AWS News Blog
Amazon Kinesis – Real-Time Processing of Streaming Big Data
 Imagine a situation where fresh data arrives in a continuous stream, 24 hours a day, 7 days a week. You need to capture the data, process it, and turn it into actionable conclusions as soon as possible, ideally within a matter of seconds. Perhaps the data rate or the compute power required for the analytics varies by an order of magnitude over time. Traditional batch processing techniques are not going to do the job.
Imagine a situation where fresh data arrives in a continuous stream, 24 hours a day, 7 days a week. You need to capture the data, process it, and turn it into actionable conclusions as soon as possible, ideally within a matter of seconds. Perhaps the data rate or the compute power required for the analytics varies by an order of magnitude over time. Traditional batch processing techniques are not going to do the job.
Amazon Kinesis is a managed service designed to handle real-time streaming of big data. It can accept any amount of data, from any number of sources, scaling up and down as needed.
You can use Kinesis in any situation that calls for large-scale, real-time data ingestion and processing. Logs for servers and other IT infrastructure, social media or market data feeds, web clickstream data, and the like are all great candidates for processing with Kinesis.
Let’s dig into Kinesis now…
Important Concepts
 Your application can create any number of Kinesis streams to reliably capture, store and transport data. Streams have no intrinsic capacity or rate limits. All incoming data is replicated across multiple AWS Availability Zones for high availability. Each stream can have multiple writers and multiple readers.
Your application can create any number of Kinesis streams to reliably capture, store and transport data. Streams have no intrinsic capacity or rate limits. All incoming data is replicated across multiple AWS Availability Zones for high availability. Each stream can have multiple writers and multiple readers.
When you create a stream you specify the desired capacity in terms of shards. Each shard has the ability to handle 1000 write transactions (up to 1 megabyte per second — we call this the ingress rate) and up to 5 read transactions (up to 2 megabytes per second — the egress rate). You can scale a stream up or down at any time by adding or removing shards without affecting processing throughput or incurring any downtime, with new capacity ready to use within seconds. Pricing (which I will cover in depth in just a bit) is based on the number of shards in existence and the number of writes that you perform.
The Kinesis client library is an important component of your application. It handles the details of load balancing, coordination, and error handling. The client library will take care of the heavy lifting, allowing your application to focus on processing the data as it becomes available.
Applications read and write data records to streams. Records can be up to 50 Kilobytes in length and are comprised of a partition key and a data blob, both of which are treated as immutable sequences of bytes. The record’s partition determines which shard will handle the data blob; the data blob itself is not inspected or altered in any way. A sequence number is assigned to each record as part of the ingestion process. Records are automatically discarded after 24 hours.
The Kinesis Processing Model
The “producer side” of your application code will use the PutRecord function to store data in a stream, passing in the stream name, the partition key, and the data blob. The partition key is hashed using an MD5 hashing function and the resulting 128-bit value will be used to select one of the shards in the stream.
The “consumer” side of your application code reads through data in a shard sequentially. There are two steps to start reading data. First, your application uses GetShardIterator to specify the position in the shard from which you want to start reading data. GetShardIterator gives you the following options for where to start reading the stream:
- AT_SEQUENCE_NUMBER to start at given sequence number.
- AFTER_SEQUENCE_NUMBER to start after a given sequence number.
- TRIM_HORIZON to start with the oldest stored record.
- LATEST to start with new records as they arrive.
Next, your application uses GetNextRecords to retrieve up to 2 megabytes of data per second using the shard iterator. The easiest way to use GetNextRecords is to create a loop that calls GetNextRecords repeatedly to get any available data in the shard. These interfaces are, however, best thought of as a low-level interfaces; we expect most applications to take advantage of the higher-level functions provided by the Kinesis client library.
The client library will take care of a myriad of details for you including fail-over, recovery, and load balancing. You simply provide an implementation of the IRecordProcessor interface and the client library will “push” new records to you as they become available. This is the easiest way to get started using Kinesis.
After processing the record, your consumer code can pass it along to another Kinesis stream, write it to an Amazon S3 bucket, a Redshift data warehouse, or a DynamoDB table, or simply discard it.
Scaling and Sharding
You are responsible for two different aspects of scalability – processing and sharding. You need to make sure that you have enough processing power to keep up with the flow of records. You also need to manage the number of shards.
Let’s start with the processing aspect of scalability. The easiest way to handle this responsibility is to implement your Kinesis application with the Kinesis client library and to host it on an Amazon EC2 instance within an Auto Scaling group. By setting the minimum size of the group to 1 instance, you can recover from instance failure. Set the maximum size of the group to a sufficiently high level to ensure plenty of headroom for scaling activities. If your processing is CPU-bound, you will want to scale up and down based on the CloudWatch CPU Utilization metric. On the other hand, if your processing is relatively lightweight, you may find that scaling based on Network Traffic In is more effective.
Ok, now on to sharding. You should create the stream with enough shards to accommodate the expected data rate. You can then add or delete shards as the rate changes. The APIs for these operations are SplitShard and MergeShards, respectively. In order to use these operations effectively you need to know a little bit more about how partition keys work.
