AWS Architecture Blog
Category: Amazon SageMaker

Architecting offline-first generative AI applications for edge deployments using AWS services
According to Siemens’ 2024 report The True Cost of Downtime, Fortune 500 companies lose an estimated $1.4 trillion annually because of unplanned downtime. This downtime is often worsened by a lack of skills to detect and resolve issues quickly. Generative AI offers a promising path to address this, but deploying these capabilities in industrial environments […]

How Mapfre Insurance modernized fraud claims with Amazon EMR Serverless
Insurance fraud remains a significant challenge for the insurance industry because fraudulent claims can increase loss costs, reduce trust, and consume investigation capacity that could otherwise be focused on serving customers. Traditional fraud detection approaches typically rely on rules-based controls, manual investigation triggers, historical claim patterns, and structured-data-only analysis. These approaches are useful for known […]

Preventing data exfiltration in machine learning environments with Amazon SageMaker AI
In this post, we demonstrate how iBusiness implemented a three-layered security architecture using Amazon SageMaker AI, virtual private cloud (VPC) endpoints, and Amazon WorkSpaces Secure Browser to prevent data exfiltration while maintaining data scientist productivity. You can adapt this approach to build secure machine learning environments that balance strict data protection with team scalability.

Unlock efficient model deployment: Simplified Inference Operator setup on Amazon SageMaker HyperPod
In this post, we walk through the new installation experience, demonstrate three deployment methods (console, CLI, and Terraform), and show how features like multi-instance-type deployment and native node affinity give you fine-grained control over inference scheduling

Automate safety monitoring with computer vision and generative AI
This post describes a solution that uses fixed camera networks to monitor operational environments in near real-time, detecting potential safety hazards while capturing object floor projections and their relationships to floor markings. While we illustrate the approach through distribution center deployment examples, the underlying architecture applies broadly across industries. We explore the architectural decisions, strategies for scaling to hundreds of sites, reducing site onboarding time, synthetic data generation using generative AI tools like GLIGEN, and other critical technical hurdles we overcame.
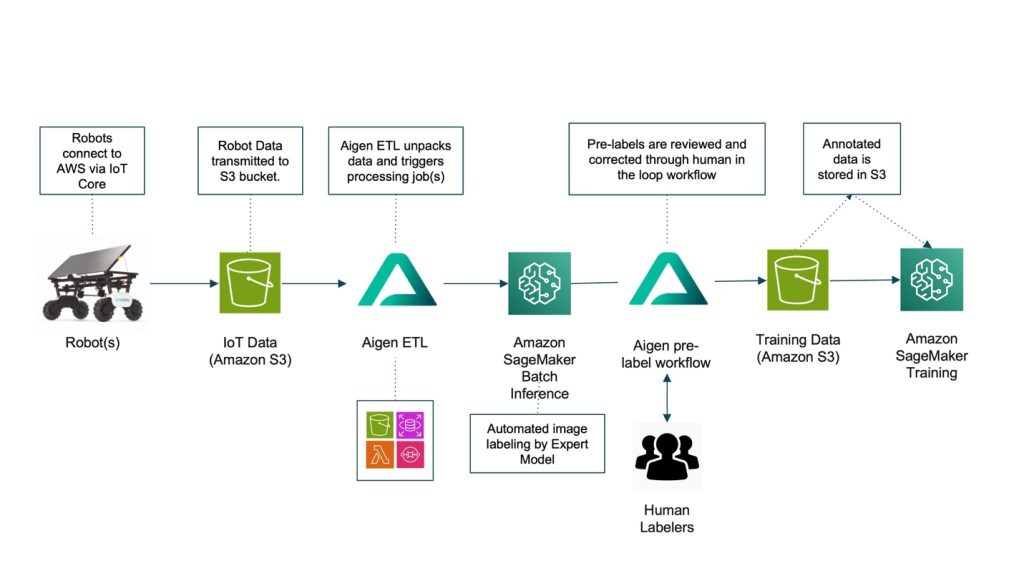
How Aigen transformed agricultural robotics for sustainable farming with Amazon SageMaker AI
In this post, you will learn how Aigen modernized its machine learning (ML) pipeline with Amazon SageMaker AI to overcome industry-wide agricultural robotics challenges and scale sustainable farming. This post focuses on the strategies and architecture patterns that enabled Aigen to modernize its pipeline across hundreds of distributed edge solar robots and showcase the significant business outcomes unlocked through this transformation. By adopting automated data labeling and human-in-the-loop validation, Aigen increased image labeling throughput by 20x while reducing image labeling costs by 22.5x.

Optimizing fleet operations using Amazon SageMaker AI and Amazon Bedrock
In this post, we’ll explore how to maximize the value of dashcam footage through best practices for implementing and managing Computer Vision systems in commercial fleet operations. We’ll demonstrate how to build and deploy edge-based machine learning models that provide real-time alerts for distracted driving behaviors, while effectively collecting, processing, and analyzing footage to train these AI models.

Training a call center fraud detection model for IVR calls with Amazon SageMaker Canvas
This blog post will show you how to use the power of ML to build a fraud-detection model using Amazon SageMaker Canvas, a no-code/low-code ML service that business analysts and domain experts can use to build, train, and deploy ML models without requiring extensive ML expertise.

Use generative AI on AWS for efficient clinical document analysis
In this post, we show how Clario uses the AWS platform to accelerate clinical document analysis.

Top Architecture Blog Posts of 2024
Well, it’s been another historic year! We’ve watched in awe as the use of real-world generative AI has changed the tech landscape, and while we at the Architecture Blog happily participated, we also made every effort to stay true to our channel’s original scope, and your readership this last year has proven that decision was […]