AWS Architecture Blog
Category: Amazon DynamoDB
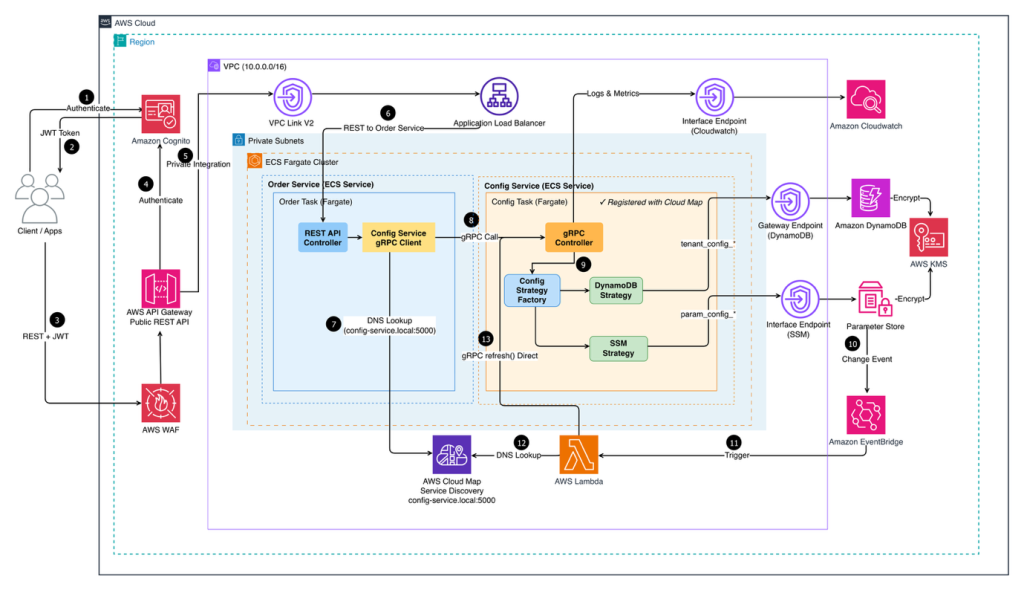
Build a multi-tenant configuration system with tagged storage patterns
In this post, we demonstrate how you can build a scalable, multi-tenant configuration service using the tagged storage pattern, an architectural approach that uses key prefixes (like tenant_config_ or param_config_) to automatically route configuration requests to the most appropriate AWS storage service. This pattern maintains strict tenant isolation and supports real-time, zero-downtime configuration updates through event-driven architecture, alleviating the cache staleness problem.
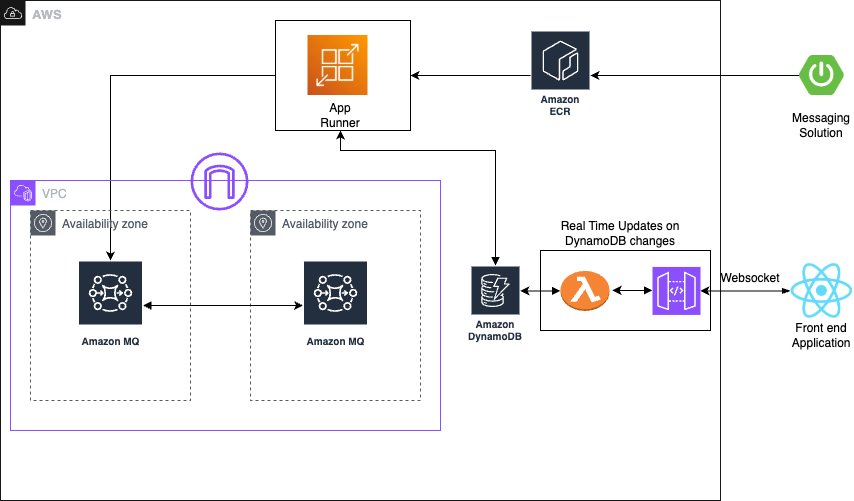
Build priority-based message processing with Amazon MQ and AWS App Runner
In this post, we show you how to build a priority-based message processing system using Amazon MQ for priority queuing, Amazon DynamoDB for data persistence, and AWS App Runner for serverless compute. We demonstrate how to implement application-level delays that high-priority messages can bypass, create real-time UIs with WebSocket connections, and configure dual-layer retry mechanisms for maximum reliability.
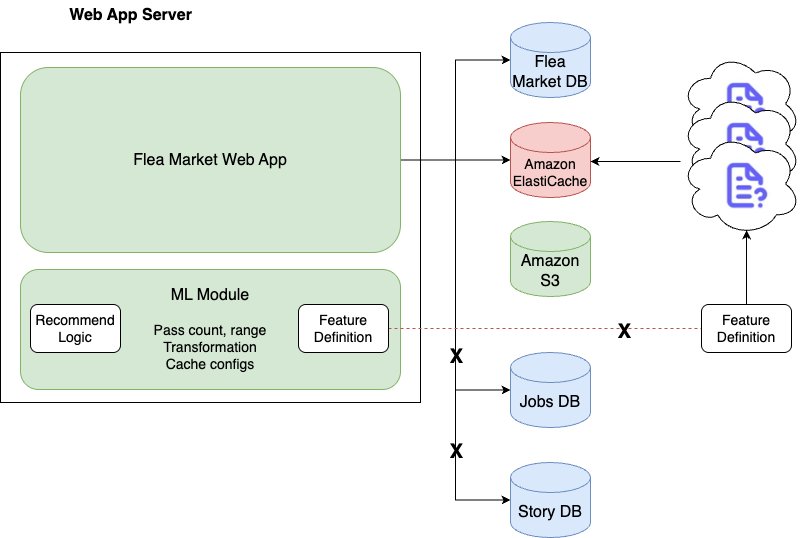
How Karrot built a feature platform on AWS, Part 1: Motivation and feature serving
This two-part series shows how Karrot developed a new feature platform, which consists of three main components: feature serving, a stream ingestion pipeline, and a batch ingestion pipeline. This post starts by presenting our motivation, our requirements, and the solution architecture, focusing on feature serving.

