AWS News Blog

Announcing AWS Outposts third-party storage integration with Dell and HPE
AWS Outposts is now integrated with Dell PowerStore and HPE Alletra MP B10000 systems, enabling customers to seamlessly use their on-premises external storage infrastructure with AWS services while maintaining data residency requirements.

Introducing Claude Sonnet 4.5 in Amazon Bedrock: Anthropic’s most intelligent model, best for coding and complex agents
Amazon Web Services announces Claude Sonnet 4.5 in Amazon Bedrock, featuring advanced capabilities in coding, tool handling, and long-horizon tasks, with improvements in memory management, context processing, and industry-specific applications across finance, research, and cybersecurity sectors.

AWS Weekly Roundup: Amazon S3 updates, Bedrock AgentCore, AWS X-Ray smart sampling, and more (September 29, 2025)
Wow, can you all believe it? We’re nearing the end of the year already. Next thing you know, AWS re:Invent will be here! This is our biggest event that takes place every year in Las Vegas from December 1st to December 5th where we reveal and release many of the things that we’ve been working […]
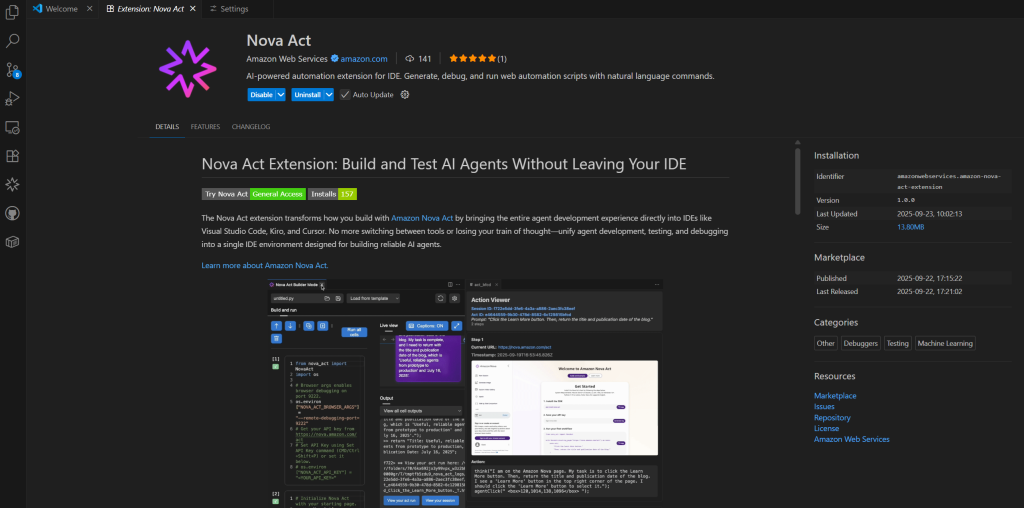
Accelerate AI agent development with the Nova Act IDE extension
The Nova Act extension is a new IDE-integrated tool that enables developers to create browser automation agents using natural language through the Nova Act model, offering features like Builder Mode, chat capabilities, and predefined templates while streamlining the development process without leaving their preferred development environment.

AWS Weekly Roundup: Amazon Q Developer, AWS Step Functions, AWS Cloud Club Captain deadline, and more (September 22, 2025)
Three weeks ago, I published a post about the new AWS Region in New Zealand (ap-southeast-6). This led to an incredible opportunity to visit New Zealand, where I met passionate builders and presented at several events including Serverless and Platform Engineering meetup, AWS Tools and Programming meetup, AWS Cloud Clubs in Auckland, and AWS Community […]

Qwen models are now available in Amazon Bedrock
Amazon Bedrock has expanded its model offerings with the addition of Qwen 3 foundation models enabling users to access and deploy them in a fully managed, serverless environment. These models feature both mixture-of-experts (MoE) and dense architectures to support diverse use cases including advanced code generation, multi-tool business automation, and cost-optimized AI reasoning.

DeepSeek-V3.1 model now available in Amazon Bedrock
AWS launches DeepSeek-V3.1 as a fully managed models in Amazon Bedrock. DeepSeek-V3.1 is a hybrid open weight model that switches between thinking mode for detailed step-by-step analysis and non-thinking mode for faster responses.

AWS named as a Leader in 2025 Gartner Magic Quadrant for Cloud-Native Application Platforms and Container Management
AWS was named as a Leader in the 2025 Gartner Magic Quadrant for Cloud-Native Application Platforms in two consecutive years positioned highest on “Ability to Execute”, and for Container Management in three years positioned furthest for “Completeness of Vision”.