O blog da AWS
Will bank aumenta em 37% a satisfação de clientes e reduz em 26% o trabalho humano com o Amazon Bedrock
Por Aruã de Mello Sousa, Cientista de Dados, will bank; Isabella Cunha, Product Manager, will bank; Janaina Vallim de Melo, Designer Conversacional, will bank; Thiago de Oliveira Tuler, Desenvolvedor, will bank; Felipe Olivieri, Arquiteto de soluções na AWS e Marcelo Moras, Arquiteto de soluções na AWS.
Quem é will bank?
O Will bank é um banco digital que tem como missão atender a população brasileira com difícil acesso a serviços financeiros tradicionais ou com problemas recorrentes. Com quase 12 milhões de clientes, sendo a maioria residente na região Nordeste e em cidades pequenas, o will objetiva simplificar as finanças por meio de produtos flexíveis para seu público. E em 40% de sua base de clientes, o will foi o primeiro cartão solicitado.
Oportunidade
Antes, o atendimento a clientes no will era iniciado por um robô que usava abordagens clássicas de processamento de linguagem natural, fazia uma classificação da intenção e direcionava o atendimento para robôs especialistas com fluxos conversacionais baseado em árvore de decisão e botões de decisão. No entanto, tal solução trazia limitações como:
- Interações inflexíveis: a rigidez na interpretação de intenções exigia que a pessoa se expressasse de maneira muito específica e havia falhas na compreensão de variações da linguagem, o que resultava em conversas pouco naturais, com baixa personalização.
- Navegação engessada e sem contexto: a estrutura de árvore de decisão e a transição entre robôs ditavam um caminho unilateral de respostas estáticas. A ausência de contexto dificultava a mudança de assunto e tratativa de problemas correlatos.
- Alta complexidade de manutenção e baixa escalabilidade: adicionar novos casos de uso, ajustar fluxos ou otimizar classificadores demandava um esforço manual e repetitivo, tornando o sistema caro e lento para escalar.
Esses obstáculos resultavam na deterioração da experiência do usuário e na percepção dos clientes sobre a não resolução no atendimento. Foi nesse contexto que emergiu o desafio: usar a inteligência artificial generativa para se conectar, de forma autêntica e empática, com o público do will. O objetivo estratégico era ir além da tecnologia, personalizando a comunicação para compreender e se adaptar a diversos modos de fala de clientes.
Isso se traduziu na ideia de criar jornadas simples e resolutivas, onde a IA poderia atuar como um assistente inteligente que oferecesse uma experiência fluida e de alta qualidade, reservando a intervenção humana para casos mais complexos e, assim, escalar o atendimento sem perder a conexão e o propósito de inclusão financeira do will bank.
Solução
Arquitetura
Como início da solução, desenvolvemos uma nova arquitetura que conecta o chat do aplicativo diretamente ao nosso backend, visando superar as limitações anteriores. Essa arquitetura foi composta por componentes essenciais para suportar um sistema multiagentes robusto.
Destacamos o Gateway, que atua como uma chave para facilitar o gerenciamento e o acesso de clientes aos recursos ofertados. O ponto central é a API, responsável por prover todos os recursos e a lógica necessária para o funcionamento do sistema multiagentes, além do banco de dados utilizado para a persistência do histórico das conversas e da base de conhecimento do sistema. Nessa arquitetura, abstraímos a complexidade do funcionamento do chat no app e das APIs que fornecem dados de clientes. Elas são representadas pelo Gateway e por uma API GraphQL, respectivamente, em nosso diagrama.
