- AWS Solutions Library›
- Guidance for Low Latency, High Throughput Inference using Efficient Compute on Amazon EKS
Guidance for Low Latency, High Throughput Inference using Efficient Compute on Amazon EKS
Overview
How it works
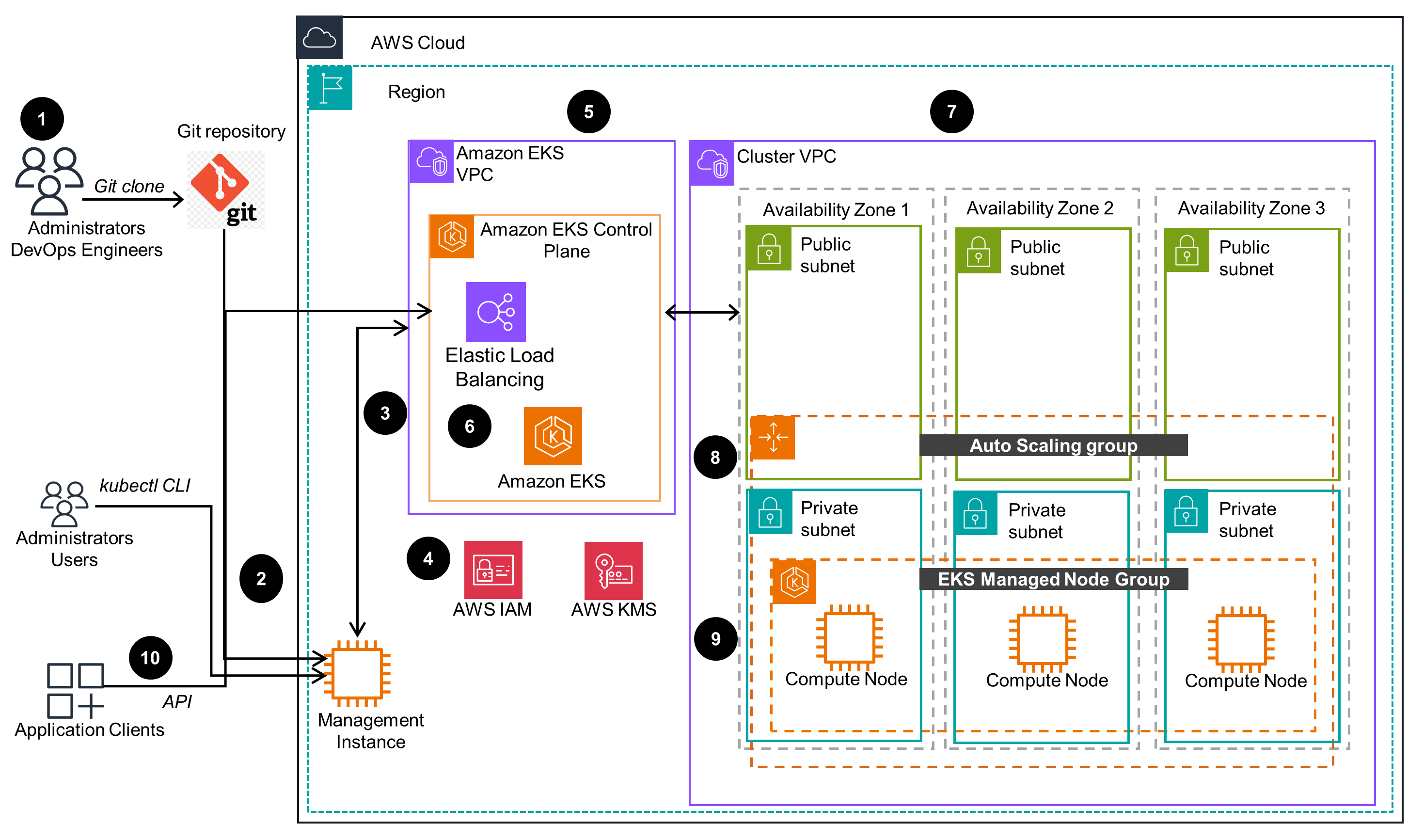
Infrastructure
This infrastructure diagram provides a way to setup an Amazon Elastic Kubernetes Service (Amazon EKS) cluster that is compatible with this Guidance. Optionally, a pre-existing Amazon EKS cluster can be used. To learn more about running inference workloads on this infrastructure, open the Architecture tab.
