Simplismart.ai Scales Generative AI Workloads with Faster Inference and 40% Lower Infrastructure Costs
Learn how Simplismart.ai helps enterprises scale low-latency generative AI workloads with its proprietary inference engine—reducing infrastructure costs by up to 40%.
Benefits
Overview
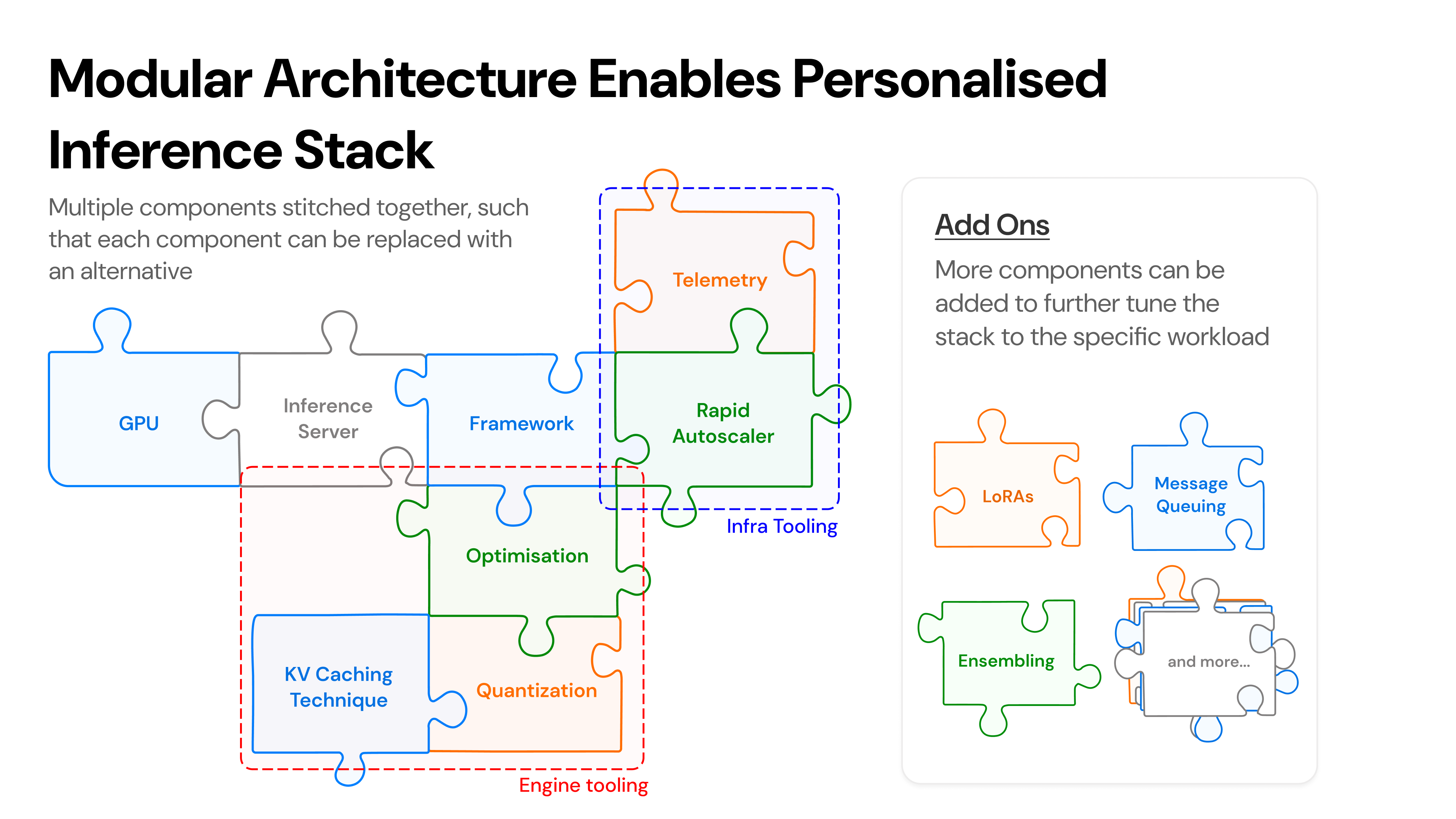
Simplismart.ai is an India-based startup that helps enterprises deploy high-performance generative AI workloads quickly and efficiently. The company offers a modular, inference-first MLOps orchestration platform that supports fine-tuning, deployment, and monitoring of open-source or custom models across cloud and hybrid environments.
As enterprise adoption accelerated, Simplismart.ai aimed to support rapid, reliable scaling across multiple availability zones. With the help of Amazon Web Services (AWS), the company implemented intelligent autoscaling tailored for generative AI and streamlined infrastructure across deployments. This helped reduce infrastructure costs by up to 40 percent, increase GPU hours deployed by 8x, and scale operations sixfold in six months.
