Wie war dieser Inhalt?
- Lernen
- Im Blickpunkt: Datagen erstellt synthetische Daten mit hoher Wiedergabetreue, um menschenzentrierte Probleme zu lösen
Im Blickpunkt: Datagen erstellt synthetische Daten mit hoher Wiedergabetreue, um menschenzentrierte Probleme zu lösen
Als Gil Elbaz und Ofir Zuk Datagen 2018 gründeten, hatten sie das Ziel, den gescheiterten Prozess, mit dem Kunden Daten für Computer-Vision-Netzwerktrainingssitzungen abrufen, neu zu erfinden. Insbesondere wollten sie jedem Computer-Vision-Team eine Datensimulation auf kontinuierliche und skalierbare Weise zur Verfügung stellen.

Da die Leistung von KI-Modellen sowohl von der Qualität des Modells als auch von der Qualität der für das Training verwendeten Daten abhängt, ist es unerlässlich, über eine große Menge guter Daten zu verfügen; und es ist oft schwierig, so viele wie nötig zu sammeln. Daten aus der realen Welt sind in der Regel auch problematisch, wenn es um die Geschwindigkeit der Erfassung, Präzision, Kosten und Verzerrungen geht. „Jemand sammelt [reale] Daten mit unterschiedlichen Identitäten (zum Beispiel für Gesichter) und die Person sammelt nicht genug Daten zu bestimmten Ethnien, Altersgruppen oder Geschlechtern“, erklärt Shay Navon, Senior Product Marketing Manager bei Datagen. „Und dann bekommt man diese Voreingenommenheit.“
Um Computer-Vision-Teams dabei zu helfen, Vorurteile zu bekämpfen, bietet Datagen eine einzigartige Möglichkeit, Daten mithilfe von Computeralgorithmen zu generieren. Ihre synthetischen Daten ähneln sowohl statistisch als auch mathematisch realen Daten, können jedoch schnell und mit geringeren Kosten generiert werden und sind frei von menschlichem Versagen. Anstatt einen Menschen mit der lästigen Aufgabe zu beauftragen, Daten manuell zu sammeln und zu kommentieren (eine arbeitsintensive Aufgabe, bei der man ein Foto von einem Gesicht aufnehmen und die Merkmale dann von Hand beschriften muss), werden synthetische Daten in großem Umfang generiert, mit integrierten Ground-Truth-Anmerkungen wie der Blickrichtung, die für einen Menschen unmöglich zu bestimmen wären. Das Ergebnis ist eine genauere und detailliertere Datenannotation, ohne dass manuelles Tagging erforderlich ist.
„Wir simulieren die Welt, um KI schneller in die Produktion zu bringen“, sagt Karine Regev, VP of Marketing bei Datagen. „KI in die Produktion zu bringen, ist für die meisten Unternehmen eine ungelöste Herausforderung. Deshalb machen wir sie professioneller und genauer und lösen Probleme wie den Datenschutz und Probleme wie Datenverzerrungen, die die größten Engpässe in der modernen KI darstellen.“
Datagen bietet Kunden eine Selfservice-Plattform, die 3D-Simulationen verwendet, um ihre Algorithmen zu trainieren. „Um ein Modell zu trainieren, benötigt man Millionen verschiedener Bilder“, sagt Regev. „Und genau hier passen wir rein. [Datagen-Kunden] haben die Möglichkeit, die Szenen, den Hintergrund, die verschiedenen Modalitäten, die verschiedenen Bezeichnungen, die Sie benötigen, die Beleuchtung, das Geschlecht, die ethnische Zugehörigkeit, alles zu kontrollieren.“
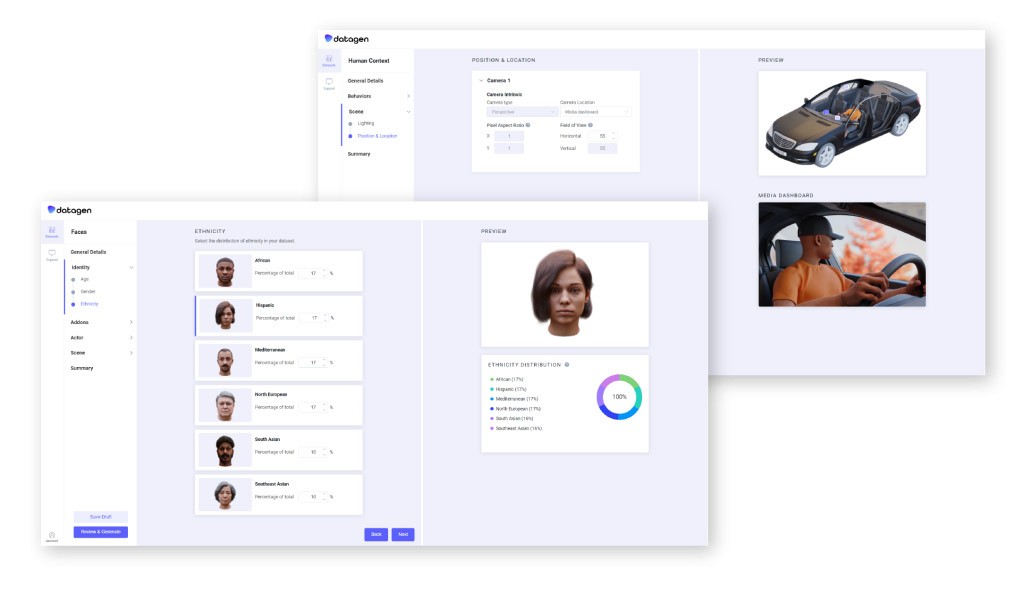
Datagen generiert nicht nur verschiedene Daten, die echt aussehen, skalierbar und pixelgenau sind, sondern bietet seinen Kunden auch absolute Vertraulichkeit. „Es ist vollständig datenschutzkonform, da die Daten keine persönlich identifizierbare Informationen (Personally Identifiable Information) enthalten“, sagt Shay Navon über die synthetischen Daten. „Niemand kann sagen: ‚Das ist jemand, den wir benutzen, der in Bezug auf den Datenschutz ein Problem darstellt.‘ Unser Fachwissen und unsere Daten, bei denen der Mensch im Mittelpunkt steht, konzentrieren sich auf verschiedene Domains, von der Erkennung von Gesichtspunkten über die Einschätzung des Blickes und die Analyse von Gesichtsausdrücken bis hin zu Körperhaltungen, Körperteilen wie Augen, Händen usw.“
In naher Zukunft wird prognostiziert, dass es üblicher sein wird, Modelle mit synthetischen Daten zu trainieren, als sie aus realen Quellen zu sammeln. Dementsprechend ist Datagen rasant gewachsen und ist in den letzten neun Monaten von rund 40 auf fast 100 Mitarbeiter angewachsen. „Wir arbeiten mit einigen der größten Technologieunternehmen der Welt in verschiedenen Branchen zusammen“, sagt Regev. „Lösung verschiedener Anwendungsfälle, von AR/VR/Metaverse über Fahrerüberwachung in der Fahrzeugkabine bis hin zu Haussicherheit und intelligenten Büros.“

