AWS Architecture Blog
Category: Amazon Machine Learning
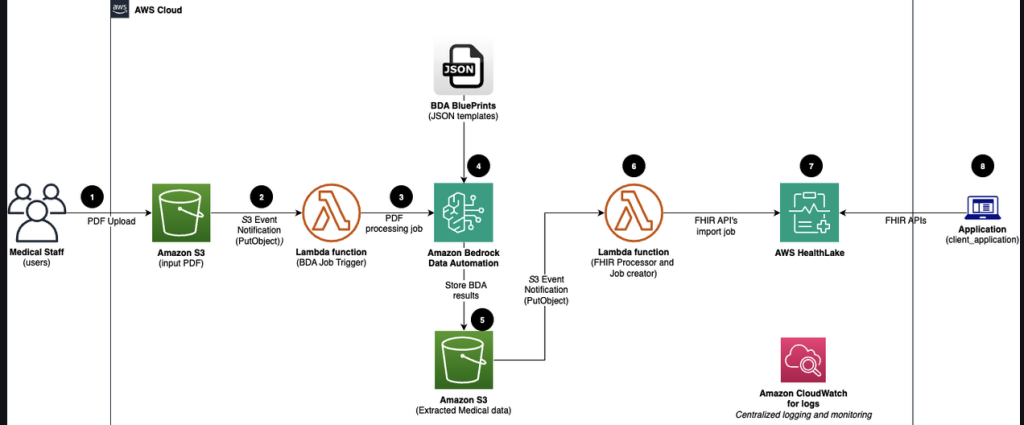
Automate medical record digitization with Amazon Bedrock Data Automation and AWS HealthLake
In this post, you learn how to build an automated, serverless pipeline that converts scanned PDF medical records into FHIR R4-compliant data using Amazon Bedrock Data Automation and AWS HealthLake. We walk through the architecture, explain how each AWS service connects to the next, show you what the pipeline looks like when it runs, and get you deployed in under 20 minutes.

