Инстансы Amazon EC2 Trn2 и UltraServers
Высокоэффективные вычислительные решения EC2 для обучения генеративного искусственного интеллекта и получения выводов
Почему инстансы Amazon EC2 Trn2 и UltraServers?
Инстансы Amazon EC2 Trn2 на базе 16 чипов AWS Trainium2 специально созданы для генеративного искусственного интеллекта и являются самыми мощными инстансами EC2 для обучения и развертывания моделей с параметрами от сотен миллиардов до триллионов. Инстансы Trn2 дают на 30-40 % лучшее соотношение цены и эффективности по сравнению с инстансами EC2 P5e и P5en на базе графического процессора. С помощью инстансов Trn2 вы можете получить самую современную производительность обучения и логических выводов при одновременном снижении затрат, а также сократить время обучения, ускорить итерации и предоставлять возможности на базе искусственного интеллекта в режиме реального времени. Инстансы Trn2 можно использовать для обучения и развертывания моделей, включая большие языковые модели (LLM), мультимодальные модели и диффузионные трансформеры, для создания приложений генеративного искусственного интеллекта нового поколения.
Чтобы сократить время обучения и обеспечить рекордное время отклика (задержка на каждый токен) для самых требовательных и современных моделей, вам может потребоваться больше вычислительных ресурсов и памяти, чем может предоставить один инстанс. Инстансы Trn2 UltraServers используют NeuronLink, наше запатентованное межчиповое соединение, для подключения 64 чипов Trainium2 к четырем инстансам Trn2, что в четыре раза увеличивает пропускную способность вычислительных ресурсов, памяти и сети на одном узле и обеспечивает максимальную производительность AWS для задач глубокого обучения и генеративного искусственного интеллекта. Для задач получения логических выводов инстансы UltraServers обеспечивают ведущее в отрасли время отклика и создание наилучших условий работы в режиме реального времени. Для задач обучения инстансы UltraServers повышают скорость и эффективность обучения модели благодаря более быстрой коллективной коммуникации для обеспечения параллелизма моделей по сравнению с отдельными инстансами.
Вы можете легко начать работу с инстансами Trn2 и Trn2 UltraServers благодаря встроенной поддержке популярных платформ машинного обучения, таких как PyTorch и JAX.
«Trn2 UltraServers теперь доступны для самых требовательных рабочих нагрузок генеративного искусственного интеллекта».
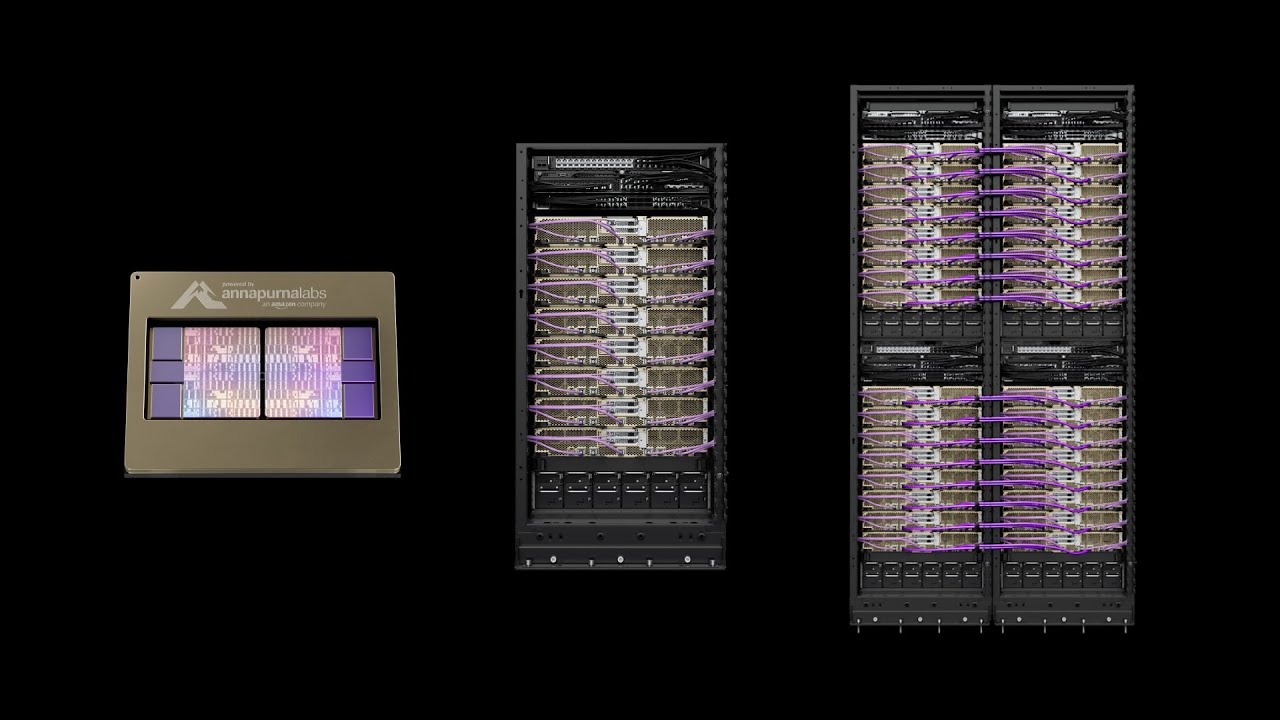
Преимущества
Инстансы Trn2 помогают сократить время обучения и предоставить конечным пользователям возможность получения логических выводов в реальном времени. Инстансы Trn2 оснащены 16 микросхемами Trainium2, соединенными с NeuronLink, нашим запатентованным межчиповым соединением, что обеспечивает вычислительную мощность до 20,8 петафлопс в режиме FP8. Инстансы Trn2 имеют общую емкость 1,5 ТБ HBM3 с пропускной способностью 46 терабайт в секунду (Тбит/с) и 3,2 терабита в секунду (Тбит/с) по сети Elastic Fabric Adapter (EFAv3). Серверы Trn2 UltraServers (доступны в предварительной версии) имеют 64 микросхемы Trainium2, подключенные к NeuronLink, и обеспечивают до 83,2 петафлопс вычислительных ресурсов FP8, 6 ТБ общей памяти с высокой пропускной способностью, 185 Тбит/с общей пропускной способности памяти и 12,8 Тбит/с по сети EFAv3.
