AWS News Blog
Process Streaming Data with Kinesis and Elastic MapReduce

|
Regular readers of this blog already know that Amazon Kinesis is a fully managed service for real-time processing of streaming data at massive scale.
As I noted last month when we introduced the Kinesis Storm Spout, Kinesis is but one component of a complete end-to-end streaming data application. In order to build such an application, you can use the Kinesis Client Library for load-balancing of streaming data and coordination of distributed services and the Kinesis Connector Library to communicate with other data storage and processing services.
New EMR Connector to Kinesis
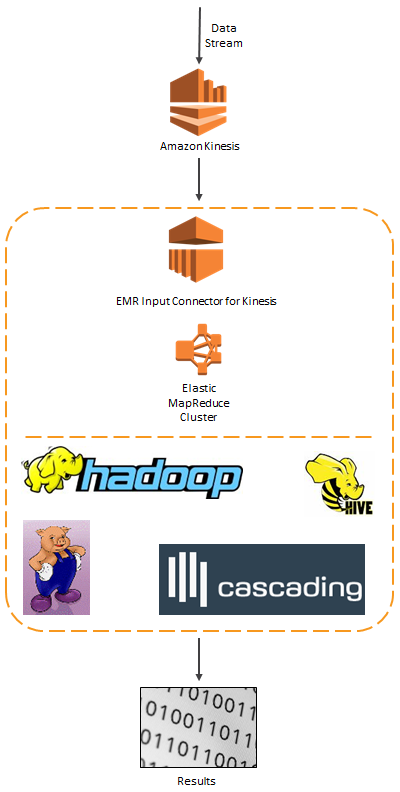
Today we are adding an Elastic MapReduce Connector to Kinesis. With this connector, you can analyze streaming data using familiar Hadoop tools such as Hive, Pig, Cascading, and Hadoop Streaming. If you build the analytical portion of your streaming data application around the combination of Kinesis and Amazon Elastic MapReduce, you will benefit from the fully managed nature of both services. You won’t have to worry about building deploying, or maintaining the infrastructure needed to do real-time processing at world-scale. This connector is available in version 3.0.4 of the Elastic MapReduce AMI.
Here’s how all of the pieces mentioned above fit together:
Interesting Use Cases
So, what can you do with this pair of powerful services? Here are a few ideas to get you started:
On the IT side, you can analyze your log files to generate operational intelligence. Stream your web logs into Kinesis, analyze them every few minutes, and generate a Top 10 error list broken down by region and page.
On the business side, you can join Kinesis stream with data stored in S3, DynamoDB tables, and HDFS to drive comprehensive data workflows. For example, you can write queries that join clickstream data from Kinesis with advertising campaign information stored in a DynamoDB table to identify the most effective categories of ads that are displayed on particular websites.
You can also use Elastic MapReduce to filter or pre-process incoming data before you store it (perhaps in Amazon DynamoDB, Amazon S3, or Amazon Redshift) for further analysis. Perhaps you need to exclude certain record types, perform some preliminary calculations, or aggregate multiple records.
Finally, you can run ad-hoc queries on data flowing through a Kinesis stream. You can form and test out queries before embedding them in your code. You can periodically load draft from Kinesis into HDFS and make it available as a local Impala table for fast, interactive analytic queries.
You have two different options when it comes to running your queries:
First, you can perform incremental queries. In this case the connector tracks the starting and ending records in each shard, returning only newly available records in each batch. The checkpoint information is stored in Amazon DynamoDB. A unique iteration number is assigned to each batch in order to simplify downstream processing.
Alternatively, you can disable the checkpointing behavior and query the entire stream. This will give you access to all of the data present in the stream. This query gives you a sliding window into the last 24 hours (the duration that data persists in Kinesis).
Mapping Streams to Tables in Hive
If you are using Hive to process data that arrives via Kinesis, your table definition can reference a Kinesis stream by ending it as follows:
STORED BY
'com.amazon.emr.kinesis.hive.KinesisStorageHandler'
TBLPROPERTIES("kinesis.stream.name"="AccessLogStream");
You can create Hive tables for multiple streams and then join them in the usual way. If checkpointing is enabled, these queries will process data corresponding to the same iteration number and logical name from both of the tables.
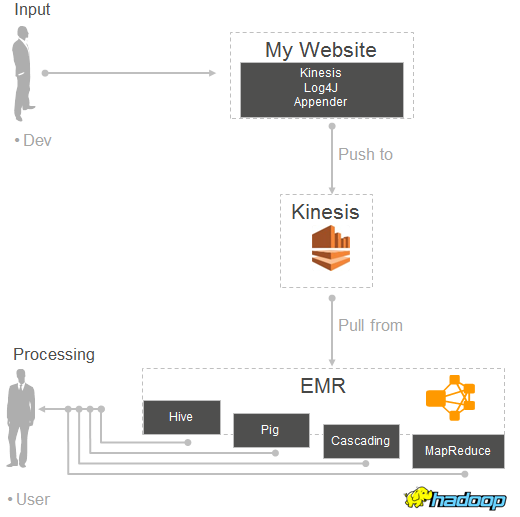
Kinesis Log4J Appender
If you are interested in pushing large amounts of log-style data into Kinesis, I encourage you to take a look at the Kinesis Log4J Appender (download the jar). We have developed a Log4J Appender implementation that makes it easy to continuously push log directly to a Kinesis stream. You can use it, along with the new connector described in this blog post, to implement the following processing model:
Getting Started
If you are already familiar with Elastic MapReduce and Hadoop, you can put your hard-won skills to good use at once by reading our new Streaming Data Analysis Tutorials. If not, you’ll want to study the Kinesis Getting Started Guide and the Elastic MapReduce documentation.
To learn more about this feature, read the new Analyze Real-Time Data from Kinesis Streams chapter of the Elastic MapReduce documentation. The Elastic MapReduce FAQ has also been updated and should also be helpful.
— Jeff;