AWS Architecture Blog
Increasing McGraw-Hill’s Application Throughput with Amazon SQS
This post was co-authored by Vikas Panghal, Principal Product Mgr – Tech, AWS and Nick Afshartous, Principal Data Engineer at McGraw-Hill
McGraw-Hill’s Open Learning Solutions (OL) allow instructors to create online courses using content from various sources, including digital textbooks, instructor material, open educational resources (OER), national media, YouTube videos, and interactive simulations. The integrated assessment component provides instructors and school administrators with insights into student understanding and performance.
Within OL, the performance reports module allows administrators to generate reports showing the performance of different learner populations. McGraw-Hill measures performance report processing by observing throughput, which is the amount of work done by an application in a given period. McGraw-Hill worked with AWS to ensure OL continues to run smoothly and to allow it to scale with the organization’s growth. This blog post shows how we reviewed and refined their architecture of learning performance reports by incorporating Amazon Simple Queue Service (Amazon SQS). to achieve better throughput and stability.
Reviewing the original performance reports architecture
Figure 1 shows the OL original architecture, which works as follows:
- The application makes a REST call to DMAPI. DMAPI is an API layer over the Datamart. The call results in a row being inserted in a job requests table in Postgres.
- A monitoring process called Watchdog periodically checks the database for pending requests.
- Watchdog spins up an Apache Spark on Databricks (Spark) cluster and passes up to 10 requests.
- The report is processed and output to Amazon Simple Storage Service (Amazon S3).
- Report status is set to completed.
- User can view report.
- The Databricks clusters shut down.
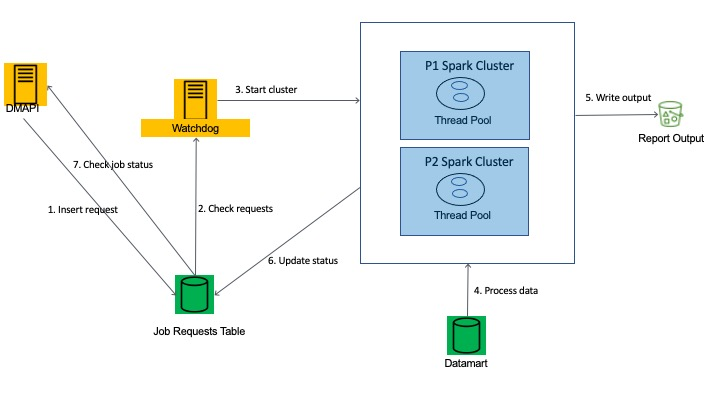
Figure 1. Original OL architecture
To help isolate longer running reports, we separated requests that have up to five schools (P1) from those having more than five (P2) by allocating a different pool of clusters. Each of the two groups can have up to 70 clusters running concurrently.
Challenges with original architecture
There are several challenges inherent in this original architecture, and we concluded that this architecture will fail under heavy load.
It takes 5 minutes to spin up a Spark cluster. After processing up to 10 requests, each cluster shuts down. Pending requests are processed by new clusters. This results in many clusters continuously being cycled.
We also identified a database resource contention problem. In testing, we couldn’t process 142 reports out of 2,030 simulated reports within the allotted 4 hours. Furthermore, the architecture cannot be scaled out beyond 70 clusters for the P1 and P2 pools. This is because adding more clusters will increase the number of database connections. Other production workloads on Postgres would also be affected.
Refining the architecture with Amazon SQS
To address the challenges with the existing architecture, we rearchitected the pipeline using Amazon SQS. Figure 2 shows the revised architecture. In addition to inserting a row to the requests table, the API call now inserts the job request Id into one of the SQS queues. The corresponding SQS consumers are embedded in the Spark clusters.

Figure 2. New OL architecture with Amazon SQS
The revised flow is as follows:
- An API request results in a job request Id being inserted into one of the queues and a row being inserted into the requests table.
- Watchdog monitors SQS queues.
