bloqueio.
- Limitado por CPU: Bcrypt é determinístico e limitado por CPU (não por memória ou I/O), isolando as características de desempenho que queremos medir.
Ao longo desta publicação, processamos lotes de senhas e medimos como o multi-threading melhora o throughput à medida que escalamos de 1 a 6 vCPUs.
Entendendo a Alocação de vCPU do Lambda
O AWS Lambda aloca recursos de CPU proporcionalmente à memória configurada. De acordo com a documentação de memória de função do AWS Lambda, em 1.769 MB uma função tem o equivalente a uma vCPU.
|
Memória (MB) |
vCPUs Aproximadas |
| 128 – 1.769 | ~1 |
| 1.770 – 3.538 | ~2 |
| 3.539 – 5.307 | ~3 |
| 5.308 – 7.076 | ~4 |
| 7.077 – 8.845 | ~5 |
| 8.846 – 10.240 |
~6 |
Nota: O crate num_cpus retorna o número de CPUs lógicas visíveis para o ambiente Lambda, que pode diferir da parcela de vCPU alocada. Em configurações de memória mais baixas, você pode ver 2 CPUs relatadas mesmo que apenas 1 vCPU de tempo de computação seja alocada.
Visão Geral da Solução
A solução consiste em uma função Lambda em Rust que:
- Recebe uma solicitação especificando o número de itens a processar
- Detecta vCPUs disponíveis e configura um pool de threads de acordo
- Processa itens em paralelo usando a biblioteca Rayon (uma biblioteca de paralelismo de dados que permite converter iteradores sequenciais em paralelos com uma chamada
.par_iter()) - Retorna métricas de desempenho incluindo duração e throughput
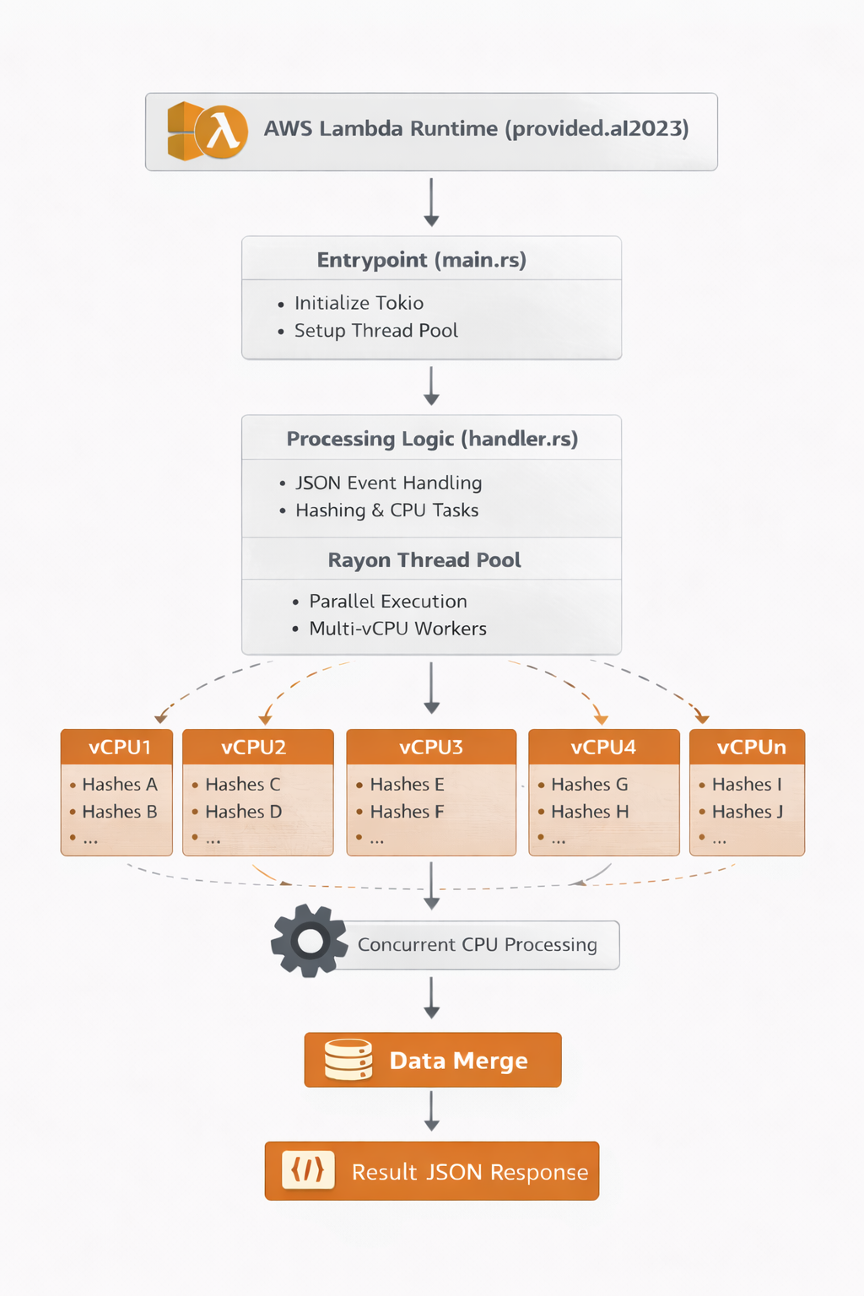
Diagrama de Arquitetura: Lambda recebe solicitação, inicializa pool de threads Rayon baseado na variável de ambiente WORKER_COUNT, processa hashes bcrypt em paralelo através de múltiplas vCPUs e retorna resultados.
