¿Qué le pareció este contenido?
- Aprender
- Tema destacado: Datagen crea datos sintéticos de alta fidelidad para abordar problemas centrados en las personas
Tema destacado: Datagen crea datos sintéticos de alta fidelidad para abordar problemas centrados en las personas
Cuando Gil Elbaz y Ofir Zuk fundaron Datagen en 2018, tenían el propósito de reinventar el proceso defectuoso de cómo los clientes obtienen datos para el entrenamiento de redes de visión artificial. Más específicamente, querían llevar la simulación de datos a todos los equipos de visión artificial de forma continua y escalable.

Dado que el rendimiento de los modelos de IA depende tanto de la calidad del modelo como de la calidad de los datos que se utilizan para entrenarlo, es fundamental contar con una gran cantidad de datos de buena calidad y, a menudo, resulta difícil recopilar la cantidad necesaria. Los datos del mundo real también suelen ser problemáticos en lo que respecta a la velocidad de adquisición, la precisión, los gastos y el sesgo. “Alguien recopila datos [del mundo real] sobre diferentes identidades (por ejemplo, sobre rostros) y no recopila datos suficientes sobre determinadas etnias, edades o géneros”, explica Shay Navon, Senior Product Marketing Manager en Datagen. “Y luego surge este sesgo”.
Para ayudar a los equipos de visión artificial a combatir los sesgos, Datagen ofrece una forma única de generar datos mediante algoritmos de computación. Sus datos sintéticos son similares a los datos del mundo real desde el punto de vista estadístico y matemático, pero se pueden generar rápidamente, con menos gastos y están exentos de errores humanos. En lugar de encargar a un humano la tarea de recopilar y anotar datos manualmente, lo cual es una tarea laboriosa que requiere tomar una foto de un rostro y luego etiquetar sus rasgos a mano, los datos sintéticos se generan a gran escala, con anotaciones de base fiable integradas, como la dirección de los ojos, algo que un humano jamás podría determinar. El resultado es una anotación de datos más precisa y detallada sin el desafío de etiquetarlos manualmente.
“Estamos simulando el mundo para llevar la IA a producción de forma más rápida”, afirma Karine Regev, VP de Marketing de Datagen. “Llevar la IA a producción es en sí mismo un desafío sin resolver para la mayoría de las empresas, por lo que estamos haciendo que sea más profesional y preciso mediante la resolución de problemas como la privacidad y los sesgos en los datos, que son los mayores obstáculos de la IA moderna”.
Datagen ofrece a los clientes una plataforma de autoservicio que utiliza simulaciones 3D para entrenar sus algoritmos. “Para entrenar un modelo, se necesitan millones de imágenes diferentes”, afirma Regev. “Y justo aquí es donde encajamos nosotros. [Los clientes de Datagen] tienen la capacidad de controlar las escenas, el fondo, las diferentes modalidades, las diferentes etiquetas que necesita, la iluminación, el género, la etnia, todo”.
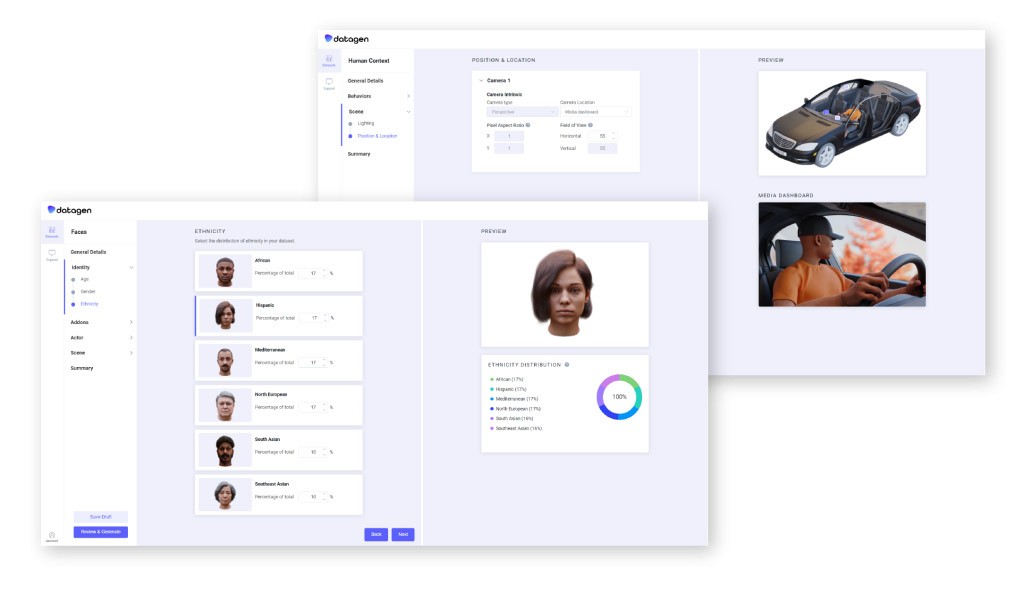
Además de generar datos diversos que parecen reales, escalables y pixel perfect, Datagen ofrece a sus clientes una confidencialidad total. “Cumple plenamente con las normas de privacidad, ya que los datos no contienen ningún tipo de información de identificación personal”, afirma Shay Navon sobre los datos sintéticos. “Nadie puede decir: ‘Utilizamos a alguien que representa un problema de privacidad’. Nuestra experiencia y nuestros datos centrados en las personas se centran en varios ámbitos, desde la detección de puntos de referencia faciales, la estimación de la mirada y el análisis de la expresión hasta las posturas completas del cuerpo humano, pasando por partes del cuerpo, como los ojos, las manos, etc.”.
En un futuro muy próximo, se predice que será más común entrenar modelos con datos sintéticos que recopilarlos de orígenes del mundo real. En consecuencia, Datagen ha crecido rápidamente y ha pasado de unos 40 empleados a casi 100 en los últimos nueve meses. “Trabajamos con algunas de las empresas de tecnología más grandes del mundo en diferentes sectores”, afirma Regev. “Resolvemos diferentes casos de uso, desde la RA, la RV y el metaverso hasta la supervisión de conductores para vehículos con cabina, así como también la seguridad del hogar y las oficinas inteligentes”.