A representação visual dessa arquitetura e seus componentes é apresentada abaixo:
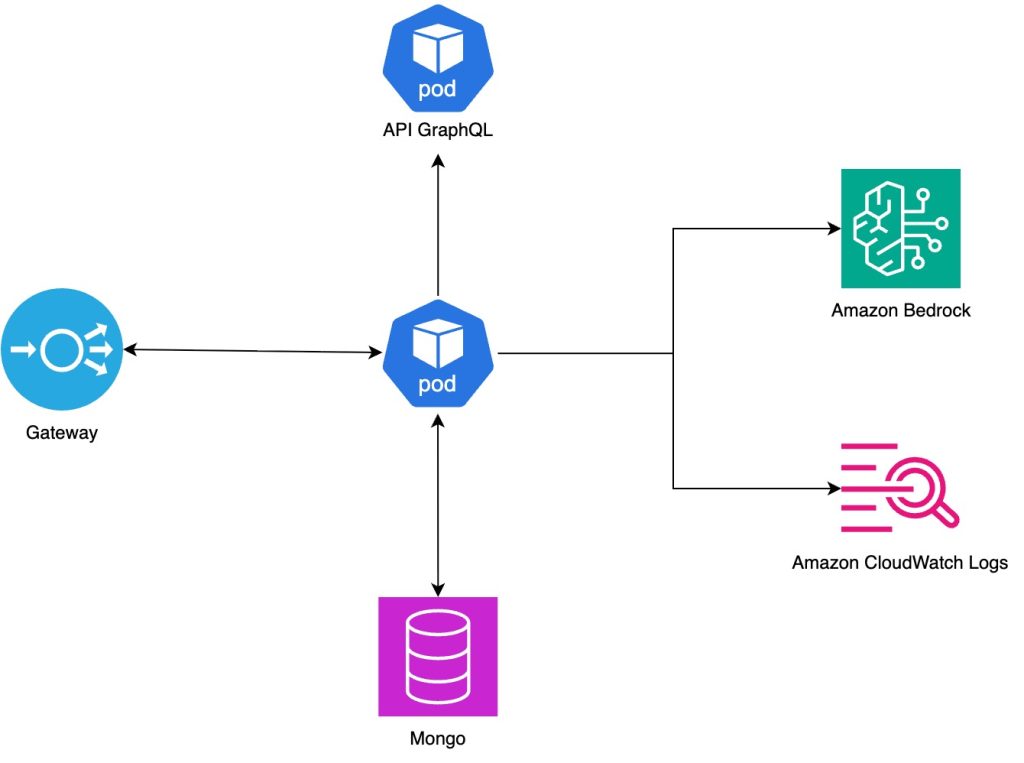
Para detalhar os componentes dessa arquitetura, começamos pelo ponto de entrada, o Gateway. Ele foi desenvolvido usando o Kong com a função de receber as requisições e direcioná-las para a nossa aplicação.
Já na nossa aplicação multiagentes, utiliza uma API construída em Python 3.12, que roda no ambiente escalável do Amazon Elastic Kubernetes Service (EKS), desenvolvido pelo time do will, o que nos permite processar as requisições com segurança e alta disponibilidade.
Outro pilar fundamental da arquitetura multiagente é a comunicação com nossas APIs internas. Para isso, desenvolvemos uma aplicação que suporta o protocolo GraphQL. Dessa forma, sempre que um agente de LLM (Large Language Model) precisa de informações específicas do cliente, ele faz uso de uma “tool” para executar uma query e recuperar tais informações.
Para a persistência de dados, optamos por uma implementação não relacional usando um banco de dados Mongo Atlas, que também está hospedado na AWS usando o Amazon EKS. Essa tecnologia foi escolhida por sua flexibilidade de esquema, ideal para uma fase inicial de prototipação onde as estruturas de dados podem evoluir rapidamente.
Por fim, em relação ao provedor de LLMs e Guardrails, utilizamos o Amazon Bedrock. Tal escolha nos trouxe a vantagem de ter acesso a uma série de modelos de fundação de ponta, além de nos beneficiarmos da segurança e da integração nativa com o restante do nosso ambiente AWS.
Estrutura Multiagentes
A solução multiagentes que escolhemos trouxe vantagens em aspectos cruciais na abordagem das dores de clientes, como:
- Memória e continuidade do atendimento: permite que, iterativamente, clientes e robôs construam uma conversa para solucionar o problema.
- Fluidez na conversa: também há um resultado expressivo da capacidade de memória. O robô tem habilidade para identificar o momento de transferir para um atendimento humano, manter a conversa, devolver para o sistema classificador etc., tornando a conversa muito mais natural por meio do recurso de agenciamento.
- Ferramentas: é notável a capacidade de acessar bases de conhecimento e informações relacionadas em tempo real no contexto da conversa.