Criando uma Função Lambda Rust Multi-threaded
Crie um novo projeto Lambda usando Cargo Lambda:
cargo lambda new rust-multithread-demo
cd rust-multithread-demoDependências
Atualize Cargo.toml com as dependências necessárias:
[package]
name = "rust-multithread-lambda"
version = "0.1.0"
edition = "2021"
[dependencies]
lambda_runtime = "1.0.0"
tokio = { version = "1", features = ["macros", "rt-multi-thread"] }
serde = { version = "1.0", features = ["derive"] }
serde_json = "1.0"
bcrypt = "0.15"
rayon = "1.7"
num_cpus = "1.16"
[profile.release]
opt-level = 3
lto = true
codegen-units = 1
strip = trueAs flags de otimização em [profile.release] reduzem o tamanho do binário e melhoram o desempenho:
opt-level = 3: Otimização máximalto = true: Otimização em tempo de link para binários menoresstrip = true: Remove símbolos de depuração
Implementando o Ponto de Entrada do Lambda
Primeiro, vamos ver como inicializamos o pool de threads durante o cold start:
src/main.rs:
use lambda_runtime::{run, service_fn, Error, LambdaEvent};
mod handler;
use handler::{function_handler, get_worker_count, init_thread_pool, ProcessRequest};
#[tokio::main]
async fn main() -> Result<(), Error> {
// Initialize Rayon thread pool at cold start (once per container lifecycle)
init_thread_pool(get_worker_count());
run(service_fn(|event: LambdaEvent<ProcessRequest>| async move {
function_handler(event.payload).await
}))
.await
}Por que inicializar em main() e não no handler?
- Configuração Determinística: O pool de threads é configurado uma vez por contêiner, antes de qualquer solicitação chegar. Isso evita condições de corrida se múltiplas solicitações tentarem inicializar simultaneamente.
- Reutilização de Contêiner: Contêineres Lambda podem atender múltiplas solicitações. Inicializar em
main()garante que a configuração seja definida durante o cold start e persista para todas as invocações warm subsequentes. - Desempenho: A configuração do pool de threads acontece durante o cold start (já contado como tempo de inicialização), não durante o processamento da solicitação.
