AWS News Blog
Amazon Polly Update – Time-Driven Prosody and Asynchronous Synthesis

|
I hope that you are enjoying the Polly-powered audio that is available for the newest posts on this blog, including the DeepLens Challenge and the Storage Gateway Recap. As part of my blogging process, I now listen to the synthesized speech for my draft blog posts in order to get a better sense for how they flow.
Today we are launching two new features for Amazon Polly:
Time-Driven Prosody – You can now specify the desired duration for the synthesized speech that corresponds to part or all of the input text.
Asynchronous Synthesis – You can now process large blocks of text and store the synthesized speech in Amazon S3 with a single call.
Both of these features are available now and you can start using them today. Let’s take a closer look!
Time-Driven Prosody
Imagine that you are creating a multi-lingual version of a video or a self-running presentation. You write the script, record the video in one language, and then use Amazon Translate and Amazon Polly to create audio tracks in other languages. In order to keep each language in sync with the visual content, you need to exercise fine-grained control over the duration of each segment. That’s where this new feature comes in. You can now specify the maximum desired duration for any desired segments, counting on Polly to adjust the speech rate in order to limit the length of each segment.
The preceding paragraph generates 19 seconds of audio if I use Amazon Polly’s Joanna voice with no other options:
I can use a <prosody> tag to limit the length to 15 seconds:
I can control the duration at a more fine-grained level by using multiple <prosody> tags:
The Spanish equivalent (courtesy of Amazon Translate) of my English text is somewhat longer and the speed-up is apparent:
The text inside of each time-limited <prosody> tag is limited to 1500 characters and nesting is not allowed (the inner tag will be ignored). In order to ensure that the audio remains comprehensible, Polly will speed up the audio by a maximum of 5x.
