AWS Architecture Blog
Category: Customer Solutions

Prioritize your AWS Health alerts using AWS User Notifications
If you run critical workloads on AWS, such as a contact center on Amazon Connect Customer, database workloads on Amazon Relational Database Service (Amazon RDS), or hybrid connectivity through AWS Direct Connect, service health events demand your attention. But not all events are equal. An operational issue, a scheduled maintenance window, and a deprecation notice […]

Unlocking the future of video data: March Networks cloud storage on AWS
Enterprise video surveillance is operating at an unprecedented scale as organizations across retail, banking, quick-service restaurants (QSR), convenience stores, and transportation networks generate petabytes of video data across thousands of distributed locations. As retention requirements grow and organizations seek to extract more operational insights from video, traditional on-premise storage models are becoming increasingly difficult and […]

Lessons learned from scaling to 1 million Lambda functions
In this post, we share our journey and the lessons learned from building and running a fully serverless, multi-account software as a service (SaaS) platform at scale. We’ll explore why true scale-to-zero is critical, how we handle quota management, why engaging AWS service teams early saved us from outages, and which unexpected practices emerged once we scaled from thousands to over a million functions.

Preventing data exfiltration in machine learning environments with Amazon SageMaker AI
In this post, we demonstrate how iBusiness implemented a three-layered security architecture using Amazon SageMaker AI, virtual private cloud (VPC) endpoints, and Amazon WorkSpaces Secure Browser to prevent data exfiltration while maintaining data scientist productivity. You can adapt this approach to build secure machine learning environments that balance strict data protection with team scalability.

Reducing SMS OTP fraud with Vonage network-powered solutions and Amazon Cognito
In this post, we show how Vonage network-powered solutions work with Amazon Cognito to enhance many mobile-first use cases with network-level identity verification. Vonage network-powered solutions are a composable stack of real-time mobile operator intelligence, silent authentication, and integrated fraud protection, which uses the CUSTOM_AUTH flow to complete identity verification in under 5 seconds, with zero user interaction.

How Samsung achieved real-time pricing with AWS Lambda Response Streaming
In this post, we walk through the legacy architecture challenges, the stateless streaming solution, key implementation patterns, and performance results—a pattern you can apply if you’re building high-traffic APIs that aggregate data from multiple backend sources.

Building highly available Oracle databases with Amazon FSx for NetApp ONTAP
This post shows how to build a highly available Oracle database architecture using FSxN shared storage, Auto Scaling groups with dynamic AMI updates, and serverless orchestration to help reduce recovery times with current configurations.

Automating contract intelligence with Doczy.ai™ on AWS
In this post, we show you how Doczy.ai™ uses generative AI on AWS to automate contract intelligence at scale, transforming unstructured documents into structured, actionable insights, so organizations can automate critical business processes and unlock the full value of their data.

Scaling oncology patient support: How New York Cancer and Blood Specialists transformed customer experience with AWS and Pronetx, now part of Caylent
This post details how NYCBS partnered with Amazon Web Services (AWS) and AWS partner Pronetx (now part of Caylent) to migrate to Amazon Connect Customer, the AWS cloud contact center service. The migration delivered a 54 percent improvement in patient enrollment and transformed the way NYCBS connects with the patients who need them most.
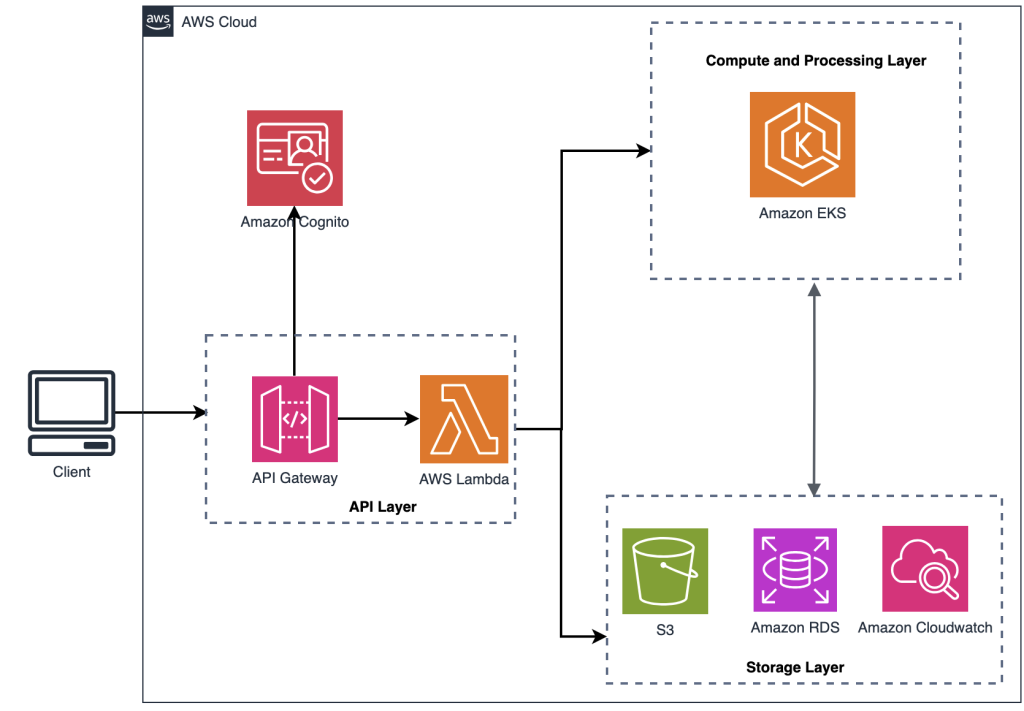
How ALS GeoAnalytics LITHOLENS ™ revolutionizes core logging through machine learning with Amazon EKS
This post explores how ALS GeoAnalytics successfully deployed LITHOLENS ™ with Amazon Elastic Kubernetes Service (Amazon EKS) to scale model training and inference while minimizing cost.