Implementando o Handler de Solicitação
src/handler.rs:
use serde::{Deserialize, Serialize};
use std::env;
use std::sync::Once;
use std::time::Instant;
use std::collections::HashSet;
use std::sync::Mutex;
use rayon::prelude::*;
static INIT: Once = Once::new();
#[derive(Deserialize)]
pub struct ProcessRequest {
count: usize,
mode: String,
}
#[derive(Serialize)]
pub struct ProcessResponse {
processed: usize,
duration_ms: u128,
mode: String,
workers: usize,
detected_cpus: usize,
avg_ms_per_item: f64,
memory_used_kb: u64,
threads_used: usize, // Actual threads that processed items (proves multi-threading)
}
// CPU-intensive bcrypt hashing with cost factor 10
fn hash_password(password: &str) -> Result<String, bcrypt::BcryptError> {
bcrypt::hash(password, 10)
}
// Process items one at a time (baseline for comparison)
fn process_sequential(items: Vec<String>) -> Result<(Vec<String>, usize), Box<dyn std::error::Error + Send + Sync>> {
let results: Result<Vec<String>, _> = items
.iter()
.map(|item| hash_password(item))
.collect();
results
.map(|r| (r, 1))
.map_err(|e| Box::new(e) as Box<dyn std::error::Error + Send + Sync>)
}
// Process items in parallel using Rayon's work-stealing scheduler
// Thread pool size is configured once at cold start via init_thread_pool()
fn process_parallel(items: Vec<String>) -> Result<(Vec<String>, usize), Box<dyn std::error::Error + Send + Sync>> {
let thread_ids: Mutex<HashSet<std::thread::ThreadId>> = Mutex::new(HashSet::new());
let results: Result<Vec<String>, _> = items
.par_iter()
.map(|item| {
thread_ids.lock().unwrap().insert(std::thread::current().id());
hash_password(item)
})
.collect();
let threads_used = thread_ids.lock().unwrap().len();
results
.map(|r| (r, threads_used))
.map_err(|e| Box::new(e) as Box<dyn std::error::Error + Send + Sync>)
}
// Get worker count from env var or detect CPUs, clamped to 1-6
pub fn get_worker_count() -> usize {
if let Ok(count_str) = env::var("WORKER_COUNT") {
if let Ok(count) = count_str.parse::<usize>() {
return count.clamp(1, 6);
}
}
num_cpus::get().clamp(1, 6)
}
// Initialize Rayon global thread pool (only once per Lambda container)
pub fn init_thread_pool(workers: usize) {
INIT.call_once(|| {
let _ = rayon::ThreadPoolBuilder::new()
.num_threads(workers)
.build_global();
});
}
// Read RSS memory from /proc/self/statm (Linux only)
fn get_memory_usage_kb() -> u64 {
std::fs::read_to_string("/proc/self/statm")
.ok()
.and_then(|s| s.split_whitespace().nth(1)?.parse::<u64>().ok())
.map(|pages| pages * 4)
.unwrap_or(0)
}
// Main Lambda handler - processes items sequentially or in parallel
pub async fn function_handler(request: ProcessRequest) -> Result<ProcessResponse, Box<dyn std::error::Error + Send + Sync>> {
if request.count == 0 { return Err("count must be greater than 0".into()); }
if request.count > 1000 { return Err("count exceeds maximum of 1000 items".into()); }
let items: Vec<String> = (0..request.count)
.map(|i| format!("password_{:06}", i))
.collect();
let workers = get_worker_count();
let mode = match request.mode.as_str() {
"sequential" => "sequential",
"parallel" => "parallel",
_ => if workers > 1 { "parallel" } else { "sequential" },
};
let start = Instant::now();
let (results, threads_used) = match mode {
"sequential" => process_sequential(items)?,
_ => process_parallel(items)?,
};
let duration_ms = start.elapsed().as_millis();
Ok(ProcessResponse {
processed: results.len(),
duration_ms,
mode: mode.to_string(),
workers: if mode == "parallel" { workers } else { 1 },
detected_cpus: num_cpus::get(),
avg_ms_per_item: duration_ms as f64 / request.count as f64,
memory_used_kb: get_memory_usage_kb(),
threads_used,
})
}Detalhes Chave da Implementação
Inicialização do Pool de Threads no Cold Start: O código inicializa o pool de threads em main() antes do runtime do Lambda iniciar, não durante o processamento da solicitação. Esta abordagem é projetada para eliminar condições de corrida e fornecer comportamento determinístico em todas as invocações.
Nota Importante: Lambda inicializa o pool de threads uma vez por container. A configuração do pool de threads mantém seu valor original mesmo se você alterar a variável de ambiente WORKER_COUNT entre invocações dentro do mesmo container. Para implantações de produção, mantenha WORKER_COUNT consistente durante o ciclo de vida da função.
Validação de Entrada: O handler valida que count está entre 1 e 1000 para evitar esgotamento de recursos.
Rastreamento de Threads: O campo threads_used prova que o multi-threading está funcionando rastreando IDs de thread únicos durante o processamento paralelo. Isso fornece validação empírica de que o trabalho é distribuído através de múltiplas threads.