Estrutura do grafo de agentes
- Agente principal e comunicação com especialistas:
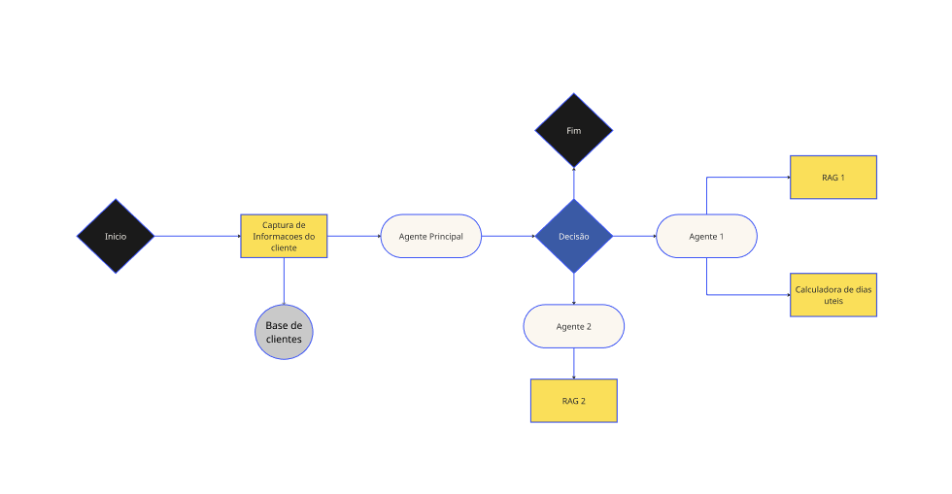
- Agente especialista:
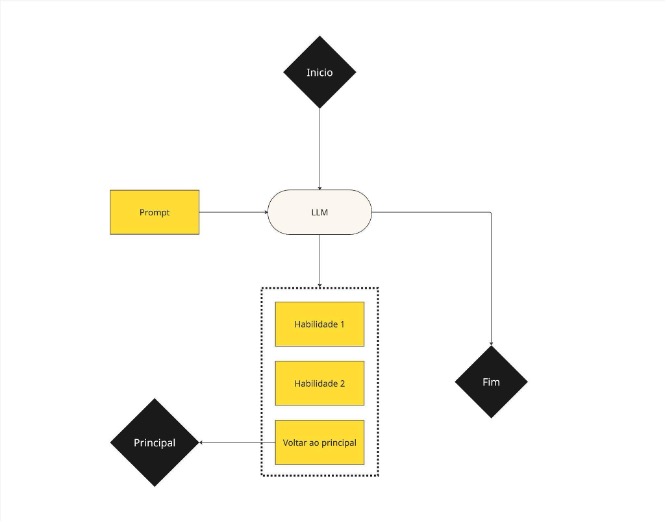
Utilizamos uma arquitetura multiagentes de supervisor e especialistas. Nesse modelo, a pessoa cliente interage somente com o supervisor, que direciona as perguntas para ser formulada pelos agentes especialistas em cada um dos assuntos tratados pelo robô.
Cada agente tem acesso a diferentes ferramentas necessárias para desempenhar sua função, seja o acesso a informações atualizadas, a uma base de conhecimento com regras de negócio específicas ou até mesmo uma simples calculadora de dias úteis. O próprio agente determina em que momento deve utilizar cada uma das ferramentas, e inclui os resultados habilmente em sua resposta.
Jornada
No âmbito do design conversacional, vale destacar a fase de descoberta, de construção do prompt de sistema, bases de conhecimento e cenários de teste. Esta fase foi importante para entender as dores de clientes por jornada. A base de conhecimento, que é o repertório de informações que o robô usa para elaborar as respostas, foi organizada em “pedaços” de conteúdo, no sistema de perguntas e respostas (QA), para otimizar a busca em textos diretos e autoexplicativos. O prompt de sistema atuou como um guia para o comportamento do robô, e os cenários de teste foram utilizados para validar e aprimorar o comportamento do robô.
O grande desafio era adequar o comportamento da LLM para assegurar que as respostas fossem coerentes, úteis e previsíveis. Tal criação exigiu um processo exaustivo de refinamentos para aderência do modelo aos limites de atuação, por meio de um sistema de avaliação de três níveis. O “Nível 1″ teve foco em testes controlados, automatizados e estáticos, usando user inputs reais e recorrentes para testar diversas combinações de prompts, temperatura, top P e versões do modelo. A partir desses testes, elegemos a melhor combinação de parâmetros para o desenvolvimento dos agentes.
Um segundo desafio surgiu com a necessidade de testar a continuidade da conversa em cenários mais complexos, uma vez que o LLM poderia apresentar comportamentos indesejados de reformulação de respostas durante um diálogo completo com clientes. Para mitigar esse problema, o time avançou para as avaliações de “Nível 2”, que consistiram em testes humanos com cenários pré-definidos em ambiente de homologação. Esses cenários de teste simulavam 7 diferentes problemas recorrentes por jornada, o que permitiu identificar falhas para iterar prompts e bases de conhecimento. A experiência de depuração em homologação se tornou um recurso valioso para aprimorar a qualidade das respostas.
Também tivemos que lidar com as diferenças de comportamento do modelo em ambiente de produção. A análise amostral de conversas revelou que o robô poderia se comportar de forma diferente em um cenário real, o que exigiu ajustes finos e mais iterações. Para enfrentar isso, fizemos os testes de “Nível 3”, realizados em produção, que se evidenciaram como uma etapa crucial do ciclo de vida de validações.
