Apache Spark için Amazon Redshift Entegrasyonu
Amazon Redshift'teki verileri okuyan ve yazan Apache Spark uygulamaları oluşturun
Neden Apache Spark için Amazon Redshift Entegrasyonu?

Amazon Redshift'in Avantajları
-
Amazon EMR, AWS Glue veya SageMaker üzerinde çalışan çeşitli analiz ve makine öğrenimi (ML) uygulamalarınızda kullanabileceğiniz veri kaynaklarının kapsamını okuyup veri ambarına yazarak genişletin.
-
Onaylanmamış bağlayıcıların ve JDBC sürücülerinin zahmetli ve genellikle manuel olan kurulum sürecini kolaylaştırıp analiz ve makine öğrenimi görevlerindeki hazırlık süresini düşürün.
-
Amazon Redshift veri ambarından yalnızca ilgili verilerin taşınması adına sıralama, toplama, sınırlama, birleştirme ve ölçülebilir işlevler gibi birkaç yığınsal özellik kullanın.
Nasıl çalışır?
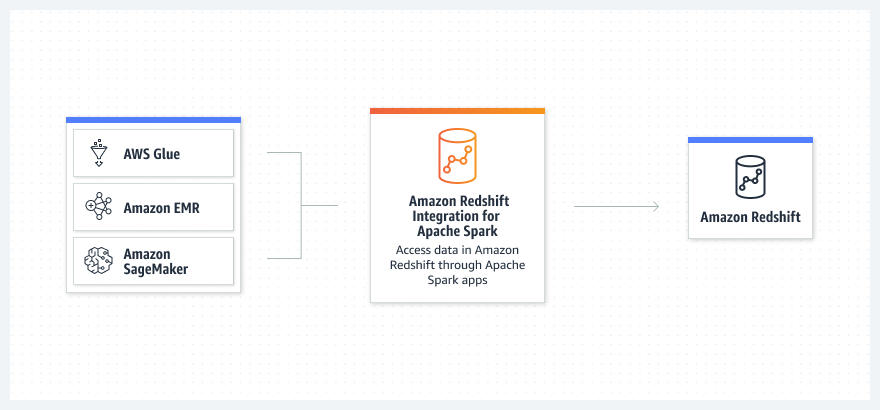
Kullanım örnekleri
-
Apache Spark tabanlı AWS analiz hizmetleriyle Java, Scala ve Python üzerinde Apache Spark uygulamaları oluşturun.
-
Amazon EMR, AWS Glue, SageMaker, AWS analiz ve ML hizmetleriyle Amazon Redshift üzerinde veri okuyup yazın.
-
Apache Spark işi veya not defterinizden veri çerçevesi kodu almak ve Amazon Redshift'e bağlanmak üzere Amazon EMR ya da AWS Glue kullanın.
-
Performans için kurulum, test ve gelişmiş güvenlik (IAM tabanlı kimlik bilgileri), işlevsel yığınlar ve Parquet dosya formatı olmadan süreci kolaylaştırın.
Müşteriler
Corey Johnson, Veri Mimarı Yöneticisi - Huron Consulting
Huron, sağlam stratejiler oluşturmak, operasyonları optimize etmek, dijital dönüşümü hızlandırmak, işletme ve çalışanların geleceklerini kurmak adına onları güçlendirmek üzere mümkün olan imkanları hayata geçirmek için müşterilerle iş birliği yapan küresel bir profesyonel hizmet firmasıdır.
"Mühendislerimize Python ve Scala kullanarak Apache Spark ile kendi veri hat ve uygulamalarını oluşturma imkanı tanıyoruz. Operasyonları basitleştiren ve müşterilerimiz için daha hızlı ve verimli bir şekilde teslim eden özel bir çözüm istemiştik ve yeni Apache Spark için Amazon Redshift Entegrasyonu sayesinde bunu başardık.”
Alcuin Weidus, Kıdemli Veri Mimarı Sorumlusu - GE Aerospace
GE Aerospace, ticari ve askeri uçaklar için küresel bir jet motoru, bileşeni ve sistemi sağlayıcısıdır. Şirket, Birinci Dünya Savaşı'ndan günümüze jet motorları tasarlayıp, geliştirip üretmektedir.
"GE Aerospace, önemli iş kararlarını yönlendiren kritik iş öngörülerini gerçekleştirmek üzere AWS analizi ve Amazon Redshift kullanmaktadır. Amazon S3'ten otomatik kopyalama desteğiyle, verileri Amazon S3'ten Amazon Redshift'e taşımak üzere daha basit veri hatları oluşturabiliyoruz. Böylece veri ürünü ekiplerimizin verilere erişme ve son kullanıcılara öngörü sağlama özellikleri de hızlanmaktadır. Verilerle değer katmak adına daha fazla, entegrasyon için daha az zaman harcıyoruz.”
Neema Raphael, Baş Veri Sorumlusu - Goldman Sachs
Goldman Sachs Group, Inc.; şirket, finansal kurum, hükümet ve bireyleri kapsayan geniş ve çeşitlendirilmiş bir müşteri tabanına yatırım bankacılığı, menkul kıymetler, yatırım yönetimi ve tüketici bankacılığı genelinde geniş bir finansal hizmet yelpazesi sunan lider bir küresel finans kurumudur.
"Odak noktamız, Goldman Sachs bünyesindeki tüm kullanıcılarımızın verilere bireysel olarak erişmelerini sağlamaktır. Bir açık kaynaklı veri yönetimi ve yönetişim platformu olan Legend adlı platformumuz aracılığıyla, finansal hizmetler sektöründe işbirliği yaparken kullanıcıların veri merkezli uygulamalar geliştirmelerine ve veri odaklı öngörüler elde etmelerine olanak tanıyoruz. Apache Spark için Amazon Redshift Entegrasyonuyla veri platformu ekibimiz, sıfır kodlu ETL'ye izin vererek Amazon Redshift verilerine küçücük manuel adımlarla erişebilecek ve mühendislerin eksiksiz ve zamanında bilgi toplarken iş akışlarını en iyileştirmeye odaklanmalarını kolaylaştırma yetimizi artıracaktır. Kullanıcılarımız artık Amazon Redshift son verilerine kolayca erişebildiğinden, uygulama performanslarında artış ve gelişmiş güvenlik görmeyi bekliyoruz."
Kaynaklar
Bugün aradığınızı buldunuz mu?
Sayfalarımızdaki içeriğin kalitesini artırabilmemiz için bize görüşlerinizi bildirin