Чтобы обеспечить эффективное распределенное обучение, инстансы Trn2 обеспечивают пропускную способность сети EFAv3 3,2 Тбит/с, а серверы Trn2 UltraServers – 12,8 Тбит/с. EFA построен на основе AWS Nitro System, поэтому все передаваемые через EFA данные шифруются без снижения производительности. EFA также использует сложный протокол маршрутизации трафика и контроля перегрузки, который позволяет надежно масштабироваться до сотен тысяч чипов Trainium2. Инстансы Trn2 и серверы UltraServers развертываются в EC2 UltraClusters, чтобы обеспечить масштабируемое распределенное обучение на десятках тысяч чипов Trainium в одной петабитной неблокирующей сети.
Инстансы Trn2 дают на 30-40 % лучшее соотношение цены и эффективности по сравнению с инстансами EC2 P5e и P5en на базе графического процессора.
Энергоэффективность инстансов Trn2 в 3 раза выше, чем у Trn1. Эти инстансы и их базовые чипы используют передовые кремниевые технологии, а также аппаратные и программные оптимизации, которые позволяют добиться высокой энергоэффективности при масштабном выполнении задач генеративного ИИ.
SDK AWS Neuron помогает получить максимальную производительность от инстансов Trn2 и UltraServers. Neuron изначально интегрируется с JAX, PyTorch и такими важными библиотеками, как Hugging Face, PyTorch Lightning и т. д. Neuron создан для исследователей искусственного интеллекта, чтобы обеспечить ранее невиданную производительность. Благодаря полной интеграции с PyTorch вы можете обучать и развертывать модели, не изменяя в них ни единой строки кода. Инженерам по производительности ИИ предоставляется более глубокий доступ к Trainium2, чтобы они могли дополнительно настраивать ядра и производительность для еще лучшей работы моделей. Благодаря Neuron можно применять инстансы Trn2 с такими сервисами, как Amazon SageMaker, Amazon EKS, Amazon ECS, AWS ParallelCluster и AWS Batch, а также со сторонними сервисами, такими как Ray (Anyscale), Domino Data Lab и Datadog. Поскольку инновации процветают благодаря открытости, Neuron стремится внедрять их с помощью открытого исходного кода и сотрудничества с широким сообществом ИИ.
Возможности
Инстансы Trn2 оснащены 16 чипами Trainium2, соединенными с NeuronLink и обеспечивающими вычислительную мощность до 20,8 петафлопс FP8. Trn2 UltraServers расширяют возможности подключения NeuronLink к 64 чипам Trainium2 на четырех инстансах Trn2, обеспечивая вычислительную мощность до 83,2 петафлопс FP8.
Инстансы Trn2 предоставляют 1,5 ТБ ускорительной памяти с общей пропускной способностью 46 Тбит/с. Trn2 UltraServers предлагают 6 ТБ общей ускорительной памяти с общей пропускной способностью 185 Тбит/с для поддержки сверхбольших базовых моделей.
Для поддержки масштабируемого распределенного обучения сверхбольших базовых моделей инстансы Trn2 обеспечивают пропускную способность сети EFAv3 3,2 Тбит/с, а серверы Trn2 UltraServers – 12,8 Тбит/с. В сочетании с EC2 UltraClusters EFAv3 обеспечивает меньшую сетевую задержку по сравнению с EFAv3. Каждый экземпляр Trn2 поддерживает до 8 ТБ, а каждый Trn2 UltraServer поддерживает до 32 ТБ локального хранилища NVMe для более быстрого доступа к большим наборам данных.
Инстансы Trn2 и серверы UltraServer поддерживают типы данных FP32, TF32, BF16, FP16 и настраиваемые типы данных FP8 (cFP8). Они также поддерживают передовые оптимизации ИИ, включая 4-кратную разреженность (16:4), стохастическое округление и специальные коллективные движки. Нейронный интерфейс Kernel (NKI) обеспечивает прямой доступ к архитектуре набора команд (ISA) с использованием среды на основе Python с интерфейсом, подобным Triton, что позволяет внедрять инновационные архитектуры моделей и высокооптимизированные вычислительные ядра, превосходящие существующие технологии.
Сервис Neuron совместим с более чем 100 000 моделями из Центра моделей Hugging Face, поддерживая их обучение и развертывание на Trn2, включая популярные архитектуры, такие как Llama и Stable Diffusion. Neuron изначально интегрируется с JAX, PyTorch и основными инструментами, фреймворками и библиотеками, такими как NeMo, Hugging Face, PyTorch Lightning, Ray, Domino Data Lab и Data Dog. Сервис оптимизирует готовые модели для распределенного обучения и вывода, а также предоставляет глубокие аналитические данные для профилирования и отладки. Neuron также интегрируется с такими сервисами, как Amazon SageMaker, Amazon EKS, Amazon ECS, AWS ParallelCluster и AWS Batch.
Отзывы клиентов и партнеров
Здесь представлено несколько примеров того, как клиенты и партнеры планируют достичь своих бизнес-целей с помощью инстансов Amazon EC2 Trn2.