- Pending requests prompt Watchdog to spin up a Spark cluster.
- SQS consumer consumes the messages.
- Report data is processed.
- Report files output to Amazon S3
- Job status is updated in the requests table.
- Report can be viewed in the application.
After deploying the Amazon SQS architecture, we reran the previous load of 2,030 reports with a configuration ceiling of up to five Spark clusters. This time all reports were completed within the 4-hour time limit, including the 142 reports that timed out previously. Not only did we achieve better throughput and stability, but we did so by running far fewer clusters.
Reducing the number of clusters reduced the number of concurrent database connections that access Postgres. Unlike the original architecture, we also now have room to scale by adding more clusters and consumers. Another benefit of using Amazon SQS is a more loosely coupled architecture. The Watchdog process now only prompts Spark clusters to spin up, whereas previously it had to extract and pass job requests Ids to the Spark job.
Consumer code and multi-threading
The following code snippet shows how we consumed the messages via Amazon SQS and performed concurrent processing. Messages are consumed and submitted to a thread pool that utilizes Java’s ThreadPoolExecutor for concurrent processing. The full source is located on GitHub.
/**
* Main Consumer run loop performs the following steps:
* 1. Consume messages
* 2. Convert message to Task objects
* 3. Submit tasks to the ThreadPool
* 4. Sleep based on the configured poll interval.
*/
def run(): Unit = {
while (!this.shutdownFlag) {
val receiveMessageResult = sqsClient.receiveMessage(new
ReceiveMessageRequest(queueURL)
.withMaxNumberOfMessages(threadPoolSize))
val messages = receiveMessageResult.getMessages
val tasks = getTasks(messages.asScala.toList)
threadPool.submitTasks(tasks, sqsConfig.requestTimeoutMinutes)
Thread.sleep(sqsConfig.pollIntervalSeconds * 1000)
}
threadPool.shutdown()
}
Kafka versus Amazon SQS
We also considered routing the report requests via Kafka, because Kafka is part of our analytics platform. However, Kafka is not a queue, it is a publish-subscribe streaming system with different operational semantics. Unlike queues, Kafka messages are not removed by the consumer. Publish-subscribe semantics can be useful for data processing scenarios. In other words, it can be used in cases where it’s required to reprocess data or to transform data in different ways using multiple independent consumers.
In contrast, for performing tasks, the intent is to process a message exactly once. There can be multiple consumers, and with queue semantics, the consumers work together to pull messages off the queue. Because report processing is a type of task execution, we decided that SQS queue semantics better fit the use case.
Conclusion and future work
In this blog post, we described how we reviewed and revised a report processing pipeline by incorporating Amazon SQS as a messaging layer. Embedding SQS consumers in the Spark clusters resulted in fewer clusters and more efficient cluster utilization. This, in turn, reduced the number of concurrent database connections accessing Postgres.
There are still some improvements that can be made. The DMAPI call currently inserts the report request into a queue and the database. In case of an error, it’s possible for the two to become out of sync. In the next iteration, we can have the consumer insert the request into the database. Hence, the DMAPI call would only insert the SQS message.
Also, the Java ThreadPoolExecutor API being used in the source code exhibits the slow poke problem. Because the call to submit the tasks is synchronous, it will not return until all tasks have completed. Here, any idle threads will not be utilized until the slowest task has completed. There’s an opportunity for improved throughput by using a thread pool that allows idle threads to pick up new tasks.
Ready to get started? Explore the source code illustrating how to build a multi-threaded AWS SQS consumer.
Looking for more architecture content? AWS Architecture Center provides reference architecture diagrams, vetted architecture solutions, Well-Architected best practices, patterns, icons, and more!
Acknowledgements
We’d like to thank the following colleagues at McGraw-Hill Education for their participation in discussions, review, and testing leading up to the production deployment: Andy Winslow, Vineetha Raghavendra, Kapil Shrivastava, and Boris Slavin.