About Simplismart.ai
Simplismart.ai is transforming the deployment of generative AI with an ultra-fast inference engine built for large language models, speech-to-text models like Whisper, embeddings, image and video generation, and multimodal models. Founded in India, the company delivers a modular, end-to-end MLOps platform that spans fine-tuning, inference, and observability, supporting both cloud and hybrid environments and helping enterprises deliver low-latency, cost-optimized AI solutions at scale.
Opportunity | Scaling Generative AI Inference While Reducing Latency and Cost
Founded in India, Simplismart.ai offers an end-to-end MLOps orchestration platform built around a proprietary inference engine. The platform supports open-source, open-weight, or custom models—including large language models (LLMs), small language models (SLMs), text-to-image and text-to-video models, automatic speech recognition (ASR), speech translation, and multimodal models. Built for both cloud and hybrid AI deployments, Simplismart.ai’s platform is designed to help enterprises scale generative AI workloads with low latency and high efficiency. As adoption grew, engineering teams found it increasingly difficult to manage orchestration, model fine-tuning, and observability across diverse environments.
Initially, Simplismart.ai’s customers relied on high-end GPU instances to run production workloads but struggled to scale efficiently as demand fluctuated. This led to higher infrastructure costs and underutilized resources. At the same time, traditional autoscaling methods were too slow to respond to sudden traffic surges, affecting service reliability and user experience. “Inference at scale is extremely demanding,” says Devansh Ghatak, co-founder and chief technology officer at Simplismart.ai. “It’s not just about raw compute—it’s about latency, efficiency, and adaptability.”
Recognizing the need to reduce latency, optimize costs, and maintain SLA-grade performance, the company set out to design a more responsive, intelligent infrastructure to meet the demands of enterprise-scale generative AI applications.
Solution | Building a High-Performance Inference Architecture with Amazon EC2 Auto Scaling Warm Pools and Amazon EKS
After evaluating multiple infrastructure approaches to deliver low-latency, cost-effective inference, Simplismart.ai chose AWS for its high-performance compute options, elastic scalability, and collaborative technical support. The team used Amazon Elastic Compute Cloud (Amazon EC2) P5 and P4d instances to fine-tune its inference engine for production-grade generative AI workloads. Amazon Elastic Kubernetes Service (Amazon EKS) provided orchestration across environments, while Amazon EC2 Auto Scaling with warm pools—pre-initialized instances kept in a standby state—significantly reduced scale-up times. “With Amazon EC2 Auto Scaling warm pools, our customers can scale in under 70 seconds,” says Ghatak. “That flexibility lets them use lower-tier GPUs, reduce costs, and still meet SLAs.”
AWS engineers also supported Simplismart.ai in developing custom pod autoscalers that integrate with Amazon EC2 Auto Scaling warm pools. These enhancements reduced scale-up times from five to six minutes to just over one minute—improvements Simplismart.ai was able to pass on to customers through better performance and cost efficiency. From a single control plane, engineering teams can deploy and manage Kubernetes clusters across AWS and hybrid infrastructure—centralizing orchestration of model fine-tuning, deployment, and observability across environments. Recognizing that no two deployments are alike, Simplismart.ai enables enterprises to adapt their ML stack—including quantization, model backends, libraries, and models—based on specific use cases and load profiles. Through a modular interface, customers can easily swap components in and out, accelerating experimentation, avoiding vendor lock-in, and staying future-proof.
Beyond performance, AWS support helped Simplismart.ai accelerate development. Early collaboration with AWS solution architects shaved weeks off the infrastructure build phase, giving the team a fast path to deploying a production-ready system.
Outcome | Accelerating Generative AI Workloads Scalability and Cutting Cost
Deploying its inference platform on AWS helped Simplismart.ai eliminate scaling delays and reduce infrastructure costs for its customers by up to 40 percent. With warm pool-enabled autoscaling, customers now scale compute in just 60–70 seconds, allowing them to respond to traffic surges quickly while maintaining SLA-grade performance. These enhancements allow customers to optimize GPU usage more intelligently and run LLM workloads with greater reliability.
“The AWS-hosted control planes give us near 100 percent uptime, and our inference engine now adapts in real time to customer needs,” says Ghatak. “Whether it’s making responses faster or handling more requests at once, we can fine-tune the setup to meet our customers’ needs.”
As a result, Simplismart.ai scaled its business 6x in six months and increased GPU deployment eightfold in just three months. With faster scaling and improved infrastructure efficiency, the team accelerated customer onboarding and enhanced the overall performance of generative AI workloads across use cases. “AWS gave us the right tools and guidance to move fast,” says Ghatak. “Their support helped us scale instantly and reliably, while optimizing costs for our customers and delivering great experiences to them.”
AWS gave us the right tools and guidance to move fast. Their support helped us scale instantly and reliably, while optimizing costs for our customers and delivering great experiences to them.
Devansh Ghatak
Co-Founder and CTO at Simplismart.aiAWS Services Used
Get Started
Organizations of all sizes across all industries are transforming their businesses and delivering on their missions every day using AWS. Contact our experts and start your own AWS journey today.
Did you find what you were looking for today?
Let us know so we can improve the quality of the content on our pages