As I have already mentioned, your partition keys are run through an MD5 hashing function to produce a 128-bit number, which can be in the range of 0 to 2127-1. Each stream breaks this interval into one or more contiguous ranges, each of which is assigned to a particular shard.
Let’s start with the simplest case, a stream with a single shard. In this case, the entire interval maps to a single shard. Now, things start to heat up and you begin to approach the data handling limit of a single shard. It is time to scale up! If you are confident that the MD5 hash of your partition keys results in values that are evenly distributed across the 128-bit interval, then you can simply split the first shard in the middle. It will be responsible for handling values from 0 to 2126-1, and the new shard will be responsible for values from 2126 to 2127-1.
Reality is never quite that perfect, and it is possible that the MD5 hash of your partition keys isn’t evenly distributed. In this case, splitting the partition down the middle would be a sub-optimal decision. Instead, you (in the form of your sharding code) would like to make a more intelligent decision, one that takes the actual key distribution into account. To do this properly, you will need to track the long-term distribution of hashes with respect to the partitions, and to split the shards accordingly.
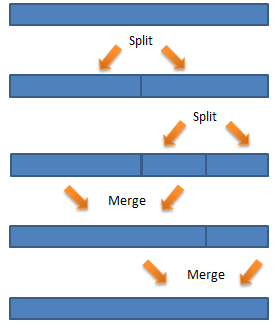
You can reduce your operational costs by merging shards when traffic declines. You can merge adjacent shards; again, an intelligent decision will maintain good performance and low cost. Here’s a diagram of one possible sequence of splits and merges over time:
Kinesis Pricing
Kinesis pricing is simple: you pay for PUTs and for each shard of throughput capacity. Lets assume that you have built a game for mobile devices and you want to track player performance, top scores, and other metrics associated with your game in real-time so that you can update top score dashboards and more.
Lets also assume that each mobile device will send a 2 kilobyte message every 5 seconds and that at peak youll have 10,000 devices simultaneously sending messages to Kinesis. You can scale up and down the size of your stream, but for simplicity lets assume its a constant rate of data.
Use this data to calculate how many Shards of capacity youll need to ingest the incoming data. The Kinesis console helps you estimate using a wizard, but lets do the math here. 10,000 (PUTs per second) * 2 kilobytes (per PUT) = 20 megabytes per second. You will need 20 Shards to process this stream of data.
Kinesis uses simple pay as you go pricing. You pay $0.028 per 1,000,000 PUT operations and you pay $0.015 per shard per hour. For one hour of collecting game data youd pay $0.30 for the shards and about $1.01 for the 36 million PUT calls, or $1.31.
Kinesis From the Console
You can create and manage Kinesis streams using the Kinesis APIs, the AWS CLI, and the AWS Management Console. Here’s a brief tour of the console support.
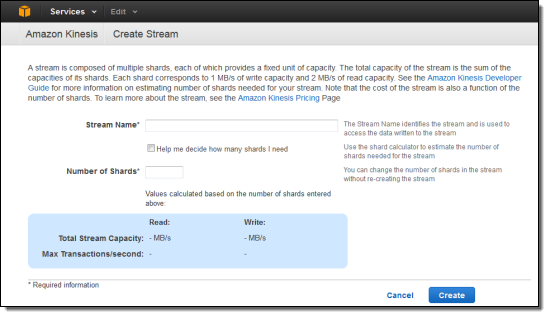
Click on the Create Stream button to get started. You need only enter a stream name and the number of shards to get started:
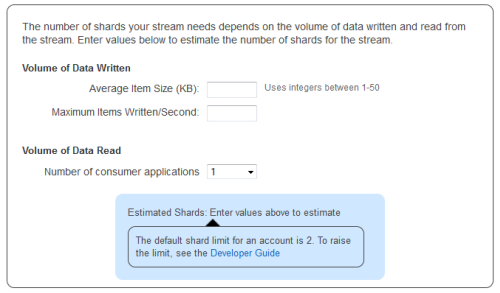
The console includes a calculator to help you estimate the number of shards you need:
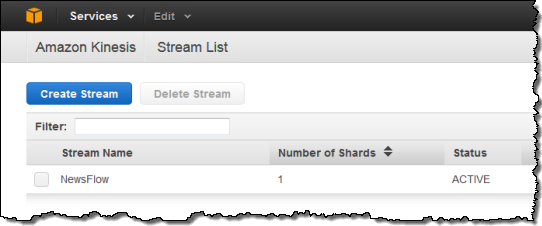
You can see all of your streams at a glance:
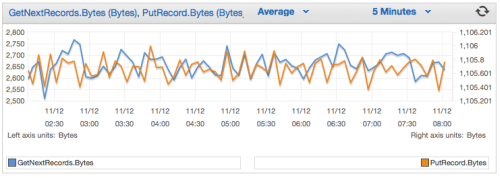
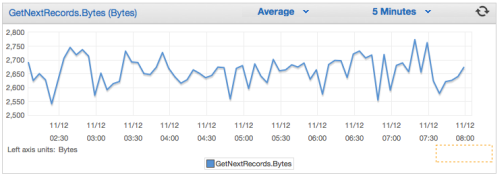
And you can view the CloudWatch metrics for each stream:
Getting Started
Amazon Kinesis is available in limited preview and you can request access today.
— Jeff;