Para satisfacer esta nueva demanda, Datagen decidió cambiar a la arquitectura en la nube. Su prioridad era escalar utilizando los últimos modelos de GPU. Tras analizar en profundidad los proveedores de servicios en la nube, la empresa recurrió a AWS, decidida a desarrollar su sistema con la tecnología de Kubernetes. Datagen diseñó un sistema de software de programación personalizado llamado Agni que se integra con Elastic Kubernetes Service (Amazon EKS) y utiliza el escalamiento automático de Kubernetes y los grupos de escalamiento automático de AWS Auto Scaling.
Agni, y toda la plataforma de generación de datos de Datagen, ahora dependen de instancias de spot de CPU y GPU, lo que ha permitido reducir los costos y crear un sistema más eficiente. Esto también permite mantener un sistema relativamente pequeño que puede crecer de forma dinámica hasta crear cientos de miles de trabajos simultáneos y reducirse en función de la demanda, lo que da como resultado una plataforma de autoservicio alojada en AWS.
De cara al futuro, el equipo de Datagen predice que la necesidad de datos sintéticos seguirá creciendo. “Estamos viendo una gran demanda, tanto en términos de crecimiento como de perspectivas, la necesidad de liderazgo intelectual, la necesidad de tecnología y una solución como la nuestra que realmente puedan sentar precedente en lo que respecta a los datos sintéticos”, afirma Regev.

AWS Editorial Team
El equipo de marketing de contenido para startups de AWS colabora con startups de todos los tamaños y sectores para ofrecer contenido excepcional que eduque, entretenga e inspire.
¿Qué le pareció este contenido?