AWS News Blog
Semi-Autonomous Driving Using EC2 Spot Instances at Mapbox

|
Please note: We have updated the Amazon EC2 Spot pricing model as of November, 2017. The new pricing model simplifies purchasing without bidding and with fewer interruptions. Click here to learn more about the updated pricing model.
Will White of Mapbox shared the following guest post with me. In the post, Will describes how they use EC2 Spot Instances to economically process the billions of data points that they collect each day.
I do have one note to add to Will’s excellent post. We know that many AWS customers would like to create Spot Fleets that automatically scale up and down in response to changes in demand. This is on our near-term roadmap and I’ll have more to say about it before too long.
— Jeff;
The largest automotive tech conference, TU-Automotive, kicked off in Detroit this morning with almost every conversation focused on strategies for processing the firehose of data coming off connected cars. The volume of data is staggering – last week alone we collected and processed over 100 million miles of sensor data into our maps.
Collecting Street Data
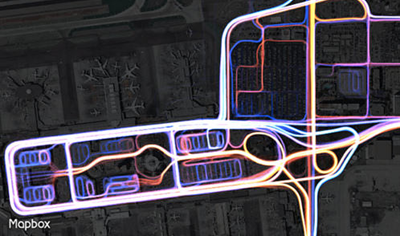 Rather than driving a fleet of cars down every street to make a map, we turn phones, cars, and other devices into a network of real-time sensors. EC2 Spot Instances process the billions of points we collect each day and let us see every street, analyze the speed of traffic, and connect the entire road network. This anonymized and aggregated data protects user privacy while allowing us to quickly detect road changes. The result is Mapbox Drive, the map built specifically for semi-autonomous driving, ride sharing, and connected cars.
Rather than driving a fleet of cars down every street to make a map, we turn phones, cars, and other devices into a network of real-time sensors. EC2 Spot Instances process the billions of points we collect each day and let us see every street, analyze the speed of traffic, and connect the entire road network. This anonymized and aggregated data protects user privacy while allowing us to quickly detect road changes. The result is Mapbox Drive, the map built specifically for semi-autonomous driving, ride sharing, and connected cars.
Pricing for Spot Capacity
We use the Spot market to bid on spare EC2 instances, letting us scale our data collection and processing at 1/10th the cost. When you launch an EC2 Spot instance you set a price for how much you are willing to pay for the instance. The market price (the price you actually pay) constantly changes based on supply and demand in the market. If the market price ever exceeds your price, your EC2 Spot instance is terminated. Since spot instances can spontaneously terminate, they have become a popular cost-saving tool for non-critical environments like staging, QA, and R&D – services that don’t require high availability. However, if you can architect your application to handle this kind of sudden termination, it becomes possible to run extremely resource-intensive services on spot and save a massive amount of money while maintaining high availability.
The infrastructure that processes the 100 million miles of sensor data we collect each week is critical and must always be online, but it uses EC2 Spot Instances. We do it by running two Auto Scaling groups, a Spot group and an On-Demand group, that share a single Elastic Load Balancer. When Spot prices spike and instances get terminated, we simply fallback by automatically launching On-Demand instances to pick up the slack.
Handling Termination Notices
We use termination notices, which give us a two-minute warning before any EC2 Spot instance is terminated. When an instance receives a termination notice it immediately makes a call to the Auto Scaling API to scale up the On-Demand Auto Scaling group, seamlessly adding stable capacity to the Elastic Load Balancer. We have to pay On-Demand prices for the replacement EC2s, but only for as long as the Spot interruption lasts. When the Spot market price falls back below our price, our Spot Auto Scaling group will automatically launch new Spot instances. As the Spot capacity scales back up, an aggressive Auto Scaling policy scales down the On-Demand group, terminating the more expensive instances.