Automating contract intelligence with Doczy.ai™ on AWS
In this post, we show you how Doczy.ai™ uses generative AI on AWS to automate contract intelligence at scale, transforming unstructured documents into structured, actionable insights, so organizations can automate critical business processes and unlock the full value of their data.
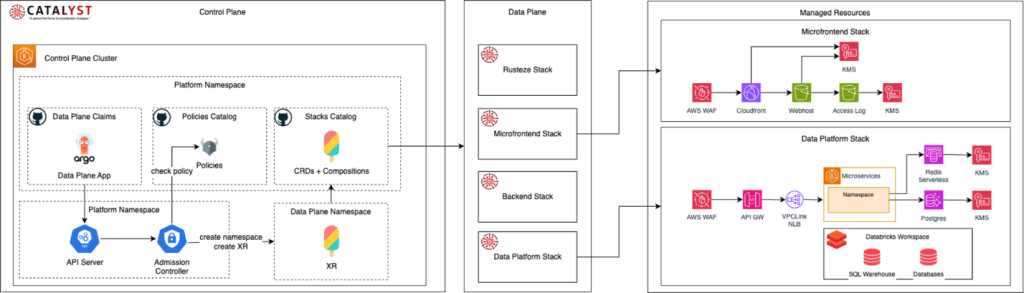
Digital Transformation at Santander: How Platform Engineering is Revolutionizing Cloud Infrastructure
Santander faced a significant technical challenge in managing an infrastructure that processes billions of daily transactions across more than 200 critical systems. The solution emerged through an innovative platform engineering initiative called Catalyst, which transformed the bank’s cloud infrastructure and development management. This post analyzes the main cases, benefits, and results obtained with this initiative.
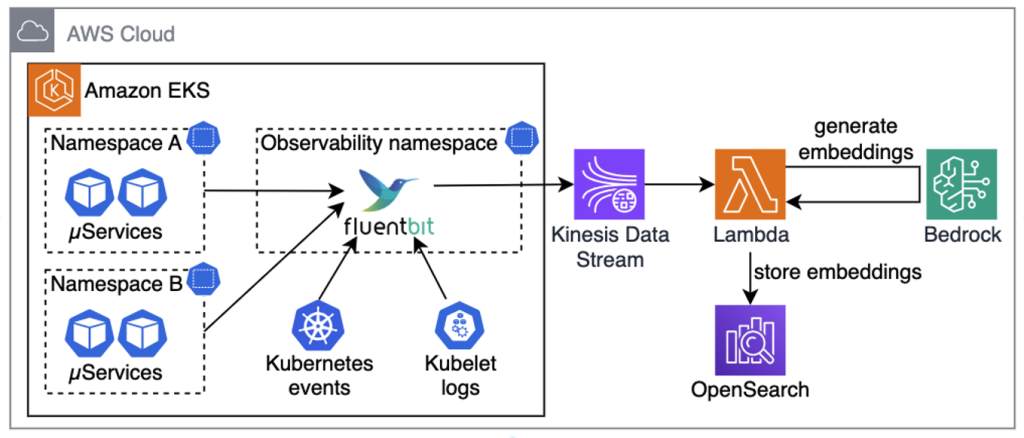
Architecting conversational observability for cloud applications
In this post, we walk through building a generative AI–powered troubleshooting assistant for Kubernetes. The goal is to give engineers a faster, self-service way to diagnose and resolve cluster issues, cut down Mean Time to Recovery (MTTR), and reduce the cycles experts spend finding the root cause of issues in complex distributed systems.
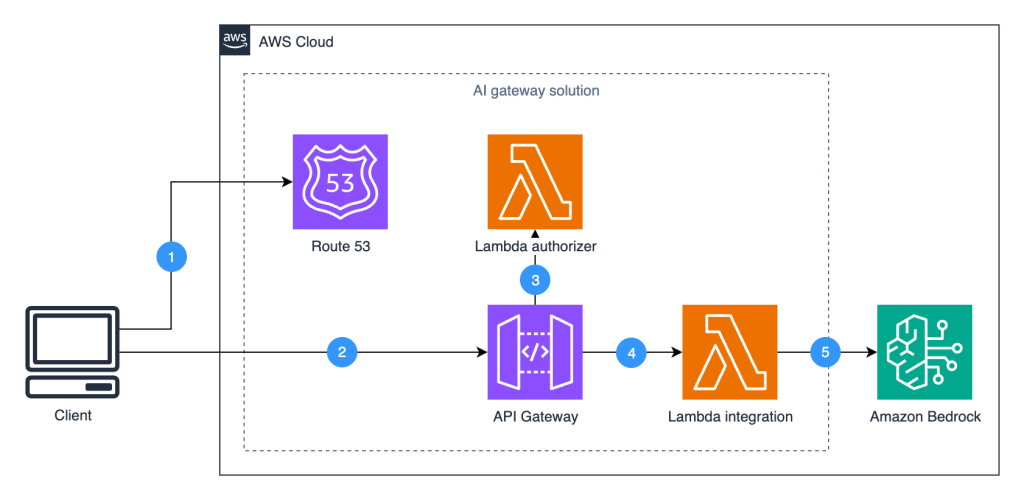
Building an AI gateway to Amazon Bedrock with Amazon API Gateway
In this post, we’ll explore a reference architecture that helps enterprises govern their Amazon Bedrock implementations using Amazon API Gateway. This pattern enables key capabilities like authorization controls, usage quotas, and real-time response streaming. We’ll examine the architecture, provide deployment steps, and discuss potential enhancements to help you implement AI governance at scale.

Architecting for AI excellence: AWS launches three Well-Architected Lenses at re:Invent 2025
At re:Invent 2025, we introduce one new lens and two significant updates to the AWS Well-Architected Lenses specifically focused on AI workloads: the Responsible AI Lens, the Machine Learning (ML) Lens, and the Generative AI Lens. Together, these lenses provide comprehensive guidance for organizations at different stages of their AI journey, whether you’re just starting to experiment with machine learning or already deploying complex AI applications at scale.

Announcing the updated AWS Well-Architected Machine Learning Lens
We are excited to announce the updated AWS Well-Architected Machine Learning Lens, now enhanced with the latest capabilities and best practices for building machine learning (ML) workloads on AWS.

Build resilient generative AI agents
Generative AI agents in production environments demand resilience strategies that go beyond traditional software patterns. AI agents make autonomous decisions, consume substantial computational resources, and interact with external systems in unpredictable ways. These characteristics create failure modes that conventional resilience approaches might not address. This post presents a framework for AI agent resilience risk analysis […]

Simplifying sustainability reporting using AWS and generative AI in banking
In this post, you learn how you can use generative AI services on Amazon Web Services (AWS) to automate your sustainability reporting requirements, reduce manual effort, and improve accuracy. You do this by implementing an automated solution for extracting, processing, and validating data from corporate reports.

Amazon Bedrock baseline architecture in an AWS landing zone
In this post, we explore the Amazon Bedrock baseline architecture and how you can secure and control network access to your various Amazon Bedrock capabilities within AWS network services and tools. We discuss key design considerations, such as using Amazon VPC Lattice auth policies, Amazon Virtual Private Cloud (Amazon VPC) endpoints, and AWS Identity and Access Management (IAM) to restrict and monitor access to your Amazon Bedrock capabilities.