AWS Architecture Blog
Category: Amazon FSx for Lustre

Designing a hybrid AI/ML data access strategy with Amazon SageMaker
Over time, many enterprises have built an on-premises cluster of servers, accumulating data, and then procuring more servers and storage. They often begin their ML journey by experimenting locally on their laptops. Investment in artificial intelligence (AI) is at a different stage in every business organization. Some remain completely on-premises, others are hybrid (both on-premises […]

Genomics workflows, Part 5: automated benchmarking
Launching and running genomics workflows can take hours and involves large pools of compute instances that process data at a petabyte scale. Benchmarking helps you evaluate workflow performance and discover faster and cheaper ways of running them. In practice, performance evaluations happen irregularly because of the associated heavy lifting. In this blog post, we discuss […]
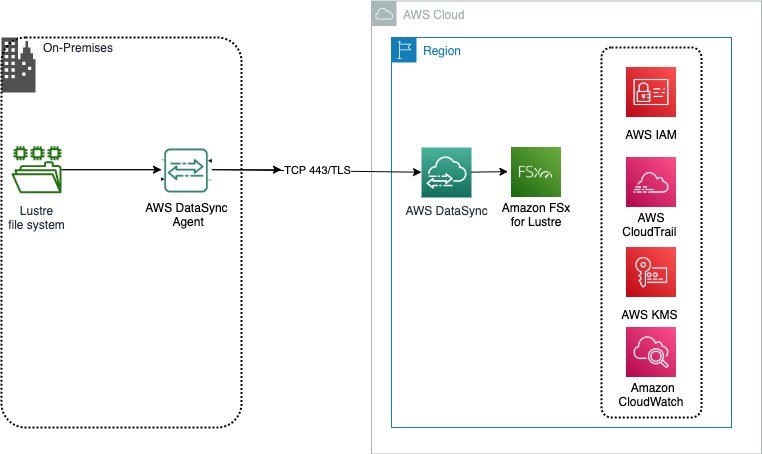
Migrating petabytes of data from on-premises file systems to Amazon FSx for Lustre
For International Women’s Day and Women’s History Month, we’re featuring more than a week’s worth of posts that highlight female builders and leaders. We’re showcasing women in the industry who are building, creating, and, above all, inspiring, empowering, and encouraging everyone—especially women and girls—in tech. Many organizations use the Lustre filesystem for Linux-based applications that […]
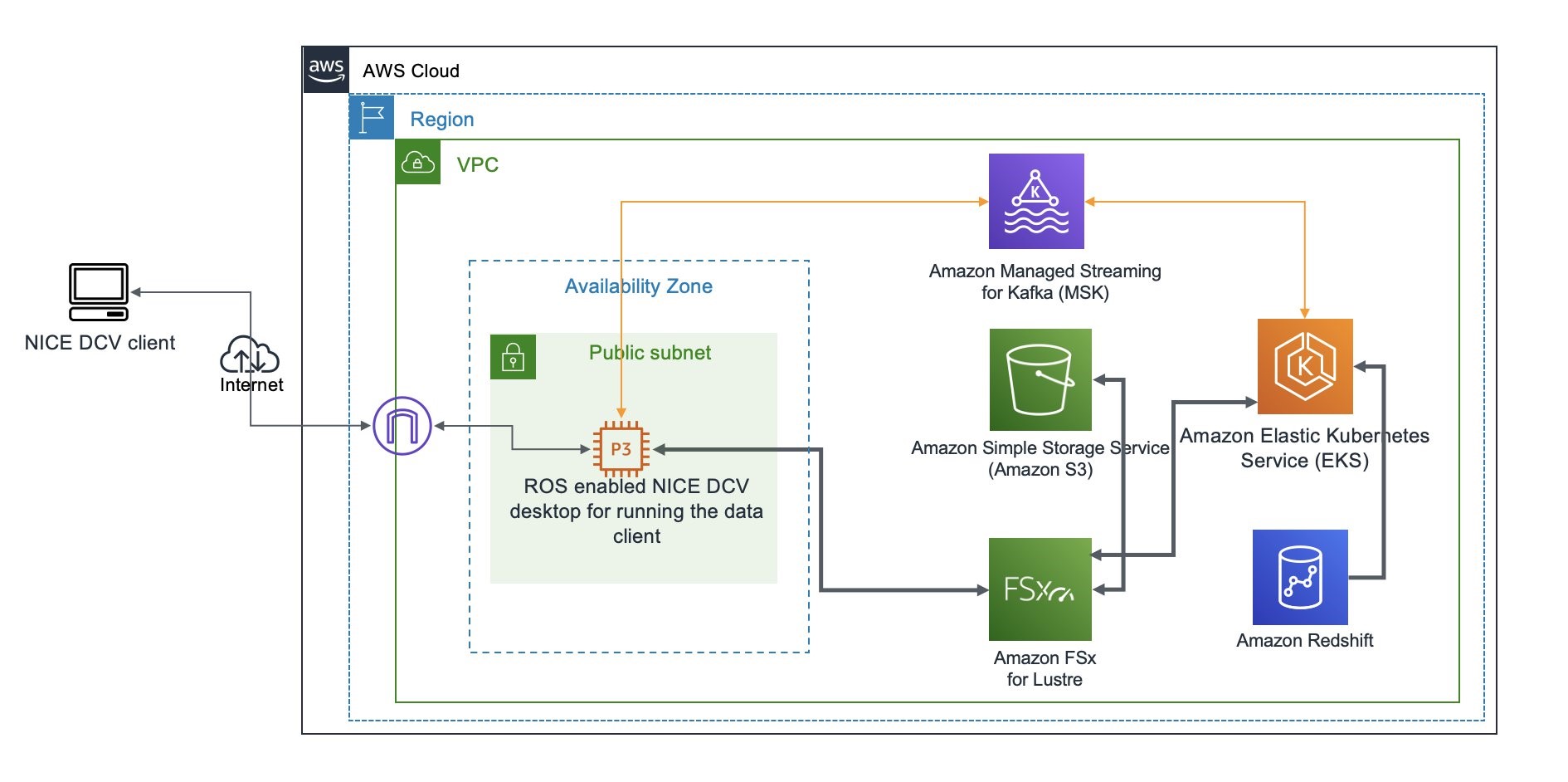
Field Notes: Building a Data Service for Autonomous Driving Systems Development using Amazon EKS
Many aspects of autonomous driving (AD) system development are based on data that capture real-life driving scenarios. Therefore, research and development professionals working on AD systems need to handle an ever-changing array of interesting datasets composed from the real-life driving data. In this blog post, we address a key problem in AD system development, which […]