Anthropic
 «В Anthropic миллионы людей ежедневно полагаются на Claude в своей работе. Мы объявляем о двух важных достижениях AWS. Во-первых, о новом «режиме с оптимизацией задержек» для Claude 3.5 Haiku, который работает на Trainium2 на 60 % быстрее с помощью Amazon Bedrock. А во-вторых, о Project Rainier – новом кластере с сотнями тысяч чипов Trainium2, обеспечивающем производительность в сотни экзафлопс, что более чем в пять раз превышает масштаб нашего предыдущего кластера. Project Rainier будет способствовать как нашим исследованиям, так и масштабированию технологий нового поколения. Для клиентов это означает более высокий уровень искусственного интеллекта, снижение затрат и увеличение скорости работы. Мы создаем не просто более быстрый искусственный интеллект, а надежный и масштабируемый». – Том Браун, директор по вычислительным технологиям компании Anthropic
«В Anthropic миллионы людей ежедневно полагаются на Claude в своей работе. Мы объявляем о двух важных достижениях AWS. Во-первых, о новом «режиме с оптимизацией задержек» для Claude 3.5 Haiku, который работает на Trainium2 на 60 % быстрее с помощью Amazon Bedrock. А во-вторых, о Project Rainier – новом кластере с сотнями тысяч чипов Trainium2, обеспечивающем производительность в сотни экзафлопс, что более чем в пять раз превышает масштаб нашего предыдущего кластера. Project Rainier будет способствовать как нашим исследованиям, так и масштабированию технологий нового поколения. Для клиентов это означает более высокий уровень искусственного интеллекта, снижение затрат и увеличение скорости работы. Мы создаем не просто более быстрый искусственный интеллект, а надежный и масштабируемый». – Том Браун, директор по вычислительным технологиям компании Anthropic
Databricks
 «Mosaic AI от Databricks предоставляет организациям мощный инструмент для создания и развертывания высококачественных систем агентов. Благодаря интеграции с корпоративными хранилищами данных, Mosaic AI позволяет легко и безопасно адаптировать модели к специфике бизнеса, обеспечивая более точные результаты. Высокая производительность и экономичность Trainium дают клиентам возможность масштабировать обучение моделей на платформе Mosaic AI с минимальными затратами. С выходом Trainium2 Databricks получит значительное преимущество, поскольку растущий спрос на Mosaic AI наблюдается среди клиентов по всему миру и во всех отраслях. Как одна из крупнейших компаний в области обработки данных и ИИ, Databricks планирует использовать TRN2 для повышения эффективности своих решений и снижения совокупной стоимости владения для клиентов до 30 %». –Навин Рао, вице-президент по технологиям искусственного интеллекта компании Databricks
«Mosaic AI от Databricks предоставляет организациям мощный инструмент для создания и развертывания высококачественных систем агентов. Благодаря интеграции с корпоративными хранилищами данных, Mosaic AI позволяет легко и безопасно адаптировать модели к специфике бизнеса, обеспечивая более точные результаты. Высокая производительность и экономичность Trainium дают клиентам возможность масштабировать обучение моделей на платформе Mosaic AI с минимальными затратами. С выходом Trainium2 Databricks получит значительное преимущество, поскольку растущий спрос на Mosaic AI наблюдается среди клиентов по всему миру и во всех отраслях. Как одна из крупнейших компаний в области обработки данных и ИИ, Databricks планирует использовать TRN2 для повышения эффективности своих решений и снижения совокупной стоимости владения для клиентов до 30 %». –Навин Рао, вице-президент по технологиям искусственного интеллекта компании Databricks
poolside
 «Компания poolside намерена построить мир, в котором искусственный интеллект станет движущей силой большинства экономически ценных работ и научного прогресса. Мы уверены, что разработка программного обеспечения станет первой масштабной областью, в которой нейронные сети смогут достичь уровня человеческого интеллекта. Именно здесь мы можем наиболее эффективно объединить методы обучения и поиска. Для этого мы разрабатываем базовые модели, API и ассистента, которые позволят вашим разработчикам (или даже обычной клавиатуре) использовать потенциал генеративного ИИ. Основой для внедрения этой технологии является наша инфраструктура, обеспечивающая создание и запуск продуктов. Используя AWS Trainium2, наши клиенты смогут значительно масштабировать свои приложения с оптимальным соотношением цены и производительности, превосходя другие ускорители на основе ИИ. В дополнение к этому мы планируем обучать будущие модели на Trainium2 UltraServers, что позволит достичь экономии до 40 % по сравнению с инстансами EC2 P5». – Эйсо Кант, технический директор и соучредитель компании poolside
«Компания poolside намерена построить мир, в котором искусственный интеллект станет движущей силой большинства экономически ценных работ и научного прогресса. Мы уверены, что разработка программного обеспечения станет первой масштабной областью, в которой нейронные сети смогут достичь уровня человеческого интеллекта. Именно здесь мы можем наиболее эффективно объединить методы обучения и поиска. Для этого мы разрабатываем базовые модели, API и ассистента, которые позволят вашим разработчикам (или даже обычной клавиатуре) использовать потенциал генеративного ИИ. Основой для внедрения этой технологии является наша инфраструктура, обеспечивающая создание и запуск продуктов. Используя AWS Trainium2, наши клиенты смогут значительно масштабировать свои приложения с оптимальным соотношением цены и производительности, превосходя другие ускорители на основе ИИ. В дополнение к этому мы планируем обучать будущие модели на Trainium2 UltraServers, что позволит достичь экономии до 40 % по сравнению с инстансами EC2 P5». – Эйсо Кант, технический директор и соучредитель компании poolside
Itaú Unibanco