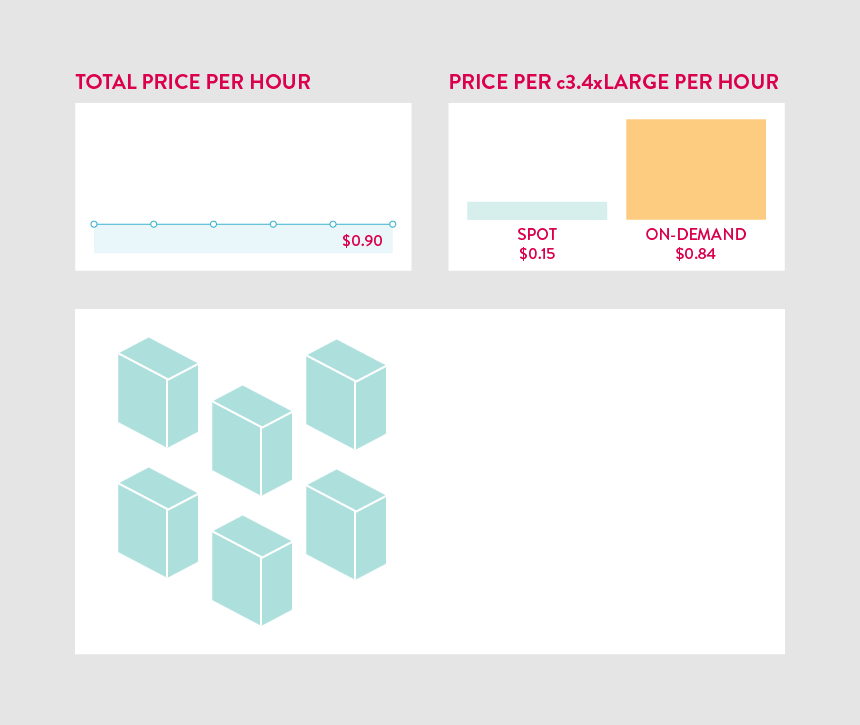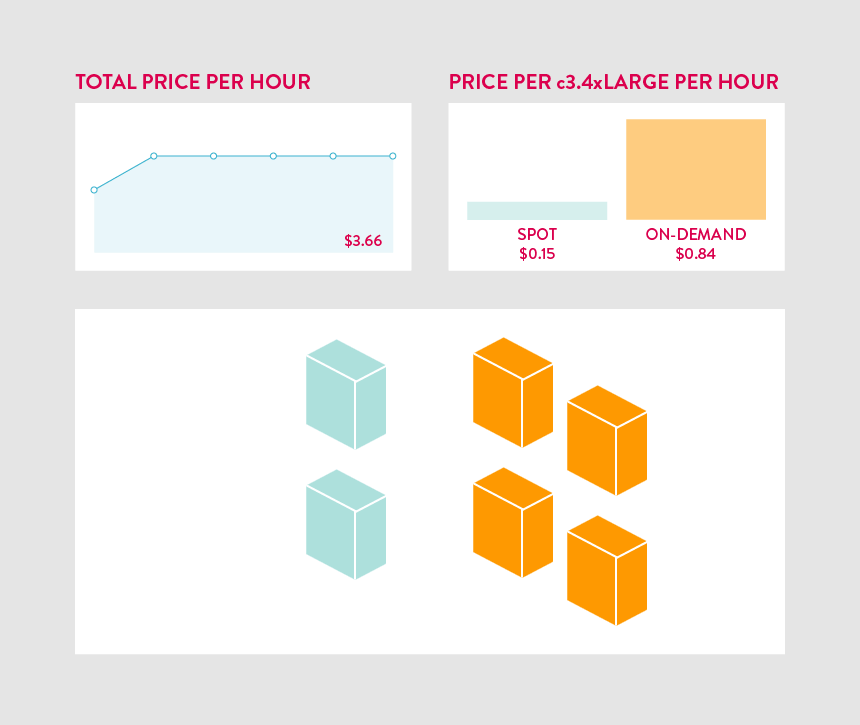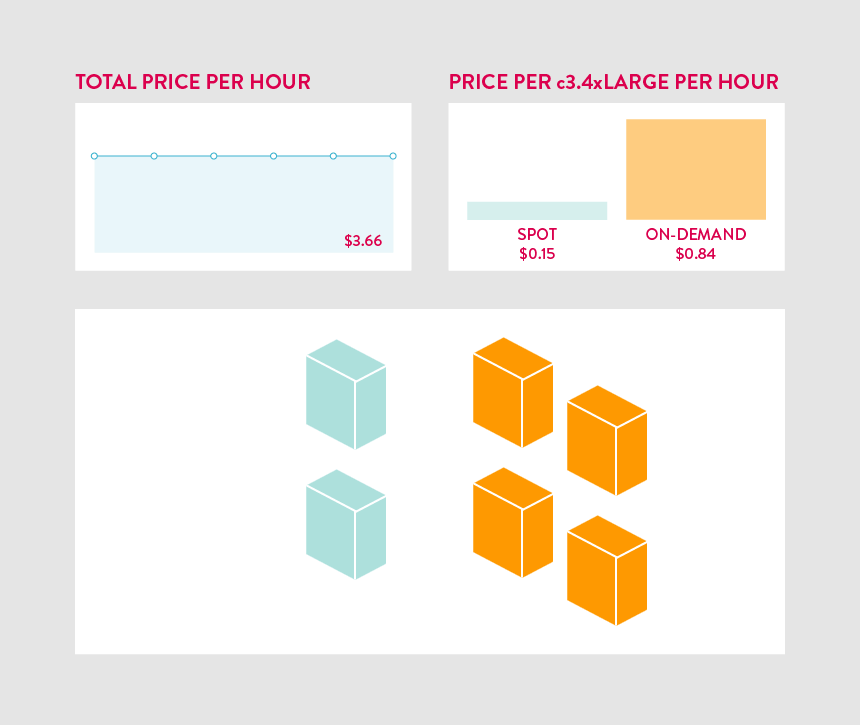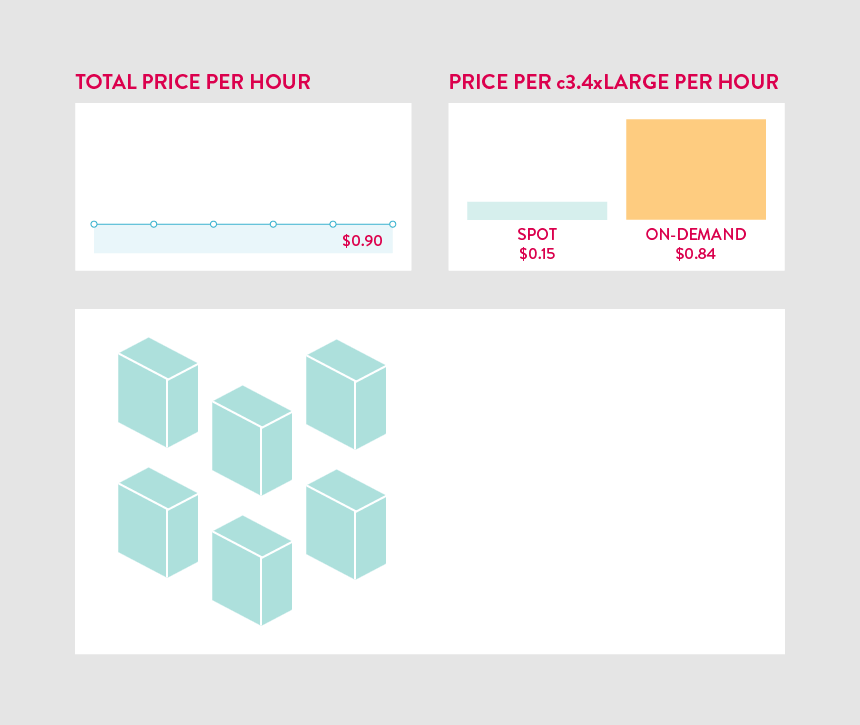
Building our data processing pipeline on Spot worked so well that we have now moved nearly every Mapbox service over to Spot too. As the traffic done by over 170 million unique users of apps like Foursquare, MapQuest, and Weather.com grows each month, our cost of goods sold (COGS) continues to fall. Spot interruptions are relatively rare for the instance types we use so the fallback is only triggered a 1-2 times per month. This means we are running on discounted Spot instances more than 98% of the time. On our maps service alone, this has resulted in an 90% savings on our EC2 costs each month.
Going Further with Spot
To further optimize our COGS we’re working on a “waterfall” approach to fallback, pushing traffic to other configurations of Spot Instances first and only using On-Demand as an absolute last resort. For example, an application that normally runs on c4.xlarge instances, is often compatible with other instance sizes in the same family (c4.2xlarge, c4.4xlarge, etc) and instance types in other families (m4.2xlarge, m4.4xlarge, etc). When our Spot EC2s get terminated, we’ll price the next cheapest option on the Spot market. This will