Por fim, a gestão das expectativas foi um ponto central: o time aprendeu que não se deve buscar 100% de acerto nas respostas, mas sim calibrar o robô para alcançar a qualidade e resultados desejados, aceitando trade-offs deliberados. A reutilização da infraestrutura de avaliação para depuração e a criação de métricas específicas foram aprendizados essenciais para a evolução inteligente do robô.
A experiência www
A adoção da IA generativa no design conversacional trouxe ganhos expressivos para a experiência dos usuários, que chamamos internamente de “experiência www”. Com a capacidade de compreender variações de linguagem e adaptar respostas, o robô passou a oferecer interações mais naturais e contextualizadas.
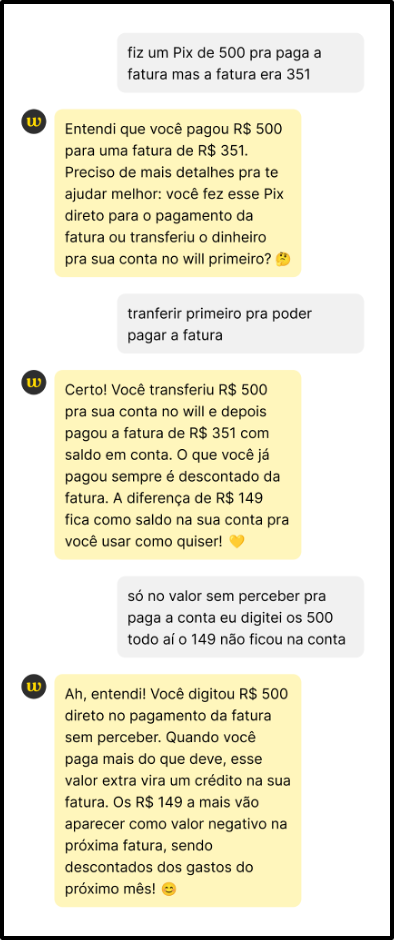
Após a aplicação da IA generativa, foi notável a competência do robô em manter o ritmo do diálogo, respondendo com coerência, precisão e em consonância com os movimentos da conversa. Isso ampliou a sensação de que o atendente virtual estaria, de fato, entendendo e endereçando o problema, conforme notado nos diálogos a seguir.
 |
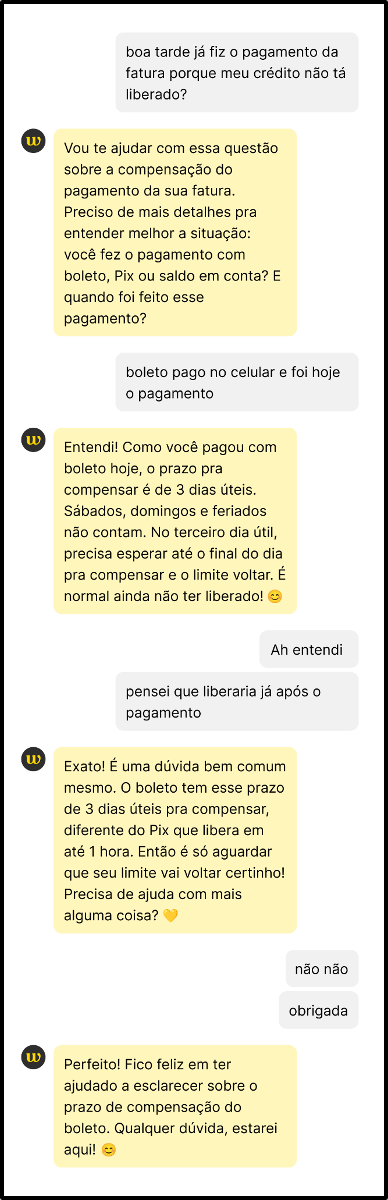 |
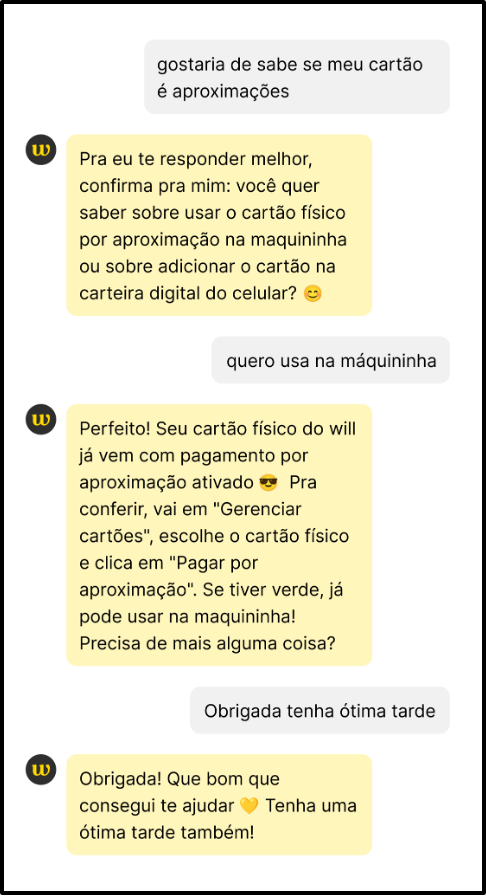 |
Resultados
Como resultado, o robô elevou a qualidade das tratativas e diminuiu a necessidade de transferências para agentes humanos. No total, a resolutividade do robô multiagentes foi 26% maior em relação ao robô tradicional híbrido, baseado em NLP e árvore de decisão. Falando especificamente de novos agentes construídos apenas com essa nova arquitetura, o incremento chega a ser de 72% em relação aos modelos tradicionais, o que significa uma capacidade de atender uma base maior de clientes reduzindo o custo de atendimento.