 «Цель Itaú Unibanco – улучшить отношение людей к деньгам, оказать положительное влияние на их жизни и расширить возможности для преобразований. В Itaú Unibanco мы уверены, что каждый клиент уникален, поэтому мы фокусируемся на удовлетворении их индивидуальных потребностей. Используя интуитивно понятные цифровые технологии, основанные на ИИ, мы обеспечиваем постоянную адаптацию наших решений к меняющимся потребительским привычкам. Мы протестировали AWS Trainium и Inferentia для решения различных задач, начиная от стандартных логических выводов и заканчивая тщательно настроенными приложениями. Производительность этих чипов ИИ позволила нам достичь значительных результатов в наших исследованиях и разработках. Как для пакетных задач, так и для задач интерактивного вывода мы наблюдали 7-кратное увеличение пропускной способности по сравнению с графическими процессорами. Такое повышение производительности приводит к увеличению числа сценариев использования в организации. Последнее поколение чипов Trainium2 открывает ранее невиданные возможности для генеративного искусственного интеллекта и открывает двери для инноваций в Itau». – Витор Асека, руководитель отдела анализа данных компании Itaú Unibanco
«Цель Itaú Unibanco – улучшить отношение людей к деньгам, оказать положительное влияние на их жизни и расширить возможности для преобразований. В Itaú Unibanco мы уверены, что каждый клиент уникален, поэтому мы фокусируемся на удовлетворении их индивидуальных потребностей. Используя интуитивно понятные цифровые технологии, основанные на ИИ, мы обеспечиваем постоянную адаптацию наших решений к меняющимся потребительским привычкам. Мы протестировали AWS Trainium и Inferentia для решения различных задач, начиная от стандартных логических выводов и заканчивая тщательно настроенными приложениями. Производительность этих чипов ИИ позволила нам достичь значительных результатов в наших исследованиях и разработках. Как для пакетных задач, так и для задач интерактивного вывода мы наблюдали 7-кратное увеличение пропускной способности по сравнению с графическими процессорами. Такое повышение производительности приводит к увеличению числа сценариев использования в организации. Последнее поколение чипов Trainium2 открывает ранее невиданные возможности для генеративного искусственного интеллекта и открывает двери для инноваций в Itau». – Витор Асека, руководитель отдела анализа данных компании Itaú Unibanco
NinjaTech AI
 «Ninja – это универсальный агент ИИ, предлагающий неограниченную продуктивность: одна подписка дает доступ к передовым мировым моделям ИИ, а также лучшим навыкам, включая написание текстов, программирование, генерацию идей, создание изображений и проведение онлайн-исследований. Как агентская платформа, Ninja предлагает сервис «SuperAgent», который использует смесь агентов с точностью мирового уровня, сравнимой с моделями Frontier Foundation, а в некоторых областях даже превосходящей их. Для реализации технологий Ninja Agentic требуются ускорители высочайшей производительности, чтобы обеспечивать нашим клиентам уникальный опыт работы в реальном времени, соответствующий их высоким ожиданиям. Мы рады запуску AWS TRN2, который, как мы уверены, обеспечит лучшую производительность на токен и максимальную скорость для нашей базовой модели Ninja LLM, построенной на основе Llama 3.1 405B. Особенно впечатляют низкая задержка Trn2, конкурентоспособные цены и удобная доступность по запросу. Это открывает новые возможности для Ninja». –Бабак Пахлаван, основатель и генеральный директор компании NinjaTech AI
«Ninja – это универсальный агент ИИ, предлагающий неограниченную продуктивность: одна подписка дает доступ к передовым мировым моделям ИИ, а также лучшим навыкам, включая написание текстов, программирование, генерацию идей, создание изображений и проведение онлайн-исследований. Как агентская платформа, Ninja предлагает сервис «SuperAgent», который использует смесь агентов с точностью мирового уровня, сравнимой с моделями Frontier Foundation, а в некоторых областях даже превосходящей их. Для реализации технологий Ninja Agentic требуются ускорители высочайшей производительности, чтобы обеспечивать нашим клиентам уникальный опыт работы в реальном времени, соответствующий их высоким ожиданиям. Мы рады запуску AWS TRN2, который, как мы уверены, обеспечит лучшую производительность на токен и максимальную скорость для нашей базовой модели Ninja LLM, построенной на основе Llama 3.1 405B. Особенно впечатляют низкая задержка Trn2, конкурентоспособные цены и удобная доступность по запросу. Это открывает новые возможности для Ninja». –Бабак Пахлаван, основатель и генеральный директор компании NinjaTech AI
Ricoh
 «Команда специалистов RICOH по машинному обучению разрабатывает решения для рабочих мест и услуги по цифровой трансформации, направленные на управление и оптимизацию потока информации в рамках наших корпоративных решений. Переход на инстансы Trn1 оказался простым и понятным. Мы смогли предварительно обучить нашу модель LLM с параметром 13B всего за 8 дней, используя кластер из 4096 чипов Trainium. После успеха, достигнутого при использовании нашей компактной модели, мы усовершенствовали новый, более крупный LLM на базе Llama-3-Swallow-70B и, используя Trainium, смогли сократить затраты на обучение на 50 % и повысить энергоэффективность на 25 % по сравнению с использованием новейших графических процессоров в AWS. Мы рады использовать чипы AWS Trainium2 последнего поколения на базе искусственного интеллекта, чтобы и дальше обеспечивать нашим клиентам максимальную производительность при минимальных затратах». – Ёсиаки Уметсу, директор Центра развития цифровых технологий компании Ricoh
