AWS News Blog
Consistent View for Elastic MapReduce’s File System
Many AWS developers are using Amazon EMR (a managed Hadoop service) to quickly and cost-effectively build applications that process vast amounts of data. The EMR File System (EMRFS) allows AWS customers to use Amazon Simple Storage Service (Amazon S3) as a durable and cost-effective data store that is independent of the memory and compute resources of any particular cluster. It also allows multiple EMR clusters to process the same data set. This file system is accessed via the s3:// scheme.
Because S3 is designed for eventual consistency, if one application creates an S3 object it may take a short time (typically measured in tens or hundreds of milliseconds) before it is visible in a LIST operation. This small window can sometimes lead to inconsistent results when the output files produced by one MapReduce job are used as the input of another job.
Today we are making EMRFS even more powerful with the addition of a consistent view of the files stored in Amazon Simple Storage Service (Amazon S3). If you enable this feature, you can be confident that all of your files will be processed as intended when you run a chained series of MapReduce jobs. This is not a replacement file system. Instead, it extends the existing file system with mechanisms that are designed to detect and react to inconsistencies. The detection and recovery process includes a retry mechanism. After it has reached a configurable limit on the number of retries (to allow S3 to return what EMRFS expects in the consistent view), it will either (your choice) raise an exception or log the issue and continue.
The EMRFS consistent view creates and uses metadata in an Amazon DynamoDB table to maintain a consistent view of your S3 objects. This table tracks certain operations but does not hold any of your data. The information in the table is used to confirm that the results returned from an S3 LIST operation are as expected, thereby allowing EMRFS to check list consistency and read-after-write consistency.
Enabling the Consistent View
This feature is not enabled by default. You can, however, enable it when you create a new Elastic MapReduce cluster from the command line, the Elastic MapReduce API, or the Elastic MapReduce Console. Here are the options that are available to you when you use the console:
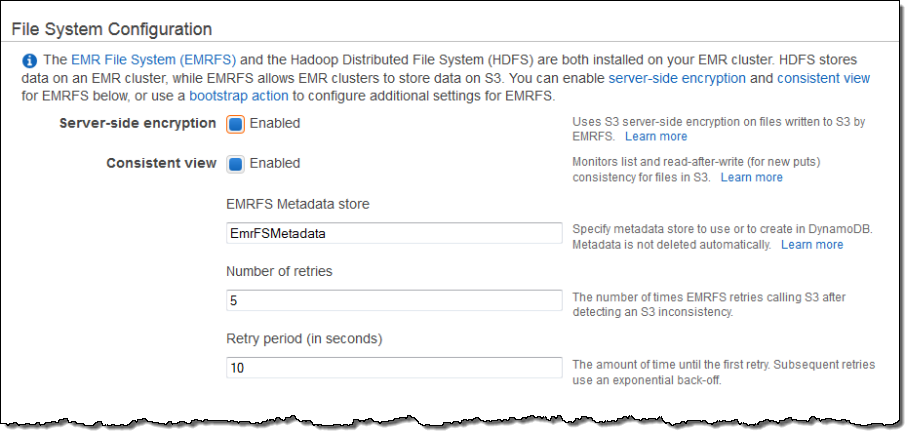
As you can see, you can also enable S3 server-side encryption for EMRFS.
Here’s how you enable the consistent view from the command line when you create a new EMR cluster:
$ aws emr create-cluster --name TestCluster --ami-version 3.2.1 \
--instance-type m3.xlarge --instance-count 3 \
--emrfs Consistent=True --ec2-attributes KeyName=YOURKEYNAME
Important Details
In general, once enabled, this feature will enforce consistency with no action on your part. For example, it will create, populate, and update the DynamoDB table as needed. It will not, however, delete the table (it has no way to know when it is safe to do so). You can delete the table through the DynamoDB console or you can add a final cleanup step to the last job on your processing pipeline.
You can also sync a folder to load it into a consistent view. This is useful to add new folders to the view that were not written by EMRFS, or to manually sync a folder being managed by EMRFS. You can log in to the Master node of your cluster and run the emrfs command like this: table:
$ emrfs sync s3://bucket/folder
There is no charge for this feature, but you will pay an hourly charge for the data stored in the DynamoDB table (the first 100 MB is available to you at no charge at part of the AWS Free Usage tier and for the level of provisioned read and write capacity). By default, the table is provisioned for 500 read capacity units and 100 write capacity units. As I noted earlier, you are responsible for deleting the table when you no longer need it.
Be Consistent
This feature is available now and you can start using it today!
— Jeff;