Rastreamento de Memória: O campo memory_used_kb relata o uso de memória RSS lendo /proc/self/statm, fornecendo visibilidade sobre o consumo real de memória.
Seleção de Modo: A função suporta três modos:
sequential: Processamento single-threadedparallel: Processamento multi-threaded usando Rayonauto: Seleciona automaticamente com base nos workers disponíveis
Compilando e Implantando
Com a implementação completa, vamos compilar a função para o ambiente do Lambda e implantá-la na AWS.
# Build for ARM64 (Graviton2) - recommended for cost efficiency
cargo lambda build --release --arm64
# Or build for x86_64
cargo lambda build --release --x86-64O processo de compilação produz um binário de aproximadamente 1,7 MB (descompactado) ou 0,8 MB (zipado).
Implantando na AWS
Use Cargo Lambda para implantar a função com sua configuração de memória desejada e contagem de workers.
# Deploy with 6144 MB memory (4 vCPUs) and 4 workers
cargo lambda deploy rust-multithread-lambda \
--memory 6144 \
--timeout 30 \
--env-var WORKER_COUNT=4Nota: Para testar diferentes configurações, repita os comandos de build e deploy com diferentes valores de --memory e configurações de WORKER_COUNT para cada configuração que você deseja fazer benchmark. Para testes abrangentes entre arquiteturas, construa com --arm64, implante todas as configurações de memória, depois reconstrua com --x86-64 e implante novamente.
Permissões IAM Necessárias
A role de execução do Lambda precisa das seguintes permissões:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"logs:CreateLogGroup",
"logs:CreateLogStream",
"logs:PutLogEvents"
],
"Resource": "arn:aws:logs:*:*:*"
}
]
}Testando a Função
Após a implantação, verifique se a função está funcionando corretamente invocando-a com um payload de teste.
aws lambda invoke \
--function-name rust-multithread-lambda \
--payload '{"count":20,"mode":"parallel"}' \
--cli-binary-format raw-in-base64-out \
response.jsonBenchmarks de Desempenho
Testamos múltiplas configurações em ARM64 (Graviton2) para medir o impacto do multi-threading.
Carga de trabalho de teste: Processamento de 20 hashes de senha bcrypt (fator de custo 10)
Nota: Os resultados de benchmark podem variar entre execuções devido a fatores como posicionamento do Lambda, diferenças de hardware subjacente e condições de infraestrutura da AWS. Os números apresentados aqui são representativos do desempenho típico observado em múltiplas execuções de teste.
Resultados de Desempenho: ARM64 (Graviton2)
| Memória | vCPUs | Workers | Média (ms) | P50 (ms) | P95 (ms) | P99 (ms) | Mín | Máx | Aceleração |
| 1536 MB | ~1 | 1 | 1.885 | 1.882 | 1.898 | 1.898 | 1.877 | 1.907 | 1,00x |
| 2048 MB | ~2 | 2 | 1.334 | 1.331 | 1.341 | 1.341 | 1.324 | 1.356 | 1,41x |
| 4096 MB | ~3 | 3 | 685 | 683 | 699 | 699 | 669 | 704 | 2,75x |
| 6144 MB | ~4 | 4 | 463 | 464 | 467 | 467 | 453 | 469 | 4,07x |
| 8192 MB | ~5 | 5 | 338 | 343 | 345 | 345 | 325 | 346 | 5,57x |
| 10240 MB | ~6 | 6 | 280 | 278 | 292 | 292 | 271 | 293 | 6,73x |
Resultados de Desempenho: x86_64
| Memória | vCPUs | Workers | Média (ms) | P50 (ms) | P95 (ms) | P99 (ms) | Mín | Máx | Aceleração |
| 1536 MB | ~1 | 1 | 1.671 | 1.675 | 1.681 | 1.681 | 1.659 | 1.684 | 1,00x |
| 2048 MB | ~2 | 2 | 1.253 | 1.249 | 1.265 | 1.265 | 1.241 | 1.294 | 1,33x |
| 4096 MB | ~3 | 3 | 892 | 891 | 899 | 899 | 888 | 900 | 1,87x |
| 6144 MB | ~4 | 4 | 429 | 425 | 443 | 443 | 417 | 449 | 3,89x |
| 8192 MB | ~5 | 5 | 330 | 323 | 349 | 349 | 317 | 358 | 5,06x |
| 10240 MB | ~6 | 6 | 292 | 292 | 298 | 298 | 291 | 298 | 5,72x |
Comparação de Arquitetura
| Memória | Workers | Média ARM64 | Média x86_64 | Dif % | Arq Mais Rápida |
| 1536 MB | 1 | 1.885 ms | 1.671 ms | -12,8% | x86_64 |
| 2048 MB | 2 | 1.334 ms | 1.253 ms | -6,4% | x86_64 |
| 4096 MB | 3 | 685 ms | 892 ms | +23,2% | ARM64 |
| 6144 MB | 4 | 463 ms | 429 ms | -7,9% | x86_64 |
| 8192 MB | 5 | 338 ms | 330 ms | -2,4% | x86_64 |
| 10240 MB | 6 | 280 ms | 292 ms | +4,1% | ARM64 |
Observações Importante
Desempenho de Cold Start: Os tempos de inicialização de cold start do Rust são consistentemente entre 19-28 ms em todas as configurações de memória e arquiteturas. ARM64 (Graviton2) mostra cold starts ligeiramente mais rápidos (19-23 ms) comparado ao x86_64 (26-29 ms). Ambos são significativamente mais rápidos que runtimes interpretados porque o binário é pré-compilado.