«Команда специалистов RICOH по машинному обучению разрабатывает решения для рабочих мест и услуги по цифровой трансформации, направленные на управление и оптимизацию потока информации в рамках наших корпоративных решений. Переход на инстансы Trn1 оказался простым и понятным. Мы смогли предварительно обучить нашу модель LLM с параметром 13B всего за 8 дней, используя кластер из 4096 чипов Trainium. После успеха, достигнутого при использовании нашей компактной модели, мы усовершенствовали новый, более крупный LLM на базе Llama-3-Swallow-70B и, используя Trainium, смогли сократить затраты на обучение на 50 % и повысить энергоэффективность на 25 % по сравнению с использованием новейших графических процессоров в AWS. Мы рады использовать чипы AWS Trainium2 последнего поколения на базе искусственного интеллекта, чтобы и дальше обеспечивать нашим клиентам максимальную производительность при минимальных затратах». – Ёсиаки Уметсу, директор Центра развития цифровых технологий компании Ricoh
PyTorch
 «Что мне больше всего понравилось в библиотеке AWS Neuron NxD Inference, так это то, как легко она интегрируется с моделями PyTorch. Подход NxD прост и удобен в использовании. Наша команда смогла внедрить модели HuggingFace PyTorch с минимальными изменениями кода за короткий промежуток времени. Включение таких продвинутых функций, как непрерывное пакетирование и спекулятивное декодирование, не составило труда. Такая простота использования повышает производительность разработчиков, позволяя командам больше сосредоточиться на инновациях, а не на проблемах интеграции». – Хамид Шоджаназери, ведущий инженер компании Meta, партнер PyTorch
«Что мне больше всего понравилось в библиотеке AWS Neuron NxD Inference, так это то, как легко она интегрируется с моделями PyTorch. Подход NxD прост и удобен в использовании. Наша команда смогла внедрить модели HuggingFace PyTorch с минимальными изменениями кода за короткий промежуток времени. Включение таких продвинутых функций, как непрерывное пакетирование и спекулятивное декодирование, не составило труда. Такая простота использования повышает производительность разработчиков, позволяя командам больше сосредоточиться на инновациях, а не на проблемах интеграции». – Хамид Шоджаназери, ведущий инженер компании Meta, партнер PyTorch
Refact.ai
 «Refact.ai предоставляет широкий набор инструментов ИИ, включая автоматическое дополнение кода на основе Retrieval-Augmented Generation (RAG), точные рекомендации и контекстно-зависимый чат. Эти функции поддерживаются как собственными моделями, так и моделями с открытым исходным кодом, что обеспечивает максимальную гибкость и эффективность. По сравнению с инстансами EC2 G5, производительность инстансов EC2 Inf2 выросла на 20 %, а токенов за доллар – в 1,5 раза. Возможности точной настройки Refact.ai помогают клиентам глубже понимать уникальные особенности их кодовой базы и рабочей среды, а также адаптировать решения под индивидуальные потребности. Мы также рады предложить технологии Trainium2, обеспечивающие еще более быструю и эффективную обработку рабочих процессов. Этот инновационный подход ускоряет разработку программного обеспечения, повышая производительность разработчиков и соблюдая строгие стандарты безопасности кодовой базы». – Олег Климов, генеральный директор и основатель компании Refact.ai
«Refact.ai предоставляет широкий набор инструментов ИИ, включая автоматическое дополнение кода на основе Retrieval-Augmented Generation (RAG), точные рекомендации и контекстно-зависимый чат. Эти функции поддерживаются как собственными моделями, так и моделями с открытым исходным кодом, что обеспечивает максимальную гибкость и эффективность. По сравнению с инстансами EC2 G5, производительность инстансов EC2 Inf2 выросла на 20 %, а токенов за доллар – в 1,5 раза. Возможности точной настройки Refact.ai помогают клиентам глубже понимать уникальные особенности их кодовой базы и рабочей среды, а также адаптировать решения под индивидуальные потребности. Мы также рады предложить технологии Trainium2, обеспечивающие еще более быструю и эффективную обработку рабочих процессов. Этот инновационный подход ускоряет разработку программного обеспечения, повышая производительность разработчиков и соблюдая строгие стандарты безопасности кодовой базы». – Олег Климов, генеральный директор и основатель компании Refact.ai
Karakuri Inc.
 «KARAKURI разрабатывает инструменты ИИ, направленные на оптимизацию веб-поддержки и упрощение обслуживания клиентов. В их число входят чат-боты на основе генеративного ИИ, системы централизованного управления часто задаваемыми вопросами и инструменты автоматизации ответов на электронные письма. Эти решения позволяют повысить эффективность работы и улучшить качество поддержки клиентов. Используя AWS Trainium, нам удалось обучить чат KARAKURI LM 8x7B версии 0.1. Для стартапов, таких как наш, необходимо оптимизировать время разработки и затраты на обучение LLM. При поддержке AWS Trainium и команды AWS мы смогли за короткий промежуток времени разработать практический уровень LLM. Кроме того, внедрив AWS Inferentia, мы смогли создать быстрый и экономичный сервис логических выводов. Мы с энтузиазмом используем Trainium2, так как он революционизирует наш процесс обучения моделей, сокращая время тренировок вдвое и значительно повышая их эффективность». – Томофуми Накаяма, соучредитель компании Karakuri Inc.
«KARAKURI разрабатывает инструменты ИИ, направленные на оптимизацию веб-поддержки и упрощение обслуживания клиентов. В их число входят чат-боты на основе генеративного ИИ, системы централизованного управления часто задаваемыми вопросами и инструменты автоматизации ответов на электронные письма. Эти решения позволяют повысить эффективность работы и улучшить качество поддержки клиентов. Используя AWS Trainium, нам удалось обучить чат KARAKURI LM 8x7B версии 0.1. Для стартапов, таких как наш, необходимо оптимизировать время разработки и затраты на обучение LLM. При поддержке AWS Trainium и команды AWS мы смогли за короткий промежуток времени разработать практический уровень LLM. Кроме того, внедрив AWS Inferentia, мы смогли создать быстрый и экономичный сервис логических выводов. Мы с энтузиазмом используем Trainium2, так как он революционизирует наш процесс обучения моделей, сокращая время тренировок вдвое и значительно повышая их эффективность». – Томофуми Накаяма, соучредитель компании Karakuri Inc.
