AWS Architecture Blog
Best Practices for Developing on AWS Lambda
In our previous post we discussed the various ways you can invoke AWS Lambda functions. In this post, we’ll provide some tips and best practices you can use when building your AWS Lambda functions.
One of the benefits of using Lambda, is that you don’t have to worry about server and infrastructure management. This means AWS will handle the heavy lifting needed to execute your Lambda functions. You should take advantage of this architecture with the tips below.
Tip #1: When to VPC-Enable a Lambda Function
Lambda functions always operate from an AWS-owned VPC. By default, your function has full ability to make network requests to any public internet address — this includes access to any of the public AWS APIs. For example, your function can interact with AWS DynamoDB APIs to PutItem or Query for records. You should only enable your functions for VPC access when you need to interact with a private resource located in a private subnet. An RDS instance is a good example.
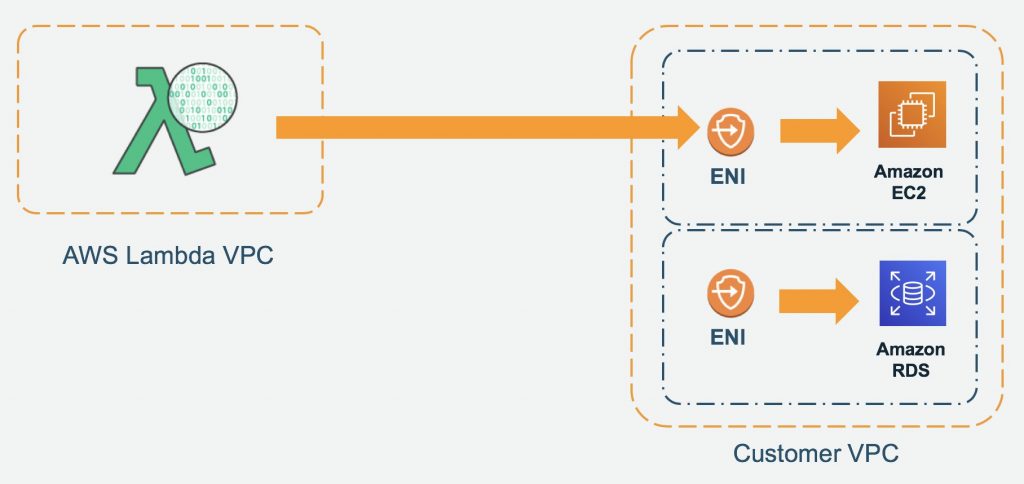
Once your function is VPC-enabled, all network traffic from your function is subject to the routing rules of your VPC/Subnet. If your function needs to interact with a public resource, you will need a route through a NAT gateway in a public subnet.
Tip #2: Deploy Common Code to a Lambda Layer (i.e. the AWS SDK)
If you intend to reuse code in more than one function, consider creating a Layer and deploying it there. A great candidate would be a logging package that your team is required to standardize on. Another great example is the AWS SDK. AWS will include the AWS SDK for NodeJS and Python functions (and update the SDK periodically). However, you should bundle your own SDK and pin your functions to a version of the SDK you have tested.
Tip #3: Watch Your Package Size and Dependencies
Lambda functions require you to package all needed dependencies (or attach a Layer) — the bigger your deployment package, the slower your function will cold-start. Remove all unnecessary items, such as documentation and unused libraries. If you are using Java functions with the AWS SDK, only bundle the module(s) that you actually need to use — not the entire SDK.
Good:
<dependency> <groupId>software.amazon.awssdk</groupId> <artifactId>dynamodb</artifactId> <version>2.6.0</version> </dependency>
Bad:
<!-- https://mvnrepository.com/artifact/software.amazon.awssdk/aws-sdk-java --> <dependency> <groupId>software.amazon.awssdk</groupId> <artifactId>aws-sdk-java</artifactId> <version>2.6.0</version> </dependency>
Tip #4: Monitor Your Concurrency (and Set Alarms)
Our first post in this series talked about how concurrency can effect your down stream systems. Since Lambda functions can scale extremely quickly, this means you should have controls in place to notify you when you have a spike in concurrency. A good idea is to deploy a CloudWatch Alarm that notifies your team when function metrics such as ConcurrentExecutions or Invocations exceeds your threshold. You should create an AWS Budget so you can monitor costs on a daily basis. Here is a great example of how to set up automated cost controls.
Tip #5: Over-Provision Memory (in some use cases) but Not Function Timeout
Lambda allocates compute power in proportion to the memory you allocate to your function. This means you can over provision memory to run your functions faster and potentially reduce your costs. You should benchmark your use case to determine where the breakeven point is for running faster and using more memory vs running slower and using less memory.
However, we recommend you do not over provision your function time out settings. Always understand your code performance and set a function time out accordingly. Overprovisioning function timeout often results in Lambda functions running longer than expected and unexpected costs.