AWS News Blog
Marry Amazon Kinesis and Storm Using the New Kinesis Storm Spout
Amazon Kinesis is a fully managed service for real-time processing of streamed data at massive scale. When we launched Kinesis in November of 2013, we also introduced the Kinesis Client Library. You can use the client library to build applications that process streaming data. It will handle complex issues such as load-balancing of streaming data, coordination of distributed services, while adapting to changes in stream volume, all in a fault-tolerant manner.
Kinesis Connector Library
In many streaming data applications, Kinesis is an important central component, but just one component nevertheless. We know that many developers want to consume and process incoming streams using a variety of other AWS and non-AWS services.
In order to meet this need, we released the Kinesis Connector Library late last year with support for Amazon DynamoDB, Amazon Redshift, and Amazon S3.
Today we are expanding the Kinesis Connector Library with support for the popular Storm real-time computation system. We call this new offering the Kinesis Storm Spout!
All About Storm
A Storm cluster processes streaming messages on a continuous basis. Individual logical processing units (Bolts in Storm terminology) are connected together in pipeline fashion to express the series of transformations steps while also exposing opportunities for concurrent processing.
A Storm’s stream is sourced by a Spout. Each Spout emits one or more sequences of tuples into a cluster for processing. A given Bolt can consume any number of input streams, process the data, and emit transformed tuples. A Topology is a multi-stage distributing computation composed of a network of Spouts and Bolts. A Topology (which you can think of as a full application) runs continuously in order to process incoming data.
Kinesis and Storm
The new Kinesis Storm Spout routes data from Kinesis to a Storm cluster for processing.
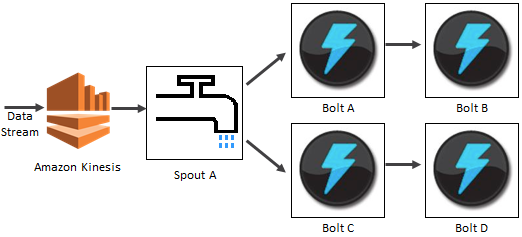
In the illustration below, Spout A is an example of a Kinesis Storm Spout wired to consume a data record from the Kinesis stream and emit a tuple into the Storm Cluster. Constructing the Spout only requires pointing to the Kinesis Stream, the Zookeeper configuration and AWS credentials to access the stream.
Getting Started
Your Java code has three duties:
- Constructing the Kinesis Storm Spout
- Setting up the Storm Topology
- Submitting the Topology to the Storm cluster
Here’s how you construct the Kinesis Storm Spout:
final KinesisSpoutConfig config =
new KinesisSpoutConfig(streamName, zookeeperEndpoint)
.withZookeeperPrefix(zookeeperPrefix)
.withInitialPositionInStream(initialPositionInStream);
final KinesisSpout spout =
new KinesisSpout(config, new CustomCredentialsProviderChain(), new ClientConfiguration());
The Kinesis Spout implements Storms IRichSpout, and is constructed by just specifying the stream name, Zookeper configs and your AWS credentials. Note that a Storm Spout is expected to push one record at a time when the nextTuple API is called. However, the Kinesis GetRecords API call is optimized to get a batch of records. The Kinesis Spout buffers a batch of records internally, and emits one tuple at a time.
Here’s how you create a topology with one Kinesis Spout (2 parallel tasks) and one Storm Bolt (2 parallel tasks). Note that they are connected using Storm’s field grouping feature. This feature supports routing of tuples to specific tasks based on the value found in a particular field.
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("kinesis_spout", spout, 2);
builder.setBolt("print_bolt",
new SampleBolt(), 2).fieldsGrouping("kinesis_spout",
new Fields(DefaultKinesisRecordScheme.FIELD_PARTITION_KEY));
And here’s how you submit the topology to your Storm cluster to begin processing the Kinesis stream:
StormSubmitter.submitTopology(topologyName, topoConf, builder.createTopology());
You will have to package up the compiled form of the code above and all of the dependencies in (including Kinesis Storm Spout) into a single JAR file. This file must also include the sample.properties and AWSCredentials.properties files.
The Kinesis Storm Spout is available on GitHub now and you can start using it today.
— Jeff;