Stockmark Inc.
 «Поставив перед собой цель «создать новый механизм повышения ценности и развития человечества», компания Stockmark помогает многим компаниям создавать и развивать инновационный бизнес, предоставляя передовые технологии обработки естественного языка. Новая услуга Stockmark, включающая Anews для анализа и сбора данных, а также SAT – инструмент для структурирования данных, значительно улучшает использование генеративного ИИ, упорядочивая разнообразную информацию, хранящуюся в организациях. Для поддержки этих продуктов нам пришлось полностью пересмотреть подход к созданию и развертыванию моделей. С использованием 256 ускорителей Trainium мы разработали и запустили Stockmark-13B – большую языковую модель с 13 миллиардами параметров, предварительно обученную с нуля на японском корпусе объемом 220 миллиардов токенов. Инстансы Trn1 помогли нам сократить расходы на обучение на 20 %. Благодаря Trainium мы смогли создать LLM, способную отвечать на критически важные для бизнеса вопросы профессионалов с непревзойденной точностью и скоростью. Это достижение особенно важно, учитывая сложности, с которыми сталкиваются компании при обеспечении достаточных вычислительных ресурсов для разработки таких моделей. Учитывая впечатляющую скорость и снижение стоимости инстансов Trn1, мы рады видеть дополнительные преимущества, которые Trainium2 принесет нашим рабочим процессам и клиентам». – Косуке Арима, технический директор и соучредитель компании Stockmark Inc.
«Поставив перед собой цель «создать новый механизм повышения ценности и развития человечества», компания Stockmark помогает многим компаниям создавать и развивать инновационный бизнес, предоставляя передовые технологии обработки естественного языка. Новая услуга Stockmark, включающая Anews для анализа и сбора данных, а также SAT – инструмент для структурирования данных, значительно улучшает использование генеративного ИИ, упорядочивая разнообразную информацию, хранящуюся в организациях. Для поддержки этих продуктов нам пришлось полностью пересмотреть подход к созданию и развертыванию моделей. С использованием 256 ускорителей Trainium мы разработали и запустили Stockmark-13B – большую языковую модель с 13 миллиардами параметров, предварительно обученную с нуля на японском корпусе объемом 220 миллиардов токенов. Инстансы Trn1 помогли нам сократить расходы на обучение на 20 %. Благодаря Trainium мы смогли создать LLM, способную отвечать на критически важные для бизнеса вопросы профессионалов с непревзойденной точностью и скоростью. Это достижение особенно важно, учитывая сложности, с которыми сталкиваются компании при обеспечении достаточных вычислительных ресурсов для разработки таких моделей. Учитывая впечатляющую скорость и снижение стоимости инстансов Trn1, мы рады видеть дополнительные преимущества, которые Trainium2 принесет нашим рабочим процессам и клиентам». – Косуке Арима, технический директор и соучредитель компании Stockmark Inc.
Brave
 «Brave – это независимый браузер и поисковая система, которые уделяют приоритетное внимание конфиденциальности и безопасности пользователей. Более 70 миллионов пользователей применяют наши лучшие в отрасли средства защиты, которые делают работу в Интернете более безопасной и удобной. В отличие от других платформ, которые отказались от подходов, ориентированных на пользователя, Brave по-прежнему ставит конфиденциальность, безопасность и удобство на первое место. Ключевые функции включают блокировку вредоносных скриптов и трекеров, сводки страниц с помощью ИИ на основе LLM, встроенные VPN-сервисы и многое другое. Мы постоянно стремимся повысить скорость и экономичность наших поисковых сервисов и моделей ИИ. Для этого мы с радостью применяем новейшие возможности чипов ИИ AWS, включая Trainium2, чтобы улучшить пользовательский опыт и эффективно масштабировать систему для обработки миллиардов поисковых запросов ежемесячно». – Субу Сатьянараяна, вице-президент по проектированию компании Brave Software
«Brave – это независимый браузер и поисковая система, которые уделяют приоритетное внимание конфиденциальности и безопасности пользователей. Более 70 миллионов пользователей применяют наши лучшие в отрасли средства защиты, которые делают работу в Интернете более безопасной и удобной. В отличие от других платформ, которые отказались от подходов, ориентированных на пользователя, Brave по-прежнему ставит конфиденциальность, безопасность и удобство на первое место. Ключевые функции включают блокировку вредоносных скриптов и трекеров, сводки страниц с помощью ИИ на основе LLM, встроенные VPN-сервисы и многое другое. Мы постоянно стремимся повысить скорость и экономичность наших поисковых сервисов и моделей ИИ. Для этого мы с радостью применяем новейшие возможности чипов ИИ AWS, включая Trainium2, чтобы улучшить пользовательский опыт и эффективно масштабировать систему для обработки миллиардов поисковых запросов ежемесячно». – Субу Сатьянараяна, вице-президент по проектированию компании Brave Software
Anyscale
 «Anyscale – компания, создавшая Ray, вычислительный движок ИИ, лежащий в основе машинного обучения, и инициативы по генеративному ИИ для предприятий. Благодаря унифицированной платформе ИИ Anyscale на базе RayTurbo, наши клиенты получают следующие преимущества: в 4,5 раза более быструю обработку данных, в 10 раз меньшую стоимость пакетного вывода с использованием LLM, в 5 раз более быстрое масштабирование, в 12 раз более быструю итерацию, а также экономию затрат на интерактивный вывод моделей на 50 % благодаря оптимизации использования ресурсов. В Anyscale мы стремимся предоставить предприятиям лучшие инструменты для эффективного и экономичного масштабирования рабочих нагрузок ИИ. Благодаря встроенной поддержке чипов AWS Trainium и Inferentia в среде выполнения RayTurbo наши клиенты получают доступ к высокопроизводительным и экономичным решениям для обучения и обслуживания моделей. Мы с радостью объединяем усилия с AWS, чтобы использовать Trainium2, открывая новые возможности для наших клиентов в области быстрого внедрения инноваций и масштабного использования высокопроизводительных технологий ИИ». – Роберт Нишихара, соучредитель компании Anyscale
