- AWS Solutions Library›
- Guidance for Live Chat Content Moderation with Generative AI on AWS
Guidance for Live Chat Content Moderation with Generative AI on AWS
Overview
This Guidance demonstrates how organizations can implement generative artificial intelligence (AI) services for automated message screening in live chat environments. The architecture integrates with existing chat platforms through a secure, scalable cloud infrastructure. It also uses AWS machine learning services to offer near real-time content analysis and customizable filtering rules. Organizations can significantly reduce manual reviews, maintain consistent moderation standards, and create safer communication environments by automatically detecting and filtering inappropriate content across multiple languages. This approach helps businesses efficiently manage content moderation at scale while improving user experience and safety.
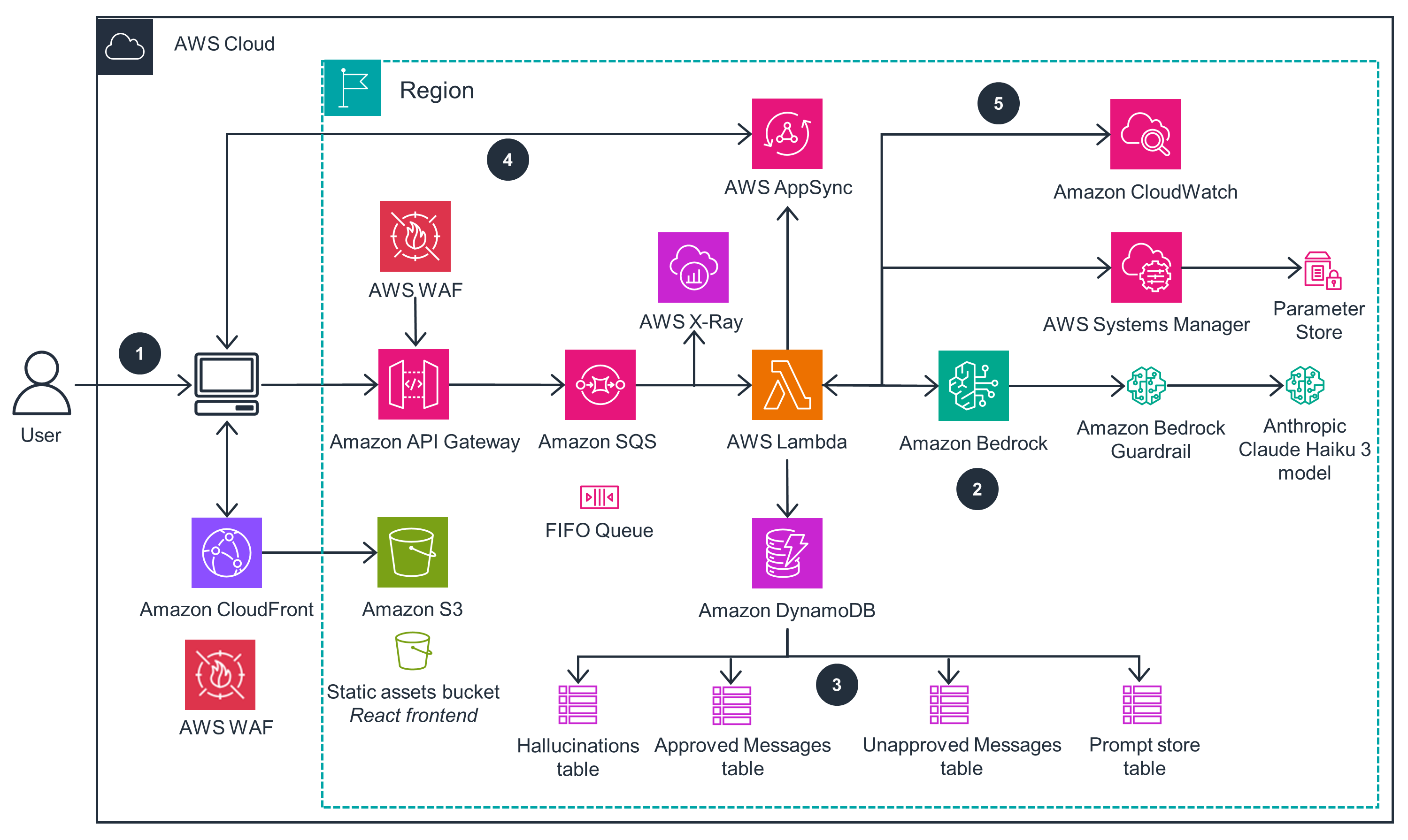
How it works
This architecture diagram illustrates a real-time chat moderation system designed for live streaming platforms. It uses AWS services and generative artificial intelligence (AI) to automatically filter and moderate chat messages, creating a safer and more engaging environment for users.
Get Started
Well-Architected Pillars
The architecture diagram above is an example of a Solution created with Well-Architected best practices in mind. To be fully Well-Architected, you should follow as many Well-Architected best practices as possible.
Live Chat Content Moderation with Generative AI transforms online conversation management. It deploys through an AWS Cloud Development Kit (AWS CDK), minimizing configuration errors with fast, consistent, and repeatable deployments. Operations teams gain visibility through CloudWatch dashboards and logs, tracking moderation accuracy and chat performance in real-time. And through automated Lambda functions, the system processes and moderates’ messages using generative AI, protecting users while maintaining natural conversation flow.
Lambda functions and API Gateway endpoints operate with specific AWS Identity and Access Management (IAM) roles that grant only the permissions needed for each component's function. For example, the message processing Lambda function has permissions limited to reading from and writing to its designated DynamoDB tables. Data remains encrypted both at rest through a default AWS Key Management Service ( AWS KMS) encryption, and in transit using HTTPS. This encryption covers the full message lifecycle, from initial user input through moderation processing and storage.
The fault tolerance design for this architecture centers on Amazon SQS queues. These queues help ensure message processing reliability, while dedicated dead-letter queues capture and preserve any failed processing attempts. If message processing fails, the system automatically retries based on configurable policies before moving messages to the dead-letter queue for investigation. This design also relies entirely on serverless technologies, including Lambda functions, API Gateway endpoints, and DynamoDB tables. More specifically, Lambda functions automatically retry on failure, API Gateway maintains high availability across multiple Availability Zones, and DynamoDB provides automatic replication. These services also scale automatically based on incoming traffic, adjusting capacity in response to demand without manual intervention, handling variations from normal chat volumes to unexpected traffic spikes.
CloudFront caches static assets at edge locations, reducing latency for end users by serving content from the nearest geographical point. This architecture also decouples message ingestion from processing using Amazon SQS , allowing this design to maintain consistent performance during high-load periods by buffering incoming messages and processing them asynchronously.
Through the serverless and managed services, costs are directly aligned with usage. Lambda charges based on execution time and memory consumption, while API Gateway and DynamoDB costs scale with actual request volume and storage needs. AppSync and Amazon Bedrock follow similar consumption-based pricing models. Performance and cost trade-offs can be adjusted through Lambda configuration settings, allowing for the fine-tuning of memory allocation and timeout values based on observed execution patterns and requirements.
This architecture can be deployed in AWS Regions that operate with higher percentages of renewable energy, contributing to reduced carbon footprint. In addition, resource efficiency is achieved through dynamic scaling, where compute and storage capacity adjust automatically to match actual demand, eliminating the waste associated with over-provisioned infrastructure.
Disclaimer
Did you find what you were looking for today?
Let us know so we can improve the quality of the content on our pages