AWS News Blog
New AWS Command Line Interface (CLI)

|
Graphical user interfaces (e.g. the AWS Management Console) are great, but nothing beats the expressiveness of the command line!
Today we are releasing the AWS Command Line Interface (CLI). The AWS CLI provides a single, unified interface to a very large collection of AWS services. After downloading and configuring the CLI you can drive Amazon EC2, Amazon S3, Elastic Beanstalk, the Simple Workflow Service, and twenty other services (complete list) from your Linux, OS X, or Windows command line.
Download and Configure
The Getting Started page contains the information that you need to know in order to download and configure the AWS CLI. You’ll need to have Python (any version from 2.6.x up to 3.3.x) installed if you are on Linux or OS X, but that’s about it. You can install the CLI using easy_install, pip, or from a Windows MSI.
You can set your AWS credentials for the CLI using environment variables or a configuration file. If you are running the CLI on an EC2 instance, you can also use an IAM role.
I recommend that you create an IAM user (I called mine awscli) so that you have full control of the AWS operations that can be performed from the command line. For testing purposes, I used the all-powerful Administrator Access policy template. In practice I would definitely use a more restrictive template.
Running Commands
The AWS CLI commands take the form:
$ aws SERVICE OPERATION [OPTIONS]
The SERVICE is the name of the service, except in the case of Amazon S3, where it is s3api. The s3 service is used to invoke a very powerful set of file manipulation commands that I will describe in a moment.
The OPERATION is the name of the corresponding AWS API function — describe-instances, list-buckets, and so forth. You can issue the help operation to see a list of all available operations for the service:
$ aws ec2 help
Each operation generates its output in JSON format by default. You can use –output text and –output table to request text and tabular output, respectively. Here are samples of all three:
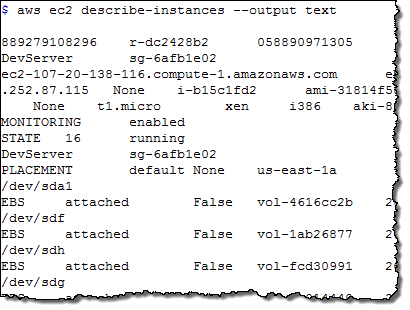

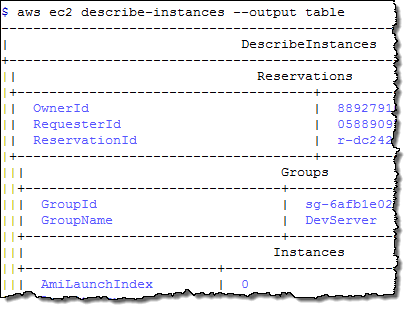
The jq (JSON Query) tool makes it easy for you to process JSON data. For example, a recent post on Reddit asked about extracting tag data for an EC2 instance. Here’s how to solve that problem by using the AWS CLI and jq:
$ aws ec2 describe-instances --output json | jq .Reservations[].Instances[].Tags[] { "Key": "Name", "Value": "DevServer" }
S3 File Operations
The AWS CLI also supports a set of S3 file operations. You can list (ls), copy (cp), move (mv), and sync (sync) files (S3 objects). You can also make (mb) and remove (rb) S3 buckets. Here are a couple of examples:
$ aws s3 mb s3://jbarr-book-code make_bucket: s3://jbarr-book-code/ $ aws s3 sync . s3://jbarr-book-code upload: CVS/Entries to s3://jbarr-book-code/CVS/Entries upload: .cvsignore to s3://jbarr-book-code/.cvsignore upload: Makefile to s3://jbarr-book-code/Makefile upload: CVS/Repository to s3://jbarr-book-code/CVS/Repository upload: LICENSE.txt to s3://jbarr-book-code/LICENSE.txt upload: README to s3://jbarr-book-code/README upload: NOTICE.txt to s3://jbarr-book-code/NOTICE.txt upload: TODO.txt to s3://jbarr-book-code/TODO.txt upload: aws.dot to s3://jbarr-book-code/aws.dot upload: CVS/Root to s3://jbarr-book-code/CVS/Root upload: aws_meta.dot to s3://jbarr-book-code/aws_meta.dot upload: aws_meta.php to s3://jbarr-book-code/aws_meta.php ...
$ aws s3 ls s3://jbarr-book-code Bucket: jbarr-book-code Prefix: LastWriteTime Length Name ------------- ------ ---- PRE CVS/ PRE magpierss-0.72/ 2013-09-03 20:53:54 63 .cvsignore 2013-09-03 20:53:55 9189 LICENSE.txt 2013-09-03 20:53:55 401 Makefile 2013-09-03 20:53:55 406 NOTICE.txt 2013-09-03 20:53:55 470 README 2013-09-03 20:53:55 2190 TODO.txt 2013-09-03 20:53:55 5941 aws.dot 2013-09-03 20:53:55 763110 aws_meta.dot ... $ touch ch4*.php $ aws s3 sync . s3://jbarr-book-code upload: ch4_simple_crawl.php to s3://jbarr-book-code/ch4_simple_crawl.php upload: ch4_ec2_setup.php to s3://jbarr-book-code/ch4_ec2_setup.php
The file operations will automatically make use of parallelized multi-part uploads to Amazon S3 for large files and for groups of files. You can also use the –recursive option on the cp, mv, and rm commands in order to process the current directory and all directories inside of it.
A Few More Options
Some of the AWS commands accept or require large amount of text or JSON content as parameters. You can store parameters values of this type in a file or in a web-accessible location and then reference it as follows:
$ aws ec2 authorize-security-group-ingress --group-name MySecurityGroup --ip-permissions file://ip_perms.json $ aws ec2 authorize-security-group-ingress --group-name MySecurityGroup --ip-permissions http://mybucket.s3.amazonaws.com/ip_perms.json
View Source
The AWS CLI is an open source project and the code is available on GitHub at http://github.com/aws/aws-cli. You can browse the source, enter suggestions, raise issues, and submit pull requests for desired changes.
— Jeff;
Modified 2/9/2021 – In an effort to ensure a great experience, expired links in this post have been updated or removed from the original post.