result in more Spot interruptions, but our COGS decrease further because we’ll fallback on Spot instances instead of paying full price for On-Demand EC2 instances. This maximizes our COGS savings while maintaining high availability for our enterprise customers.
It’s worth noting that similar fallback functionality is built into EC2 Spot Fleet, but we prefer Auto Scaling groups due to a few limitations with Spot Fleet (for example, there’s no support for Auto Scaling without implementing it yourself) and because Auto Scaling groups give us the most flexibility.
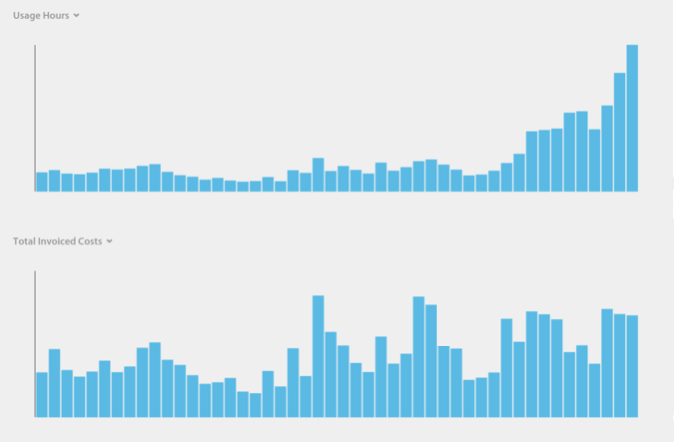
Over the last 12 months, data collection and processing has increased our consumption of EC2 compute hours by 1044%, but our COGS actually decreased. We used to see our costs increase linearly with consumption, but now see these hockey stick increases in consumption while costs stay basically flat for the same period.
If you’re building a resource-hungry application that requires high availability and the costs for On-Demand EC2 instances make it unsustainable to run, take a close look at EC2 Spot Instances. Combined with the right architecture and some creative orchestration, EC2 Spot Instances will allow you to run your application with extremely low COGS.
— Will White, Development Engineering, Mapbox