Architecture
This diagram provides a simple, scalable, and highly available architecture for running machine learning (ML) inference workloads on AWS. It uses a standard Amazon Elastic Kubernetes Service (Amazon EKS) infrastructure that can be deployed across multiple Availability Zones for high availability. For instructions to setup an Amazon EKS cluster compatible with this Guidance, open the Infrastructure tab.
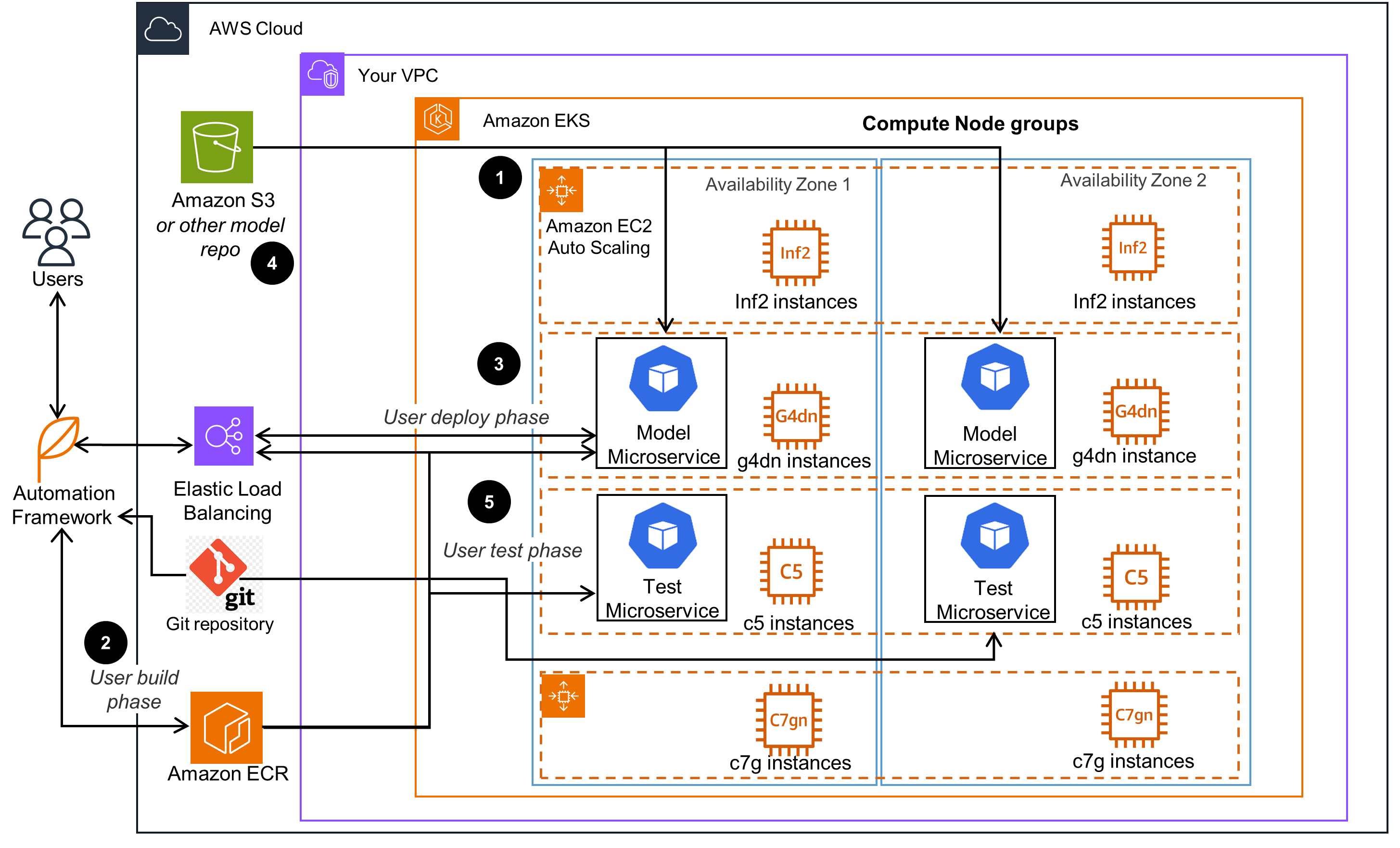
Well-Architected Pillars
The architecture diagram above is an example of a Solution created with Well-Architected best practices in mind. To be fully Well-Architected, you should follow as many Well-Architected best practices as possible.
