AWS Cloud Financial Management
Improve cost visibility of Machine Learning workloads on Amazon EKS with AWS Split Cost Allocation Data
We are excited to introduce split cost allocation support for accelerated workloads in Amazon Elastic Kubernetes Service (EKS). This enhancement to Split Cost Allocation Data for EKS enables customers to track container-level resource costs for accelerator-powered workloads. Split Cost Allocation Data now utilizes Trainium, Inferentia, NVIDIA and AMD GPUs, complementing existing CPU and memory cost tracking capabilities. This cost data is available in the AWS Cost and Usage Report (legacy and CUR 2.0), providing organizations with a consolidated view of their cloud expenditures. This feature is now available across all AWS commercial regions (excluding China regions) at no additional cost to customers.
The challenges of monitoring and allocating container costs for accelerated workloads
Organizations are increasingly leveraging accelerator-powered workloads on Amazon EKS to power Artificial Intelligence (AI) applications including Machine Learning (ML), and Generative AI applications. These workloads typically run in multi-tenant clusters that utilize shared Amazon Elastic Compute Cloud (Amazon EC2) instances to host multiple application containers. These accelerator resources are both highly valuable and in high demand, making it critical to optimize their usage and maximize return on investment. These clusters run application workloads that span across multiple teams, departments, and environments. Customers require granular cost visibility and accountability to accurately allocate costs, set budgets, and drive efficient use of the resources. Furthermore, just having visibility into CPU and memory for accelerated workloads provides an incomplete view of their infrastructure usage, leading to incorrect cost allocation. Customers are asking for granular pod-level usage data for accelerator resources, along with CPU and Memory. As a result, customers often resort to using homegrown solutions or third-party products, which can be expensive and challenging to manage and maintain.
Get granular cost visibility for accelerated workloads running on EKS with Split Cost Allocation Data
The accelerator support in the Split Cost Allocation Data for EKS provides customers with a native AWS solution that enables visibility into the cost and usage of Kubernetes pods, based on the actual usage of accelerators (Trainium, Inferentia, NVIDIA and AMD GPUs), CPUs, and memory consumed by the pods. Customers can leverage the cost allocation tags like aws:eks:cluster-name, aws:eks:namespace, aws:eks:node, aws:eks:workload-type, aws:eks:workload-name, and aws:eks:deployment that are automatically enabled for accelerator powered pods to get a consolidated view of their application’s cost and usage running in shared multi-tenant environments. This capability allows customers to allocate Inferentia, Trainium and GPU costs accurately to respective cost centers. This enables customers to drive accountability of resource usage and make informed product prioritization decisions. Additionally, the Split Cost Allocation Data feature helps customers identify unused compute resources, allowing them to optimize their cluster configurations and container reservations, thereby minimizing inefficiencies. This feature eliminates the need for customers to build their own custom cost management tools, which can be resource-intensive and creates additional operational cost burdens.
Customers running containerized machine learning workloads can opt-in to Split Cost Allocation Data for Amazon EKS by visiting the AWS Billing and Cost Management Console. Once opted in, Split Cost Allocation Data for EKS automatically scans for clusters across all accounts in the organization. It ingest the accelerator, CPU, and Memory reservation data for the container workloads, and prepares the granular cost data for the current month. Split Cost Allocation Data for EKS automatically calculates new split allocation cost metrics. For example, GPU usage for each Kubernetes pod, which includes the Amazon EC2 amortized costs and any applicable discounts. Customers can use system created Kubernetes primitives such as aws:eks:cluster-name, aws:eks:namespace, aws:eks:node, aws:eks:workload-type, aws:eks:workload-name, and aws:eks:deployment as cost allocation tags, making it easy to organize costs. Customers can analyze the costs at hourly, daily, or monthly granularity, and perform internal chargebacks using the cost and usage data export.
For a detailed explanation of enabling spilt cost allocation data for EKS, please visit Understanding split cost allocation data.
How EKS split cost allocation works
To use this capability, customers must first enable Split Cost Allocation Data. For existing Split Cost Allocation Data customers, this feature will be enabled by automatically. Split Cost Allocation Data for EKS ingests accelerator, CPU and memory reservations with utilization and uses the greater of reservation and usage to calculate how much GPU, CPU and memory was allocated to the Pod. This concept can best be described by walking through an example. Let’s say that you have a single EC2 instance that is running 4 Pods across 2 namespaces and you wish to understand the costs of each namespace. The EC2-Instance is an p3.16xlarge with 8GPU, 64 vCPU, 488 GB RAM. The total cost of running your instance is $10/hr. based on on-demand rates. If you had a commitment i.e., Savings Plan or Reserved Instance, they will be factored in. Split Cost Allocation data normalizes the cost per resource based on a relative ratio of GPU:(CPU: memory) of 9:1. This implies that a unit of GPU costs 9x as much as a unit of CPU &memory. CPU and memory are then assigned a weight of 9:1 which is consistent with the current allocation weights. For a non-accelerated EC2 instance, the current default behavior will be adopted which is CPU: memory weight defaults to 9:1.
There are four steps in the calculations (for detailed calculations, please visit the documentation page):
Step #1 – Compute the unit cost
Based on the accelerator (Trainium, Inferentia and GPU), CPU and memory resources on the EC2 instance and using the ratio of mentioned above, Split Cost Allocation data first calculates the unit cost per GPU-hr, vCPU-hr, and GB-hr, which is $0.50, $0.05, and $0.005 respectively.