How UNiDAYS achieved AWS Region expansion in 3 weeks
In this post, we share how UNiDAYS achieved AWS Region expansion in just 3 weeks using AWS services.

From virtual machine to Kubernetes to serverless: How dacadoo saved 78% on cloud costs and automated operations
In this post, we walk you step-by-step through dacadoo’s journey of embracing managed services, highlighting their architectural decisions as we go.

Build an enterprise API management solution using Amazon API Gateway
This blog post shows how you can use Amazon API Gateway—along with AWS Lambda, Amazon DynamoDB, and other AWS services—to create a comprehensive and customizable APIM solution. This solution addresses the complex requirements of large enterprises managing APIs at scale.

Top Architecture Blog Posts of 2024
Well, it’s been another historic year! We’ve watched in awe as the use of real-world generative AI has changed the tech landscape, and while we at the Architecture Blog happily participated, we also made every effort to stay true to our channel’s original scope, and your readership this last year has proven that decision was […]

Let’s Architect! Serverless developer experience in AWS
Accelerate your serverless feedback loop with game-changing AWS developer tools: generate tests with AI, visualize DynamoDB schemas locally, optimize Lambda memory, and more—all within a streamlined local IDE experience.

How Wesfarmers Health implemented upstream event buffering using Amazon SQS FIFO
Customers of all sizes and industries use Software-as-a-Service (SaaS) applications to host their workloads. Most SaaS solutions take care of maintenance and upgrades of the application for you, and get you up and running in a relatively short timeframe. Why spend time, money, and your precious resources to build and maintain applications when this could […]

Tenant portability: Move tenants across tiers in a SaaS application
In today’s fast-paced software as a service (SaaS) landscape, tenant portability is a critical capability for SaaS providers seeking to stay competitive. By enabling seamless movement between tiers, tenant portability allows businesses to adapt to changing needs. However, manual orchestration of portability requests can be a significant bottleneck, hindering scalability and requiring substantial resources. As […]