Além disso, o robô com o Amazon Bedrock trouxe um ganho significativo na avaliação de clientes. Notamos, nas pesquisas, um aumento de 37% na satisfação com essa nova solução. A experiência tornou-se mais resolutiva, personalizada e alinhada com o propósito de inclusão e autonomia no uso dos serviços financeiros do will bank.
Como próximos passos, queremos explorar outras arquiteturas de agentes, com diferentes LLMs para cada especialista, dependendo do nível de complexidade necessária para a jornada e especificidade de respostas.
Agradecemos a Débora Furieri, Heider Berlink, Marcone Bhering, Lucas Carvalho e Luiz Faccioli pela colaboração durante este trabalho.
Autores
 |
Felipe Olivieri é Arquiteto de Soluções na AWS, possuindo mais de 20 anos de experiência. Felipe atuou em centenas de projetos de infraestrutura de TI em sua carreira e agora utiliza esse aprendizado para apoiar clientes AWS em suas jornadas de migração para a nuvem. |
 |
Marcelo Moras é Arquiteto de Soluções na AWS atendendo clientes Enterprise com foco em mercado financeiro. Com mais de 18 anos de experiência atuando com infraestrutura, administração de sistemas, redes, containers e segurança. |
 |
Aruã de Mello é Cientista de Dados no will bank. Mestre em ciência da computação pela Universidade Federal de São Paulo com foco em Machine Learning, atua com o desenvolvimento e a implementação de chatbots multi-agent utilizando GenAI para revolucionar a interação com clientes. https://www.linkedin.com/in/aruasousa
|
 |
Isabella Cunha é Product Manager no will bank. Especialista na construção de produtos de IA, chatbots, NLP e GenAI, conduz times multidisciplinares transformando dados em soluções. Com visão estratégica sobre clientes e ciclo de vida de produtos, busca sempre entregar alto impacto para o negócio. https://www.linkedin.com/in/isabella-almeida-cunha-ferreira/ |
 |
Janaina Vallim é Designer Conversacional no will bank. Graduou-se em Comunicação pela Unesp e atualmente é pesquisadora de Agentes de IA no IEA da USP. Já trabalhou como UX Writer de chatbots baseados em NLP e hoje atua em projetos de chatbots com GenAI, com foco em engenharia de prompts. |
 |
Thiago Tuler é Software Engineer no will bank. Mestre em Informática pela Universidade Federal do Espírito Santo, com especialização em Sistemas de Informação e Processamento de Linguagem Natural, ele se dedica a atuar como arquiteto de sistemas de atendimento ao cliente com foco em Inteligência Artificial. |
Revisores
 |
Luis Miguel é Arquiteto de Soluções na AWS, com mais de 12 anos de experiência em tecnologia. Atualmente, atua apoiando clientes corporativos na região Sul do Brasil em suas jornadas modernização e jornada para nuvem, projetando soluções escaláveis e resilientes. Sua expertise abrange desde arquiteturas tradicionais até soluções cloud-native. |
 |
Neuton Assis é Arquiteto de Soluções na AWS para o segmento de Enterprise. Antes disso, trabalhou por mais de 10 anos na arquitetura e desenvolvimento de softwares voltados para automação de atividades de TI, auditoria de sistemas e gestão de identidade e acesso, atuando principalmente em ambientes Microsoft. Atualmente, tem se especializado em Agentic AI e auxilia clientes da AWS a terem sucesso na jornada para computação em nuvem. |