Amazon EKS, Amazon ECR, and a test automation framework are used in this Guidance to enhance your operational excellence. It helps you visualize, customize, and understand the concept of serving ML models using a FastAPI framework, providing you the flexibility to choose the Amazon EKS node compute instances of your choice in order to optimize performance and costs. Amazon EKS and Amazon ECR are managed Kubernetes and image repository services, respectively, and fully support API-based automation of all phases of the machine learning operations (MLOps) cycle. We also show how you can automatically deploy and run a large number of customized machine learning models, as well as automate load and scale testing of those models' performance using an automation framework.
Amazon EKS, Amazon VPC, IAM roles and policies, and Amazon ECR work in tandem to protect your information and systems. The Amazon EKS cluster resources are deployed into a VPC that provides a logical isolation of its resources from the public internet. A VPC supports a variety of security features, such as security groups and network access control lists (ACLs), which are used to control inbound and outbound traffic to resources, as well as IAM roles and policies for authorization to limit access. The Amazon ECR image registry provides additional container-level security features, such as vulnerability scanning.
Amazon EKS and Amazon ECR are used throughout this Guidance to help your workloads perform their intended functions correctly and consistently. Amazon EKS deploys the Kubernetes control plane (the instances that control how, when, and where your containers run) and the compute planes (the instances where your containers run) across multiple Availability Zones (AZs) in AWS Regions. This ensures that both the control and compute planes are always available, even if one AZ goes down. Also, Elastic Load Balancing (ELB) will route application traffic to functional nodes. Additionally, the Amazon EKS cluster components are sending metrics to an Amazon CloudWatch portal, where events can be configured to invoke alerts in case certain thresholds are crossed.
Amazon ECR, Amazon EKS, and Amazon EC2 were used in this Guidance to support a structured and streamlined allocation of IT and computing resources. The compute nodes within the Amazon EKS cluster (that are Amazon EC2 instances) can be scaled up and down based on the application's workload requirement while conducting the tests. Moreover, Amazon ECR and Amazon EKS are highly available services, optimized for scalability and performance of containerized applications. This Guidance leverages those and other services (such as Amazon S3, and the GitHub open-source software) to monitor and optimize performance characteristics of machine learning inference workloads through customization and automation.
Amazon ECR is a managed service that optimizes the costs of both storing and serving container image applications that are deployed on Amazon EKS. The compute nodes of the Amazon EKS cluster can scale up or down, based on projected workloads, when performing tests. Also, Amazon EKS node groups can be efficiently scaled, helping you to identify the most cost-efficient compute node configuration for running ML inferences at scale.
Amazon EKS with the Amazon EC2 compute node instances deployed into the VPC and Amazon ECR do not use custom hardware. Meaning, you do not need to purchase or manage any physical servers. Instead, this Guidance uses managed services that run on the AWS infrastructure. Furthermore, by supporting the use of energy-efficient processor instance types, like AWS Graviton Processors, this architecture provides increased sustainability. Using Graviton running in Amazon EC2 can improve the performance of your workloads with less resources and thereby decreasing your overall resource footprint.
Deploy with confidence
Everything you need to launch this Guidance in your account is right here
We'll walk you through it
Dive deep into the implementation guide for additional customization options and service configurations to tailor to your specific needs.
Let's make it happen
Ready to deploy? Review the sample code on GitHub for detailed deployment instructions to deploy as-is or customize to fit your needs.
Disclaimer
Did you find what you were looking for today?
Let us know so we can improve the quality of the content on our pages