- Amazon Redshift
- Features
- Integration for Apache Spark
Amazon Redshift Integration for Apache Spark
Build Apache Spark applications that read and write data from Amazon Redshift
Why Amazon Redshift Integration for Apache Spark?
Benefits of Amazon Redshift
-
Expand the breadth of data sources that you can use in your rich analytics and machine learning (ML) applications running in Amazon EMR, AWS Glue, or SageMaker by reading from and writing data to your data warehouse.
-
Streamline the cumbersome and often manual process of setting up uncertified connectors and JDBC drivers, reducing the preparation time for analytics and ML tasks.
-
Use several pushdown capabilities such as sort, aggregate, limit, join, and scalar functions so that only relevant data is moved from the Amazon Redshift data warehouse.
How it works
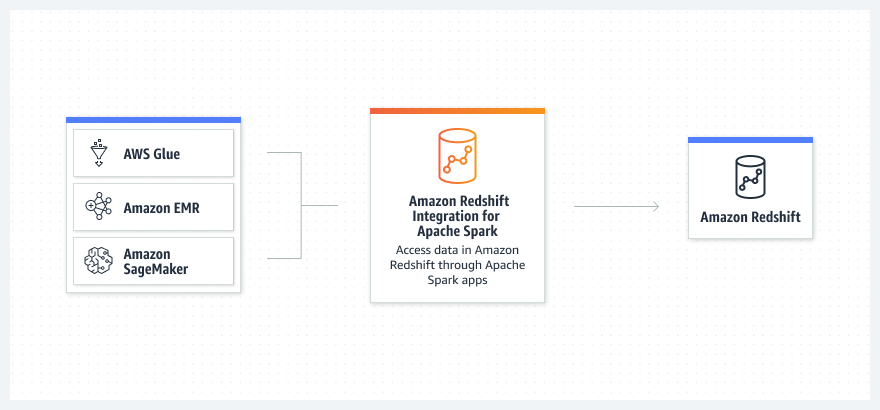
Use cases
-
Create Apache Spark applications in Java, Scala, and Python with Apache Spark–based AWS analytics services.
-
Read and write data to and from Amazon Redshift with Amazon EMR, AWS Glue, SageMaker, and AWS analytics and ML services.
-
Use Amazon EMR or AWS Glue to take data frame code from your Apache Spark job or notebook and connect to Amazon Redshift.
-
Streamline your process with no installation or testing, enhanced security (IAM-based credentials) and operational pushdowns, and Parquet file format for performance.
Customers
Corey Johnson, Data Architect Manager - Huron Consulting
Huron is a global professional services firm that collaborates with clients to put possible into practice by creating sound strategies, optimizing operations, accelerating digital transformation, and empowering businesses and their people to own their future.
"We empower our engineers to build their data pipelines and applications with Apache Spark using Python and Scala. We wanted a tailored solution that simplified operations and delivered faster and more efficiently for our clients and that’s what we get with the new Amazon Redshift Integration for Apache Spark."
Alcuin Weidus, Sr Principal Data Architect - GE Aerospace
GE Aerospace is a global provider of jet engines, components, and systems for commercial and military aircraft. The company has been designing, developing, and manufacturing jet engines since World War I.
“GE Aerospace uses AWS analytics and Amazon Redshift to enable critical business insights that drive important business decisions. With the support for auto-copy from Amazon S3, we can build simpler data pipelines to move data from Amazon S3 to Amazon Redshift. This accelerates our data product teams’ ability to access data and deliver insights to end users. We spend more time adding value through data and less time on integrations.”
Neema Raphael, Chief Data Officer - Goldman Sachs
The Goldman Sachs Group, Inc. is a leading global financial institution that delivers a broad range of financial services across investment banking, securities, investment management and consumer banking to a large and diversified client base that includes corporations, financial institutions, governments, and individuals.
"Our focus is on providing self-service access to data for all of our users at Goldman Sachs. Through Legend, our open source data management and governance platform, we enable users to develop data-centric applications and derive data-driven insights as we collaborate across the financial services industry. With Amazon Redshift integration for Apache Spark, our data platform team will be able to access Amazon Redshift data with minimal manual steps—allowing for zero-code ETL that will increase our ability to make it easier for engineers to focus on perfecting their workflow as they collect complete and timely information. We expect to see a performance improvement of applications and improved security as our users can now easily access the latest data in Amazon Redshift.”
Did you find what you were looking for today?
Let us know so we can improve the quality of the content on our pages