«Anyscale – компания, создавшая Ray, вычислительный движок ИИ, лежащий в основе машинного обучения, и инициативы по генеративному ИИ для предприятий. Благодаря унифицированной платформе ИИ Anyscale на базе RayTurbo, наши клиенты получают следующие преимущества: в 4,5 раза более быструю обработку данных, в 10 раз меньшую стоимость пакетного вывода с использованием LLM, в 5 раз более быстрое масштабирование, в 12 раз более быструю итерацию, а также экономию затрат на интерактивный вывод моделей на 50 % благодаря оптимизации использования ресурсов. В Anyscale мы стремимся предоставить предприятиям лучшие инструменты для эффективного и экономичного масштабирования рабочих нагрузок ИИ. Благодаря встроенной поддержке чипов AWS Trainium и Inferentia в среде выполнения RayTurbo наши клиенты получают доступ к высокопроизводительным и экономичным решениям для обучения и обслуживания моделей. Мы с радостью объединяем усилия с AWS, чтобы использовать Trainium2, открывая новые возможности для наших клиентов в области быстрого внедрения инноваций и масштабного использования высокопроизводительных технологий ИИ». – Роберт Нишихара, соучредитель компании Anyscale
Datadog
 «Datadog, платформа наблюдения и безопасности для облачных приложений, предоставляет клиентам AWS Trainium и Inferentia Monitoring для оптимизации производительности моделей, повышения эффективности и снижения затрат. Интеграция Datadog обеспечивает полную визуализацию операций машинного обучения и базовой производительности микросхем благодаря упреждающему решению проблем и беспрепятственному масштабированию инфраструктуры. Мы с радостью расширяем сотрудничество с AWS в связи с запуском AWS Trainium2, который позволит пользователям сократить расходы на инфраструктуру ИИ до 50 % и значительно повысить эффективность обучения и развертывания моделей». – Ирикс Гарнье, вице-президент по продуктам компании Datadog
«Datadog, платформа наблюдения и безопасности для облачных приложений, предоставляет клиентам AWS Trainium и Inferentia Monitoring для оптимизации производительности моделей, повышения эффективности и снижения затрат. Интеграция Datadog обеспечивает полную визуализацию операций машинного обучения и базовой производительности микросхем благодаря упреждающему решению проблем и беспрепятственному масштабированию инфраструктуры. Мы с радостью расширяем сотрудничество с AWS в связи с запуском AWS Trainium2, который позволит пользователям сократить расходы на инфраструктуру ИИ до 50 % и значительно повысить эффективность обучения и развертывания моделей». – Ирикс Гарнье, вице-президент по продуктам компании Datadog
Hugging Face
 «Hugging Face – ведущая открытая платформа для разработчиков ИИ, на которой собрано более 2 миллионов моделей, наборов данных и приложений ИИ, созданных сообществом из более чем 5 миллионов исследователей, специалистов по обработке данных, инженеров машинного обучения и разработчиков программного обеспечения. Мы сотрудничаем с AWS последние несколько лет, чтобы помогать разработчикам легче оценивать преимущества AWS Inferentia и Trainium с точки зрения производительности и стоимости. Это стало возможным благодаря библиотеке Optimum Neuron с открытым исходным кодом, интегрированной в конечные точки Hugging Face Inference, а теперь и оптимизированной в нашем новом сервисе саморазвертывания HUGS, доступном на AWS Marketplace. С запуском Trainium2 наши пользователи получат еще более высокую производительность, что позволит быстрее разрабатывать и развертывать модели». – Джефф Будье, руководитель отдела продуктов компании Hugging Face
«Hugging Face – ведущая открытая платформа для разработчиков ИИ, на которой собрано более 2 миллионов моделей, наборов данных и приложений ИИ, созданных сообществом из более чем 5 миллионов исследователей, специалистов по обработке данных, инженеров машинного обучения и разработчиков программного обеспечения. Мы сотрудничаем с AWS последние несколько лет, чтобы помогать разработчикам легче оценивать преимущества AWS Inferentia и Trainium с точки зрения производительности и стоимости. Это стало возможным благодаря библиотеке Optimum Neuron с открытым исходным кодом, интегрированной в конечные точки Hugging Face Inference, а теперь и оптимизированной в нашем новом сервисе саморазвертывания HUGS, доступном на AWS Marketplace. С запуском Trainium2 наши пользователи получат еще более высокую производительность, что позволит быстрее разрабатывать и развертывать модели». – Джефф Будье, руководитель отдела продуктов компании Hugging Face
Lightning AI