Table 1: Sample cost per GPU, CPU, GB hours
Step #2 – Calculate Allocated and Unused Capacity
The GPU, vCPU and memory request and actual usage across the 4 Kubernetes pods are listed in the table below. Pod 2 used more GPU, CPU and memory than what was requested because it didn’t configure a limit. Split Cost Allocation Data computes allocated vCPU and memory based on the greater value between the requested and actual usage. In this example, we don’t have any unused GPU, vCPU, but there is 48GB of unallocated memory.
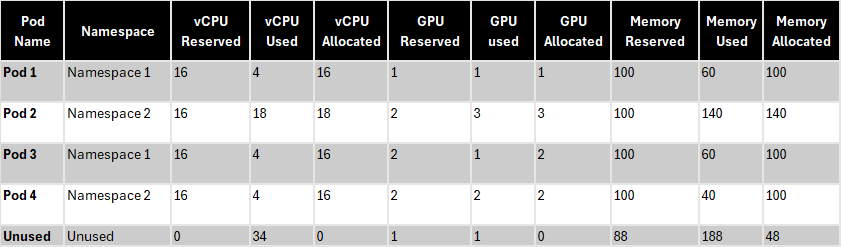
Table 2: Calculate Allocated and Unused Capacity
Step #3 – Compute Utilization ratios and Split usage ratios
Split Cost Allocation Data computes a split-usage ratio as the percentage of CPU or memory allocated by the Kubernetes pods compared to the overall GPU, CPU or memory available on the EC2 instance. It also computes an unused ratio as the percentage of GPU, CPU or memory allocated by the Kubernetes pods compared to the overall GPU, CPU or memory allocated on the EC2 instance (that is, not factoring in the unallocated GPU, CPU or memory on the instance). For instance, there is 48GB of unallocated memory on the instance, which is 48/488 = 0.098 of the total instance memory. Pod1 has allocated 100GB, which is 100/488 = 0.204 of the total instance memory. Therefore, the total unused memory ratio for Pod 1 is 0.204 / (1-0.098) = 0.227.
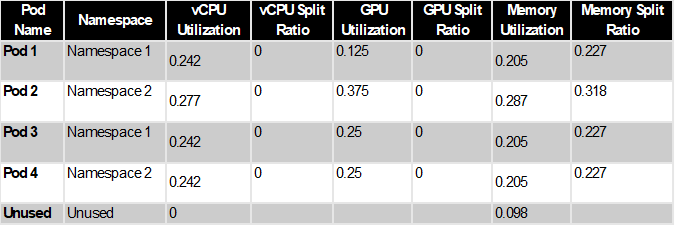
Table 3: Compute Utilization ratios
Step #4 – Compute the split and unused costs
The pod-level split costs are calculated based on split-usage ratios multiplied by the cost per GPU, vCPU-Hour and cost per GB-Hour. If there is unused resource, in this case unused memory capacity of 48GB, the unused instance cost ($0.27) is proportionally distributed to each pod based on the unused ratio computed for each pod. The total allocated cost for each pod will be the total of the split cost and proportionally redistributed unused cost. Once the EC2 cost is available at the pod level, you can calculate the aggregate namespace-level costs. In this example, the total allocated cost for Namespace 1 and Namespace 2 are $4.32 and $5.67, respectively. You can also aggregate the costs using Cost Categories or the new EKS cost allocation tags that were added to the Kubernetes pods, allowing you to compute the cost by your desired business entity level.
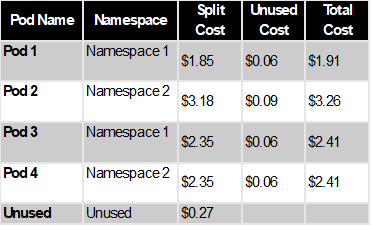
Table 4 : Compute the split and unused costs
What are the new Cost and Usage Report columns?
Existing split cost allocation data users will not see any new columns as this accelerator support capability leverages the current column structure. New customers enabling this feature will observe Kubernetes pod-level metrics in their CUR reports, in columns such as “SplitLineItem/SplitUsage” which displays GPU, vCPU, or memory allocation for specific time periods at the pod level. For a comprehensive understanding of all relevant columns and their definitions, please consult the CUR data dictionary.
To wrap up with our example, below is a demo CUR report. You can see how data will be displayed in the new CUR columns.
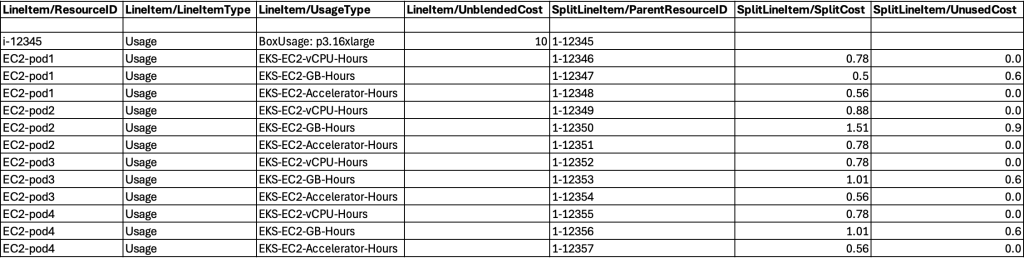
Table 5: Demo CUR report showing new columns.
You can also use the Containers Cost Allocation dashboard to query and visualize your EKS costs in Amazon QuickSight and CUR query library to query your EKS costs using Amazon Athena.
Conclusion
The visibility of EKS cost data provides insights to improve efficiency and cost optimization. Enable this granular level of cost data today and learn more about this capability.