Um dieser neuen Nachfrage gerecht zu werden, entschied sich Datagen für die Umstellung auf Cloud-Architektur. Die Priorität war die Skalierung mit den neuesten GPU-Modellen. Nach einer eingehenden Analyse der Cloud-Anbieter wandte das Unternehmen sich an AWS und waren entschlossen, sein System auf der Grundlage von Kubernetes zu entwickeln. Datagen hat ein benutzerdefiniertes Planungssoftwaresystem namens Agni entwickelt, das in Elastic Kubernetes Service (Amazon EKS) integriert ist und Kubernetes-Auto-Scaling und AWS-Auto-Scaling-Gruppen verwendet.
Agni (und die gesamte Datengenerierungsplattform von Datagen) basieren jetzt auf CPU- und GPU-Spot-Instances, was dabei geholfen hat, die Kosten zu senken und ein effizienteres System aufzubauen. Es ermöglicht dem Unternehmen auch, ein relativ kleines System zu verwalten, das dynamisch auf Hunderttausende von gleichzeitigen Aufträgen wachsen und bei Bedarf schrumpfen kann, was zu einer von AWS gehosteten Selfservice-Plattform führt.
Mit Blick auf die Zukunft prognostiziert das Datagen-Team, dass der Bedarf an synthetischen Daten weiter steigen wird. „Wir sehen eine große Nachfrage, sowohl in Bezug auf die Nachfrage als auch in Bezug auf die Aussichten, die Notwendigkeit einer Vordenkerrolle, den Bedarf an Technologie und einer Lösung wie unserer, die tatsächlich die Konversation leiten kann, wenn es um synthetische Daten geht“, sagt Regev.

AWS Editorial Team
Das Content Marketing Team von AWS Startups arbeitet mit Startups aller Größen und Branchen zusammen, um außergewöhnliche Inhalte bereitzustellen, die informieren, unterhalten und inspirieren.
Wie war dieser Inhalt?