 «Компания Lightning AI, создатель PyTorch Lightning и Lightning Studios, предлагает интуитивно понятную универсальную платформу для разработки ИИ корпоративного уровня. Lightning предоставляет инструменты с полным кодом, а также решения с низким и нулевым кодом для быстрого создания агентов, приложений и решений на основе генеративного ИИ. Разработанный с учетом гибкости, он легко работает как в вашем облаке, так и в нашем, предоставляя доступ к опытным знаниям и поддержке сообщества разработчиков, насчитывающего более 3 миллионов человек. Теперь Lightning изначально предлагает поддержку чипов AWS AI, Trainium и Inferentia, которые интегрированы в Lightning Studios и наши инструменты с открытым исходным кодом, такие как PyTorch Lightning, Fabric и LitServe. Это предоставляет пользователям возможность без труда проводить предварительное обучение, тонкую настройку и развертывание на нужном масштабе, оптимизируя стоимость, доступность и производительность при нулевых затратах на переключение. Кроме того, оно повышает производительность и экономичность чипов AWS AI, включая новейшие чипы Trainium2, обеспечивая более высокую производительность при меньших затратах». –Лука Антига, технический директор компании Lightning AI
«Компания Lightning AI, создатель PyTorch Lightning и Lightning Studios, предлагает интуитивно понятную универсальную платформу для разработки ИИ корпоративного уровня. Lightning предоставляет инструменты с полным кодом, а также решения с низким и нулевым кодом для быстрого создания агентов, приложений и решений на основе генеративного ИИ. Разработанный с учетом гибкости, он легко работает как в вашем облаке, так и в нашем, предоставляя доступ к опытным знаниям и поддержке сообщества разработчиков, насчитывающего более 3 миллионов человек. Теперь Lightning изначально предлагает поддержку чипов AWS AI, Trainium и Inferentia, которые интегрированы в Lightning Studios и наши инструменты с открытым исходным кодом, такие как PyTorch Lightning, Fabric и LitServe. Это предоставляет пользователям возможность без труда проводить предварительное обучение, тонкую настройку и развертывание на нужном масштабе, оптимизируя стоимость, доступность и производительность при нулевых затратах на переключение. Кроме того, оно повышает производительность и экономичность чипов AWS AI, включая новейшие чипы Trainium2, обеспечивая более высокую производительность при меньших затратах». –Лука Антига, технический директор компании Lightning AI
Domino Data Lab
 «Domino координирует все артефакты анализа данных, включая инфраструктуру, данные и сервисы на AWS в разных средах, дополняя Amazon SageMaker возможностями управления и совместной работы для поддержки корпоративных групп обработки и анализа данных. Domino доступен в AWS Marketplace как SaaS или как самостоятельно управляемый сервис. Ведущие компании должны правильно сочетать техническую сложность, затраты и управление, осваивая обширные возможности ИИ для внедрения инноваций. Мы в Domino стремимся предоставить клиентам доступ к передовым технологиям. Вычислительные ресурсы являются узким местом для многих инноваций, и мы гордимся тем, что предоставляем клиентам доступ к Trainium2, чтобы они могли обучать и развертывать модели с более высокой производительностью, меньшими затратами и более высокой энергоэффективностью». –Ник Элприн, генеральный директор и соучредитель компании Domino Data Lab
«Domino координирует все артефакты анализа данных, включая инфраструктуру, данные и сервисы на AWS в разных средах, дополняя Amazon SageMaker возможностями управления и совместной работы для поддержки корпоративных групп обработки и анализа данных. Domino доступен в AWS Marketplace как SaaS или как самостоятельно управляемый сервис. Ведущие компании должны правильно сочетать техническую сложность, затраты и управление, осваивая обширные возможности ИИ для внедрения инноваций. Мы в Domino стремимся предоставить клиентам доступ к передовым технологиям. Вычислительные ресурсы являются узким местом для многих инноваций, и мы гордимся тем, что предоставляем клиентам доступ к Trainium2, чтобы они могли обучать и развертывать модели с более высокой производительностью, меньшими затратами и более высокой энергоэффективностью». –Ник Элприн, генеральный директор и соучредитель компании Domino Data Lab
Начало работы
Скоро появится поддержка инстансов Trn2 в SageMaker. Вы сможете легко обучать модели на инстансах Trn2, используя Amazon SageMaker HyperPod, который обеспечивает отказоустойчивый вычислительный кластер, оптимизированную производительность обучения и эффективное использование базовых вычислительных, сетевых ресурсов и ресурсов памяти. Вы также можете масштабировать развертывание модели на инстансах Trn2 с помощью SageMaker для более эффективного управления моделями в производственной среде и снижения эксплуатационной нагрузки.
Глубокое обучение AWS AMI (DLAMI) предоставляет специалистам по глубокому обучению и анализу данных инфраструктуру и инструменты для ускорения глубокого обучения на платформе AWS в любых масштабах. Драйверы AWS Neuron предварительно сконфигурированы в DLAMI для оптимального обучения моделей DL на инстансах Trn2.
Скоро появится поддержка контейнеров глубокого обучения для инстансов Trn2. Теперь, используя эти контейнеры, вы сможете развертывать инстансы Trn2 в Amazon Elastic Kubernetes Service (Amazon EKS), полностью управляемом сервисе Kubernetes, и в Amazon Elastic Container Service (Amazon ECS), полностью управляемом сервисе оркестрации контейнеров. Кроме того, Neuron предварительно установлен в Контейнерах для глубокого обучения AWS. Дополнительные сведения о запуске контейнеров на инстансах Trn2 см. в руководствах по контейнерам Neuron.
Сведения о продукте
|
Размер инстанса
|
Доступно в EC2 UltraServers
|
Чипы Trainium2
|
Объем памяти ускорителя
|
Виртуальные ЦПУ
|
Память (ТБ)
|
Хранилище инстансов (ТБ)
|
Пропускная способность сети (Тбит/с)
|
Пропускная способность EBS (Гбит/с)
|
|---|---|---|---|---|---|---|---|---|
|
Trn2.3xlarge
|
Нет |
1 |
96 ГБ |
12 |
128 ГБ |
1 NVMe SSD на 470 ГБ
|
0,2 |
5 |
|
trn2.48xlarge
|
Нет
|
16
|
1,5 ТБ
|
192
|
2 ТБ
|
4 x 1,92 SSD на базе NVMe
|
3,2
|
80
|
|
trn2u.48xlarge
|
Да |
16
|
1,5 ТБ
|
192
|
2 ТБ
|
4 x 1,92 SSD на базе NVMe
|
3,2
|
80
|