Escalonamento Quase Linear: Ambas as arquiteturas alcançam acelerações impressionantes:
- ARM64: Aceleração de 6,73x com 6 workers (excede o teórico 6x!)
- x86_64: Aceleração de 5,72x com 6 workers
Consistência de Latência: As métricas P95 e P99 mostram excelente consistência:
- ARM64 em 6 vCPUs: P50=278ms, P95=292ms, P99=292ms (baixa variância)
- x86_64 em 6 vCPUs: P50=292ms, P95=298ms, P99=298ms
Ambas as arquiteturas mostram latência consistente na paralelização máxima.
Análise de Custo
Vamos analisar as implicações de custo de diferentes configurações para processar 20 hashes bcrypt.
Comparação de Custo: ARM64 vs x86_64 (us-east-1, a partir de janeiro de 2026):
| Config | Memória | Workers | Duração ARM64 | Custo ARM64/1M | Duração x86_64 | Custo x86_64/1M | Arq Mais Barata |
| 1 vCPU | 1536 MB | 1 | 1.885 ms | $38,60 | 1.671 ms | $42,78 | ARM64 |
| 2 vCPU | 2048 MB | 2 | 1.334 ms | $36,46 | 1.253 ms | $42,77 | ARM64 * |
| 3 vCPU | 4096 MB | 3 | 685 ms | $37,47 | 892 ms | $60,80 | ARM64 |
| 4 vCPU | 6144 MB | 4 | 463 ms | $37,97 | 429 ms | $44,00 | ARM64 |
| 5 vCPU | 8192 MB | 5 | 338 ms | $36,94 | 330 ms | $45,10 | ARM64 |
| 6 vCPU | 10240 MB | 6 | 280 ms | $38,27 | 292 ms | $49,87 | ARM64 |
*Arq Mais Barata
Fórmulas de Custo:
- ARM64: (Memória em GB) × (Duração em segundos) × $0,0000133334
- x86_64: (Memória em GB) × (Duração em segundos) × $0,0000166667 (taxa 25% maior)
Ponto-chave: A configuração ARM64 de 2 vCPU fornece o menor custo em $36,46 por milhão de invocações enquanto alcança aceleração de 1,41x. Todas as configurações ARM64 permanecem competitivas em custo (faixa de $36-$39) apesar de diferenças significativas de desempenho, demonstrando como o aumento de throughput pode compensar custos de memória mais altos.