Asynchronous Synthesis
This feature makes it easier for you to use Polly to generate speech for long-form content such as articles or book chapters by allowing you to process up to 100,000 characters of text at a time using asynchronous requests. The synthesized speech is delivered to the S3 bucket of your choice, with failure notifications optionally routed to the Amazon Simple Notification Service (Amazon SNS) topic of your choice. The generated audio can be up to 6 hours long, and is typically ready within minutes. In addition to 100,000 characters of text, each request can include an additional 100,000 characters of Speech Synthesis Markup Language (SSML) markup.
Each asynchronous request creates a new speech synthesis task. You can initiate and manage tasks from the Polly Console, CLI (start-speech-synthesis-task), or API (StartSpeechSynthesisTask).
To test this feature I created a plain-text version of my thoroughly obsolete AWS book and inserted some SSML tags, turning it in to valid XML along the way. Then I open the Polly Console, click Text-to-Speech, paste the XML, and click Synthesize to S3:
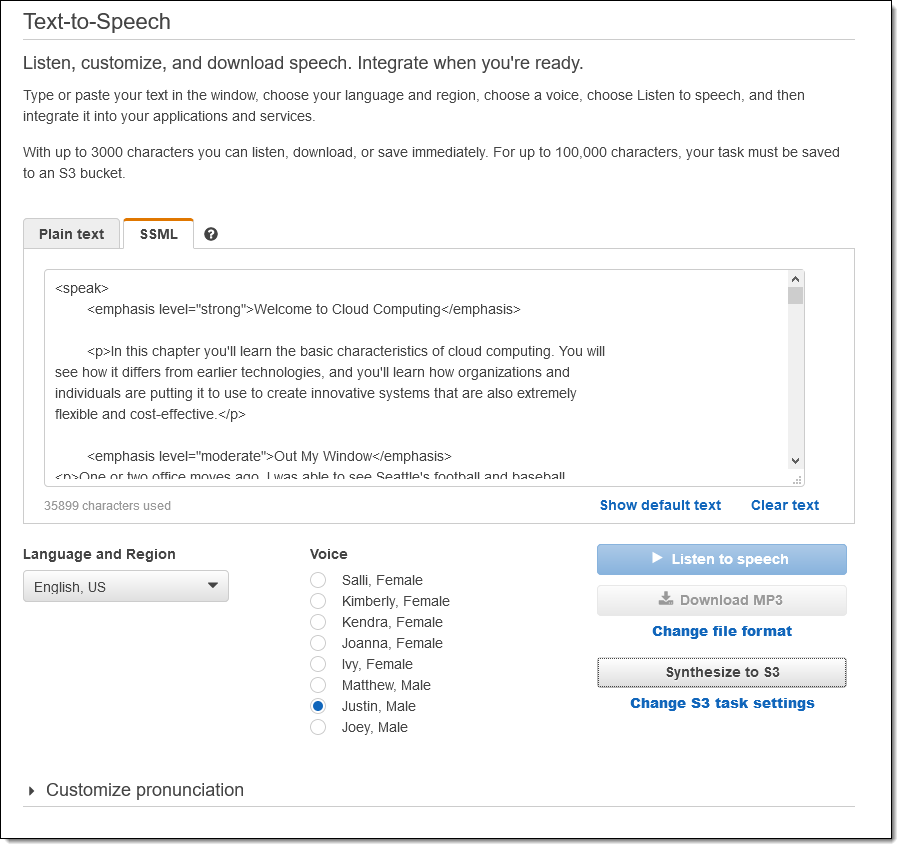
I enter the name of my S3 bucket (which must be in region where I plan to create the task), and click Synthesize to proceed:
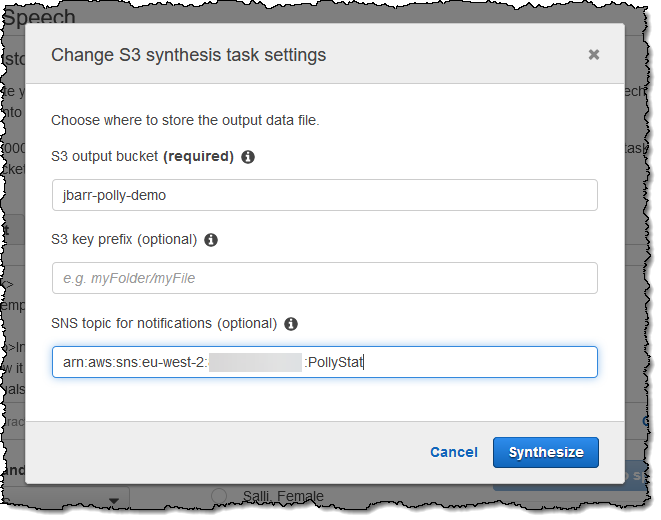
My task is created:
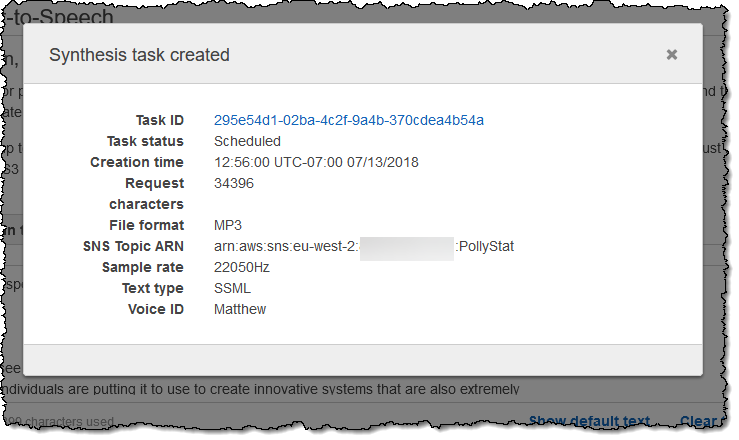
And I can see it in the list of tasks:
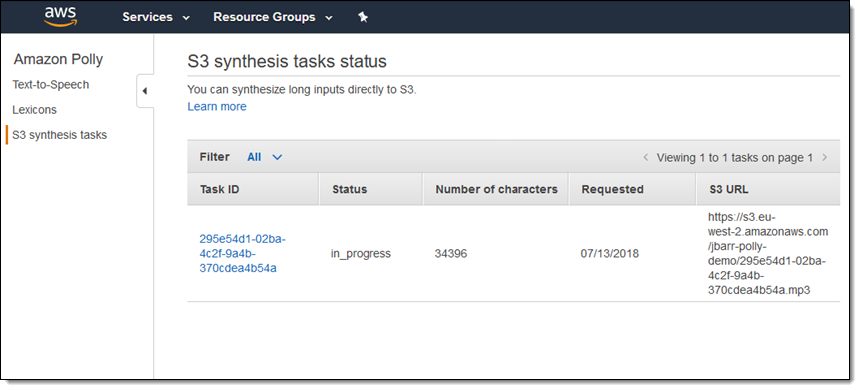
I receive an email when the synthesis is complete:
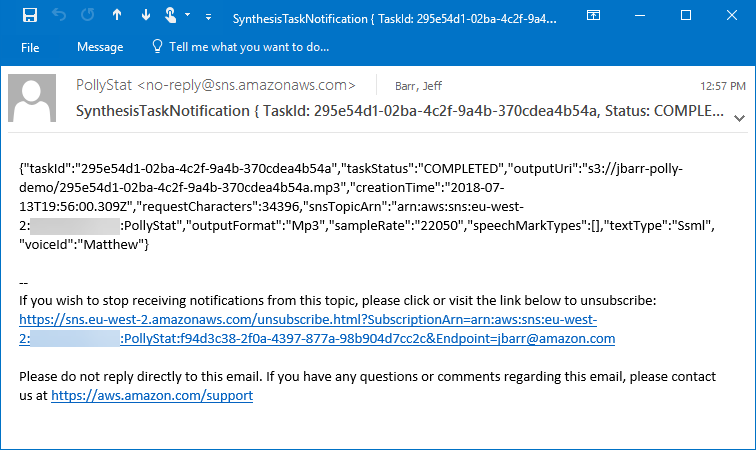
And the file is in my bucket as expected:
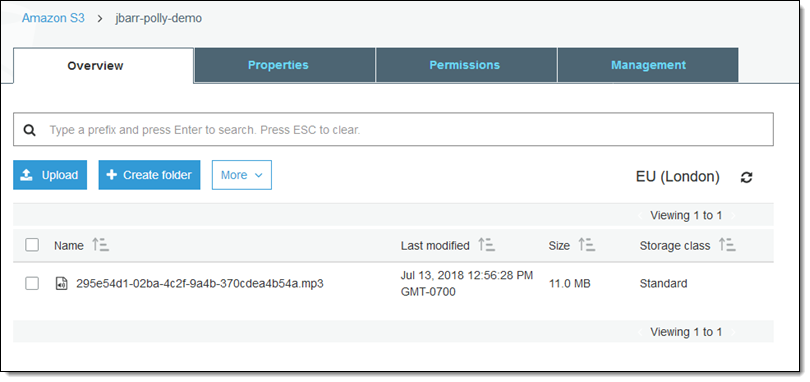
I did not spend a lot of time on the markup, but the results are impressive:
Interestingly enough, most of that chapter is still relevant. The rest of the book has been overtaken by history, and is best left there! Perhaps I’ll write another one sometime.
Anyway, as you can see (and hear) the asynchronous speech synthesis is powerful and easy to use. Give it a shot, build something cool, and tell me about it.
— Jeff;