Escolhendo a Configuração Certa:
| Prioridade | Config Recomendada | Justificativa |
| Menor Custo | ARM64, 2048 MB, 2 workers | $36,46/1M invocações, aceleração de 1,41x |
| Balanceado | ARM64, 4096 MB, 3 workers | $37,47/1M invocações, aceleração de 2,75x |
| Baixa Latência | ARM64, 10240 MB, 6 workers | 280ms média, aceleração de 6,73x |
Quando Usar Rust Multi-threaded no Lambda
Casos de Uso Recomendados
- Processamento de dados em lote: Transformar, validar ou enriquecer grandes conjuntos de dados
- Operações criptográficas: Hashing, criptografia, assinaturas digitais
- Processamento de imagem/vídeo: Redimensionar, transcodificar, analisar arquivos de mídia
- Computação científica: Simulações, análise de dados, inferência de machine learning
- Cargas de trabalho de alto volume: Funções invocadas >100.000 vezes por dia se beneficiam da otimização
Quando Considerar Alternativas
- Operações limitadas por I/O: Use Rust assíncrono em vez de multi-threading para consultas de banco de dados ou chamadas de API
- Transformações simples: Funções completando em <100ms raramente se beneficiam de paralelização
- Cargas de trabalho de baixo volume: O esforço de desenvolvimento pode não ser justificado para <10.000 invocações por dia
- Prototipagem rápida: Python ou Node.js podem ser mais apropriados quando a velocidade de iteração é crítica
Limpeza
Para excluir os recursos criados nesta publicação:
# Delete the Lambda function
aws lambda delete-function --function-name rust-multithread-lambda
# Delete the CloudWatch log group
aws logs delete-log-group --log-group-name /aws/lambda/rust-multithread-lambdaNota: Se você implantou múltiplas configurações para teste, você precisará excluir cada função individualmente repetindo o comando delete com cada nome de função, ou usar o template SAM para limpeza em massa:
aws cloudformation delete-stack --stack-name rust-multithread-benchmarkConclusão
Quando você aloca mais memória para sua função Lambda, a AWS fornece proporcionalmente mais vCPUs—até 6 vCPUs em 10.240 MB. No entanto, código sequencial usa apenas uma vCPU, deixando o poder de computação adicional ocioso enquanto você paga pela alocação completa. Rust multi-threaded com Rayon permite que você aproveite todas as vCPUs disponíveis para cargas de trabalho com uso intensivo de CPU, transformando capacidade não utilizada em ganhos reais de desempenho.
Nossos benchmarks demonstram isso claramente:
- Escalonamento quase linear: ARM64 alcançou aceleração de 6,73x com 6 workers—você obtém retornos proporcionais no seu investimento em vCPU
- Cold starts rápidos: 19-28 ms de inicialização em todas as configurações, eliminando as preocupações de cold start frequentemente associadas a linguagens compiladas
- Latência consistente: ARM64 em 6 vCPUs mostra apenas 1ms de variância entre P50 e P99, crítico para tempos de resposta previsíveis
- Eficiência de custo: ARM64 é 15-20% mais barato que x86_64 com melhor escalonamento na paralelização máxima
A principal conclusão: Se sua função Lambda executa trabalho com uso intensivo de CPU e você está alocando mais de 1.769 MB de memória, você provavelmente tem múltiplas vCPUs disponíveis. Sem multi-threading, essas vCPUs ficam ociosas. Os iteradores paralelos do Rayon permitem que você mude de processamento sequencial para paralelo alterando .iter() para .par_iter() no seu código.
Configuração inicial recomendada: ARM64 com 4096 MB (3 workers) oferece um excelente equilíbrio de custo e desempenho para a maioria das cargas de trabalho. Escale para 6 vCPUs para aplicações críticas de latência, ou para 2 vCPUs para máxima economia de custo.
Recursos Adicionais
- AWS Lambda Rust Runtime
- Documentação do Cargo Lambda
- Biblioteca de Paralelismo de Dados Rayon
- Configuração de Memória e CPU do AWS Lambda
- Preços do AWS Lambda
O código de exemplo completo, template SAM e scripts de teste desta publicação estão disponíveis no Repositório Github.
Este conteúdo foi traduzido do post original do blog, que pode ser encontrado aqui.
Autor
 |
Daniel Abib é arquiteto de soluções sênior na AWS, com mais de 25 anos trabalhando com gerenciamento de projetos, arquiteturas de soluções escaláveis, desenvolvimento de sistemas e CI/CD, microsserviços, arquitetura Serverless & Containers e segurança. Ele trabalha apoiando clientes corporativos, ajudando-os em sua jornada para a nuvem. https://www.linkedin.com/in/danielabib/ |
Tradutor
 |
Rodrigo Peres é Arquiteto de Soluções na AWS, com mais de 20 anos de experiência trabalhando com arquitetura de soluções, desenvolvimento de sistemas e modernização de sistemas legados. |